- The paper introduces VT-WAM, which integrates tactile deformation dynamics with visual cues using an Asymmetric Mixture-of-Transformers attention mechanism.
- The method employs a three-expert network to jointly process visual, tactile, and action inputs, leading to significant improvements in both surface-interaction and constrained insertion tasks.
- Experimental results show a 71.67% average success rate, with robust tactile attention ensuring performance even under occluded or ambiguous visual conditions.
Introduction and Motivation
Contact-rich manipulation remains a critical open challenge in the advancement of autonomous robotics, as it requires precise real-time reasoning about local tactile phenomena such as deformation, friction, and slip. Visual observations alone are insufficient for these settings due to occlusions and the localized, transient nature of contact cues. Contemporary visual-tactile policies have incorporated tactile observations, yet frequently do not model the temporal dynamics of tactile feedback, resulting in sub-optimal exploitation of tactile information.
The VT-WAM framework ("VT-WAM: Visual-Tactile World Action Model for Contact-Rich Manipulation" (2607.02503)) directly addresses this deficiency. The method couples action prediction with the explicit modeling of tactile deformation dynamics, formulating policy learning within a joint visual-tactile-action flow matching paradigm. The architecture synthesizes two principal advances: (1) an Asymmetric Mixture-of-Transformers (MoT) Attention mechanism, which structures information exchange across vision, tactile, and action tokens, and (2) a contact-gated Action-Visual-Tactile Attention Guidance (AVTAG) strategy, which enforces tactile attention during contact phases via a hinge ranking auxiliary training loss.
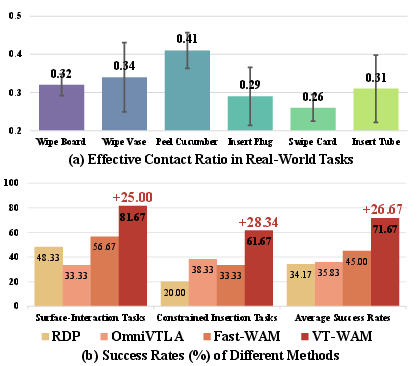
Figure 1: Tactile signal is temporally sparse; coupling action prediction with tactile dynamics yields decisive gains on both surface-interaction and constrained insertion tasks.
Methodology
VT-WAM employs a three-expert network backbone, with modality-specific experts for visual, tactile, and action streams. The visual stream captures scene context via a wrist camera, encoded using a video VAE; tactile deformation fields are acquired via paired 3D tactile sensors mounted on the gripper and encoded via a tactile VAE; action tokens represent control sequences. Each token sequence is projected into a common embedding space, with cross-modality information routed via Asymmetric MoT Attention.
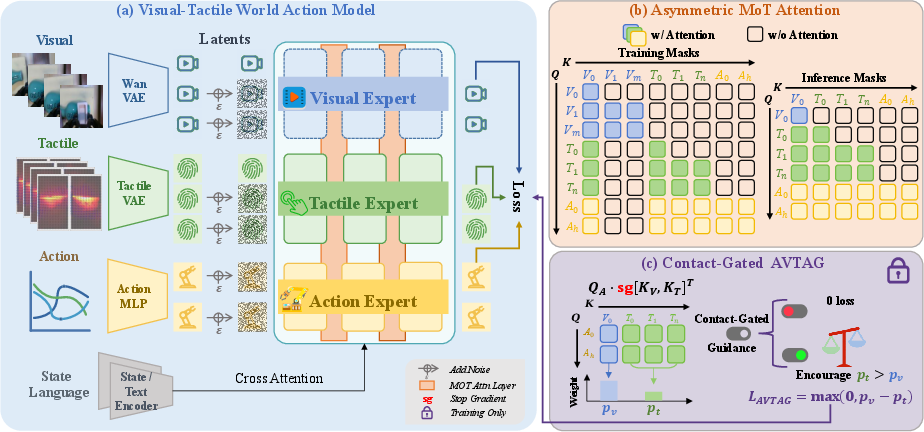
Figure 2: System overview, including the joint visual-tactile-action flow matching architecture (a), attention masks (b), and the AVTAG contact-phase loss (c).
