- The paper introduces a modular VI-SLAM framework that isolates learned visual front-ends to precisely quantify their contributions and trade-offs.
- The method integrates classical and neural feature extractors with a unified sliding-window estimator and loop closure to handle diverse environmental challenges.
- The experimental evaluation reveals context-dependent performance, highlighting gains in dynamic scenes, low-parallax conditions, and energy versus accuracy trade-offs.
DL-VINS-Factory: A Modular Benchmarking Framework for Learned Visual Front-Ends in Visual-Inertial SLAM
Motivation and Problem Setting
Robust visual-inertial SLAM in real environments depends critically on front-end feature extractors and trackers. Progress in deep local feature learning—through models such as SuperPoint, ALIKED, and RaCo—has substantially improved local correspondence, yet their system-level benefit for tightly coupled VI-SLAM remains insufficiently isolated due to convolved differences in back-end optimization, loop-closure strategies, and hardware constraints. The field lacks a modular, controlled testbed enabling precise quantification of the contribution and trade-offs of learned keypoint extractors and neural matchers compared to classical pipelines. Additionally, loop-closure modules are tightly coupled to the choice of descriptor, hampering generality.
System Architecture
DL-VINS-Factory addresses this gap, architected as a fully modular VI-SLAM stack. Classical and learned visual front-ends are interchangeable within a unified back-end (sliding-window Ceres-based estimator) and loop-closure pipeline. Supported front-ends include ALIKED, RaCo, SuperPoint, and XFeat, with either Lucas-Kanade optical flow or LightGlue neural matching; all variants share the same estimator and 4-DoF pose-graph loop-closure.
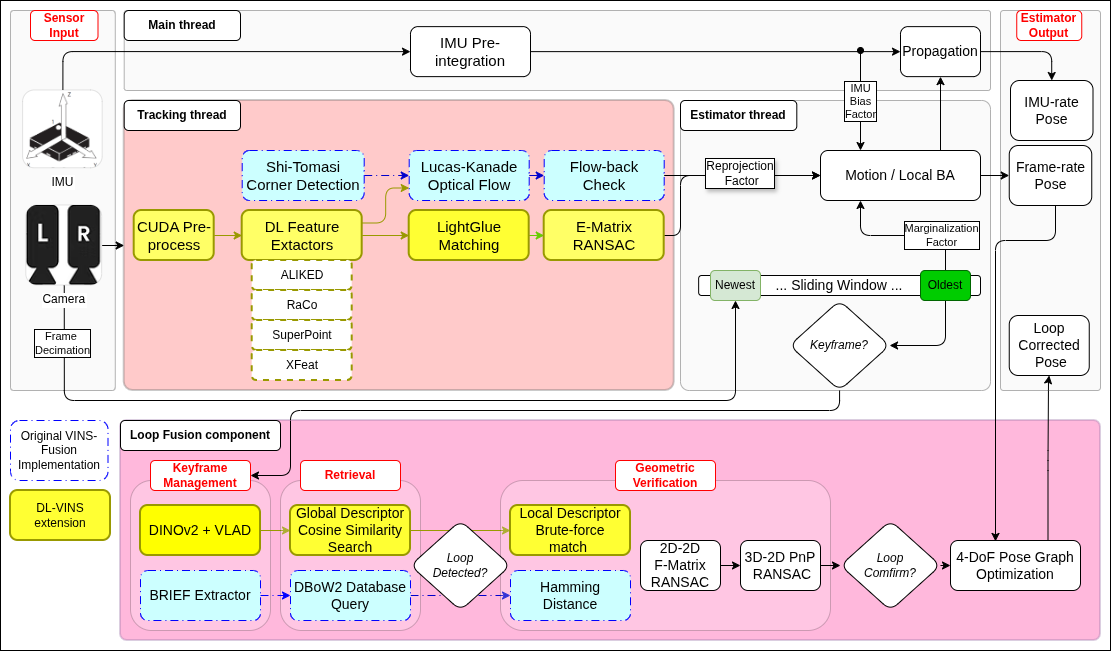
Figure 1: System overview of the DL-VINS-Factory pipeline, highlighting the interplay of modular learned front-ends and the unified, front-end agnostic loop closure subsystem.
