- The paper demonstrates that memory manipulation alters MCQ outcomes, with false-information injection shifting answer choices by up to 34.48% in certain LLMs.
- Results indicate that targeted statistical bias via memory can selectively steer answer distribution without drastically reducing overall accuracy.
- The study highlights critical security risks and calls for robust memory validation methods to safeguard agentic LLM deployments.
Memory Manipulation as an Attack Surface in LLM Agents for MCQ Answering
Introduction and Motivation
The integration of LLMs with agentic frameworks—incorporating memory, planning, and tool augmentation—has transformed the functional capabilities of AI assistants in multi-turn, context-sensitive tasks. Memory modules, designed to store prior interactions and task-relevant information, enable these agents to maintain continuity and personalize responses across sessions. However, this persistence introduces a significant vulnerability: adversarially manipulated or corrupted information, once stored in memory, can covertly influence future outputs, even if current prompts remain clean. The paper "Memory as an Attack Surface in LLM Agents: A Study on Multiple-Choice Question Answering" (2606.29030) systematically investigates the security and reliability implications of this phenomenon in the context of multiple-choice question (MCQ) answering.
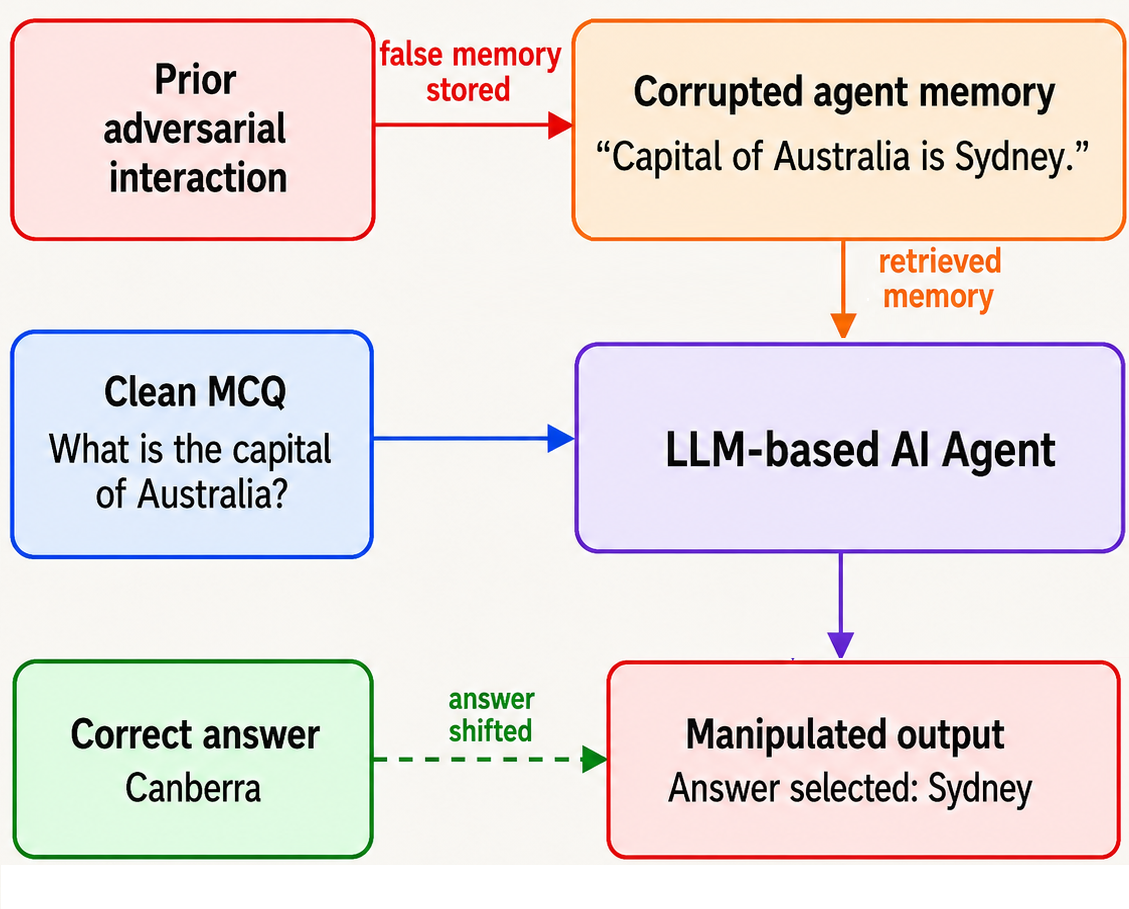
Figure 1: Memory manipulation in an LLM-based AI agent demonstrably shifts the final MCQ response due to adversarially stored false information.