Asymmetric MoT Attention restricts action queries to the first frame of visual tokens (scene context anchor) and the complete tactile sequence (contact evolution). This design enables token-efficient operation during inference (visual-cache mode), while ensuring the action expert utilizes full tactile dynamics at contact phases. Masking within the attention operator guarantees unimpaired intra-expert communication while carefully modulating cross-expert attention.
The auxiliary AVTAG loss addresses an observed optimization pathology: the stronger, temporally-dense visual signals tend to dominate action prediction despite contacts’ critical importance. By extracting the attention weights from action queries to tactile and visual tokens and imposing a contact-gated hinge ranking penalty, AVTAG enforces increased tactile attention during contact, which substantially enhances contact-driven policy adaptation.
Experiments are conducted on a 7-DoF xArm7 robot equipped with a Robotiq 2F-85 gripper, a wrist RGB camera, and dual Xense tactile sensors. All sensing and actuation streams are captured at 30 Hz. Training demonstrations are collected via kinesthetic teaching, ensuring the dataset captures realistic tactile-visual-actuation correspondences for contact-rich tasks.
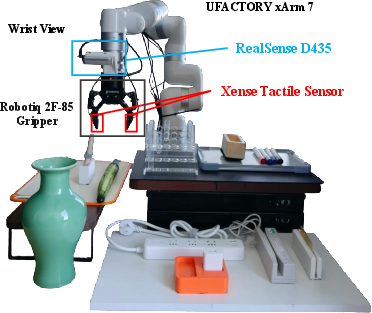
Figure 3: Physical experimental setup, highlighting the arrangement of arm, gripper, camera, and tactile sensors.
Benchmarking encompasses six real-world manipulation tasks, partitioned into surface-interaction (wipe board, wipe vase, peel cucumber) and constrained insertion (insert plug, swipe card, insert tube) domains. Each requires robust contact-state inference under varying visuotactile ambiguity and control precision.

Figure 4: Illustration of the six benchmark tasks split by interaction regime.
Quantitative and Qualitative Results
Across six tasks, VT-WAM achieves a 71.67% average success rate (see Figure 1), significantly surpassing both visual-only and prior multi-modal policies. For surface-interaction tasks, it attains 81.67%, and for constrained insertion, 61.67%. This constitutes absolute improvements of 26.67% over Fast-WAM and 35.84% over OmniVTLA baselines, confirming the efficacy of tactile dynamics integration. Notably, ablations confirm the necessity of modeling tactile temporal evolution (not just static tactile state), and demonstrate the further non-trivial benefit obtained by AVTAG guidance.
Qualitative analysis of predicted visual and tactile trajectories demonstrates that VT-WAM produces temporally-coherent tactile field forecasts, capturing nuanced dynamics such as pressure concentrations and contact migrations essential for manipulation adaptation.