Input pre-processing is CUDA-fused to minimize host-device bandwidth, and each model is exported as a platform-specific TensorRT engine with static shape for deployment. RaCo, a detector-only module, is paired with ALIKED descriptors via an efficient hybridization exploiting shared feature encoding (Figure 2).
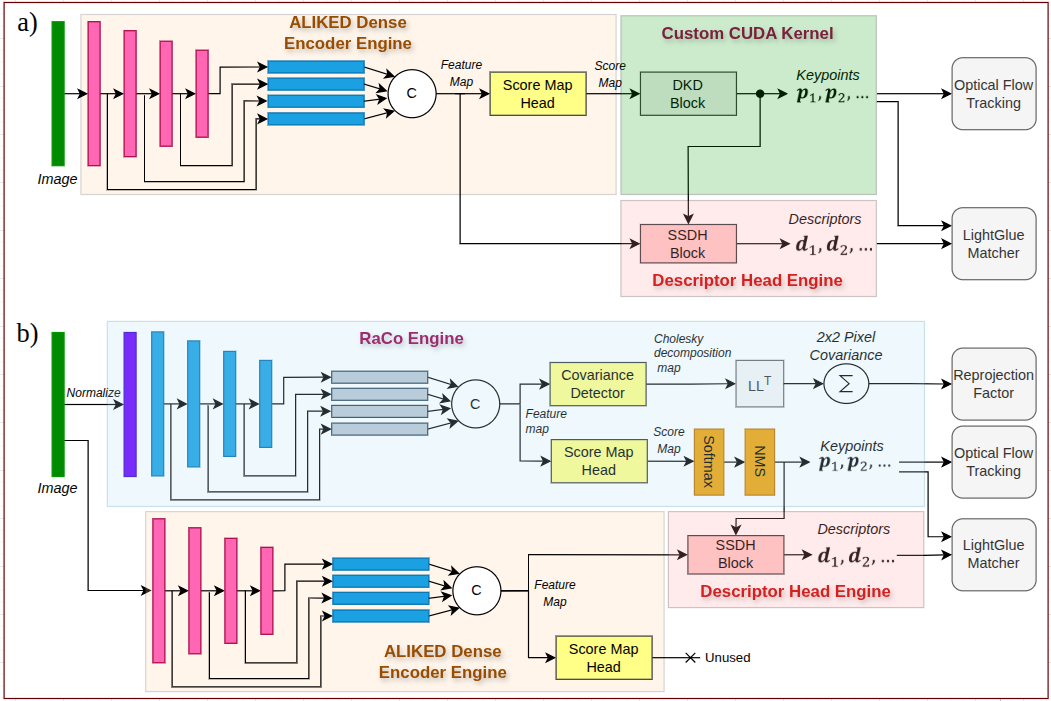
Figure 2: Decomposition of ALIKED and RaCo in deployment, demonstrating reuse of static-shaped descriptor heads and efficient GPU execution.
Feature matching with LightGlue operates fully on-GPU, exploiting batch-2 matching for stereo and temporal pairs. Tracks are constructed by identifying one-to-one correspondences above a softmax-activated confidence. Geometric verification uses MAGSAC++, with a strict 1-pixel threshold. Stereo triangulation applies local disparity and positive-depth gating. For configurations using optical flow (LK), only keypoints are required; descriptors are omitted.
An AnyLoc-based loop-closure module aggregates DINOv2 ViT-S/14 patch descriptors via a universal VLAD codebook and performs brute-force global retrieval by cosine similarity, decoupling loop-closure from the choice of local descriptor and supporting online operation without per-dataset retraining.
