GPC: Large-Scale Generative Pretraining for Transferable Motor Control
Abstract: Developing controllers capable of completing a wide range of tasks in a natural and life-like manner is a key challenge in enabling practical applications of physics-based character animation. In this work, we introduce Generative Pretrained Controllers (GPC), which leverage tokenization and next-token modeling to create general-purpose, reusable generative controllers from large-scale motion datasets. Our framework utilizes end-to-end reinforcement learning to jointly optimize a "motion vocabulary", modeled via Finite Scalar Quantization (FSQ), along with a corresponding control policy that can map the discrete codes to physics-based controls. After the "codebook" has been learned, the underlying structure of this large vocabulary is modeled by training a GPT-style autoregressive transformer, leading to a powerful generative controller that generates controls for a physically simulated character by performing next-token prediction. Once the generative controller has been trained, we propose a suite of adaptation techniques for finetuning the controller for new downstream tasks. Our proposed framework greatly simplifies the training process compared to previous tokenized methods, and achieves a 99.98% success rate in reproducing a vast corpus of motion clips. The generative controller exhibits a variety of natural emergent behaviors, such as responsive behaviors to perturbations and recovery behaviors after falling. This results in highly robust general purpose controllers for a variety of downstream applications.
























Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching a virtual character (like a video game avatar) to move in natural, human-like ways across many different situations. The authors build a “general-purpose controller” that can learn from hundreds of hours of real human motion and then reuse those skills to do new tasks, like following a path, dodging obstacles, or getting up after a fall.
What questions were the researchers trying to answer?
- How can we train a single controller to perform many kinds of movements (walking, jumping, rolling, flips) while still looking natural?
- Can we make this controller easy to reuse and adapt for new tasks without retraining everything from scratch?
- Is there a simple way to represent complex movements so that a model can “predict the next move” like how a text model predicts the next word?
How did they do it? (Methods explained simply)
Think of the character’s movement as a sentence, where each “word” is a small chunk of motion. If we can turn movement into tokens (like words), then a model can learn to predict the next token and, step by step, create a smooth, realistic performance. The authors trained their controller in three main stages:
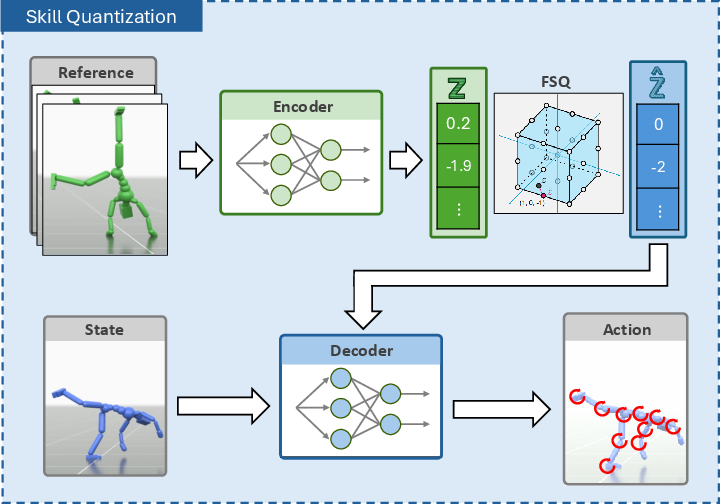
- Step 1: Build a dictionary of moves (Skill Quantization)
- They compress short segments of motion into a small set of “tokens,” a bit like turning a smooth volume knob into a few fixed notches. This method is called Finite Scalar Quantization (FSQ).
- Why this matters: Older methods used a big “codebook” that was hard to train and sometimes broke down. FSQ skips the codebook and uses simple rounding, which is easier and more stable.
- They train this with reinforcement learning (RL), which is like trial-and-error practice: the character tries to imitate motion clips and gets rewards when it does well.
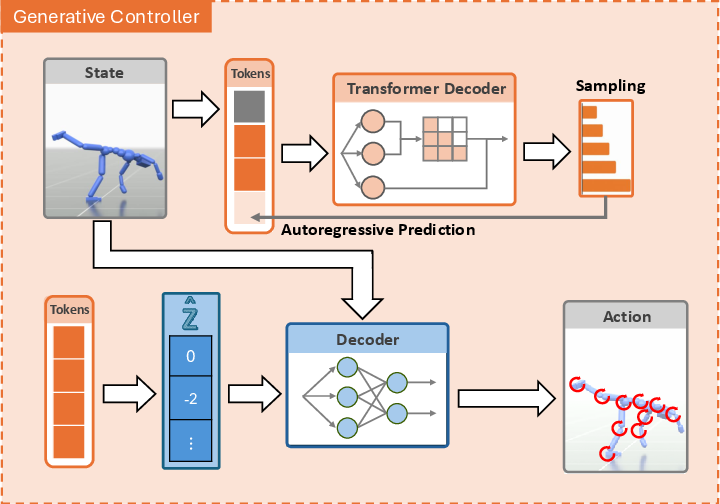
- Step 2: Teach a “predict-the-next-move” brain (Generative Controller)
- After they have motion tokens, they train a GPT-style model (the same kind of idea used in chatbots) to predict the next motion token given the character’s current state. This is like text auto-complete, but for movement.
- At each moment, it picks the next token and sends it to a decoder that turns tokens into joint actions, which move the character’s body.
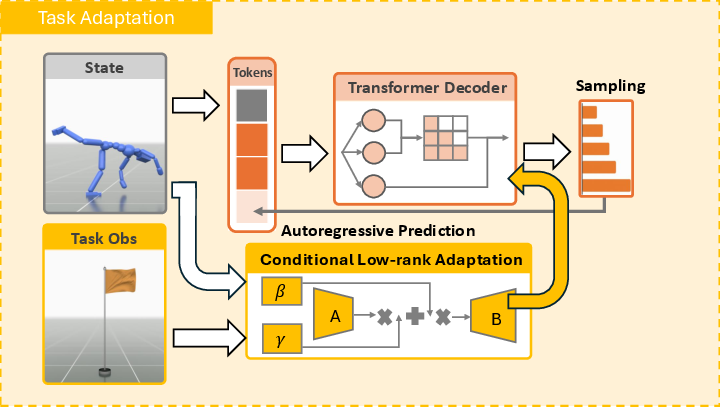
- Step 3: Fine-tune for new tasks with tiny add-ons (Parameter-Efficient Fine-Tuning)
- Instead of retraining the whole model for each new task, they add very small adapters (less than 1% extra parameters) that tweak the model’s behavior. They call this approach CoLA.