Figure 5: Sample predictions for both wrist camera streams and tactile deformation fields; orange denotes prediction, blue denotes ground truth.
Further analysis with AVTAG shows that, during events where vision is unreliable (e.g., subtle view changes or occlusions), action expert attention dynamically shifts to tactile streams, enabling recovery from contact loss and correct continuation of the manipulation routine.
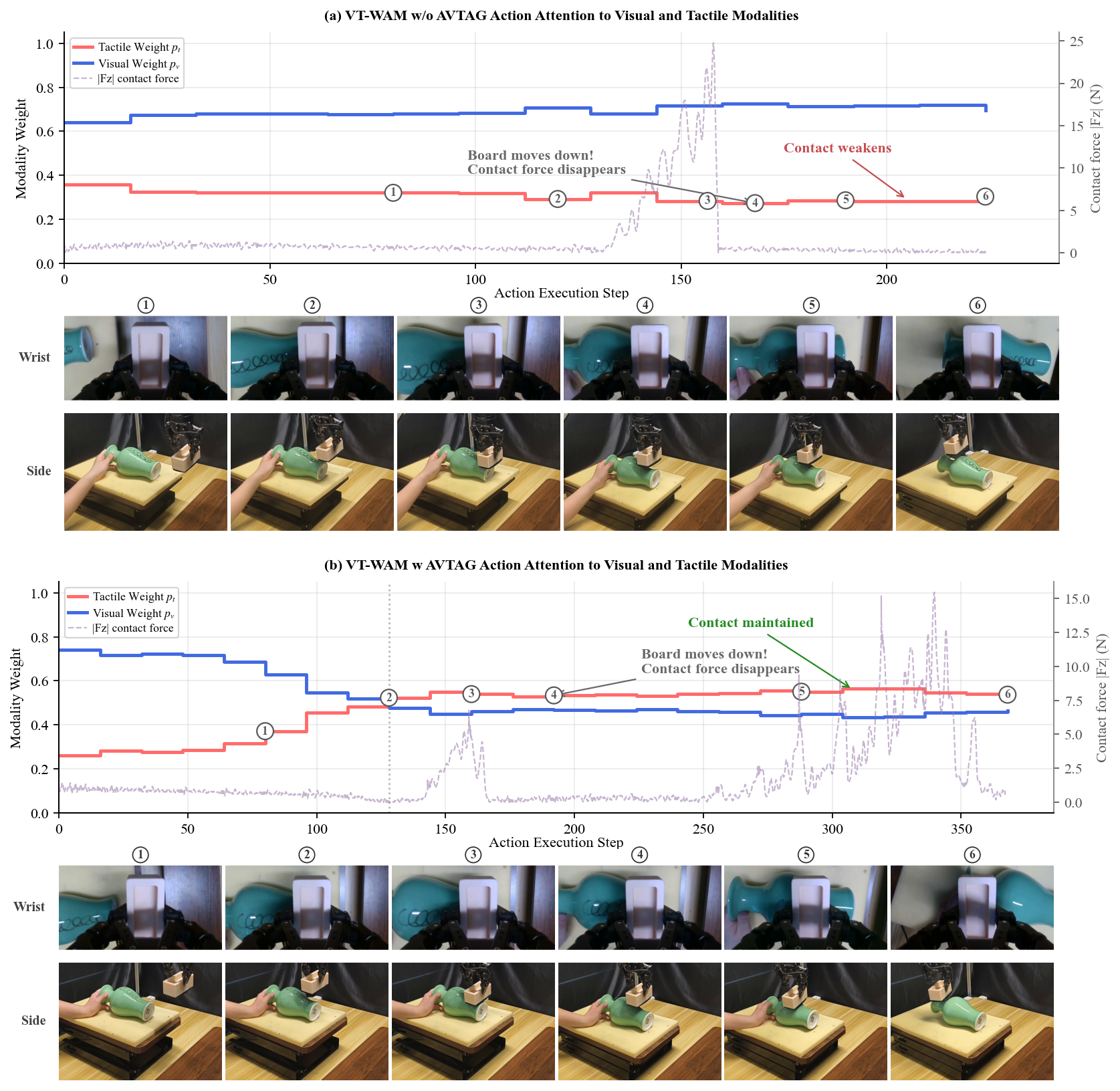
Figure 6: AVTAG ensures tactile-driven attention during contact recovery; the model increases tactile attention (red curve) and thereby achieves successful reconnection and task completion.
Ablation Studies
Systematic ablation isolates the design’s key aspects. Introducing temporal tactile prediction with symmetric attention increases task success over visual-only Fast-WAM, but using asymmetric attention (action queries get the entire tactile sequence, only first visual anchor) yields superior performance and more efficient inference. Removing temporal tactile modeling or disabling AVTAG both yield measurable drops in success rate, particularly on tasks where tactile adaptation after contact disturbance is critical.
Practical and Theoretical Implications
Practically, VT-WAM offers a deployable framework for robust contact-rich manipulation, especially in scenarios with visually-indistinct or occluded interactions. The visual-cache inference enables efficient rollout, as future visual frames need not be predicted at deployment. Theoretically, this work reifies the importance of explicit tactile dynamics modeling in world-action-policy architectures and demonstrates how attention guidance can counteract inter-modality imbalance during joint training. The approach links flow matching generative modeling, multi-modal transformer attention, and contact-phase-aware supervision, raising pertinent questions regarding scaling, transfer to multi-task settings, and extension to richer tactile modalities.
Conclusion
VT-WAM establishes the benefits of integrating tactile deformation dynamics directly into the world action modeling loop. By architecting a tailored attention mechanism and leveraging contact-gated attention guidance, the model attains clear performance improvements across diverse contact-rich manipulation settings. The results emphasize the necessity of temporally-aware tactile processing and contact-phase-sensitive training strategies. Future research directions include scaling the approach to multi-task and multi-robot regimes, and expanding tactile sensor sophistication to further enhance manipulation dexterity.