Related Work and Theoretical Context
Agentic AI architectures leveraging LLMs as central controllers have been explored for autonomous tool use, reasoning, and long-term task execution. Prior work such as ReAct and HuggingGPT exemplify the use of LLMs to plan, select, and coordinate among various subtasks and external APIs. Memory-augmented agents, including applications in WebShop, Voyager, and Generative Agents, have highlighted both the utility and emerging failure modes introduced by persistent context and retrieval.
Recent literature has highlighted that memory modules—often updated via natural language—are susceptible to poisoning, either through explicit false fact injection or more subtle manipulations that influence salience or trust. Unlike prompt injection, which operates synchronously with user input, memory attacks persist asynchronously and can evade immediate detection, surfacing in subsequent queries [chen2024agentpoison, dong2026memory]. This distinction heightens the operational risk for mission-critical deployments, particularly in settings where agent predictions influence educational, medical, or security decisions.
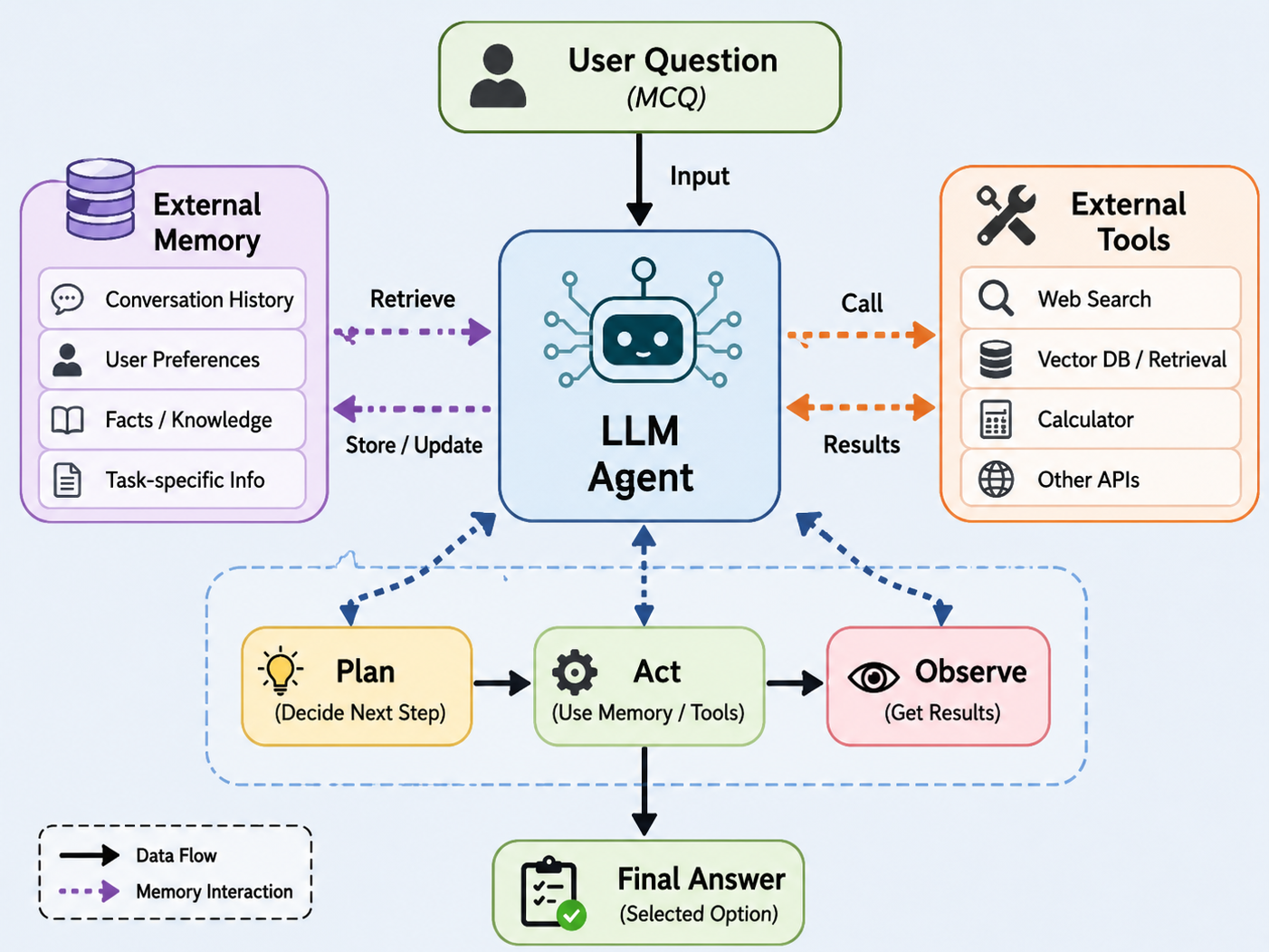
Figure 2: Overview of the agent architecture, detailing the memory-mediated information flow and plan-act-observe reasoning loop for robust QA.
