When LLMs Develop Languages: Symbolic Communication for Efficient Multi-Agent Reasoning
Abstract: Chain-of-Thought (CoT) improves LLMs on difficult reasoning tasks, but it often incurs long natural-language rationales that are poorly aligned with efficient machine reasoning. We propose Communicative Language Symbolism Routing (CLSR), a test-time framework in which multiple LLM agents autonomously invent, evolve, and share compact Language Symbolism Frameworks (LSFs), while a latent-free router adaptively selects and composes these languages per query to optimize the accuracy-token trade-off. Unlike prompt optimization that refines surface instructions, CLSR treats each LSF as a reusable symbolic protocol with compact symbols, usage rules, and a message-passing contract, and improves it through an evolutionary loop driven by correctness and token cost. At inference time, the router may invoke a single low-cost LSF call, ensemble multiple LSFs, or execute a multi-round LSF composition protocol on harder queries. Across challenging benchmarks, CLSR reduces latency-oriented generated token completion by $3\sim 6\times$ compared to standard CoT while maintaining accuracy. We further derive an information-theoretic lower bound on token cost under arbitrary symbolism and show that, under an interpreter-realizability premise, multi-round LSF protocols conditionally subsume program-execution pipelines. Code is publicly available (https://github.com/pzqpzq/LSF_MDia).


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in a nutshell)
The paper asks a simple question: Can AI chatbots invent their own “shorthand” languages to think faster without getting worse at answering questions? The authors introduce a method called CLSR that lets several AI “agents” create and improve compact symbol-based mini-languages, then pick the best one for each question to balance accuracy and speed.
What questions the researchers wanted to answer
- Can LLMs create reusable, compact “reasoning languages” that use fewer tokens than normal step-by-step English explanations?
- Can a smart planner (a “router”) decide, per question, which mini-language to use, when to combine a few, or when to run a multi-step plan—so we use just enough tokens to stay accurate?
- Is there a theoretical limit on how short answers can be while staying correct?
- Can these mini-languages act a bit like small programs, letting models do program-like reasoning without running external code?
How the method works (explained simply)
Think of tokens as the tiny pieces the AI writes—like words or parts of words. Writing fewer tokens usually makes responses faster and cheaper.
Here’s the idea, using everyday analogies:
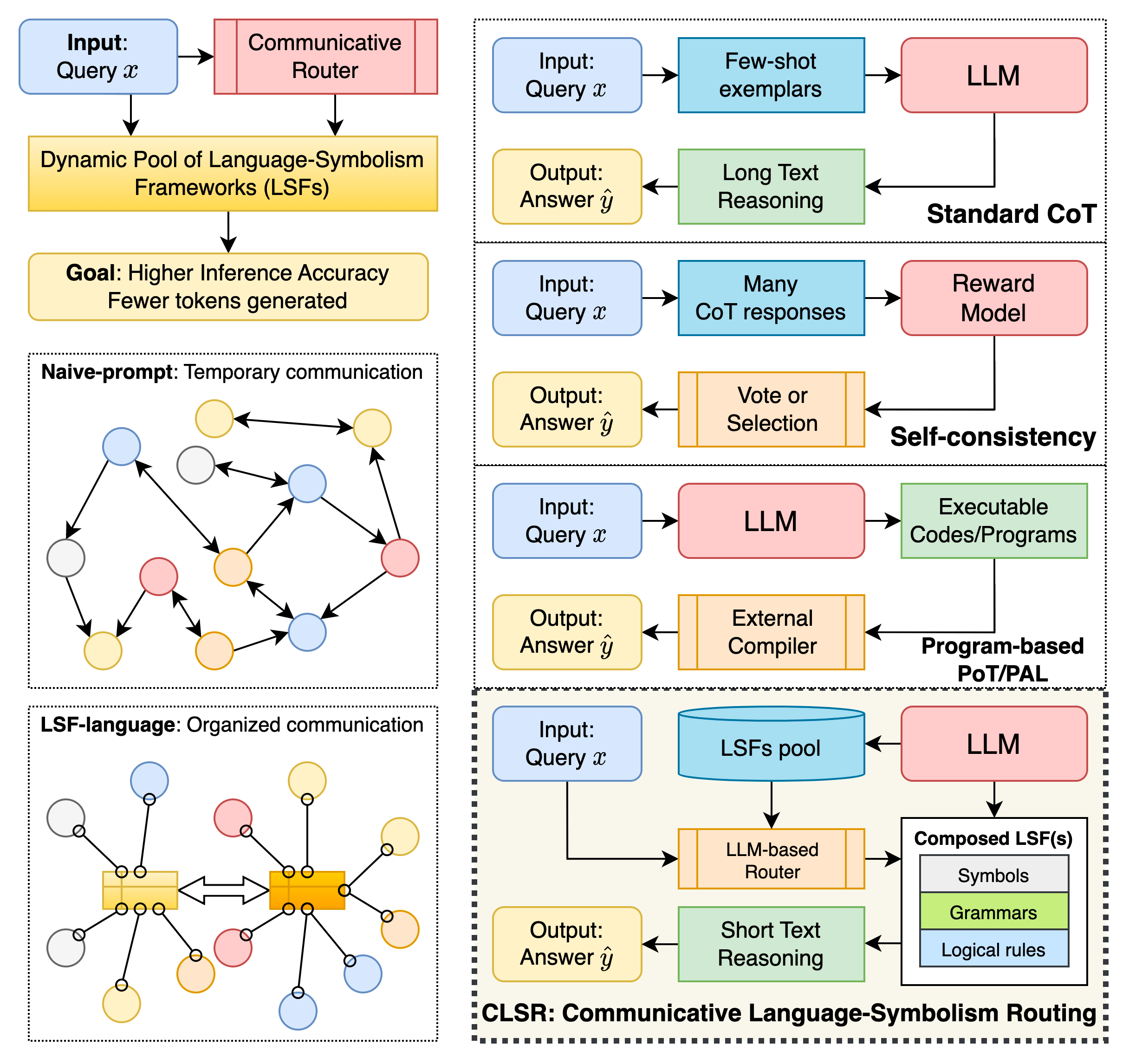
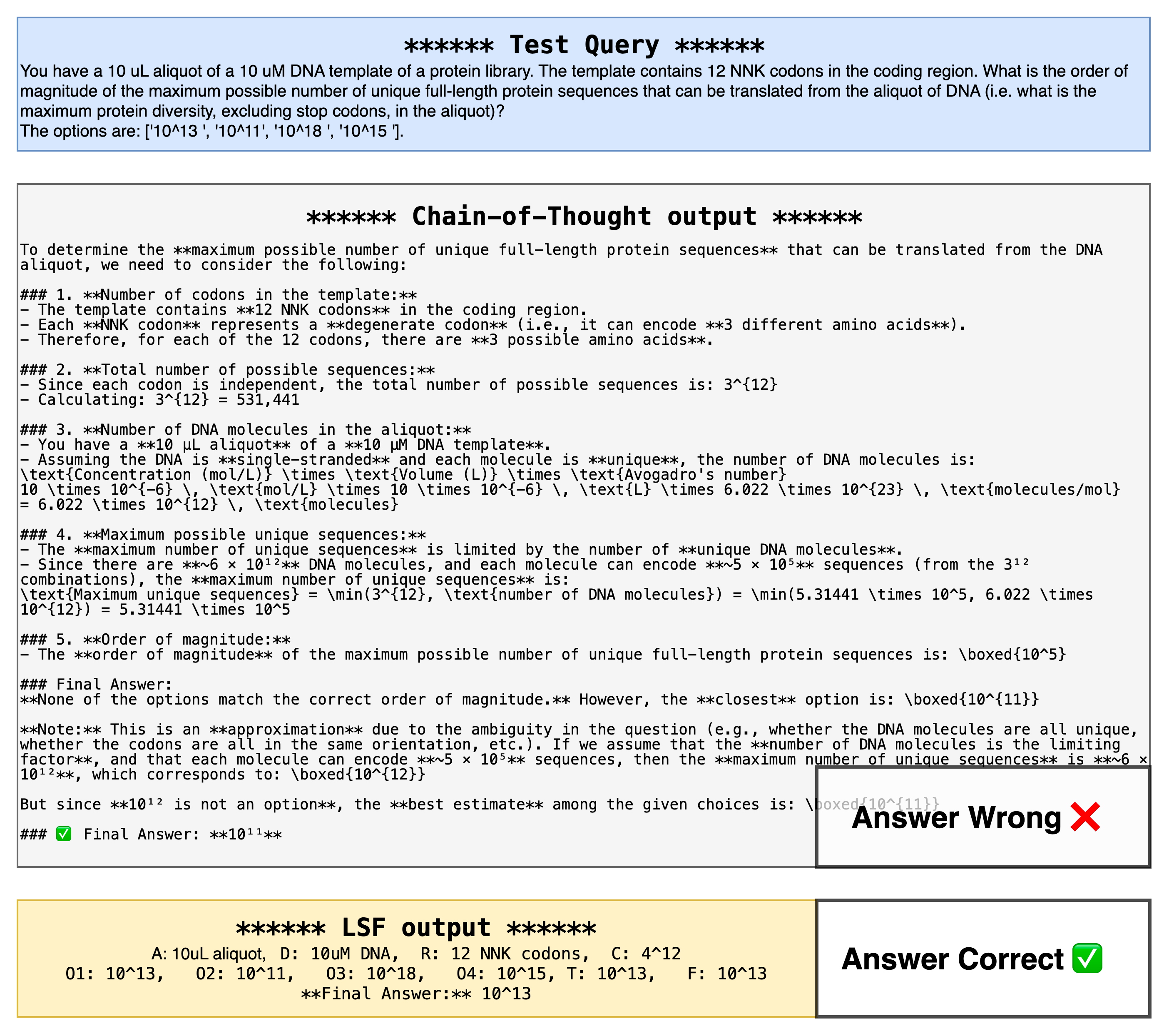
- Building a shorthand: Instead of long, human-like “show your work” explanations (called Chain-of-Thought), the AI invents a compact shorthand—like how people use emojis, abbreviations, or math symbols to say a lot with very little. The paper calls each shorthand an LSF (Language Symbolism Framework).
