Language-Based Digital Twins for Elderly Cognitive Assistance
Abstract: Digital twins have emerged as a promising paradigm for personalized healthcare, enabling modeling of individual behavior and health trajectories. In cognitive health, early detection of Mild Cognitive Impairment (MCI) remains challenging, where language and conversational patterns serve as non-invasive biomarkers. In this work, we propose a language-based digital twin framework that leverages LLMs to mimic the conversational behavior of elderly individuals by incorporating stylometric cues and contextual metadata. To evaluate fidelity and cognitive consistency, we introduce a multi-head conditional variational autoencoder (cVAE) that jointly measures reconstruction quality and predicts cognitive scores. Experiments on the I-CONECT dataset show that the digital twin preserves identity-specific characteristics and achieves reconstruction and MoCA prediction errors comparable to real data, while outperforming baseline GPT-generated responses. These results highlight the potential of language-based digital twins as a scalable and non-invasive approach for personalized and continuous cognitive health monitoring.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Language-Based Digital Twins for Elderly Cognitive Assistance — Explained Simply
1. What is this paper about?
This paper is about building a “digital twin” of an older person’s way of speaking. Think of a digital twin as a smart, virtual copy that can talk like a real person. The goal is to use this twin to spot early signs of memory or thinking problems (like Mild Cognitive Impairment, or MCI) by paying attention to how someone talks during everyday conversations.
2. What did the researchers want to find out?
The researchers asked simple, practical questions:
- Can we train an AI to speak in a way that closely matches how a specific person talks, including their style, pace, and pauses?
- Can this AI-generated speech keep important clues about a person’s thinking health, so it can help estimate cognitive test scores (like MoCA, a common 30-point memory and thinking test)?
- Is this “personalized twin” better than a regular AI chatbot at capturing both style and cognitive signals?
3. How did they do it?
They followed a few main steps, using everyday ideas to explain the tech:
- Building a “talking twin”:
- They started with a LLM—a smart text generator similar to an advanced autocomplete.
- They fine-tuned it (taught it carefully) using real conversations from older adults in a study called I-CONECT. These are natural, friendly chats, not strict tests.
- Besides words, they added “stage directions” to the transcripts, like:
- PAUSE: NONE, SHORT, MED, LONG, VLONG
- TEMPO: SLOW, MED, FAST, VFAST
- These tokens act like rhythm and timing notes in a script, helping the AI learn not just what people say, but how they say it (for example, speaking slowly with longer pauses can sometimes signal cognitive changes).
- Cleaning and organizing the data:
- They fixed transcription mistakes using an automatic speech tool (Whisper).
- They separated who was talking when (so the AI learned only the participant’s responses, not the interviewer’s).
- They created helpful summaries of the topics people talked about.
- Checking if the twin “sounds” like the person:
- They used a simple test: can a computer guess which participant’s style a message belongs to? If it can, the twin is preserving identity (voice and style) well.