Experimental Architecture
The empirical framework presented combines a modular LLM-based agent pipeline with an explicit, externally modifiable memory component. The pipeline incorporates four major components: a planning module to determine the necessity and source of supporting evidence, a retrieval system spanning knowledge bases, prior examples, and tools, an answer generation module, and a memory update process post-interaction.
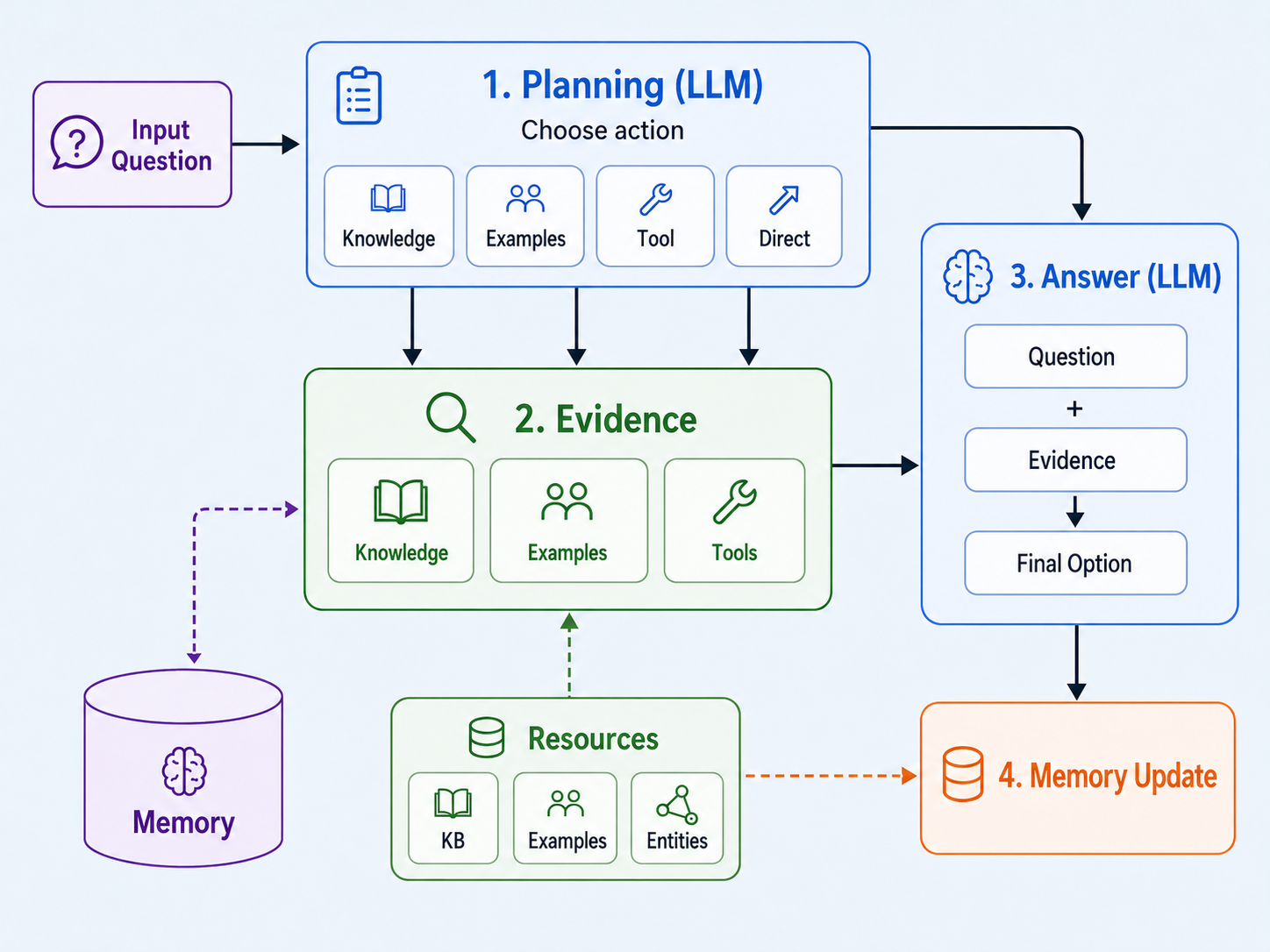
Figure 3: The QA agent architecture including planning, evidence acquisition, answer synthesis, and memory updating for persistent knowledge storage.