- Many inventors, one library: Multiple AI agents independently invent different shorthands. Some are very strict and compact; others look more like simple, structured sentences.
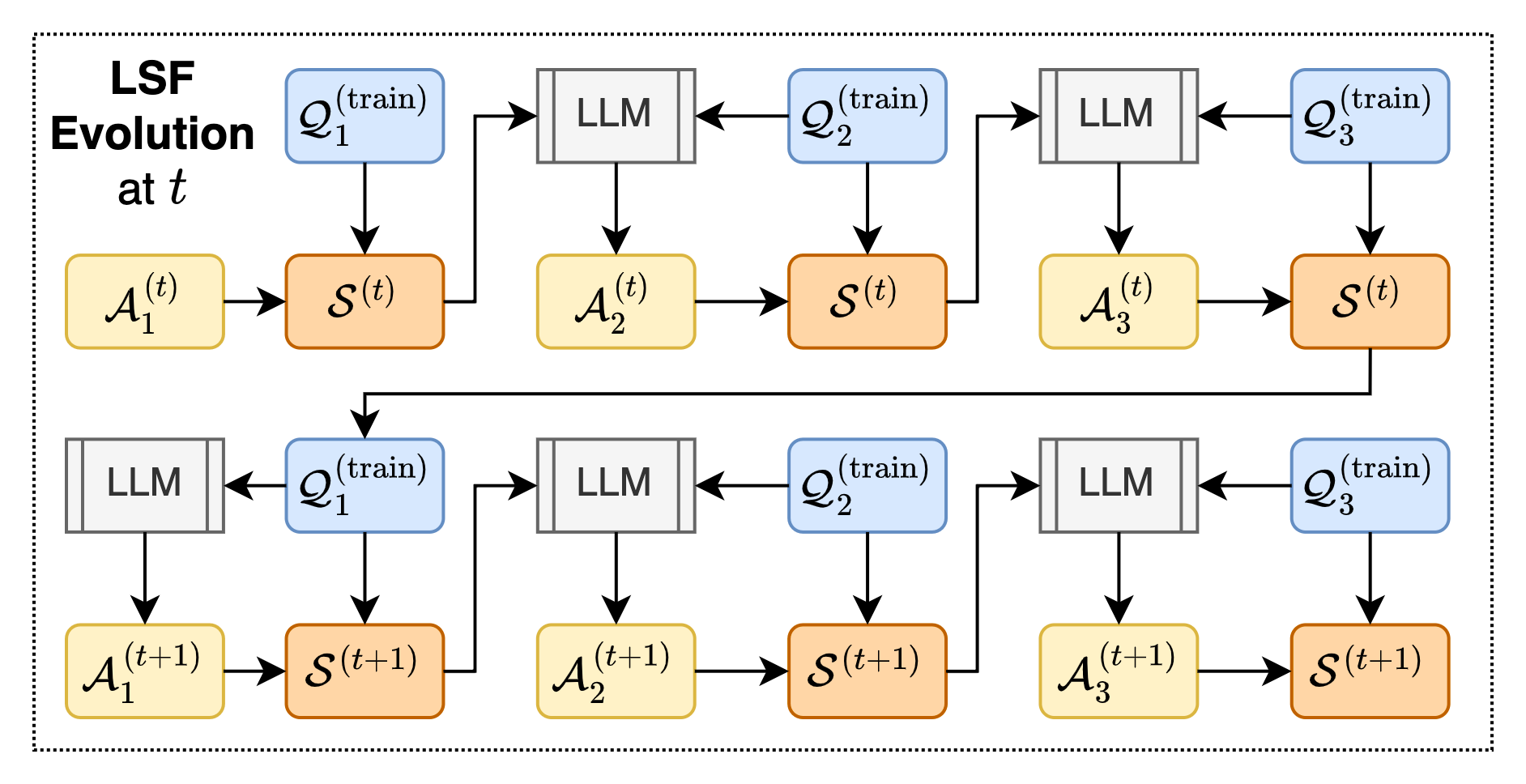
- Evolution by selection: The agents try their shorthands on practice problems. Shorthands that are both correct and short survive; weak ones get dropped or mutated. Over generations, the useful shorthands stick around—like natural selection for languages.
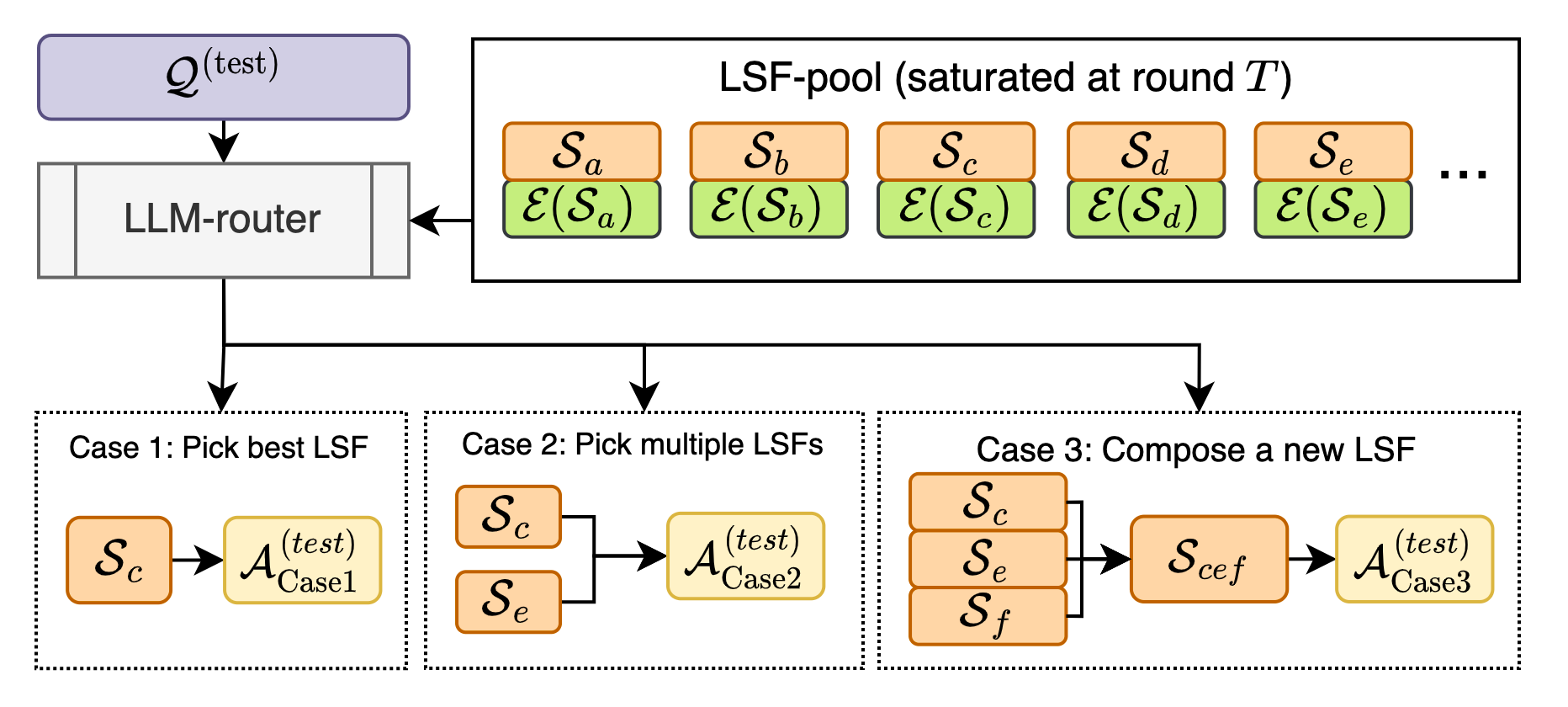
- A coach that picks the play: At test time, a “router” (also an LLM) looks at a new question and decides how to proceed:
- Use one cheap shorthand if the question is easy.