- Checking if the twin keeps cognitive clues:
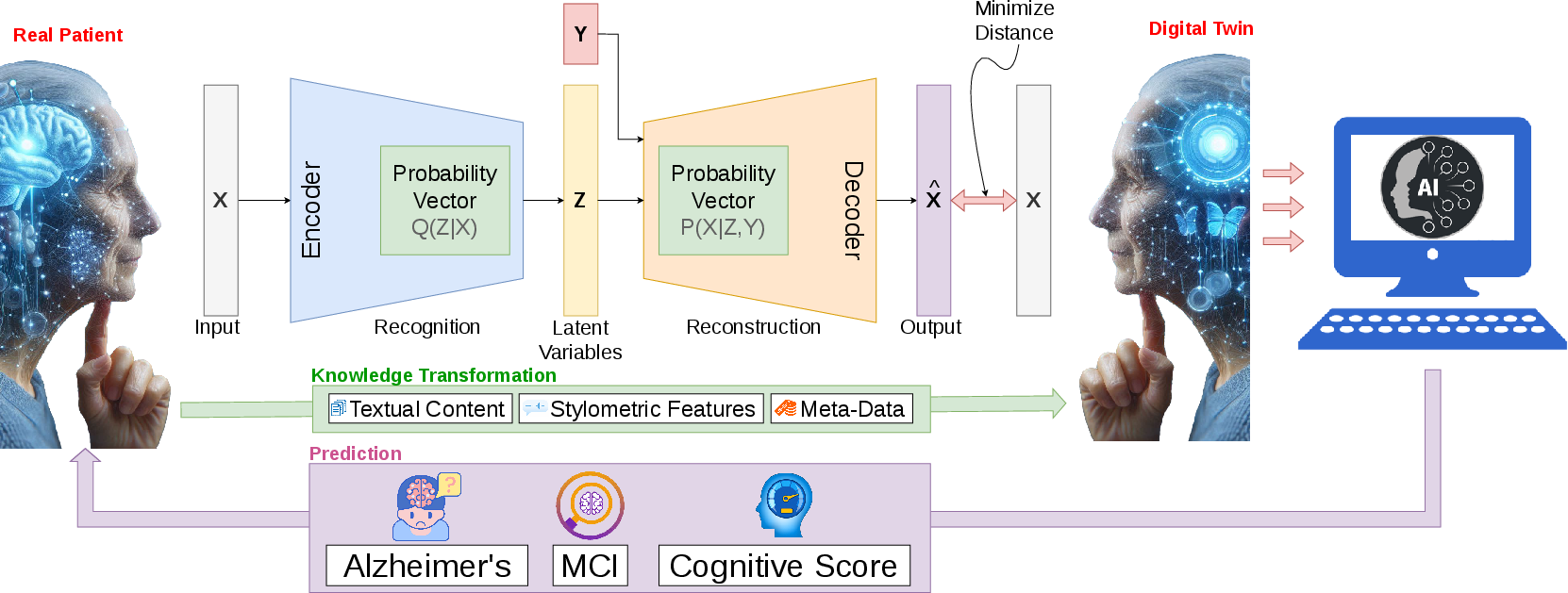
- They built a special “quality checker” model called a cVAE (conditional Variational Autoencoder).
- Think of it like this: it compresses a response into a small “fingerprint” (zip), then tries to rebuild it (unzip). If the rebuild is close to the original, the response is faithful. This same fingerprint is also used to estimate a person’s MoCA score.
- The cVAE has two jobs (“two heads”):
- 1) rebuild the response (are the words and style close?), and
- 2) predict cognitive score (is the thinking-related info preserved?).
4. What did they find, and why does it matter?
Key findings:
- The digital twin kept each person’s speaking style much better than a regular, unfine-tuned AI. In identity tests (guessing who the speaker is by style), the twin’s accuracy was close to real data and far better than the base AI.
- The twin’s responses looked very similar to real ones according to the cVAE “rebuild” test (very low reconstruction errors, close to real speech).
- The twin helped estimate MoCA scores almost as accurately as when using real responses. The base AI did much worse:
- Twin errors were small (about 0.4 to 1.08 points).
- Base AI errors were much larger (about 3.5 to 5+ points).
- This shows the twin isn’t just copying style—it’s also keeping signals related to thinking and memory.
Why it matters:
- It’s hard to catch early cognitive changes with traditional tests because they’re infrequent, costly, and don’t reflect everyday life.
- Regular conversation contains useful clues about thinking health (like word choice, pauses, and pace).
- A language-based digital twin could monitor these clues continuously and non-invasively, making it easier to spot changes early.
5. What’s the impact and what comes next?
- Potential impact:
- A personalized, talk-based twin could support at-home, ongoing check-ins for older adults, flagging subtle changes that might otherwise be missed.
- It could help doctors and caregivers decide when to step in earlier, possibly improving care and quality of life.
- What’s next:
- Add more signals like actual voice tone and facial expressions (audio and video), not just text, to make the twin more realistic and accurate.
- Test the system with more and more diverse participants to make sure it works broadly.
- Explore how well the twin can generalize across different people and situations.