Experimental Design
Benchmarks cover four data regimes: EuRoC (structured indoor MAV), NTU-VIRAL (aerial, dynamic, outdoor/indoor), Botanic Garden (unstructured outdoor, vegetation/texture-sparse), and SubT-MRS (multi-degraded, low-illumination underground), on both x86-64 (RTX 3080 Ti) and embedded Jetson AGX Orin. All models are deployed with frozen, out-of-domain weights; no retraining. The keypoint upper limit for learned extractors is capped at 256 except for particularly challenging SubT-MRS sets, where 160 are used to match the tractable sliding window size.
Tracking performance is measured by ATE (RMSE) via the evo toolkit. Performance is evaluated under strictly identical calibrations, sensor configurations (mono, stereo), and operating parameters across baselines and learned variants.
Quantitative and Qualitative Analysis
Odometry and Loop-Closed Accuracy
Empirically, learned extractors provide conditional improvements in ATE, tightly correlated with scene structure, ego-motion, parallax, and texture. In structured, moderate-motion datasets (EuRoC), classical GFTT+LK and ALIKED+LG are comparably performant (0.122–0.146 m ATE), showing that traditional, well-conditioned grid-based factoring can match or outperform learned descriptors when parallax is sufficient.
On the high-dynamics NTU-VIRAL, ALIKED+LG in stereo yields a 12% reduction in ATE over GFTT+LK (0.552 m vs. 0.711 m), demonstrating significant gains of neural matching under large inter-frame displacement. In contrast, within the Botanic Garden’s low-parallax vegetation-dominated scenes, optical-flow variants (SP+LK, Ra+LK) are optimal; here, learned features improve over GFTT, with SuperPoint+LK reducing grayscale RMSE by 29%, and RaCo+LK reducing RGB RMSE by 38%. Stereo variants generally degrade accuracy when disparity is ambiguous.
Qualitative tracking outcomes reveal that LightGlue ensures robust tracklets under high inter-frame rotations and viewpoint changes, distinctly outperforming LK under aerial or aggressive motion profiles (Figure 3).

Figure 3: Feature distribution and temporal tracking visualization, comparing front-end extracts and frame-to-frame correspondences under varying environments and front-ends.
Robustness in Adverse Conditions
Under extreme visual degradation (SubT-MRS), no system variant completes all trials. LET-NET (illumination-trained, classical variant) leads robustness; yet, certain learned configurations retain competitiveness in specific splits (see Table III of the paper). Critically, LightGlue variants show greater brittleness to severe occlusion and dynamic-object artifact: LK tracks gracefully degrade, while LightGlue rapidly loses correspondences. However, on flash/overexposure, ALIKED/LG and RaCo/LG provide accurate trajectories, showing merit for neural front-end architectures under photometric stress.
Stereo/Monocular and Matcher Trade-off
Ablation on median ATE ratio shows that the benefit of stereo configurations is strongly tied to feature geometry and texture: stereo improves over monocular for EuRoC and NTU-VIRAL, but harms performance in Botanic scenes due to under-constrained triangulation and scene ambiguity (Figure 4). Meanwhile, LightGlue matching is superior to LK for high viewpoint change, but optical flow is more stable for low-parallax, motion-degenerate sequences (Figure 5).
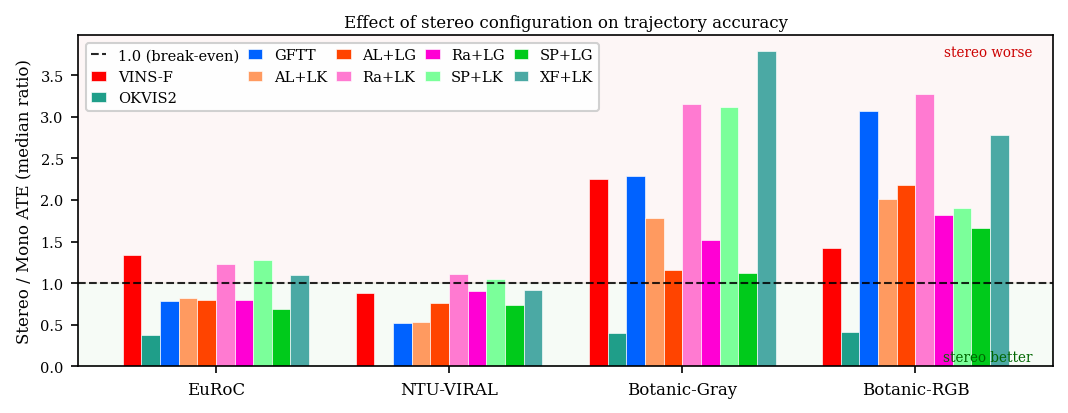
Figure 4: Median ATE ratio (stereo-to-mono) across datasets, showing environment-dependent stereo utility.