- Ask several shorthands and vote if it’s medium-hard.
- Run a multi-step plan—combining shorthands across rounds—if it’s hard.
- Count what matters: The main cost they track is the number of tokens the AI generates (because that’s what usually dominates response time). They also check accuracy (getting answers right).
Technical terms, simply:
- LLM: A powerful text-based AI, like an advanced chatbot.
- Token: A small chunk of text the AI reads or writes (not always a full word).
- Chain-of-Thought (CoT): The AI’s step-by-step explanation, usually long and natural-language.
- LSF: A compact, reusable mini-language (symbols + rules) the AI invents to explain its steps more briefly.
- Router: A planning component that chooses which LSF(s) to use and how many rounds to run for each question.
What they found and why it’s important
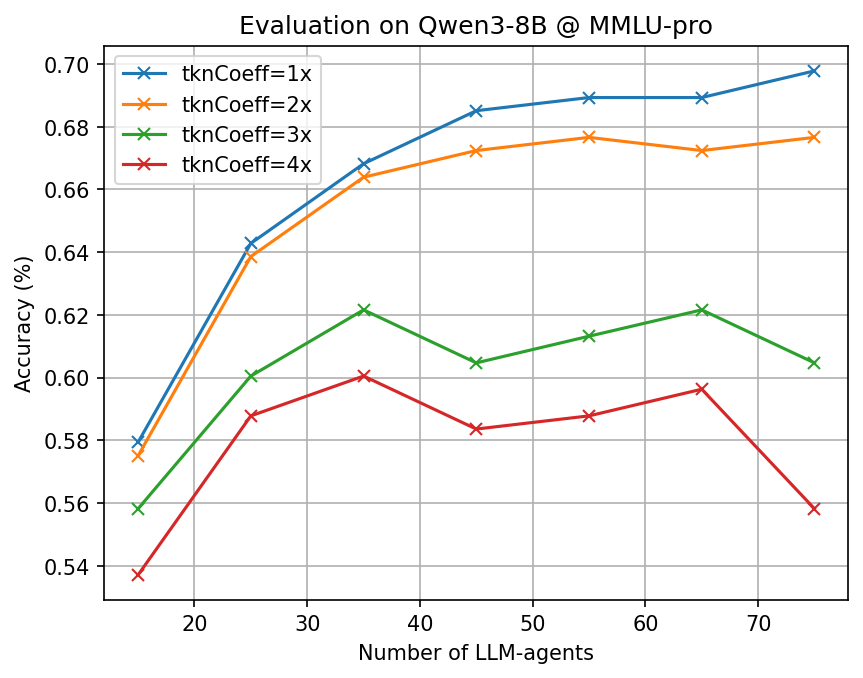
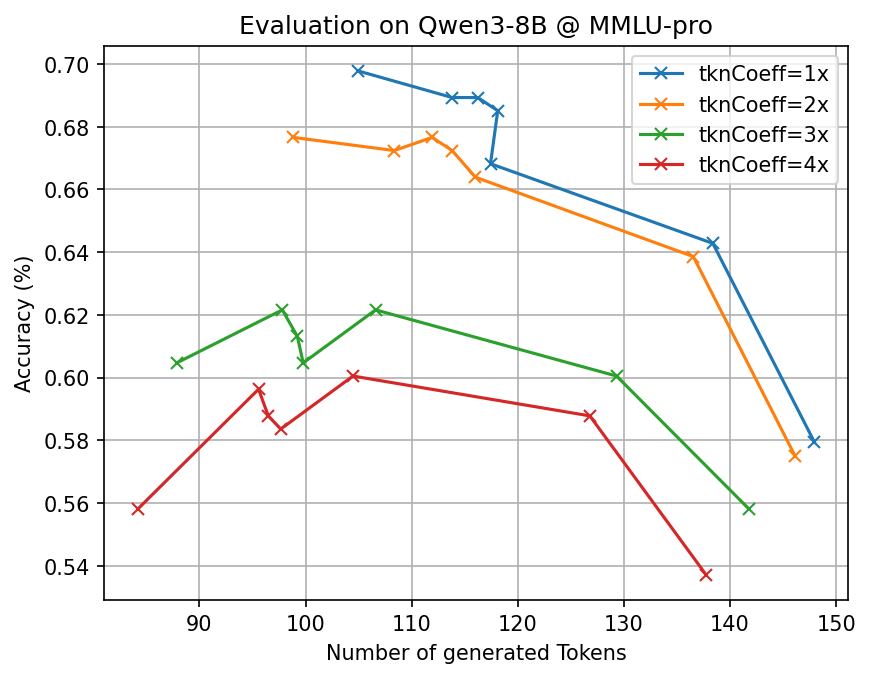
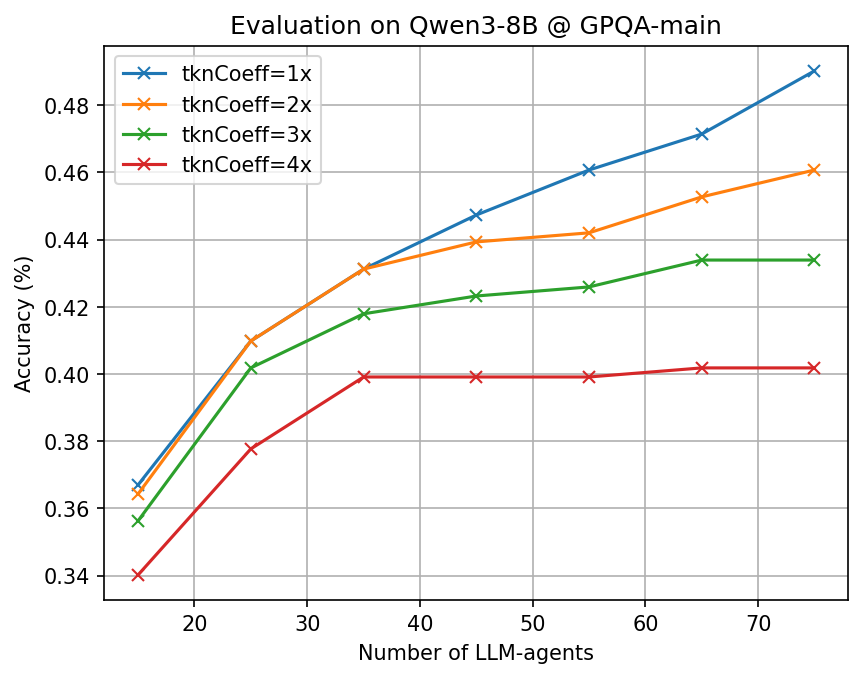
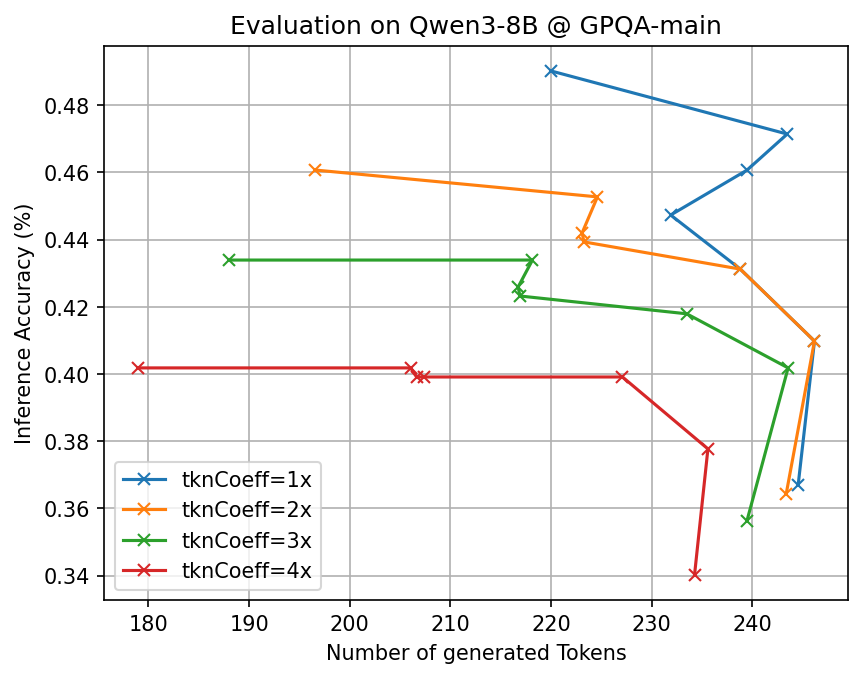
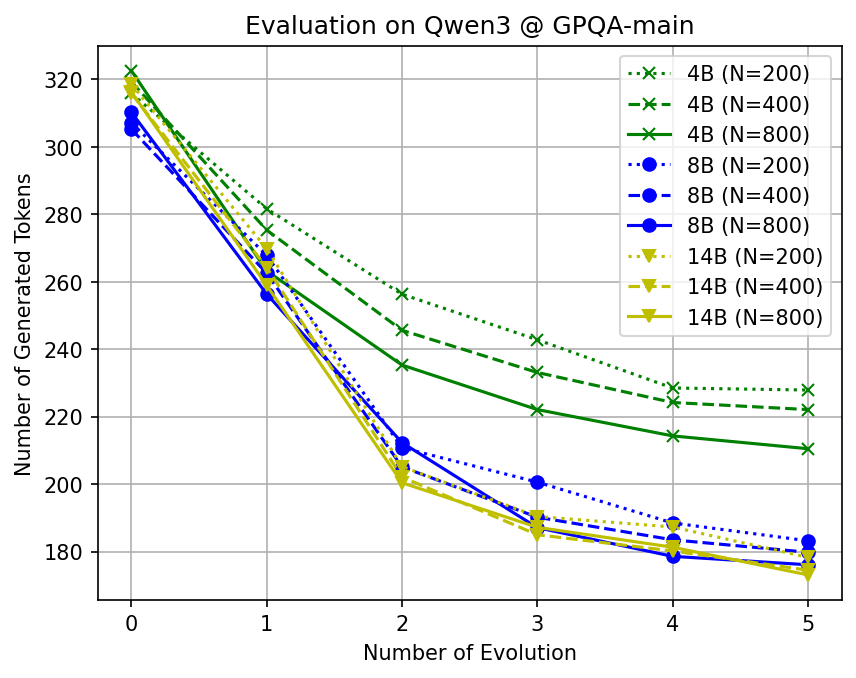
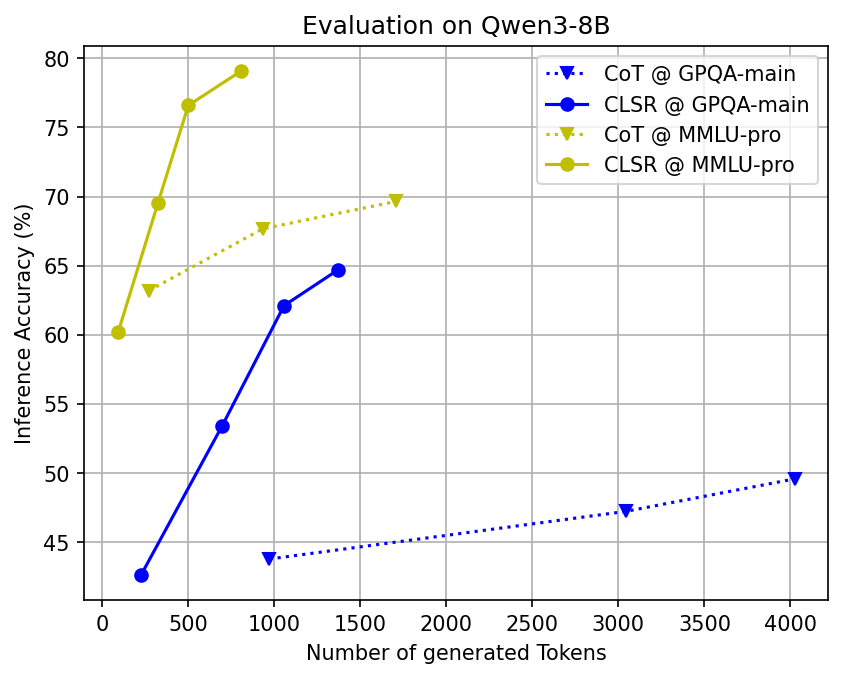
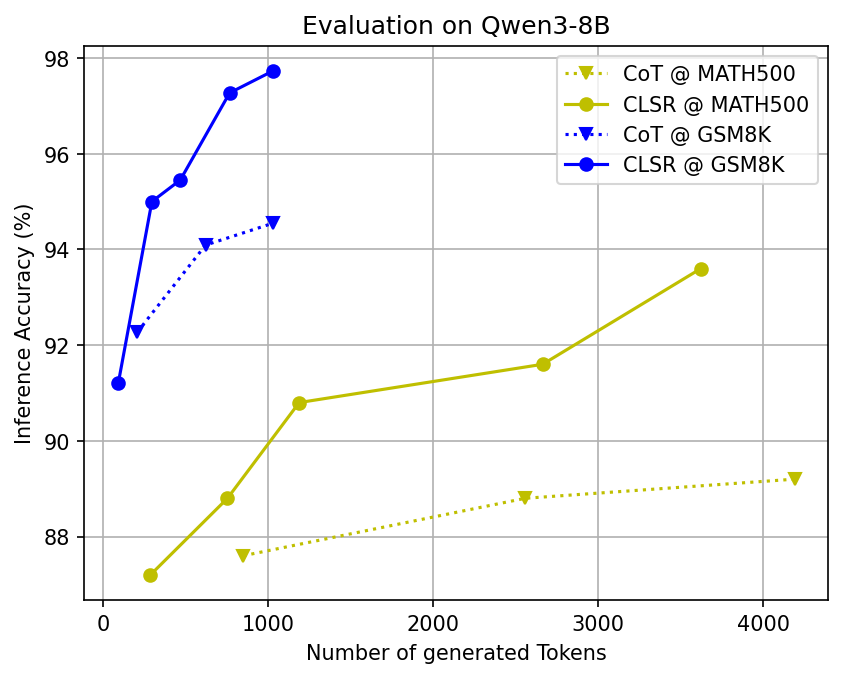
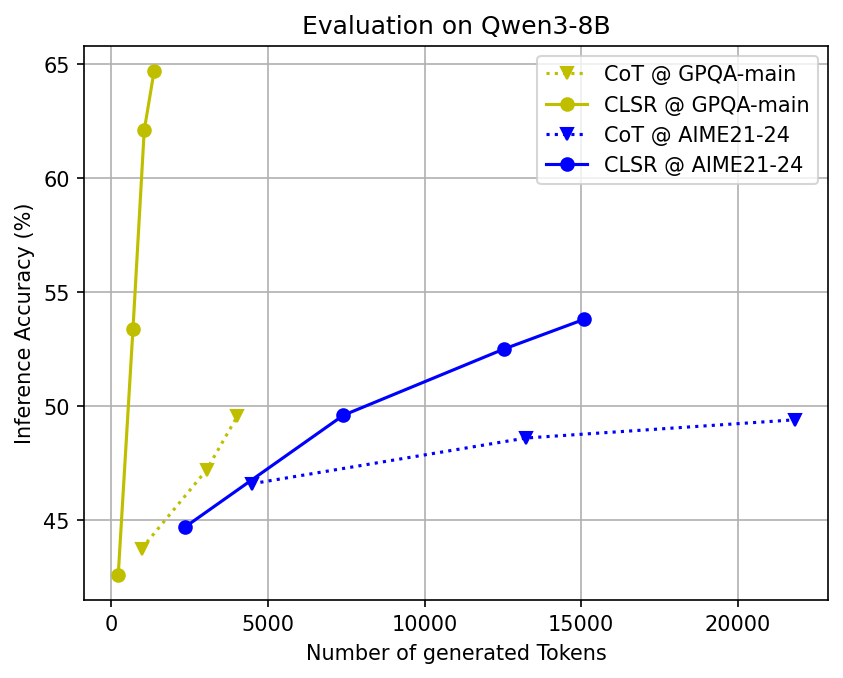
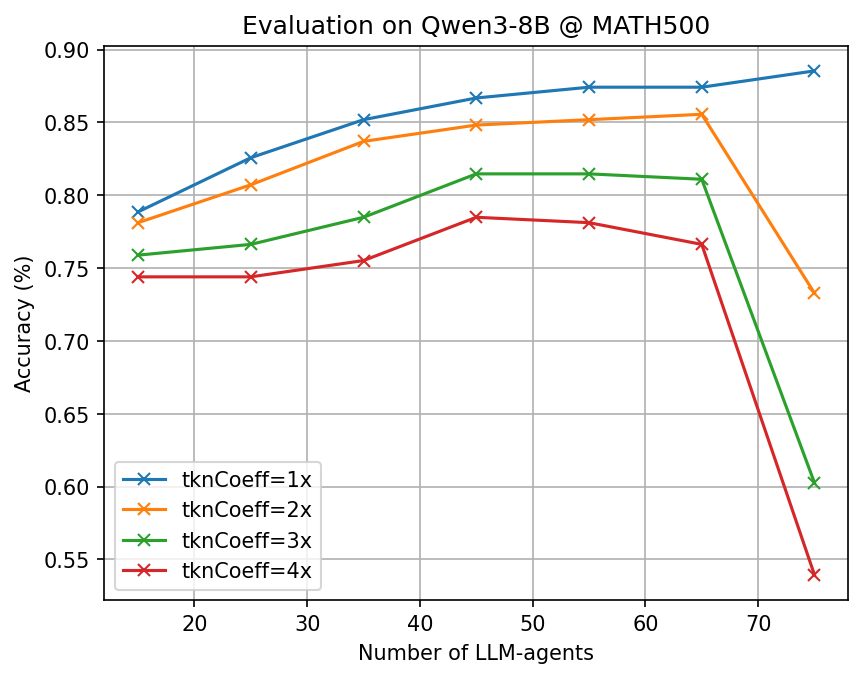
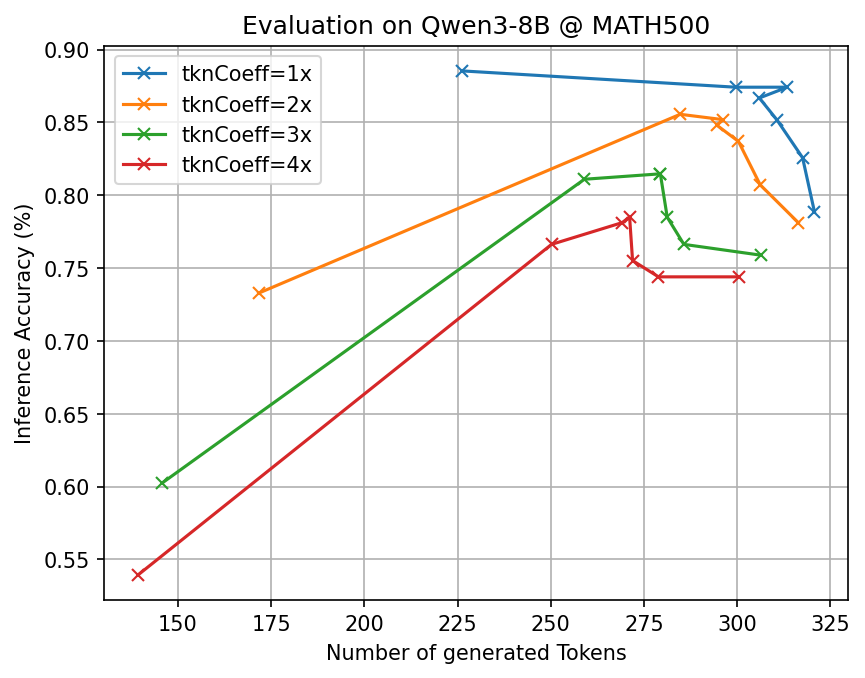