- They can tune these adapters with:
- Reinforcement Learning (to maximize task rewards), and/or
- Supervised Fine-Tuning (using example motions to nudge the style, like making the character crouch-walk more often).
Helpful analogies:
- Tokens: like Lego pieces for movement—simple building blocks that can be combined into complex actions.
- GPT-style prediction: like writing a story one word at a time; here, it “writes” a motion one token at a time.
- FSQ (quantization): turning a smooth dial into fixed positions so the model has a tidy, manageable set of choices.
- Fine-tuning adapters: small knobs attached to a big machine—easy to install, easy to adjust, no need to rebuild the machine.
What did they find, and why is it important?
Main results:
- Extremely accurate motion reproduction: The system could recreate a massive set of motion clips with a 99.98% success rate, while staying physically realistic.
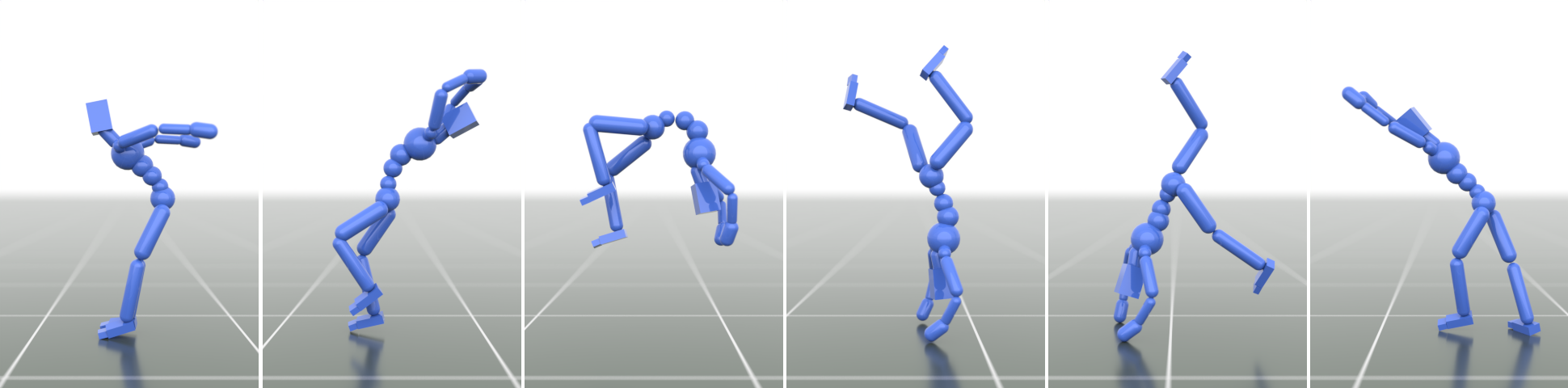
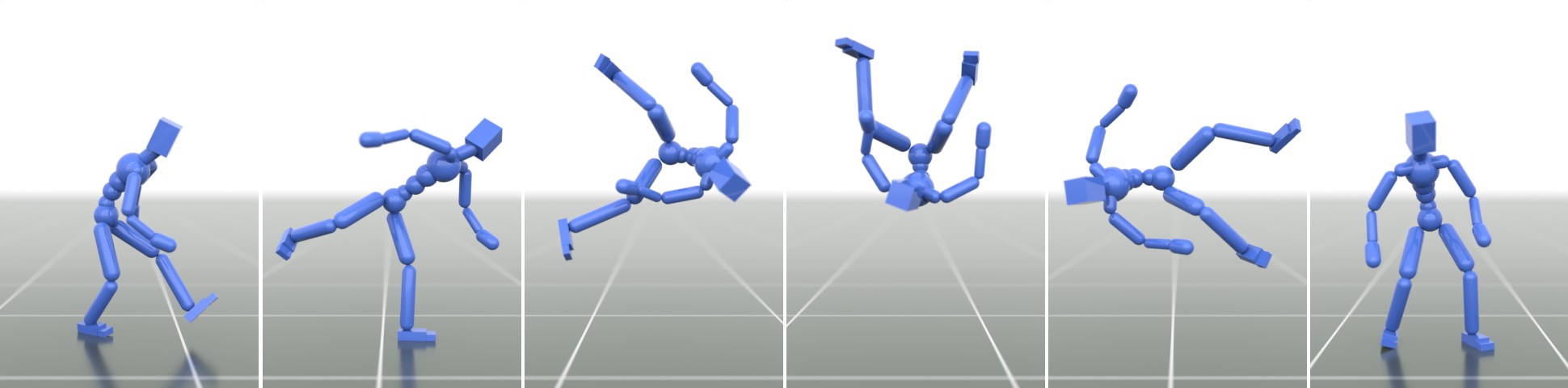
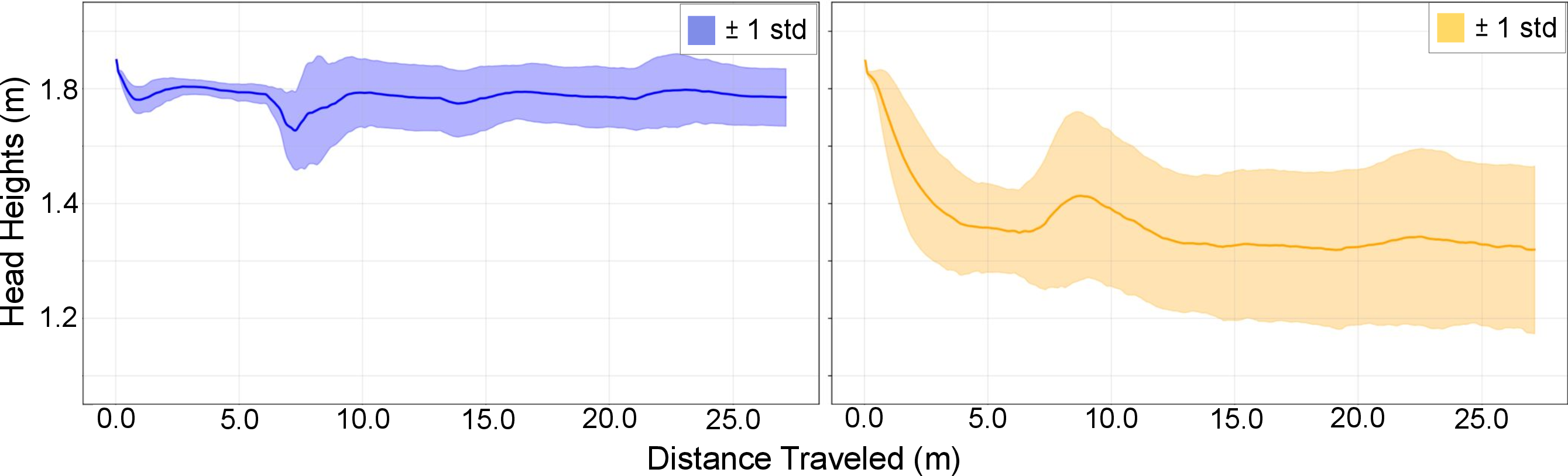
- Natural, emergent behaviors: Without being told explicitly, the controller learned life-like reactions—like catching balance when pushed and smoothly getting up after a fall.