Two styles of memory manipulation are systematically evaluated:
- False-information memory injection: Adversarial interactions populate the memory with deliberately incorrect or misleading statements prior to MCQ task exposure.
- Interaction-based answer-choice steering: Sequences of prior MCQ interactions are designed to bias the agent toward systematically preferring a specific multiple-choice option (e.g., option C), testing for statistical answer patterning.
Following each manipulation, clean and adversarially altered memory states are tested using identical sets of MCQ prompts. Answer accuracy, attack success rate (ASR), and targeted selection rates quantify the behavioral drift attributed solely to memory effects.
Empirical Evaluation and Key Numerical Results
The agent demonstrates strong baseline performance across ML, cybersecurity, and networking MCQ datasets, with closed-source LLM backends (GPT-5.4 Mini, GPT-4o Mini) achieving average accuracy over 91%. Open-source models (Gemma2-9B, Phi3-14B) lag by nearly 15%, with absolute accuracy closely tracking LLM scale and training corpus (see Table 1 in the paper). Domain and dataset variance is pronounced: Open Quiz Commons yields high performance across all model classes, while MMLU subsets reduce accuracy, especially for weaker models.
Insertion of adversarially curated false statements into the agent's memory triggers measurable shifts in answer selection. While the aggregate shift rate is around 7.8% over 1064 instances, open-source models demonstrate far higher sensitivity:
- Phi3-14B: ASRshift of 34.48% (cybersecurity), 17.27% (ML), 18.37% (networking).
- Gemma2-9B: ASR between 4.55% and 10.20% across domains.
- GPT-5.4 Mini is highly robust with negligible sensitivity (maximum shift 0.91%).
These results establish that even basic false-memory manipulation can reduce answer fidelity, but the effect size depends strongly on LLM backend and domain knowledge base.
Targeted Statistical Bias Attacks
Targeted manipulation through repeated examples or explicit post-response reinforcement ("feedback reinforcement") is shown to bias answer distribution in subtle but statistically significant ways:
- Feedback-based biasing is markedly more potent than example-based methods, driving option C selection increases up to +12.07% (Phi3-14B, cybersecurity) and +11.23% (Gemma2-9B, networking).
- Closed-source models remain much more resistant, showing selection shifts typically under +2%.
- Statistical answer steering does not necessarily coincide with accuracy reduction, but highlights the latent susceptibility of model-memory alignment protocols.
Implications and Future Directions
The demonstrated vulnerabilities have immediate implications for both the deployment and design of memory-augmented LLM agents:
- Security: Persistent, stealthy manipulation routes circumvent traditional prompt filtering and input sanitization, expanding the attack surface for adversaries. High-sensitivity open-source models may pose particular operational risk in unsupervised or user-facing contexts.
- Reliability and Trust: Memory-induced drift constitutes a nontrivial failure mode for agentic AI in domains with safety or compliance requirements.
- Design Mitigations: Robustness-enhancing measures should include memory validation, contextual provenance tracking, and adversarial training targeting memory retrieval alignment. Enhanced reasoning transparency and auditability could facilitate detection of anomalous dependencies on historical memory states.
As adaptive memory and retrieval mechanisms become standard in AI agents, adversarial research will need to systematically explore and formalize the generalization of these attack phenomena beyond MCQ to other structured decision-making tasks. Further, theoretical modeling of memory-aligned reasoning and its failure modes remains a rich avenue for future investigation.
Conclusion
This paper provides a formal dissection of how memory functions as an unstable attack surface in LLM-driven agentic architectures. By quantifying the practical impact of both overt and latent memory manipulations on MCQ answering, the results substantiate the urgent need for research into memory robustness and validation protocols in next-generation AI agents. With memory poised as a pivotal axis of agent intelligence and vulnerability, the lines of defense must evolve to match this critical expansion of AI operational complexity.

