- The paper presents a system-level breakthrough by demonstrating that small, open-weight language models can achieve competitive accuracy with up to a 390x cost reduction over proprietary systems.
- It introduces BlendSQL’s innovative techniques—such as type-constrained decoding, early deduplication, and cascade filtering—to optimize query processing and latency.
- Empirical results across diverse benchmarks reveal robust scalability, reproducibility, and energy efficiency, despite a modality gap in audio and image tasks.
Large Databases Need Small, Open-Weight LLMs: An Expert Review
Motivation and Problem Statement
Hybridizing deterministic relational DBMSs with LMs that possess flexible, unstructured reasoning capabilities has become a key challenge in database and NLP systems. A dominant integration pattern leverages UDF-style LM calls to extend native SQL, enabling powerful queries over both structured and unstructured data. However, the reliance on proprietary API-based, closed-source LMs presents two critical impediments: prohibitive cost via token-based billing—costs upwards of \$10,000 per experimental run—and operational inflexibility due to rate limits and opacity in API infrastructure. This paper provocatively challenges the prevailing assumption that only large, closed-weight LMs are practically viable for LM-DB systems, presenting strong empirical evidence and system-level optimizations that make small, quantized, open-weight LMs competitive or superior along quality, cost, and latency axes (2606.31808).
BlendSQL Architecture and System Innovations
The core system contribution is BlendSQL v0.1.0, a fully-integrated LM-DB framework that supports both text and multi-modal data, emphasizing efficient utilization of small local models. BlendSQL adopts a two-component architecture consisting of a logical query optimizer for effective predicate pushdown and batching, and robust LM function wrappers with schema-constrained decoding and type inference. The system's polymorphic LM functions (llmqa and llmmap) implement functionality spanning filtering, ranking, aggregation, and entity linking.
Key system optimizations include:
- Type-driven constrained decoding: Constrains LM outputs to specified or inferred datatypes via a context-free grammar, yielding measurable accuracy improvements for structured queries.
- Type-aligned one-shot prompting: Selects demonstration examples aligned to the datatype and output structure, minimizing unnecessary token usage while maintaining model reliability.
- Early deduplication: Reduces redundant LM calls by deduplicating input values upstream of LM invocation, directly minimizing inference workload when column cardinality is low relative to row count.
- Early exiting and cascade filtering: Enables short-circuit evaluation in the presence of LIMIT clauses and conjunctive LM filter predicates, dramatically improving system latency and efficiency.
Empirical Results and Benchmarking
Extensive benchmarking is conducted on SemBench, covering five diverse scenarios (movie, e-commerce, cars, wildlife, MMQA) with heterogeneous data modalities (text, image, audio). All experiments are performed locally using small, quantized Gemma 3/4 family models on a commodity 16GB VRAM GPU. Baselines include LOTUS, Palimpzest, ThalamusDB, and Google BigQuery AI functions.
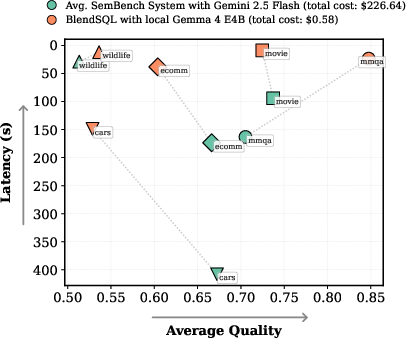
Figure 1: Quality, latency, and cost evaluated across the five SemBench scenarios, averaged over five runs.
Strong Claims and Contradictory Findings:
On text-heavy queries, the open-weight system occasionally outperforms proprietary APIs; on multi-modal tasks (image and especially audio), a "modality gap" emerges, with open models lagging by 0.10 (audio) and 0.03 (image) in quality on relevant tasks.
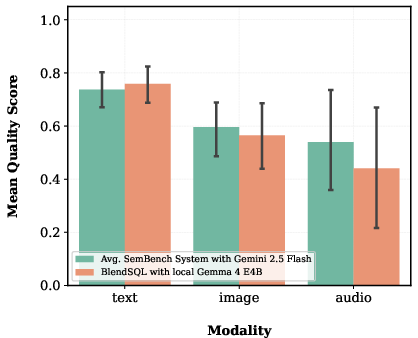
Figure 3: Comparison of model performance by modality; text quality is matched or surpassed, but open-weight models trail in image and audio.
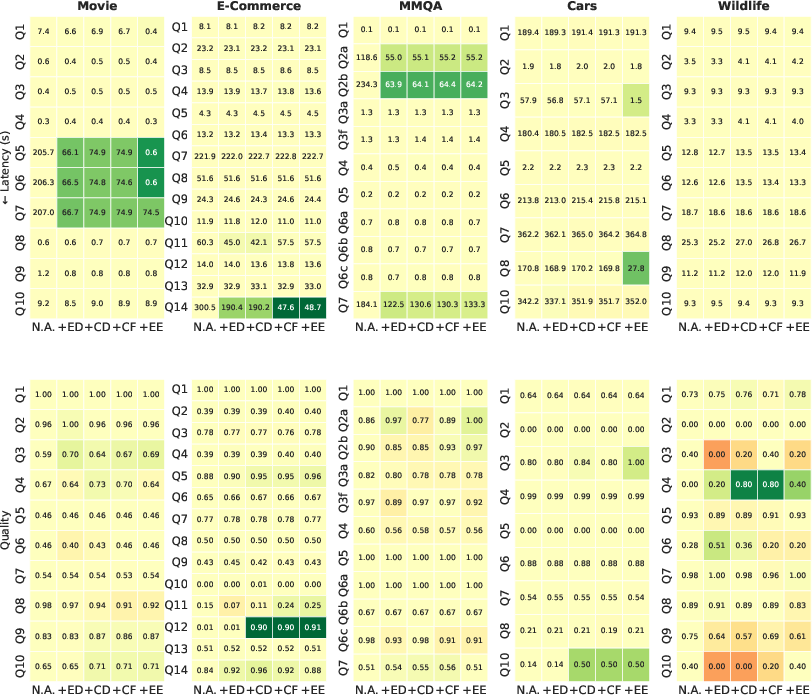
Ablation Studies and System Feature Impact
The paper conducts extensive ablation analysis to quantify the effect of each system optimization.