- Robust and diverse movement: The model can produce many kinds of motions (jumping, rolling, dancing, acrobatics) and switch between them naturally.
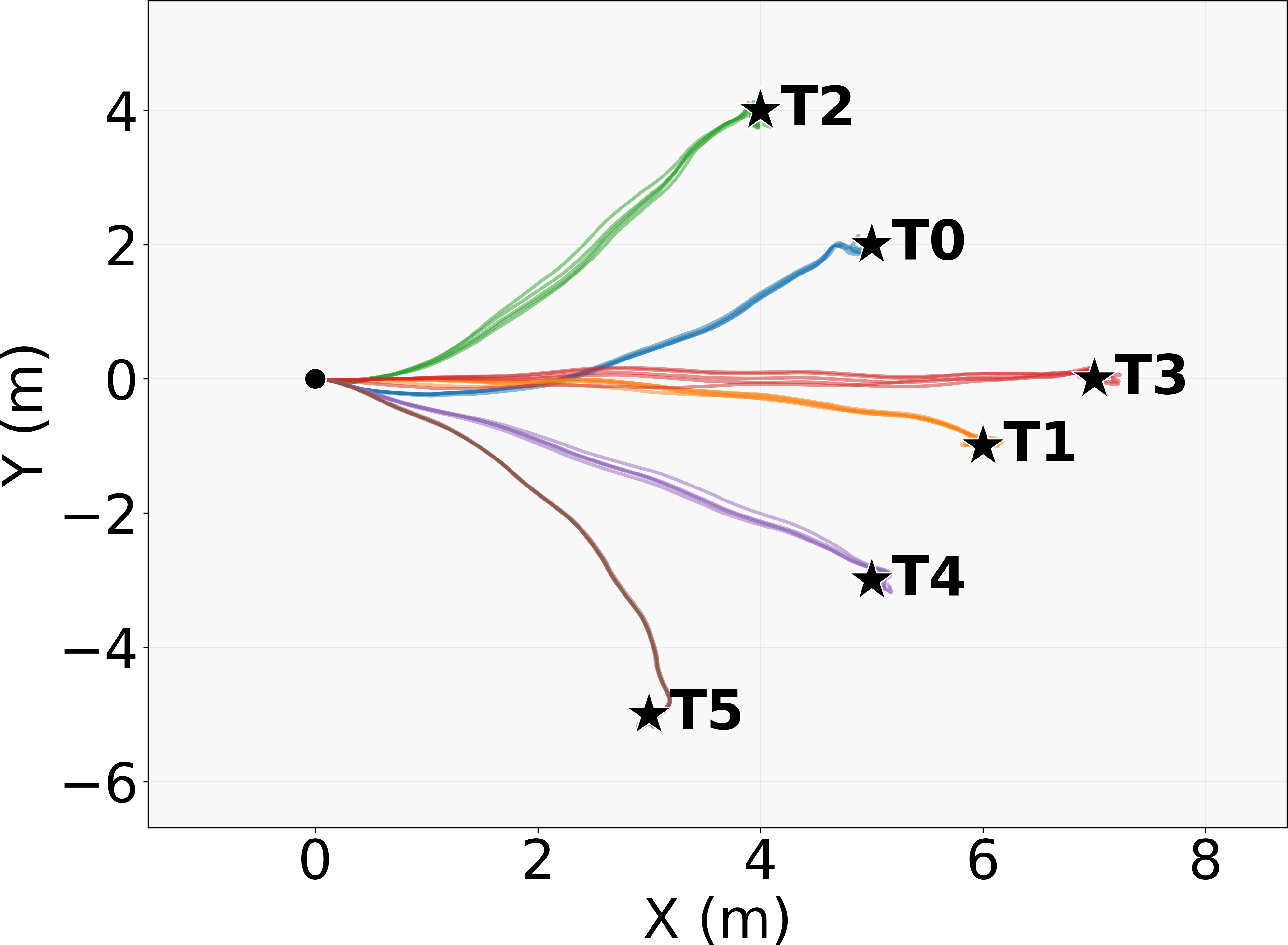
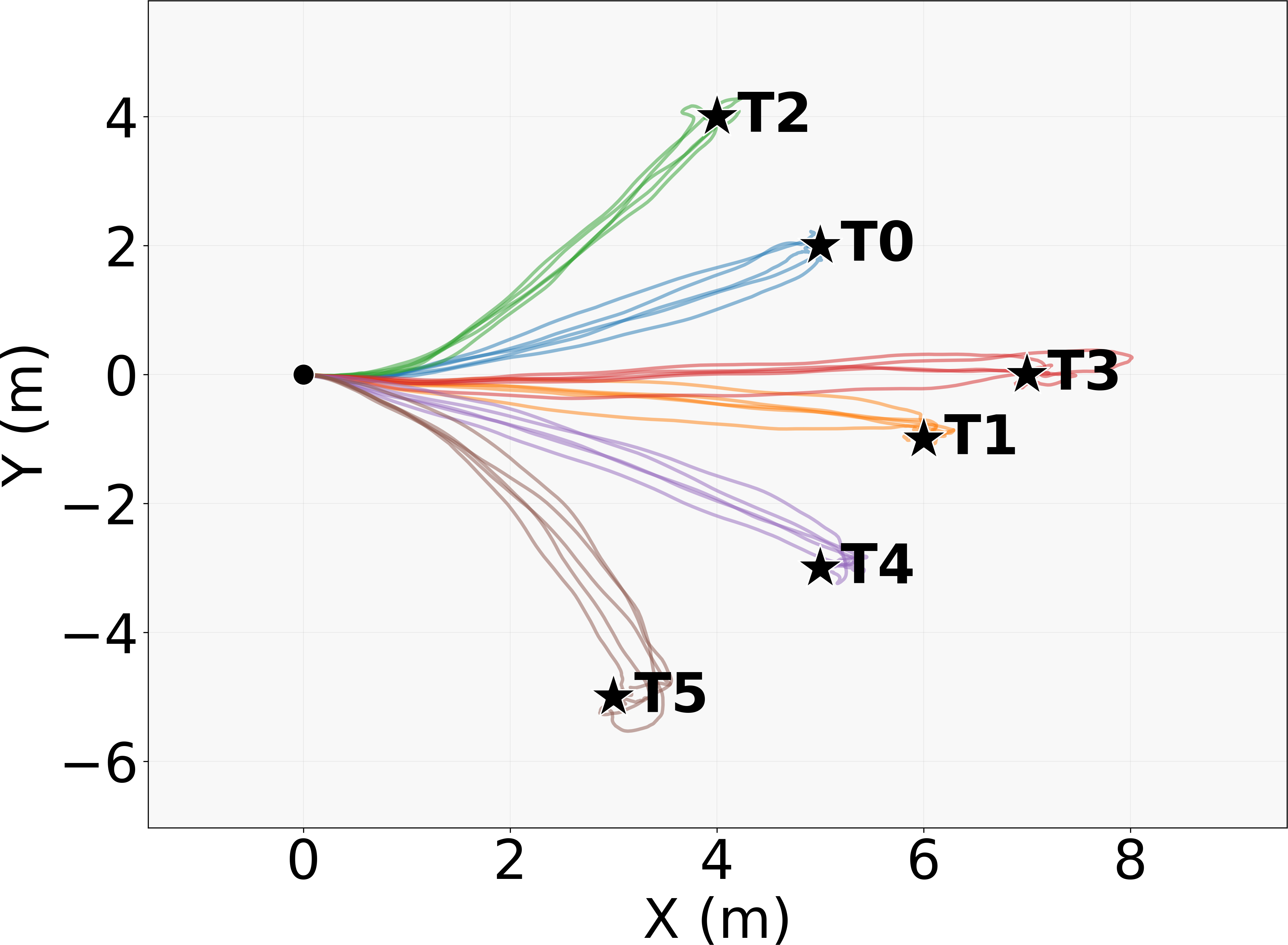
- Easy adaptation to new tasks: With tiny adapter layers, the same pretrained controller can quickly learn things like following a path, steering with a joystick, or navigating obstacles—while keeping its natural style.
- Simpler and more stable training: FSQ avoids tricky “codebook” problems common in older token-based methods (like VQ-VAE), making it easier to scale to huge motion datasets (600+ hours).
- Practical trade-offs with token “grouping”: Combining several small tokens into bigger tokens reduces sequence length (faster and cheaper to run) and can improve the variety and quality of motion, at the cost of some fine-grained smoothness. The authors identify settings that work well in practice.
Why this matters:
- For games, movies, and VR, this means characters that look and feel more real, react better, and can do more without hand-animating every situation.
- For research and robotics, it shows a strong way to mix learning from big datasets with physics and then adapt to new goals efficiently.
What does this mean for the future? (Implications and impact)
This approach points toward “foundation models” for movement: one large, reusable controller that knows many skills and can be tuned for new tasks with minimal effort. The benefits include:
- Less manual animation work, faster prototyping, and more consistent realism in interactive media.
- Quick adaptation to new environments or objectives, thanks to tiny, efficient fine-tuning layers.
- A bridge between data-driven generative models (like GPT for text) and physics-based control, which could inspire similar designs in robotics and other simulations.
- As datasets grow and models improve, we can expect even more natural, flexible, and reliable character controllers that handle complex, dynamic situations with human-like grace.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research.
