Programming by Rewards
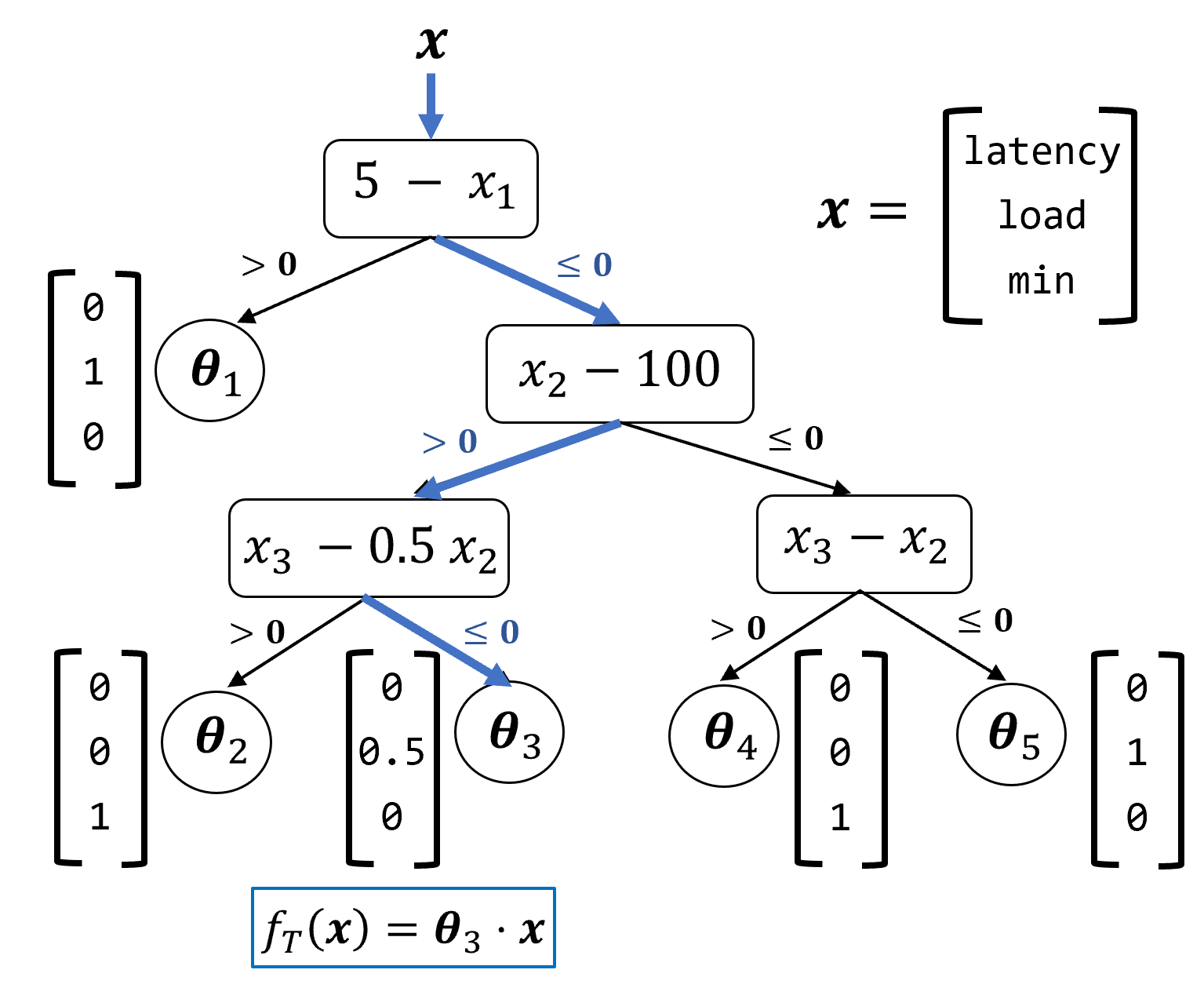
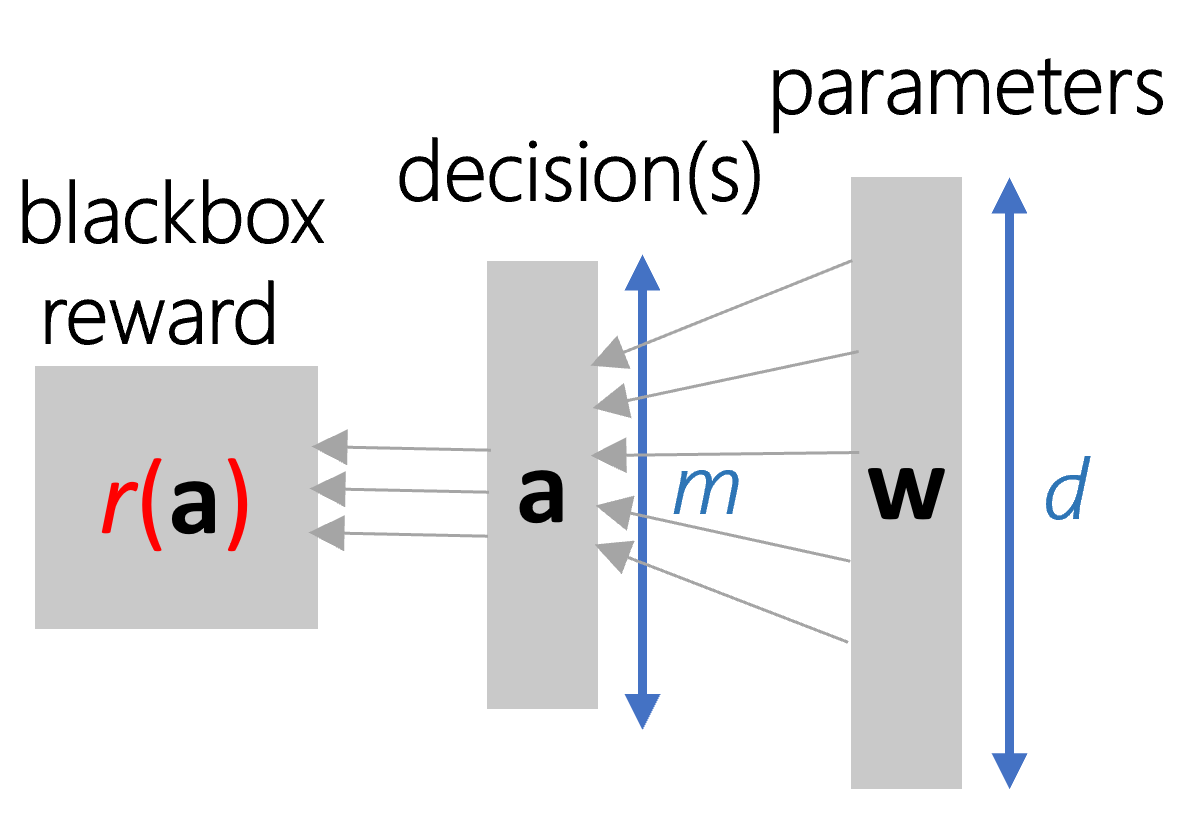
Abstract: We formalize and study ``programming by rewards'' (PBR), a new approach for specifying and synthesizing subroutines for optimizing some quantitative metric such as performance, resource utilization, or correctness over a benchmark. A PBR specification consists of (1) input features $x$, and (2) a reward function $r$, modeled as a black-box component (which we can only run), that assigns a reward for each execution. The goal of the synthesizer is to synthesize a "decision function" $f$ which transforms the features to a decision value for the black-box component so as to maximize the expected reward $E[r \circ f (x)]$ for executing decisions $f(x)$ for various values of $x$. We consider a space of decision functions in a DSL of loop-free if-then-else programs, which can branch on linear functions of the input features in a tree-structure and compute a linear function of the inputs in the leaves of the tree. We find that this DSL captures decision functions that are manually written in practice by programmers. Our technical contribution is the use of continuous-optimization techniques to perform synthesis of such decision functions as if-then-else programs. We also show that the framework is theoretically-founded ---in cases when the rewards satisfy nice properties, the synthesized code is optimal in a precise sense. We have leveraged PBR to synthesize non-trivial decision functions related to search and ranking heuristics in the PROSE codebase (an industrial strength program synthesis framework) and achieve competitive results to manually written procedures over multiple man years of tuning. We present empirical evaluation against other baseline techniques over real-world case studies (including PROSE) as well on simple synthetic benchmarks.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.