In short, this paper shows that teaching an AI to “talk like you” using your real conversations—down to your pace and pauses—can help track cognitive health in a gentle, everyday way. It’s a step toward personalized, continuous monitoring that could make early detection more practical and accessible.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research:
- Extremely small cohort (n=5) selected for having the most sessions introduces selection bias; generalizability to broader, more diverse elderly populations remains untested.
- No evaluation across demographics (sex, race/ethnicity, education, socioeconomic status) or cognitive strata (normal vs. MCI), leaving fairness, subgroup performance, and potential biases uncharacterized.
- Generalization across participants is not demonstrated (e.g., leave-one-participant-out, cold-start twins for new individuals with few samples).
- Longitudinal modeling and forecasting are not evaluated; it is unclear whether the twin can track or predict future MoCA changes or detect subtle trajectories of decline.
- The model uses per-turn SFT and metadata conditioning; multi-session temporal dependencies and stateful progression modeling are not explicitly learned or assessed.
- The identity-preservation analysis relies on SVM over embeddings/sentiment with limited statistical rigor (no confidence intervals, significance tests) and unclear train/test separation at the session/time level.
- Risk of information leakage is not addressed: the digital twin and cVAE evaluator may share overlapping sessions/participants, potentially inflating evaluation results.
- The cVAE evaluator’s validity as a surrogate metric is unvalidated against human judgments or established similarity metrics; no inter-rater or external criterion validation is provided.
- MoCA prediction is evaluated only via the cVAE trained on the same dataset; no independent model or cross-dataset validation to confirm cognitive signal preservation.
- Clinical relevance of reported MoCA prediction errors (e.g., 0.4–1.08) is not contextualized (e.g., sensitivity/specificity for MCI cutoffs, minimal clinically important difference).
- No comparison to strong baselines beyond “raw GPT” (e.g., persona-conditioned LLMs, retrieval-augmented generation, memory-augmented chat, or specialized speech-based MCI models).
- Ablation studies are absent; the relative contribution of stylometric tokens, metadata (including participant ID), topic descriptors, and content to fidelity and cognitive alignment is unknown.
- Participant ID conditioning may cause shortcut learning/memorization; performance without explicit IDs or with anonymized metadata is not examined.
- The stylometric tokens (PAUSE/TEMPO) lack a detailed derivation protocol (how thresholds are computed from audio, reliability across conditions); construct validity is unverified.
- Discretizing temporal dynamics into coarse tokens may lose clinically relevant nuance; no comparison to continuous acoustic-prosodic features (e.g., pause duration distributions, pitch, jitter, speaking rate).
- Robustness to ASR errors, diarization mistakes, and real-world noise is not tested; reliance on Whisper-reprocessed audio may not reflect deployment conditions.
- Topic/domain shift is unexamined; the twin’s fidelity on unseen topics, interviewers, or conversational contexts is unknown.
- Multi-turn conversational coherence and persona consistency over extended dialogues are not evaluated (the study focuses on turn-level responses).
- No analysis of hallucination rates, factual consistency, or safety behaviors in generated responses, which are critical for clinical-facing assistants.
- Uncertainty quantification is absent; no confidence intervals, calibration, or reliability estimates for MoCA predictions or evaluator scores are reported.
- The cVAE architecture and training details (hyperparameters, tokenization, feature scaling, regularization) are insufficiently specified for reproducibility.
- The GitHub link is generic, and the availability of code, trained models, and exact preprocessing pipelines is unclear; end-to-end reproducibility is uncertain.
- Ethical, privacy, and governance issues (e.g., consent for twin creation, risk of re-identification, membership inference, model inversion) are not addressed.
- No privacy-preserving training strategies (e.g., differential privacy, federated learning) are explored for sensitive clinical-conversational data.
- User acceptability, clinician trust, and integration into workflows (e.g., how twins will be presented, oversight mechanisms, feedback loops) are not investigated.
- No prospective or real-world pilot demonstrating feasibility, usability, or impact on clinical outcomes (screening accuracy, time-to-intervention, patient engagement).
- Lack of calibration to clinical decision thresholds (e.g., MCI classification vs. regression), and absence of diagnostic metrics (AUROC, sensitivity/specificity, PPV/NPV).