- Temporal modeling scope: The “next-token” modeling is autoregressive within the token group at a single time step, not across time; there is no explicit long-horizon sequence modeling, skill duration modeling, or macro-action planning. Investigate multi-step (temporal) token prediction, variable-duration skills, and memory mechanisms for long-term coherence.
- FSQ hyperparameter sensitivity: The effects of quantization levels (), latent dimensionality (), encoder window length (), and STE bias are not systematically ablated. Provide comprehensive studies on these hyperparameters’ impact on tracking accuracy, stability, diversity, and code utilization.
- Token grouping trade-offs: Only a coarse ablation of grouping factor is reported; vocabulary–context length–quality–compute trade-offs remain underexplored. Evaluate grouping across broader settings, including different , , frame rates, and hardware constraints.
- Temporal tokenization: Grouping is applied across latent dimensions, not across time. Explore temporal downsampling (e.g., lower token frequency, frame skipping) or temporal macro-tokens to reduce latency and improve planning.
- Token usage and semantics: Beyond average utilization, there is no analysis of per-token frequency, entropy/perplexity, dead zones, or semantic consistency. Assess whether tokens correspond to interpretable/composable skills and how token distributions vary across datasets and tasks.
- Comparisons with broader baselines: The study lacks head-to-head comparisons with diffusion-based controllers, world models, Gumbel-Softmax/product quantization, residual VQ, and other discrete-latent methods at similar scales. Benchmark against these alternatives on identical data and tasks.
- Training objective mismatch: Generative training uses teacher forcing; inference uses sampling. The impact of exposure bias and alternatives (e.g., scheduled sampling, RL-based fine-tuning of the generative prior) is not evaluated.