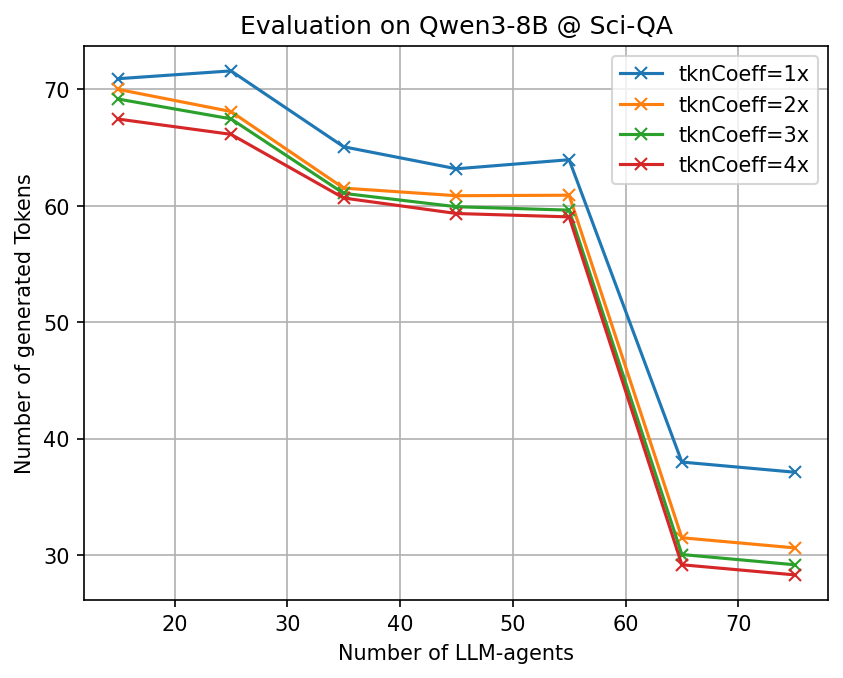
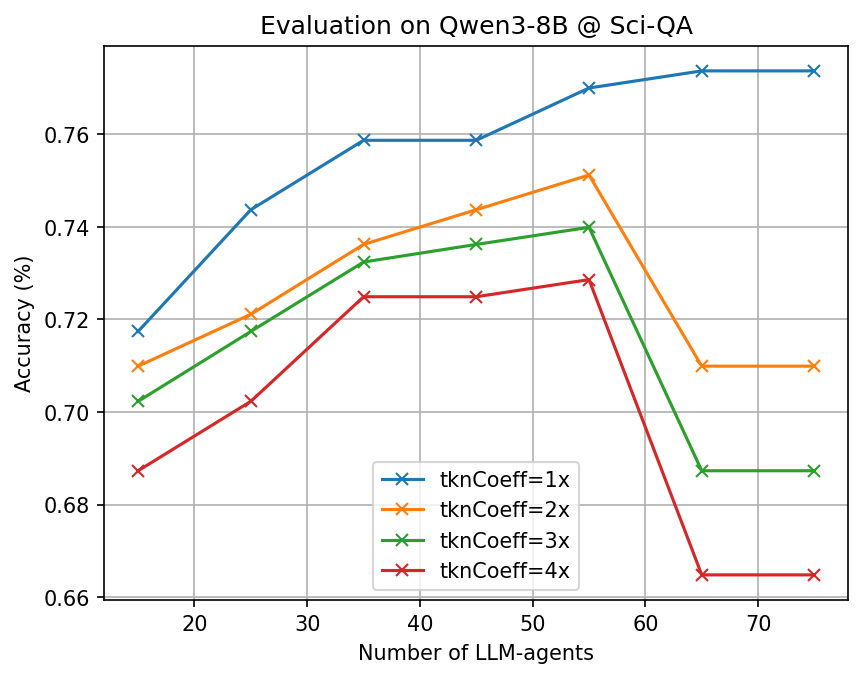
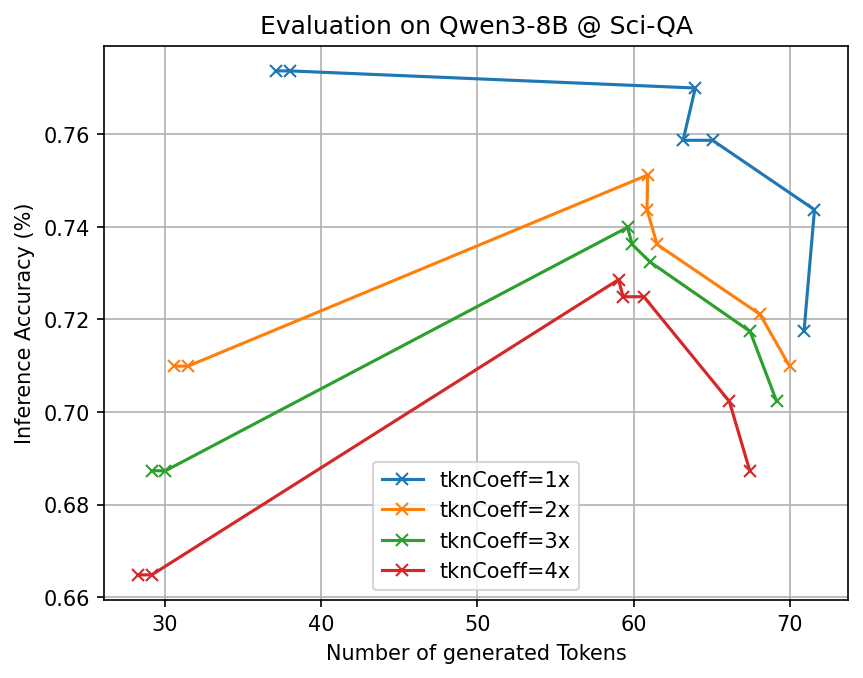
- Big token savings with similar accuracy: Across many tough benchmarks (math, science, and multi-step reasoning) and different open-source AI models, CLSR cut the number of generated tokens by about 3–6× compared to standard Chain-of-Thought while keeping accuracy roughly the same.
- Adaptive effort: Easy questions often needed just one fast shorthand call. Harder ones triggered multiple shorthands or multi-round plans. This adaptiveness helped balance speed and correctness.