- No cross-dataset validation (e.g., ADReSSo/other corpora), leaving external validity untested.
- Education and language proficiency effects—known confounders for MoCA and language biomarkers—are not analyzed or controlled.
- The pipeline from raw audio to stylometric tokens for real-time deployment is unspecified; online inference latency, throughput, and resource constraints are not evaluated.
- Potential harms from overly realistic twins (misuse, impersonation, inappropriate delegation of clinical judgments) and corresponding safeguards are not discussed.
- The minimal data requirements to build a useful twin (sample complexity) and the effect of data sparsity/imbalance across individuals are unknown.
- No investigation into interpretability/explainability (e.g., which linguistic cues drive cognitive predictions), limiting clinical insight and trust.
- Impact of using proprietary base LLMs (e.g., GPT-4.1-mini) on reproducibility, portability, and cost is not analyzed; performance portability across open-source LLMs is unknown.
- The study does not examine continual learning or safe updating of twins over time (catastrophic forgetting, drift detection, versioning).
- Safety, fairness, and compliance testing frameworks (e.g., bias audits, red-teaming) are not applied to the twin or evaluator.
Practical Applications
Immediate Applications
Below are deployable use cases that can be built with current methods and components described in the paper (LLM fine-tuning with stylometric tokens, Whisper+pyannote processing, cVAE evaluator for reconstruction and MoCA prediction).
- Personalized telehealth cognitive check-ins via conversation
- Description: Use the language-based digital twin to simulate or analyze short telehealth conversations and produce a MoCA-proxy estimate and trend for each patient.
- Sectors: Healthcare, Software (Health IT), Telemedicine
- Potential tools/products/workflows:
- Workflow: Whisper ASR → pyannote diarization → stylometric augmentation → SFT LLM digital twin → cVAE MoCA-proxy → clinician dashboard
- Product: “Cognitive Monitor” plugin for telehealth platforms (e.g., Epic-integrated or standalone dashboard)
- Assumptions/Dependencies: reliable ASR/diarization on elderly speech; access to baseline conversations to personalize; clinical oversight for interpretation; small-sample generalizability limits noted in the paper
- Clinician dashboard for longitudinal cognitive trajectories
- Description: Display patient-specific conversational features (stylometry, sentiment, embeddings) and MoCA-proxy predictions over time to support early detection of decline.
- Sectors: Healthcare, Health IT
- Potential tools/products/workflows:
- Product: Web dashboard aggregating cVAE outputs, pause/tempo profiles, and identity-consistent features
- Integration: HL7 FHIR hooks for EHR interoperability (read-only initially)
- Assumptions/Dependencies: secure data pipelines; governance for PHI; thresholds for alerting need validation
- Privacy-preserving synthetic data generation for research
- Description: Use the digital twin to generate participant-style responses to augment training sets and enable data sharing without disclosing raw patient transcripts.
- Sectors: Academia, Software (ML/Data)
- Potential tools/products/workflows:
- Tool: Fine-tuned LLM with stylometric prompts to create synthetic corpora per participant
- Process: Data synthesis + cVAE-based similarity/cognitive-consistency scoring as a release criterion
- Assumptions/Dependencies: risk of leakage/memorization; differential privacy or other safeguards recommended; IRB/data use approvals
- Training and coaching simulator for caregivers and therapists
- Description: Simulate realistic patient responses (including pauses/tempo) to train communication strategies for MCI and normal aging populations.
- Sectors: Healthcare, Education
- Potential tools/products/workflows:
- Product: Scenario-based training app where the digital twin plays the patient
- Evaluation: cVAE evaluator used for scenario realism checks
- Assumptions/Dependencies: fidelity acceptable for training but not for diagnosis; need to avoid reinforcing stereotypes/bias
- QA/evaluation module for eldercare chatbots and clinical conversation tools
- Description: Use the cVAE evaluator to quantify conversational fidelity and cognitive relevance of chatbot outputs in eldercare contexts.