- Physics feedback in pretraining: The transformer prior is trained offline to predict FSQ tokens but is not optimized end-to-end with physics-based feedback. Examine RL fine-tuning of the prior itself and joint optimization of prior and decoder under physical constraints.
- Robustness quantification: Emergent recovery behaviors are shown qualitatively; there is no systematic robustness evaluation across perturbation magnitudes/directions, contact disruptions, sensor noise, or model parameter shifts. Provide standardized robustness suites and metrics.
- Task breadth and complexity: Downstream tasks focus on locomotion, navigation, simple obstacles, and crouch-style SFT. Evaluate manipulation, tool-use, contact-rich interactions (stairs/slopes/uneven terrain), multi-agent scenarios, and long-horizon goal sequences.
- Morphological generalization: All results use one human morphology; no transfer to different body sizes, proportions, or non-humanoid skeletons. Test cross-embodiment adaptation and the effect of PEFT on morphology transfer.
- Simulator and dynamics generalization: Experiments are limited to Isaac Gym. Assess cross-simulator generalization (e.g., MuJoCo, Bullet), perturbations to mass/inertia/friction, and robustness to physics engine differences.
- Sim-to-real transfer: The approach is not validated on hardware or with real-world sensing/control loops. Investigate domain randomization, dynamics identification, latency compensation, and safety constraints for real robots.
- Control interfaces and conditioning: Conditioning is limited to task observations; text/semantic prompts, style tokens, or multimodal (vision/audio) conditioning are not explored. Develop controllable interfaces for style, semantics, and high-level intent.
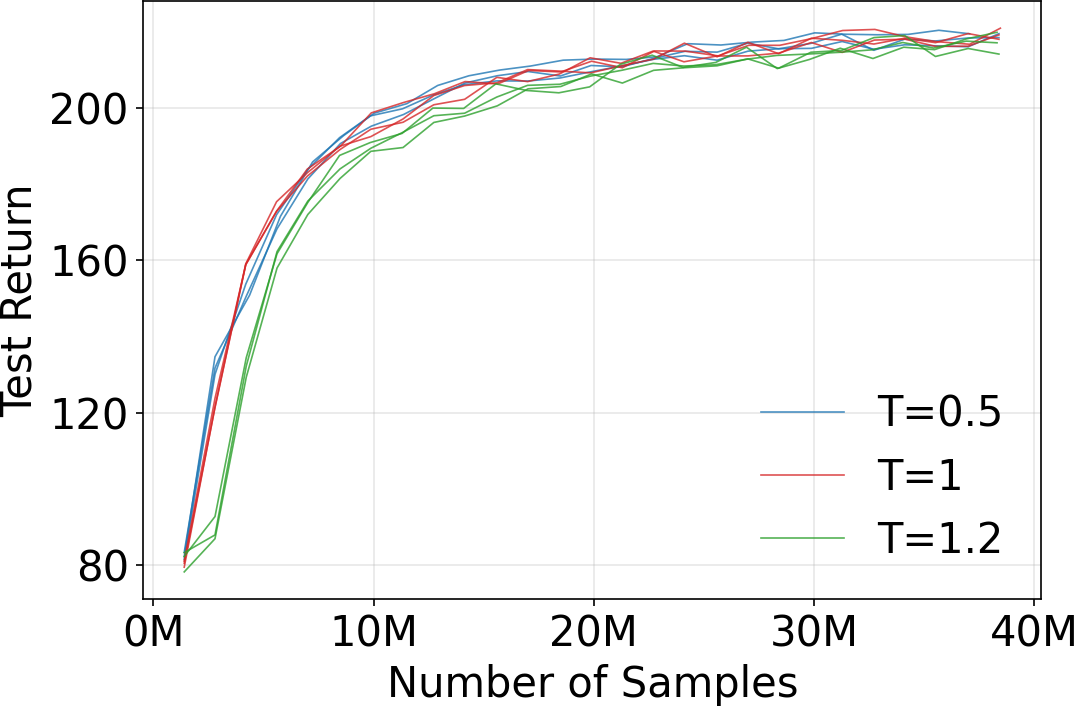
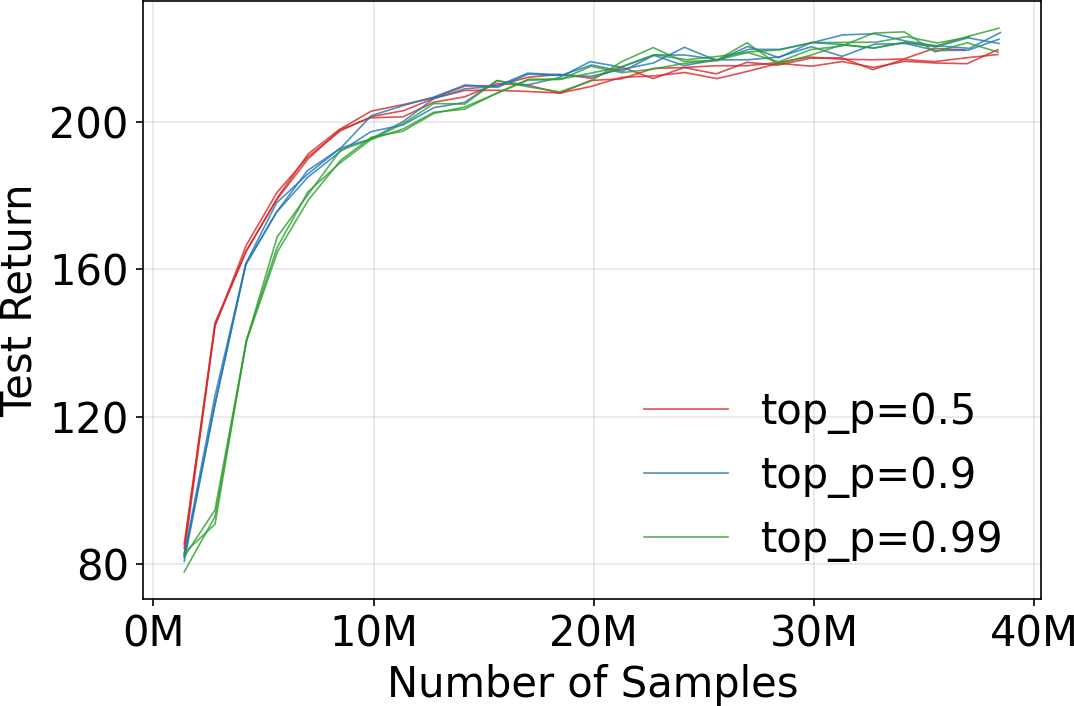
- Diversity–performance trade-offs: Nucleus sampling preserves diversity but may destabilize tasks. There is no principled calibration of sampling parameters (e.g., top-p) for risk-aware control or constraints on variability during task execution.