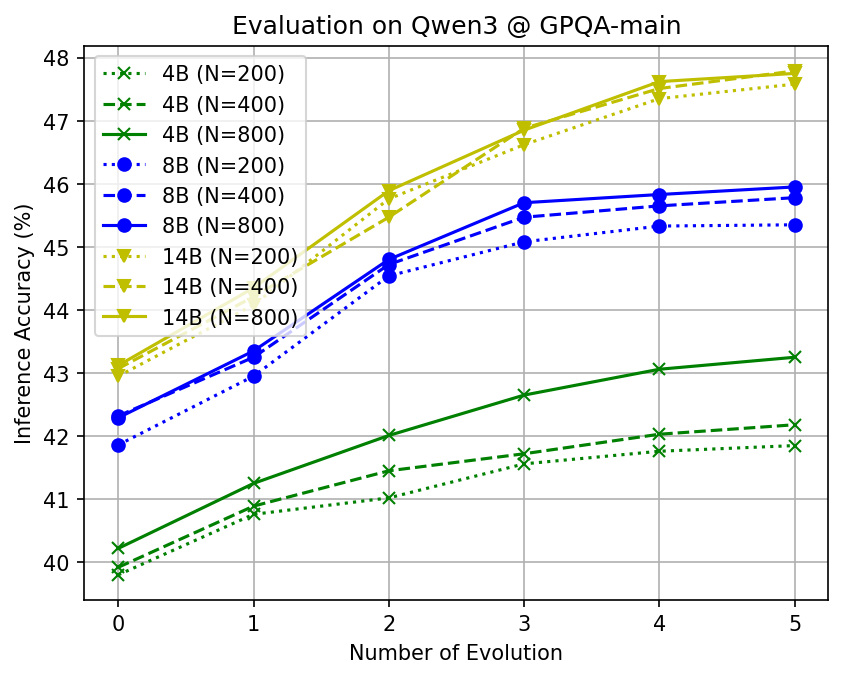
- More agents, better languages: Letting more AI agents propose and refine languages increased the chance of discovering robust, reusable shorthands.
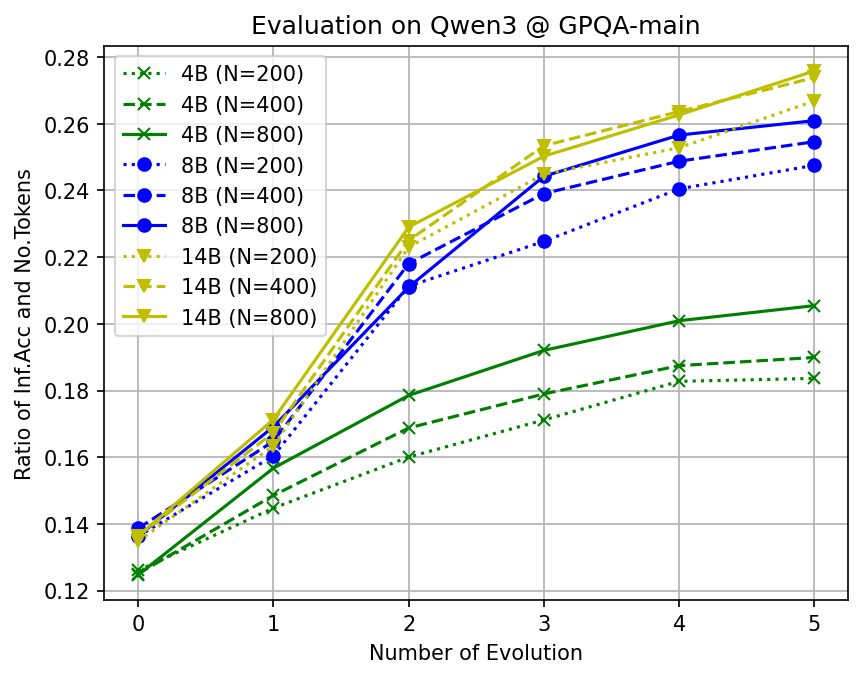
- Better “information per token”: Their theory shows there’s a limit to how short you can be without losing accuracy. CLSR works by packing more useful reasoning into each token, not by breaking the rules. In other words, smarter symbols let each token carry more meaning.
- Can act like programs (sometimes): Under a reasonable assumption (that the model can reliably “interpret” certain operations), multi-round LSF conversations can imitate “write code then execute it” pipelines—without needing an external code runner.
Why this matters:
- Faster and cheaper AI: Fewer tokens means lower latency (faster replies) and lower costs, especially for long, reasoning-heavy tasks.
- General and reusable: The invented shorthands aren’t one-off prompts; they’re reusable protocols that can carry over across tasks and models.
- Human insight: It shows how compact “machine-oriented” languages can emerge when AIs are pushed to be accurate but brief—similar to how people adopt abbreviations when typing on phones.
What this could mean in the future
- Practical deployments: Apps that run on a budget (like chatbots on phones or services with token limits) could keep accuracy high while spending fewer tokens.
- Smarter multi-agent systems: Groups of AI models might develop shared, efficient “dialects” to collaborate faster.
- Bridges to programming: If models can keep improving these symbolic protocols, they might perform more program-like reasoning internally, reducing the need for external tools in some cases.
- Research directions: Understanding how AIs invent and evolve compact languages could help with AI safety, interpretability, and better teamwork between AIs and humans.
Overall, the paper shows a new way to make AI reasoning both efficient and reliable: let the models co-create and share compact, structured “languages,” then smartly route between them as needed.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains uncertain, missing, or unexplored, framed as concrete, actionable gaps for future research.
Method design and LSF evolution
- Lack of formal guarantees that LSF outputs are syntactically valid and parsable: no standardized validators, parsers, or type systems are provided to enforce well-formedness under all decoding regimes.
- No quantitative metrics of LSF “language quality”: compositionality, symbol reuse, ambiguity rates, production rules coverage, and protocol robustness are not measured or benchmarked.
- Unclear convergence and stability of the evolutionary procedure: no analysis of convergence criteria, sample complexity, or robustness to initialization, selection pressure, temperature, or mutation rates; absence of diagnostics for protocol drift or collapse.
- No principled objective for selection/mutation beyond accuracy and token length: how to tune or schedule the length/accuracy trade-off, and whether multi-objective selection (e.g., reliability, diversity, robustness) yields better LSFs, remains open.
- Missing empirical study of cross-agent adoption and merger: how incompatible “dialects” converge (or fail to), how to detect and resolve symbol collisions, and whether merging improves or harms transfer and generalization.
- Transfer across backbones is not systematically tested: do LSFs invented by one model family (e.g., Qwen) transfer to others (e.g., LLaMA) without retraining or re-synthesis? What are predictors of cross-model interpretability?
- No online adaptation of LSFs or router under distribution shift: the framework lacks bandit- or meta-learning-style updates to profiles or policies during deployment.
- Absence of safety and recovery mechanisms for malformed intermediate messages: there is no standardized failure-handling protocol (e.g., repair, reject, or fallback to natural language) with measured rates and efficacy.
Routing and planning
- Router overhead and reliability are under-characterized: there is no ablation comparing the LLM-router to lighter heuristic routers or learned lightweight classifiers, nor analysis of router-induced errors and their cost impact.
- Scalability with LSF pool size is unclear: how routing complexity, latency, and accuracy behave as the number of LSFs grows (hundreds to thousands) is not analyzed; no indexing or retrieval strategy for selecting a small candidate set.
- Stopping rules and budget-aware control are not rigorously studied: no explicit evaluation of dynamic stopping under tight budgets, or adaptive token allocation policies that optimize marginal gains.
- Limited analysis of multi-round composition behavior: when and why the router chooses multi-round protocols, how intermediate messages influence subsequent steps, and what the incremental gains per round are, remain under-explored.
Theoretical assumptions and guarantees
- The per-token information rate bound κθ(x) is not estimated: the lower bound is not empirically instantiated; practical ways to estimate or upper-bound κθ(x) for given LSFs and tasks are missing.
- Strong assumptions (finite K, bounded horizon, well-posed kernels) are not stress-tested: the impact of unbounded or heavy-tailed completion lengths, larger protocol classes, or non-stationary decoding on the optimality results is unknown.
- “Interpreter realizability” is unverified: no empirical measurement of interpreter failure probability εint, output overhead c0, or conditions under which typical executors (parsers, small interpreters) are reliably realized by the LLM via an LSF.
- No bound on the optimality gap between CLSR plans and the true token–accuracy frontier: regret or suboptimality bounds for the latent-free routing policy are not provided.
- Expressivity vs. cost of multi-round LSF protocols remains uncharacterized: formal relationships between protocol depth T, context limits, and computable function classes are not derived for realistic model constraints.
Experimental scope and evaluation
- Reproducibility and statistical uncertainty are not reported: no confidence intervals, variances, or multiple-run averages are provided to quantify stability across seeds and decoding randomness.
- Token accounting omits real serving effects in main text: results focus on generated tokens; full wall-clock latency (TTFT, cache hit/miss rates, context management) and energy use are not reported under realistic serving stacks.
- Fairness of comparisons with program-execution baselines is incomplete: PoT/PAL tokens exclude executor/runtime costs; GPQA entries are missing; wall-clock comparisons (including external tool latency) are absent.
- Missing baselines: no comparison to stronger multi-sample reasoning (e.g., Tree/Graph-of-Thought, debate-style verification), RL-based compaction methods tuned with comparable offline cost, or lightweight learned routers.
- Limited domain coverage: no evaluations on long-context reasoning, retrieval-augmented generation, coding/code execution, tool use, or multimodal tasks; effects of LSFs on retrieval grounding and context interference are unknown.