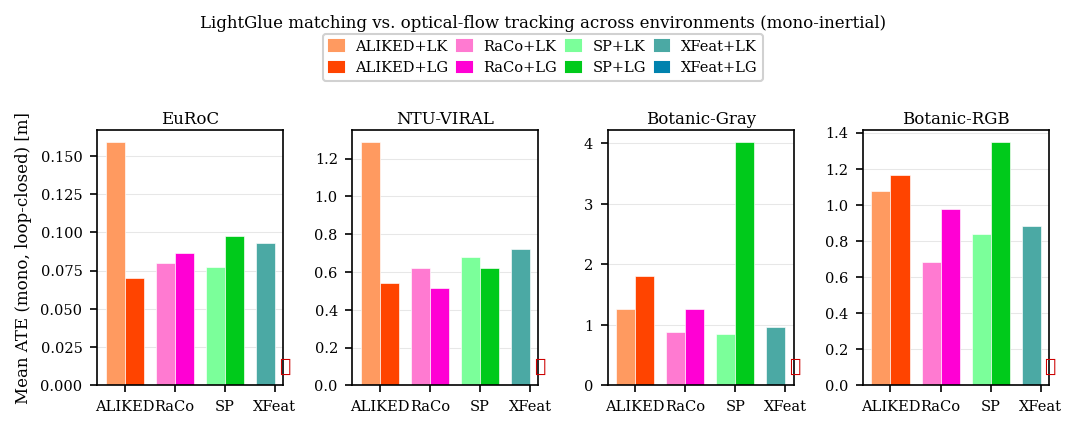
Figure 5: Mean ATE for LK versus LightGlue matchers, demonstrating the advantage of neural matching in dynamic-motion sequences.
Loop Closure and Retrieval
AnyLoc (DINOv2–VLAD) exposes up to 7× more verified loops than classical DBoW2–BRIEF, notably improving place recognition across heterogeneous datasets. The precision of raw cosine similarity gating is low; geometric verification (descriptor matching + epipolar and PnP RANSAC) remains essential. False positive loop-closures are rare but damaging, especially in visually repetitive natural environments.
DL-VINS-Factory supports strict cross-platform evaluation. ATE-matched results across x86-64 and Jetson platforms are tightly correlated (median difference ≤6%), with observed outliers arising from floating-point/round-off mismatches manifesting in minimal per-frame keypoint selection differences—these differences are most impactful on very short or high-accuracy runs. Compute profiling reveals end-to-end latency is limited by the Ceres back-end; learned front-end latency (including LightGlue) is largely hidden unless stereo and batch-2 matching are used, with Jetson running 29–47 FPS mono and 18–33 FPS stereo for EuRoC/NTU datasets (Figures 9, 10).