- Catastrophic forgetting and behavior preservation: PEFT is claimed to preserve pretrained behaviors, but there are no quantitative retention metrics (e.g., diversity, APD/ADE, token distribution shifts) pre- vs post-fine-tuning across varied tasks.
- Energy and biomechanical realism: Metrics such as energy/torque usage, joint limit violations, contact slip/foot-skate, CoM stability, and impact forces are not reported. Incorporate biomechanical/energetic costs and contact-quality metrics.
- Action representation and PD gains: Actions are PD targets with unspecified gain tuning. Analyze sensitivity to PD gains, gain scheduling across tasks, and alternative action spaces (e.g., torques, muscle models).
- Data dependence and bias: Pretraining relies on a 680-hour in-house “Bones” dataset whose composition and biases are unclear. Study how dataset balance/coverage affects emergent behaviors, and evaluate on publicly available, diverse datasets.
- Sample efficiency and compute: Training uses up to 24 A100 GPUs, but training time, sample counts, and energy costs are not disclosed. Quantify sample efficiency, wall-clock efficiency, and carbon footprint; explore distillation or smaller models.
- Runtime on consumer hardware: Although the model “can run” on an RTX 4090, detailed latency/FPS breakdowns for different and control frequencies on consumer GPUs/CPUs are missing. Provide real-time metrics for deployment contexts (games/XR).
- Failure analysis: The work reports near-perfect tracking success, but does not characterize remaining failures, jitter artifacts, or error modes (e.g., oscillations, mode switching, deadlocks). Provide failure taxonomies and diagnostics.
- Safety and constraints: The framework does not incorporate safety constraints (e.g., torque/velocity limits under uncertainty, obstacle avoidance guarantees). Explore constrained decoding, safe RL, and shielded control for deployment.
- FSQ vs VQ-VAE at scale: While FSQ simplifies training and avoids codebook issues, it remains unclear how modern stabilized VQ variants perform at similar scale and with identical training budgets. Conduct controlled, parity comparisons.
- Encoder horizon () and future conditioning: The influence of the encoder’s future-state window on learned skill abstraction and downstream control is not reported. Ablate and study its effect on temporal coherence and planning.
- Multi-character and object interactions: The model is not evaluated on scenes with other agents, articulated objects, or tight human–object coupling (e.g., carrying, pushing, throwing). Extend to interaction-heavy tasks and coordinated control.
Practical Applications
Immediate Applications
The paper introduces Generative Pretrained Controllers (GPC): an FSQ-tokenized, GPT-style generative controller trained via end-to-end RL on ≥600 hours of motion, with parameter-efficient fine-tuning (CoLA). Below are applications that can be deployed with today’s toolchains and hardware.
- Game and XR locomotion/interaction controllers
- Sectors: software, gaming, XR/VR.
- What it enables: drop-in, physics-consistent, naturalistic character control with robust emergent behaviors (e.g., recovery after falls, perturbation responses), trajectory following, target reaching, joystick steering, obstacle negotiation.
- Tools/products/workflows: Unity/Unreal middleware that wraps the FSQ decoder into the engine’s physics (PD joint drives), an authoring panel to adjust sampling (top-p) and token grouping G for diversity vs stability, on-device runtime (tested on RTX 4090).
- Assumptions/dependencies: reliable physics backend compatible with PD control, skeleton retargeting utilities, motion dataset licensing (e.g., AMASS, Bones), GPU for inference if high-fidelity crowds are required; tuning of G and sampling temperature to match design goals.
- Generative animation authoring and motion augmentation
- Sectors: film/TV/VFX, indie content creation, advertising.
- What it enables: augment sparse mocap with diverse, physically plausible variants (rolling, jumping, acrobatics), create transitions and recovery segments without hand-keying, previs with realistic environmental responses.
- Tools/products/workflows: DCC plugins (Maya/Blender/Houdini) to generate FSQ tokens from clips and sample autoregressively; batched “mocap-plus” generation for previs; timeline tools to “pin” skill tokens for deterministic beats and “unlock” tokens for emergent fills.
- Assumptions/dependencies: export/import of joint trajectories; stable PD-driven sim in DCC or via bridge (e.g., Isaac Sim); dataset IP compliance.
- Robust NPC behavior in dynamic environments
- Sectors: gaming, simulation, training.
- What it enables: crowd and NPC controllers that keep balance, recover from pushes, and exhibit varied yet goal-directed motion; improved believability with minimal designer scripting.
- Tools/products/workflows: crowd AI stack where high-level planner emits goals; GPC emits skill tokens; FSQ decoder drives physics per agent; PEFT adapters specialize styles per faction/role.
- Assumptions/dependencies: per-agent performance budget; consistent skeleton rig across agents.
- Parameter-efficient task/style adaptation (CoLA)
- Sectors: game tech, tools, research.
- What it enables: fast “style packs” (e.g., crouched walk, stealth, injured gait) and task packs (e.g., platforming, barrier traversal) by training <1% extra parameters; preserve base model naturalness.
- Tools/products/workflows: PEFT manager that loads/unloads adapters at runtime; SFT for stylistic bias followed by RLFT for reliability.
- Assumptions/dependencies: small example sets for SFT; PPO/RL infra for RLFT; policy safety (e.g., sampling bounded to high-probability regions).
- Academic baselines and large-scale control research
- Sectors: academia.
- What it enables: a stable discrete latent alternative to VQ-VAE (no dead-code heuristics), reproducible large-scale motion tracking benchmarks, ablations on token grouping G and sampling strategies.
- Tools/products/workflows: ProtoMotions + Isaac Gym training pipeline; open configurations (L=9, d=40, G in {2–5}); compare to CVAE/diffusion baselines.