- Sectors: Software (NLP), Healthcare
- Potential tools/products/workflows:
- Tool: cVAE-based “conversational quality” metric integrated into CI/CD for chatbot deployments
- Workflow: A/B test chatbot variants; select models maintaining cognitive relevance
- Assumptions/Dependencies: evaluator trained on target population/domain; periodic re-calibration as models evolve
- Automated analysis of recorded home or caregiver calls for cognitive signals
- Description: Post-hoc processing of phone/video call transcripts to extract stylometric markers and track changes that might indicate cognitive decline.
- Sectors: Healthcare, Consumer Health, Aging-in-place
- Potential tools/products/workflows:
- Workflow: Event-driven pipeline triggered by call recording → ASR+diarization → stylometric feature extraction → trend reporting
- Product: “Cognitive Signal Analyzer” for home-care agencies
- Assumptions/Dependencies: consent for recording; variable audio quality; false positives/negatives must be managed
- Participant identity/style verification in longitudinal studies
- Description: Use embedding+sentiment aggregation and SVM identity classification to validate participant identity and detect anomalies in longitudinal datasets.
- Sectors: Academia, Clinical Research Ops
- Potential tools/products/workflows:
- Tool: Data QA module for longitudinal language datasets to flag identity drifts or diarization mix-ups
- Assumptions/Dependencies: modest accuracy; meant for QA triage rather than hard identity proof
- Patient-facing engagement companion with adaptive tempo and pauses
- Description: Deliver a conversational companion that mirrors a user’s preferred pace and pause patterns to reduce cognitive load and increase engagement.
- Sectors: Consumer Health, Assistive Technology
- Potential tools/products/workflows:
- Product: Mobile or smart-speaker app employing stylometric tokens (PAUSE/TEMPO) in generation
- Assumptions/Dependencies: safety guardrails for advice; clear boundary that it is not a medical device; personalization requires initial data
Long-Term Applications
These use cases require further validation, scaling, multimodal integration, and/or regulatory pathways.
- Multimodal cognitive digital twin (language + audio + video + wearables)
- Description: Integrate prosody, articulation, facial expression, and activity/sleep data to improve sensitivity/specificity for MCI and progression.
- Sectors: Healthcare, Robotics, Consumer Electronics
- Potential tools/products/workflows:
- Product: Clinically oriented “Multimodal Cognitive Twin” platform
- Workflow: Multimodal fusion with temporal models; continuous learning
- Assumptions/Dependencies: new datasets; sensor/device integration; increased privacy risks; robust generalization across settings
- Regulatory-grade digital biomarker for remote cognitive screening
- Description: Validate MoCA-proxy from conversation as a cleared digital biomarker for Remote Patient Monitoring billing and clinical use.
- Sectors: Healthcare, Policy/Regulation, Insurance
- Potential tools/products/workflows:
- Workflow: Multi-site clinical validation studies; health economics analyses
- Product: FDA/CE-cleared software as a medical device (SaMD)
- Assumptions/Dependencies: extensive clinical trials; bias and fairness audits across dialects/languages; clear clinical utility
- EHR-integrated decision support for primary care and neurology
- Description: Auto-generate risk flags and suggested follow-up (e.g., formal assessment) based on conversational signals during routine visits or telehealth.
- Sectors: Health IT, Primary Care, Neurology
- Potential tools/products/workflows:
- Integration: FHIR APIs for ingesting transcripts and returning risk scores; audit logs and explainability summaries
- Assumptions/Dependencies: provider workflow fit; alert fatigue management; institutional governance
- Smart home and voice assistant monitoring with caregiver notifications
- Description: Embedded cognitive monitoring in smart speakers that adapt to user’s style and track changes, alerting caregivers when thresholds are crossed.
- Sectors: Consumer Electronics, Aging-in-place, Home Care
- Potential tools/products/workflows:
- Product: “Cognitive-Aware” voice assistant skill with twin-backed personalization
- Assumptions/Dependencies: always-on listening consent; robust on-device/offline options; sensitivity to false alarms
- Personalized non-pharmacological intervention planning and A/B testing
- Description: Use the digital twin to simulate and compare conversational engagement strategies, selecting those likely to benefit an individual.