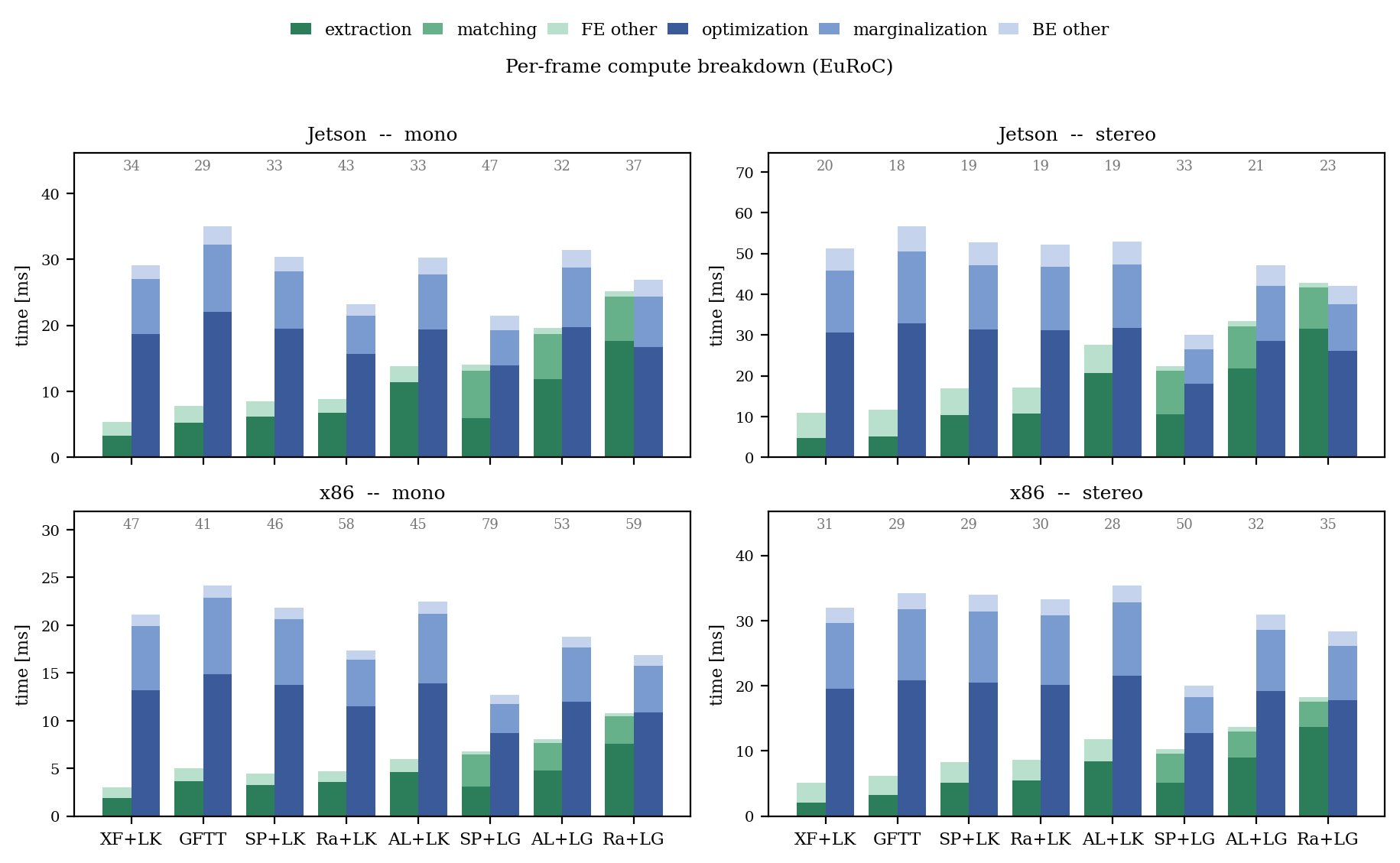
Figure 6: Per-frame compute breakdown showing front-end/back-end contributions; major latency component is sliding-window optimization.