- Assumptions/dependencies: multi-GPU access for pretraining; clear evaluation metrics (e.g., MPJPE, APD, ADE).
- Robotics simulation studies of skill-token control
- Sectors: robotics (research).
- What it enables: test whether discrete, autoregressive skill selection improves robustness and exploration vs continuous latents; study PEFT for task transfer in sim.
- Tools/products/workflows: Isaac Gym/Isaac Sim environments; ROS 2 bridges; evaluate perturbation recovery and compositionality.
- Assumptions/dependencies: morphology gap (human skeleton vs robot) requires retargeting; sim-to-real left for future work.
- Sports and biomechanics scenario testing
- Sectors: sports analytics, ergonomics, safety.
- What it enables: simulate human-like recovery and perturbation responses for “what-if” analyses; generate diverse trials without large mocap captures.
- Tools/products/workflows: pipeline to generate multiple perturbation conditions via token sampling; aggregate kinematic/kinetic metrics.
- Assumptions/dependencies: careful interpretation—model reflects dataset priors, not clinical ground truth.
- Motion search, indexing, and reuse with discrete skill tokens
- Sectors: software tools, archives.
- What it enables: token-level indexing for fast retrieval, deduplication, and library curation; “token palettes” for designers.
- Tools/products/workflows: build inverted indices over grouped tokens; clustering by token sequences; UI to drag-and-drop token motifs.
- Assumptions/dependencies: consistent FSQ configuration across assets; metadata governance.
Long-Term Applications
These applications are plausible extensions but depend on additional research, scaling, or cross-domain integration.
- Humanoid robot control with tokenized skill libraries
- Sectors: robotics, manufacturing, service.
- Vision: deploy discrete skill tokens on hardware for locomotion, balance, fall recovery; PEFT for task/site adaptation; safety-aware sampling.
- Dependencies/assumptions: high-fidelity dynamics models, robust sim-to-real transfer, torque control access, perception-to-token interfaces, compliance control; extensive safety validation.
- Generalist embodied agents with multimodal conditioning
- Sectors: software, robotics, XR.
- Vision: text/voice/vision-conditioned token selection for goal-directed behaviors; “motion GPT” that composes skills under constraints.
- Dependencies/assumptions: aligned multimodal datasets (language-action-motion), safe exploration, scalable RLHF/RLAIF for embodiment.
- Safety-critical crowd simulation for urban planning and policy
- Sectors: public policy, civil engineering, insurance.
- Vision: evacuation drills and infrastructure stress tests using controllers that handle perturbations and obstacles realistically.
- Dependencies/assumptions: calibrated domain parameters (friction, human variability), validation against real-world data, compute for large agents, ethical governance for deployment.
- Personalized rehabilitation, assistive tech, and prosthetics co-design
- Sectors: healthcare, med-tech.
- Vision: patient-specific digital twins that simulate gait variants, assistive strategies, and perturbation recovery to optimize rehab plans or prosthetic parameters.
- Dependencies/assumptions: clinical-grade validation, personalized models (anthropometry, impairment), regulatory compliance; dataset bias mitigation.
- Standardized “skill-token” interchange and marketplaces
- Sectors: software, content platforms.
- Vision: engine-agnostic token formats and adapters; creators publish style/task adapters; studios buy reusable “mobility packs.”
- Dependencies/assumptions: community consensus on FSQ specs (L, d, grouping), licensing frameworks, compatibility layers for different rigs/physics.
- Edge and mobile deployment for AR/VR wearables
- Sectors: XR/consumer electronics.
- Vision: on-device GPC inference with low-latency PEFT adapters for social VR and fitness.
- Dependencies/assumptions: distillation/quantization of transformers, mobile-friendly physics approximations, thermal/power constraints.
- Multi-agent coordination and team sports AI
- Sectors: esports analytics, simulation.
- Vision: agents coordinating via token-space planning to produce realistic team dynamics; coachable styles via PEFT.
- Dependencies/assumptions: joint planning layers, communication protocols in token space, datasets of coordinated behaviors.
- Cross-modal motion-language co-pilots for creators
- Sectors: creative tools, education.
- Vision: type “sprint, vault the barrier, tumble, get up” and receive a physics-consistent sequence with edit handles at token boundaries.
- Dependencies/assumptions: robust motion-language alignment, UI/UX for token editing, guardrails to prevent implausible or unsafe action chains.
- Digital human twins for workplace safety and ergonomics
- Sectors: industrial engineering, insurance.
- Vision: simulate varied human responses to slips/pushes across workspaces; forecast injury risks; test interventions.
- Dependencies/assumptions: validation against occupational data, accurate contact/friction models, ethical use policies.
- Governance for motion datasets and environmental cost
- Sectors: policy.
- Vision: standards for mocap rights, consent, bias auditing; reporting guidelines for compute and energy of large-scale motion pretraining.
- Dependencies/assumptions: multi-stakeholder processes, dataset documentation (datasheets), alignment with privacy/IP law.
Notes on Feasibility and Key Dependencies
- Data and IP: large-scale, diverse, and legally clear motion datasets are critical; behaviors reflect dataset priors.
- Physics fidelity: PD-joint control assumes stable, well-tuned physics; deployment in new engines may require calibration.
- Compute: pretraining used multi-GPU A100s; inference is feasible on high-end consumer GPUs; edge deployment needs compression/distillation.
- Retargeting: cross-skeleton deployment requires robust retargeting and possibly adapter retraining.
- Safety: for real-world robotics or policy simulations, empirical validation and safety certification are prerequisites.
- Tuning levers: token grouping G and sampling (top-p, temperature) trade off diversity, smoothness, and latency; PEFT adapters localize changes to maintain base naturalness.