- Sectors: Healthcare, Academia, Digital Therapeutics
- Potential tools/products/workflows:
- Platform: Twin-driven in-silico trials of conversation-based therapy; deploy best arm to the patient
- Assumptions/Dependencies: external validity of simulations; outcome tracking to close the loop
- Socially assistive robots with twin-aligned conversation and assessment
- Description: Robots that converse at a user’s preferred pace/style, maintain engagement, and periodically assess cognitive markers during daily interactions.
- Sectors: Robotics, Elder Care, Healthcare
- Potential tools/products/workflows:
- Product: Home companion robot with integrated twin and cVAE evaluator
- Assumptions/Dependencies: multimodal integration; safety and usability in unstructured environments; cost constraints
- Population-level screening through call centers and public services
- Description: Analyze consenting senior support hotline or care-management calls for cognitive risk signals and refer for assessment.
- Sectors: Public Health, Telecom-enabled Health Services, Payers
- Potential tools/products/workflows:
- Workflow: Batch processing of call corpora with cVAE scoring; referral pathways
- Assumptions/Dependencies: equitable performance across accents/languages; privacy and consent at scale; low positive predictive value may burden services
- Cross-lingual and cross-cultural twins for global health
- Description: Extend stylometric and cognitive models to multiple languages and cultural conversational norms for low-resource and diverse settings.
- Sectors: Public Health, Global Health, Academia
- Potential tools/products/workflows:
- Tools: Language-adaptive fine-tuning; culturally adapted prompts and evaluators
- Assumptions/Dependencies: new datasets across languages; culturally sensitive evaluation; localization resources
- Insurance and care-pathway optimization
- Description: Use validated conversational biomarkers to stratify risk and coordinate earlier interventions, potentially reducing downstream costs.
- Sectors: Insurance/Payers, Care Management
- Potential tools/products/workflows:
- Product: Risk stratification service ingesting call notes/transcripts; care navigation triggers
- Assumptions/Dependencies: regulatory/ethical considerations; transparency to avoid discrimination; strong validation of clinical utility
- Secure data-sharing frameworks using high-fidelity synthetic corpora
- Description: Share synthetic, twin-generated datasets for broader research while preserving participant privacy.
- Sectors: Academia, Policy, Software (Data Platforms)
- Potential tools/products/workflows:
- Platform: Synthetic data repository with cVAE-based similarity/privacy thresholds and differential privacy add-ons
- Assumptions/Dependencies: proven de-identification efficacy; governance for secondary use; standards for disclosure risk
These applications leverage the paper’s core innovations—stylometric augmentation with PAUSE/TEMPO, participant-conditioned SFT of an LLM, and a cVAE evaluator that jointly measures linguistic fidelity and cognitive alignment—and map them to concrete tools and workflows. Feasibility will hinge on data access and consent, ASR/diarization quality, generalizability beyond the small study cohort, clinical validation requirements, and rigorous privacy and fairness safeguards.
Glossary
- ASR (Automatic Speech Recognition): Technology that converts spoken language into text, often used to transcribe audio data. "Original transcripts contained ASR errors; we reprocessed audio using Whisper~\cite{radford2023robust}."
- Biomarker: A measurable indicator of a biological condition; here, linguistic features serve as non-invasive indicators of cognitive status. "In cognitive health, early detection of Mild Cognitive Impairment (MCI) remains challenging, where language and conversational patterns serve as non-invasive biomarkers."
- cVAE (Conditional Variational Autoencoder): A probabilistic generative model that conditions on input variables to learn a latent representation for reconstruction and auxiliary prediction. "To evaluate fidelity and cognitive consistency, we introduce a multi-head conditional variational autoencoder (cVAE) that jointly measures reconstruction quality and predicts cognitive scores."
- Diarization: The process of segmenting audio by speaker identity to attribute utterances to the correct speaker. "Speaker roles were separated using pyannote diarization~\cite{bredin2020pyannote}, ensuring accurate extraction of participant responses."