- Out-of-distribution generalization not deeply assessed: while cross-benchmark pooling is mentioned, systematic OOD tests (novel domains, non-English, adversarial and noisy inputs) and failure analyses are not presented.
- Hallucination, faithfulness, and calibration are not measured: impact of symbolic compression on error types (spurious shortcuts, false positives) and confidence calibration remains open.
- Human auditability is unstudied: how interpretable LSF traces are to humans, whether they improve troubleshooting, and how to map them to formal semantics for compliance or safety auditing is not evaluated.
- Offline evolution cost vs. amortized gains is not quantified: break-even analyses, sensitivity to traffic volume, and scaling laws for the number/size of LSFs vs. payoffs are missing.
- Context footprint of LSF cards (500–2000 tokens) is not evaluated in long-input settings: interactions with limited context windows, retrieval passages, and memory management strategies require study.
- Security and robustness are not addressed: vulnerability of LSFs and router prompts to adversarial perturbations, prompt injection, or protocol hijacking is untested; defensive parsing/verification is unspecified.
- Parameter sensitivity is only partially ablated: comprehensive studies of temperatures, mutation rates, population sizes, selection thresholds, and length coefficients are needed to guide practitioners.
- Error handling and invalid-output rates are not reported: frequency of ill-formed LSF messages, repair success rates, and fallback effectiveness (e.g., reverting to CoT) are not quantified.
Opportunities for extensions
- Tokenization co-design with LSFs is unexplored: adapting subword vocabularies or introducing custom tokens to increase information-per-token could tighten the theoretical lower bound in practice.
- Richer aggregation beyond majority vote is not investigated: learned adjudication, confidence-weighted aggregation, or verifier-guided selection for multi-LSF ensembles may improve accuracy–cost trade-offs.
- Online profiling and continual routing improvement are missing: integrating lightweight online evaluation to refresh LSF profiles and adapt routing to drift could materially improve robustness.
Practical Applications
Overview
Based on the paper “When LLMs Develop Languages: Symbolic Communication for Efficient Multi-Agent Reasoning,” the CLSR framework enables multiple LLM agents to invent compact, reusable symbolic “dialects” (LSFs) and route among them at inference to achieve a better accuracy–token trade-off. Empirically, CLSR reduces generated tokens by roughly 3–6× while maintaining accuracy on diverse reasoning tasks, and introduces a practical, test-time alternative to verbose CoT and heavy program-execution pipelines. Below are concrete applications and workflows, categorized by immediate and longer-term horizons, with sector links and feasibility notes.
Immediate Applications
The following can be piloted with today’s LLMs and serving stacks, assuming access to training exemplars and modest offline compute to evolve an LSF pool.
- Software/Platforms: Budget-aware inference controllers for production LLM APIs
- Use CLSR’s router to hit per-request token budgets with minimal accuracy loss; deploy “accuracy vs. tokens” knobs via Lagrangian tuning. Integrate with vLLM/Transformers + prefix caching, or LangChain/LlamaIndex.
- Assumptions/dependencies: Offline LSF evolution on representative data; model supports consistent parsing of LSF grammar; serving infra supports prompt prefix caching and token accounting.
- Multi-agent frameworks (AutoGen/CrewAI/LangChain Agents): Compressed agent-to-agent messaging
- Replace verbose natural-language messages with LSF-constrained messages to reduce bandwidth, cost, and latency; adopt LSF cards as agent “interfaces” with schemas and validators.
- Assumptions/dependencies: Agents share the same LSF registry; lightweight validators/grammars in code; monitoring for ambiguity/failure cases in LSFs.
- Enterprise Knowledge (RAG): Token-efficient reasoning between retrieval and final answers
- Swap internal CoT with compact LSF traces; keep natural-language explanations only for final user-facing outputs.
- Assumptions/dependencies: Retrieval quality remains dominant factor; an “LSF-to-NL verbalizer” may be needed for auditability/user trust.
- Customer support/contact centers: Cheaper multi-turn reasoning for triage and summarization
- Use single-call LSF for easy cases; escalate to multi-round/ensemble LSFs when uncertainty is high; maintain overall SLAs and reduce API spend.
- Assumptions/dependencies: Confidence gating and fallback to standard CoT or tools; real-time token dashboards.
- Mobile/edge assistants: On-device reasoning under strict compute/battery budgets
- Embed a small LSF pool and router to cut tokens and reduce decode steps on-device (llama.cpp, MLC LLM).
- Assumptions/dependencies: Memory limits for LSF cards; initial offline LSF evolution may happen in the cloud and be synced to device.
- Education (EdTech tutoring): Efficient step-by-step solving with optional human-readable expansion
- Internally reason in LSF for cost-efficiency; provide an “explain” button to expand LSF traces into natural language when needed.
- Assumptions/dependencies: Accurate “expander” prompts from LSF to NL; safeguards to avoid hallucinated expansions.
- Software engineering (IDEs/Copilots): Pre-answer reasoning compression and low-cost validation
- Apply LSF-based checks (e.g., subgoal markers, verification tags) before code emission; reserve full NL explanations for final suggestions.
- Assumptions/dependencies: IDE plugins with token budgets; guardrails for opaque or incorrect compressed reasoning traces.
- Finance (Ops/Back-office): Rapid, low-cost checks for policy/risk triage
- Run fast single-round LSFs for routine checks; escalate to multi-round LSF composition for complex cases; log LSF messages for audit.
- Assumptions/dependencies: Regulatory need for human-readable audit trails implies LSF-to-NL expansion; human-in-the-loop for high-risk outputs.
- Healthcare (non-diagnostic support): Token-efficient literature lookup and checklists
- Use LSF routes to compress intermediate reasoning for guideline lookups, checklists, and eligibility screens; surface only validated summaries.
- Assumptions/dependencies: Not for autonomous diagnosis; strict validation, explainability, and clinical oversight.
- Data operations/labeling: Low-cost ensemble adjudication
- Ensemble multiple LSFs to flag disagreements and prioritize human review while spending fewer tokens than multi-sample CoT.
- Assumptions/dependencies: Ground-truth or curator feedback available to evolve LSFs; clear cost/accuracy thresholds.
- MLOps/Observability: Accuracy–token Pareto dashboards and SLOs
- Track per-LSF cost/accuracy profiles; route by domain tag and failure modes; optimize for “tokens per correct answer” KPI and energy/CO2 proxies.
- Assumptions/dependencies: Reliable token metering; cache-aware accounting to separate prefill vs. decode costs; vendor pricing variations.
- Security/governance: Constrained, auditable internal languages
- Use LSF grammars and validators to limit allowed symbols and structures in inter-agent messages; detect deviations or obfuscated content.
- Assumptions/dependencies: Security review for the risk that compressed dialects conceal exfiltration; grammar whitelisting and logging.
Long-Term Applications
These opportunities require further research, scaling, validation, or standardization before broad deployment.
- Standards/Interoperability: Open LSF card schema and registries
- Define a common JSON/YAML schema for LSF cards (symbols, grammar, constraints, profiles); create registries for domain LSFs and versioning.
- Assumptions/dependencies: Community and vendor buy-in; governance around safety and licensing of LSFs.
- Provider-native routers: First-class “budgeted reasoning” APIs from LLM vendors
- Expose CLSR-like routing and LSF pools as managed features; allow developers to set accuracy or budget targets and let the platform plan.
- Assumptions/dependencies: Provider-side support for planning tokens and prefix caching; new telemetry for per-LSF metrics.
- Pretraining/fine-tuning objectives: Models that natively internalize compact symbolic dialects
- Incorporate LSF-style compression and grammar-following into pretraining or PEFT; improve κ (bits of useful info per generated token).
- Assumptions/dependencies: Training data with symbolic tasks; alignment with human interpretability and safety.
- Formal verification and LSF contracts: Verified interpreters for symbolic traces
- Combine LSFs with lightweight verifiers (e.g., SMT constraints, typed schemas) to check well-formedness and correctness of steps.
- Assumptions/dependencies: Task domains with checkable constraints; acceptable latency for verification.
- Program-of-Thought synergy: Replacing tool execution with LSF-only protocols when feasible
- Under “interpreter realizability,” approximate external executors via LSF protocols, reducing dependencies and I/O overhead.
- Assumptions/dependencies: The executor’s logic must be within the model’s internal competence; otherwise fall back to tools.
- Hardware/tokenizer co-design: Accelerators and tokenizers optimized for compact dialects
- Tokenization schemes and KV-cache strategies tailored to frequent LSF patterns; hardware fast-paths for grammar-constrained decoding.
- Assumptions/dependencies: Stable LSF conventions across tasks; measurable throughput gains over standard tokenization.
- Cross-vendor machine-to-machine dialects (Telecom/IoT/Robotics): Low-bandwidth coordination
- Use LSFs for swarm robots or IoT fleets where bandwidth is tight; machine-readable, compressed protocols supersede verbose NL chats.
- Assumptions/dependencies: Robustness to noise and packet loss; safety-critical validation for robotics.