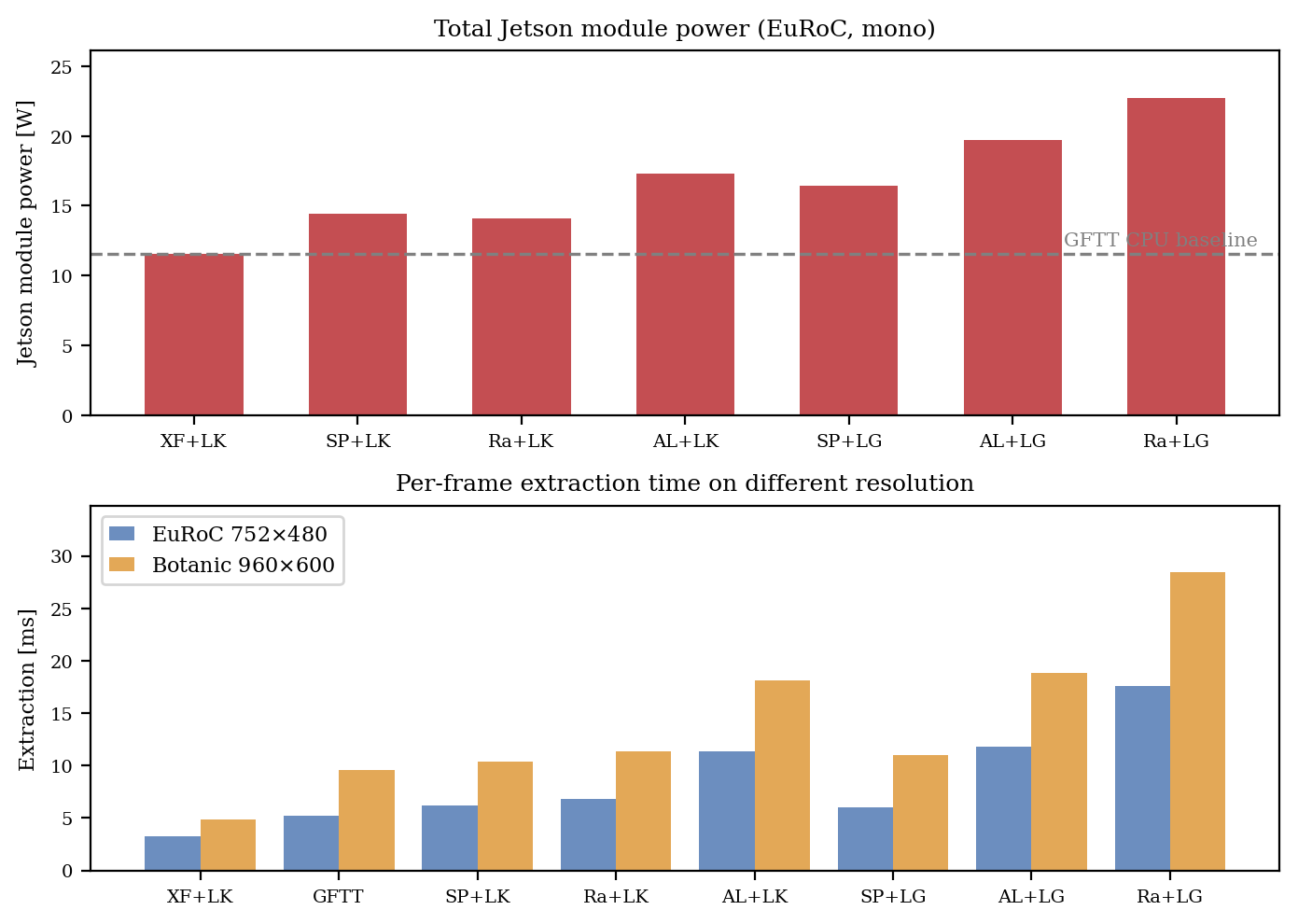
Figure 7: Power and runtime breakdown on Jetson: LightGlue and heavy extractors increase energy demand, but throughput remains suitable for real-time operation.
Keypoint ablation experiments show that learned extractors are not inherently more robust to (moderate) keypoint cap changes (Figure 8). Optimal performance for ALIKED/RaCo is at 256 keypoints—a plateau balancing kernel occupancy and tracklets for real-time processing.