Glossary
- Acceleration error (Accel.): A motion quality metric measuring the difference in acceleration between generated and reference motions. "acceleration error (Accel., m/s)"
- Adapters: Small trainable modules inserted into a frozen model to enable task-specific adaptation with few additional parameters. "such as adapters"
- Adversarial imitation learning: A technique that trains policies by matching expert behavior via an adversarial objective between a discriminator and a generator. "through adversarial imitation learning within a GAN framework"
- AMASS: A large human motion capture dataset used for training and evaluation in motion modeling. "such as AMASS \citep{mahmood2019amass}"
- APD (Average Pairwise Distance): A diversity metric quantifying the average distance between pairs of generated motion trajectories. "average pairwise distance (APD, m)"
- Average displacement error (ADE): A trajectory accuracy metric measuring average position error over time between generated and reference trajectories. "average displacement error (ADE, m)"
- Body–part–specific quantization: A discretization approach that assigns distinct quantizers to different body parts for finer control. "introduces bodyâpartâspecific quantization"
- Causal self-attention: A self-attention mechanism that restricts each token to attend only to past tokens to preserve autoregressive ordering. "via causal self-attention"
- Codebook collapse: A failure mode in vector-quantized models where few codes are used, reducing representational capacity. "mitigating common pitfalls of VQ-VAEs such as codebook collapse"
- Commitment loss: A VQ-VAE loss term encouraging encoder outputs to stay close to their assigned codebook vectors for stable code usage. "a commitment loss that penalizes deviations"
- Conditional Low-rank Adaptation (CoLA): A PEFT method that conditions low-rank weight updates on task inputs to adapt a frozen model efficiently. "Conditional Low-rank Adaptation (CoLA)"
- Cross-entropy loss: A standard classification loss used to train models to predict the correct discrete token. "cross-entropy loss to predict the tokens"
- Dead-code re-initialization: A heuristic for VQ-VAE training that reinitializes rarely used codebook entries to improve utilization. "dead-code re-initialization"
- Diffusion models: Generative models that learn to reverse a noise process to synthesize data, used for motion and image generation. "diffusion models"
- DoRA: A PEFT method that decomposes weight updates into magnitude and direction for more stable and expressive adaptation. "DoRA further refines this formulation"
- Exponential moving average (EMA): A smoothing technique for updating parameters like codebook entries to stabilize training. "exponential moving average (EMA) updates"
- Feature-wise Linear Modulation (FiLM): A conditioning method that scales and shifts intermediate features based on auxiliary inputs. "Feature-wise Linear Modulation (FiLM)"
- Finite Scalar Quantization (FSQ): A discretization method that quantizes each latent dimension independently into fixed scalar levels without a learned codebook. "Finite Scalar Quantization (FSQ)"
- GANs (Generative Adversarial Networks): Generative models trained via a game between a generator and a discriminator. "generative adversarial networks (GANs)"
- Generative Pretrained Controllers (GPC): The proposed discrete token–based generative controller pretrained on large-scale motion for physics-based characters. "Generative Pretrained Controllers (GPC)"
- GPT-style autoregressive transformer: A decoder-only transformer that models token sequences by predicting the next token conditioned on previous ones. "a GPT-style autoregressive transformer"
- Grouping factor (G): The number of base tokens packed into a single grouped token to reduce sequence length and attention cost. "Ablation of the grouping factor "
- Isaac Gym: A GPU-accelerated physics simulation environment for large-scale reinforcement learning. "implemented with Isaac Gym"
- Latent manifold: The continuous space of encoded representations where distances reflect semantic similarity. "gaps in the latent manifold"
- LoRA: A PEFT technique that injects low-rank trainable matrices into existing weights to adapt large models efficiently. "LoRA injects trainable low-rank updates"
- Markov Decision Process (MDP): A formalism for sequential decision-making with states, actions, transitions, and rewards. "commonly modeled as a Markov Decision Process (MDP)"
- Mean Per-Joint Position Error (MPJPE): A motion tracking accuracy metric measuring average joint position error. "MPJPE stands for Mean Per-Joint Position Error"
- Mode collapse: A generative modeling failure where the model produces limited varieties of outputs, ignoring modes of the data. "prone to mode collapse"
- Nucleus sampling (top-p sampling): A sampling strategy that draws from the smallest set of tokens whose cumulative probability exceeds a threshold p. "nucleus (top-) sampling"
- Parameter-efficient fine-tuning (PEFT): Techniques that adapt large pretrained models by training a small number of additional parameters. "parameter-efficient fine-tuning (PEFT)"
- PD controllers (Proportional–Derivative controllers): Low-level controllers that convert target joint rotations into torques using proportional and derivative terms. "proportional-derivative (PD) controllers"
- Proprioceptive state: The internal sensory state of a character, such as joint angles and velocities, used for control. "proprioceptive state"
- Proximal Policy Optimization (PPO): A reinforcement learning algorithm that stabilizes policy updates with clipped objectives. "Proximal Policy Optimization (PPO)"
- Reinforcement learning (RL): A learning paradigm where agents learn to act by maximizing cumulative reward through interaction. "Reinforcement learning (RL)"
- Reinforcement Learning Fine-Tuning (RLFT): Adapting a pretrained model to a task via reinforcement learning on task-specific rewards. "reinforcement learning fine-tuning (RLFT)"
- Residual VQ-VAE: A vector-quantized autoencoder variant that uses residual quantization stages to increase codebook capacity. "a residual VQ-VAE"
- Straight-through estimator (STE): A gradient approximation method that treats non-differentiable operations (e.g., quantization) as identity in backpropagation. "straight-through estimator (STE)"
- Supervised Fine-Tuning (SFT): Adapting a pretrained model using labeled examples and supervised losses before RL fine-tuning. "supervised fine-tuning (SFT) provides an effective mechanism"
- Teacher forcing: A training technique for autoregressive models where ground-truth tokens are fed as previous inputs during training. "trained with teacher forcing"
- Token grouping: Packing multiple base tokens into one larger-vocabulary token to shorten sequences and reduce attention cost. "Token grouping is an important design choice"
- Tokenization: Converting continuous or structured data into discrete tokens suitable for sequence modeling. "leverage tokenization and next-token modeling"
- Variational Autoencoder (VAE): A generative model that learns a probabilistic latent space for data via amortized variational inference. "variational autoencoders (VAEs)"
- Vector-Quantized Variational Autoencoder (VQ-VAE): A VAE variant that uses a discrete codebook to quantize latent representations. "Vector-Quantized Variational Autoencoder (VQ-VAE)"
- World model: A learned model that predicts environment dynamics or representations to aid planning or control. "learn a world model"
Collections
Sign up for free to add this paper to one or more collections.