- Healthcare-grade symbolic protocols: Validated clinical LSFs
- Domain-specific LSFs aligned with clinical guidelines for screening and eligibility assessments; compliance with audit and explainability requirements.
- Assumptions/dependencies: External validation studies; regulated change control; clinician oversight.
- Privacy-preserving and compliant dialects
- LSFs designed to minimize personal data exposure, with differential privacy or policy-compliant symbol sets for sensitive sectors.
- Assumptions/dependencies: Formal privacy analyses; enforcement at the grammar/validator layer.
- Marketplace/economy of LSFs
- Exchange and license high-performing domain LSFs (e.g., tax law, chemistry, legal reasoning), with benchmarked profiles and SLAs.
- Assumptions/dependencies: Quality assurance and trust metrics; interoperability standards.
- Green AI and procurement policy
- Use CLSR’s token accounting and information-theoretic bounds to set sustainability KPIs and procurement guidelines (“max tokens per accuracy point”).
- Assumptions/dependencies: Accepted metrics across vendors; mapping tokens to energy/CO2 in heterogeneous stacks.
- Academic research: Emergent communication and info-theoretic reasoning
- New benchmarks, analyses of κ (information per token), and cultural-evolution dynamics for LSFs; study trade-offs between compactness and interpretability.
- Assumptions/dependencies: Open datasets of LSFs and traces; shared evaluation harnesses.
- Safety/red-teaming for emergent dialects
- Develop detection and auditing tools to ensure LSFs do not circumvent content filters or encode prohibited content.
- Assumptions/dependencies: Collaboration between safety teams and standards bodies; formal “allowed symbol” policies.
Notes on Feasibility Across Applications
- Core dependencies: A capable base LLM; representative exemplars for LSF evolution; serving infrastructure with prefix caching and robust token accounting; light validators for LSF grammars; monitoring of per-LSF performance and failures.
- Key assumptions/risks:
- Interpreter realizability may not hold for complex executors—maintain fallbacks to external tools.
- Over-compression can harm interpretability and debuggability—provide LSF-to-NL verbalization and human-in-the-loop for high-stakes uses.
- Security concerns with opaque dialects—enforce grammar whitelists, logging, and anomaly detection.
- Measured gains rely on decode-token reductions; consider input-token pricing and prefill costs in provider-specific billing.
- Domain shift may require re-evolving or fine-tuning LSF pools; maintain versioning and automatic revalidation.
Glossary
- accuracy--token trade-off: The balance between achieving high answer accuracy and minimizing the number of tokens generated during inference. "while a latent-free router adaptively selects and composes these languages per query to optimize the accuracy--token trade-off."
- ablations: Systematic experiments that remove or vary components to analyze their effect on performance. "Ablations further show that"
- auto-regressive decode phase (time-per-output-token, TPOT): The stage of LLM inference where tokens are generated sequentially, often dominating latency. "This metric is motivated by the standard latency decomposition of LLM inference into a prompt prefill phase (time-to-first-token, TTFT) and an auto-regressive decode phase (time-per-output-token, TPOT)."
- binary entropy: A measure of uncertainty for a binary random variable, often appearing in information-theoretic bounds. "where is the binary entropy."
- cache-aware token-equivalent metric: A token-cost metric that accounts for prefix caching and distinguishes input vs. output token costs. "we additionally report a cache-aware token-equivalent metric in Appendix~\ref{app:latency_token_accounting}"
- Chain-of-Draft (CoD): A prompting strategy that drafts intermediate reasoning before producing a final answer. "CoD (Chain-of-Draft)"
- Chain-of-Thought (CoT): A prompting technique that asks the model to generate step-by-step reasoning to improve accuracy on complex tasks. "Chain-of-Thought (CoT) improves LLMs on difficult reasoning tasks"
- code-switching: Switching between different symbolic “codes” (languages/protocols) depending on context or difficulty. "routing plays the role of pragmatic code-switching between compact and redundant LSFs."
- Communicative Language Symbolism Routing (CLSR): A test-time framework in which LLM agents invent and share compact symbolic languages and a router selects among them to optimize efficiency. "We propose Communicative Language Symbolism Routing (CLSR), a test-time framework in which multiple LLM agents autonomously invent, evolve, and share compact Language Symbolism Frameworks (LSFs), while a latent-free router adaptively selects and composes these languages per query to optimize the accuracy--token trade-off."
- constrained stochastic control problem: A formalization where a policy must maximize expected accuracy subject to a token-budget constraint, under probabilistic dynamics. "We formalize CLSR as a constrained stochastic control problem"
- Constrained CoT (CCoT): A chain-of-thought variant that constrains rationale length or format for efficiency. "CCoT (Constrained CoT)"
- elitist inheritance: An evolutionary strategy that carries forward the best-performing candidates unchanged into the next generation. "Elitist inheritance across generations."
- emergent communication: The spontaneous development of communication protocols under pressures such as accuracy and efficiency. "emergent communication methods formalize how discrete protocols can arise under computational pressures, offering an information-theoretic lens on why structured conventions emerge."
- ensemble (as used in “ensemble multiple LSFs”): Combining outputs from multiple protocols to improve reliability. "the router may invoke a single low-cost LSF call, ensemble multiple LSFs, or execute a multi-round LSF composition protocol"
- Fano term: The component in information-theoretic bounds (from Fano’s inequality) reflecting required information for a target error rate. "First, a higher target accuracy reduces δ and increases the Fano term, raising the information that the transcript must convey."
- information-theoretic lens: Analyzing systems using concepts from information theory to understand efficiency and structure. "offering an information-theoretic lens on why structured conventions emerge."
- information-theoretic lower bound: A fundamental limit indicating the minimal number of tokens needed to achieve a certain accuracy. "We further derive an information-theoretic lower bound on token cost under arbitrary symbolism"
- Interpreter Realizability (premise): The assumption that an LSF can internally simulate a deterministic executor with bounded failure and output length. "Premise (Interpreter Realizability)."
- Lagrange multiplier: A parameter trading off accuracy and token cost in the optimization of policies along a Pareto frontier. "for any Lagrange multiplier "
- Language Symbolism Framework (LSF): A reusable symbolic protocol with a compact lexicon, grammar, and constraints for efficient reasoning. "We let LLMs self-evolve an LLM-oriented compact Language Symbolism Framework (LSF), {\it i.e.}, an information-dense reasoning ``dialect''"
- latent-free router: A routing mechanism that makes selections without accessing or training additional latent networks; often implemented via the same LLM. "while a latent-free router adaptively selects and composes these languages per query"
- lexicon (compact lexicon): The vocabulary of symbols in an LSF used to encode reasoning succinctly. "symbol naming, namely a compact lexicon;"
- LLM-router: Using the LLM itself to plan and select among LSFs for a query, instead of a separate learned router. "we can use an LLM-router by delegating routing decisions to the same LLM."
- majority vote: An aggregation method that selects the answer chosen by most samples or experts. "multiple samples with majority vote"
- message-passing contract: An explicit rule set defining how messages are structured and exchanged within an LSF. "compact symbols, usage rules, and a message-passing contract,"
- Pareto criterion: A selection rule that prefers solutions not dominated in both accuracy and token cost (accuracy first, then minimal tokens). "we implement selection via a Pareto criterion"
- Pareto frontier: The set of optimal trade-offs where improving one objective (accuracy) would worsen another (token cost). "CLSR improves the Pareto frontier of accuracy versus generated tokens"
- prefill phase (time-to-first-token, TTFT): The initial stage of LLM inference that processes inputs before generating the first token. "a prompt prefill phase (time-to-first-token, TTFT)"
- Program-aided Language (PAL): A program-execution baseline where the model generates code to be run by an external executor. "PAL (Program-aided Language)"
- Program-Execution Pipelines (PE): Inference procedures that generate a program/transcript and then apply a deterministic external executor. "Program-Execution Pipelines (PE)."
- Program-of-Thoughts (PoT): A prompting approach that guides the model to produce programs as part of its reasoning process. "PoT (Program-of-Thoughts prompting)"
- prompt optimization: Techniques that refine or evolve instruction prompts to improve performance without altering model weights. "Unlike prompt optimization that refines surface instructions"
- self-consistency: A strategy that samples multiple reasoning paths and aggregates answers (e.g., via voting) to improve reliability. "chain-of-thought and self-consistency strategies"
- socio-linguistic perspective: Viewing protocol evolution through the lens of social and cultural processes shaping language. "a socio-linguistic perspective inspired by the cultural language evolution process"
- stochastic kernel: A probabilistic mapping describing the distribution of next tokens given the current history under an LSF. "the LLM decoding under each LSF defines a well-posed stochastic kernel over the next tokens conditioned on the current history."
- supremum: The least upper bound; here, the best achievable accuracy under a token budget. "the supremum is attained:"
- universality results for Transformer-like architectures: Theoretical results showing Transformers can simulate arbitrary computations under certain conditions. "universality results for Transformer-like architectures"
Collections
Sign up for free to add this paper to one or more collections.