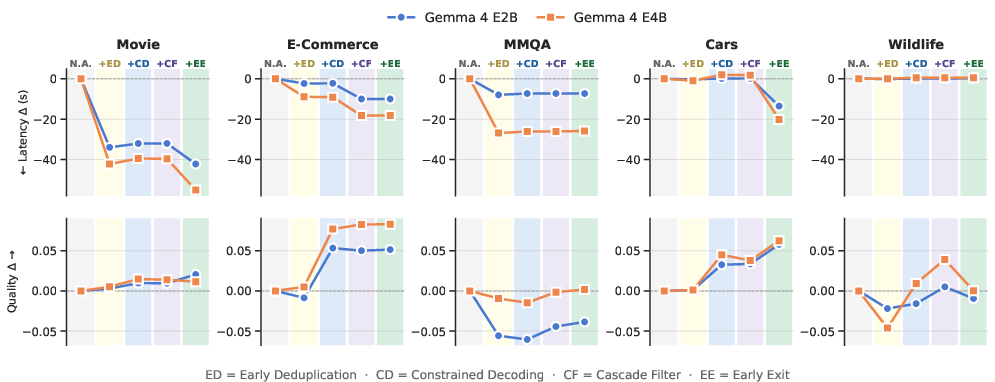
Figure 4: Incremental quality and latency improvements from each added feature in BlendSQL v0.1.0.
Concurrency and Throughput of Local Inference
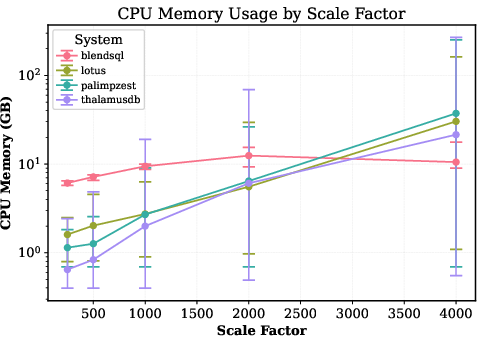
BlendSQL enables high-throughput inference by running small LMs locally without provider rate limits. The experiments show that for small prompt lengths, increasing max concurrency is highly effective up to hardware saturation.
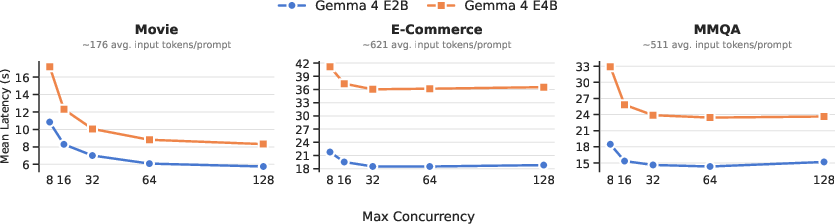
Figure 6: Latency scales inversely with concurrency up to hardware limits on a 16GB RTX 5080 GPU.
This ability to exploit hardware-parallelism allows further cost reductions under time-based billing, contrasting starkly with the volume-based counter-incentives inherent to API pricing.
Cost, Sustainability, and Reproducibility
By shifting to open-weight, local deployment, the system achieves not only drastic cost reduction but also significant improvements in research accessibility and reproducibility. Hardware cost for a single experiment run falls from \$2,988 (Palimpzest/Gemini) to \$6.96 (BlendSQL/Gemma), and the entire workload’s energy consumption is estimated at 11.4 kg CO2—orders of magnitude lower than token-billed cloud approaches. Importantly, open-weight models guarantee stable, reproducible evaluation—addressing systemic challenges posed by the fluctuating quality of closed APIs.
Limitations and Theoretical Implications
The principal limitation is the modality gap—open-weight models currently fall short for multi-modal (esp. audio) tasks, so API-based closed LMs remain preferable in those settings. Furthermore, proprietary baselines could not be fully cross-benchmarked with local LMs on all scenarios due to SDK incompatibilities.
Theoretically, this research establishes a new system-level baseline for practical LM-DB deployment: infrastructure and harness-level innovation can realize most of the performance gains typically ascribed to model scale or access to closed APIs. The result challenges the necessity of proprietary endpoints for high-quality hybrid data processing.
Future Directions
Ongoing hardware and open-model architectural advances are likely to close the modality gap observed in the present study, extending the domain coverage of small, local LMs. Further, as local inference frameworks evolve to better support multi-modal continuous batching, the performance and cost advantages demonstrated will expand. There is significant room for advancing query optimization by leveraging learned selectivity estimation or dynamic predicate reordering tailored to LM-DB function signatures.
Conclusion
This paper demonstrates that principled system-level engineering, coupled with open-weight, small LLMs, makes high-quality, low-latency, and cost-effective LM-DB integration widely accessible. By decoupling system performance from the vagaries of closed API endpoints, it establishes a solid foundation for accessible, scalable, and fully reproducible hybrid data analytics research (2606.31808).