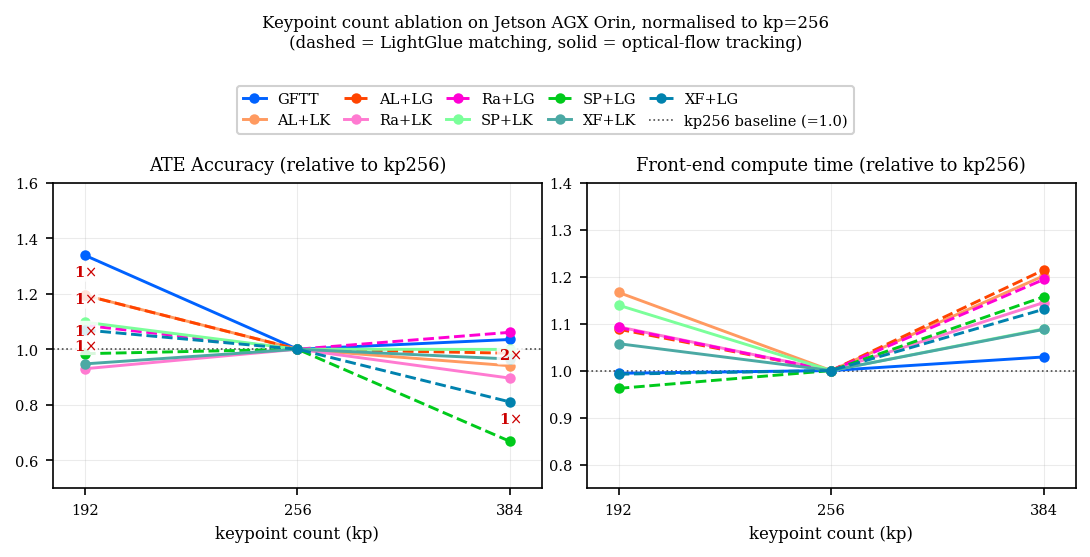
Figure 8: Keypoint count ablation: accuracy is invariant until starvation; compute time is kernel occupancy-dependent, minimal at 256 keypoints for ALIKED/RaCo.
Finally, inclusion of RaCo’s learned covariance weighting into the optimization pipeline, inspired by MAC-VO, can rescue stereo failures (ATE improvements up to 80% on failure cases), but requires careful gain adjustment; monocular trajectories exhibit neutral or negative sensitivity.
Implications and Future Directions
The decoupled design and tightly controlled benchmarking protocol clarify that the benefits of learned visual features in VI-SLAM are deployment- and context-dependent, not universal. When parallax and texture support strong geometric conditioning, classical methods are competitive. Neural extractors and matchers excel when motion, appearance, and viewpoint changes challenge invariance, but can be brittle to temporal degradation or poor local structures.
Practically, embedded deployment is feasible with real-time guarantees, but comes at higher energy cost for neural matching and global descriptor encoding. AnyLoc demonstrates scalable place recognition decoupled from local representation, facilitating agnostic loop-closure—a critical requirement for rapid system prototyping and deployment on heterogeneous hardware and sensor payloads.
Theoretically, this work motivates further research in end-to-end optimization of not just feature representation, but also adaptive, context-aware matching and uncertainty estimation at the front-end, and sampled-data optimality in tightly coupled estimators under real-world non-stationary conditions. Future developments should address fully end-to-end learned estimation in VI-SLAM, advanced uncertainty reasoning (online gain selection or direct likelihood training), and shared multi-modal fusion architectures.
Conclusion
DL-VINS-Factory constitutes a rigorous, extensible testbed for measuring the impact of learned visual front-ends in tightly coupled VI-SLAM. Empirical results show there is no universally optimal front-end; learned representations provide strong gains when geometric constraints are weak, but are conditional on the environment and motion. Loop closure via global visual descriptors enables greater modularity and matching recall, though geometric verification remains necessary to ensure reliability. Real-time, embedded deployment is tractable with TensorRT but must respect compute and energy bounds. Future work will likely focus on tighter integration between front-end learning, adaptive weighing, robust correspondence under all-weather and dynamic scenarios, and cross-modal/scene priors for resilient SLAM across broader domains.