- Digital twin: A dynamic, data-driven virtual representation of a real-world entity used for simulation, analysis, and prediction. "Digital twins are virtual representations of physical entities that are continuously updated using real-world data, enabling simulation, analysis, and prediction of system behavior."
- DistilBERT: A compressed transformer-based LLM used for efficient NLP tasks such as sentiment analysis. "We use the distilbert~\cite{sanh2019distilbert} model to extract sentiment scores per sentence, aggregated using mean and standard deviation for both questions and answers."
- Embeddings (Sentence embeddings): Dense vector representations of sentences capturing semantic meaning for downstream tasks. "Sentence-level embeddings are computed using the model all-mpnet-base-v2~\cite{reimers2019sentence}."
- I-CONECT dataset: A dataset of longitudinal, naturalistic conversations from older adults used to study cognitive health. "We utilize the I-CONECT dataset~\cite{dodge2024internet}, derived from a randomized clinical trial on conversational engagement in older adults (75+), including both cognitively normal and MCI participants."
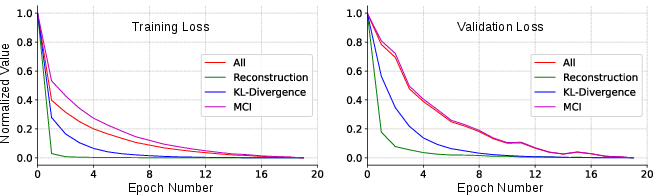
- KL divergence: A measure of how one probability distribution diverges from a reference distribution, used as a regularizer in VAEs. "Training combines reconstruction, KL divergence, and MCI prediction losses:"
- LLM: A transformer-based model trained on vast text corpora to perform language understanding and generation. "we propose a language-based digital twin framework that leverages LLMs to mimic the conversational behavior of elderly individuals by incorporating stylometric cues and contextual metadata."
- Latent representation: A compact, learned vector that captures underlying factors of variation in the data. "The encoder maps these inputs to a latent representation:"
- Latent space: The continuous space of latent variables in which the model represents data; typically parameterized by mean and variance. "The latent space is parameterized by mean and log-variance ."
- Lexical diversity: A measure of vocabulary variety within speech or text, often linked to cognitive status. "Language and speech have emerged as scalable and non-invasive biomarkers of cognitive decline, with features such as lexical diversity, fluency, and pauses correlating with cognitive status~\cite{martinez2021ten}."
- Mean Squared Error (MSE): A reconstruction loss measuring the average squared difference between predicted and true values. "The cVAE serves a dual purpose: measuring reconstruction quality via Mean Squared Error (MSE) and predicting MoCA scores from the input question, generated response, and metadata, enabling joint evaluation of linguistic fidelity and cognitive consistency."
- Mild Cognitive Impairment (MCI): A stage between normal aging and dementia characterized by noticeable cognitive decline not severe enough to interfere significantly with daily life. "Mild Cognitive Impairment (MCI) is a transitional stage between normal aging and dementia, where early detection is critical for timely intervention~\cite{petersen2014mild}."
- MoCA (Montreal Cognitive Assessment): A 30-point screening tool assessing multiple cognitive domains to detect cognitive impairment. "MoCA (Montreal Cognitive Assessment) is a 30-point cognitive screening tool assessing domains such as memory, attention, language, and executive function, where lower scores indicate greater impairment."
- Multimodal data: Data comprising multiple modalities (e.g., text, audio, physiological signals) integrated for richer modeling. "by integrating multimodal data such as clinical records, physiological signals, and behavioral observations."
- Neuroimaging: Imaging techniques (e.g., MRI, PET) used to visualize the structure or function of the brain for diagnosis. "However, traditional diagnostic approaches rely on structured assessments and neuroimaging, which are costly, infrequent, and limited in capturing gradual changes in everyday behavior~\cite{jack2018nia}."
- PCA (Principal Component Analysis): A dimensionality reduction technique that projects data onto orthogonal components capturing maximal variance. "Session-level embeddings were generated using Sentence-BERT~\cite{reimers2019sentence} and reduced via PCA to obtain topic descriptors for cVAE inputs."
- Precision medicine: Tailoring medical treatment to individual characteristics using detailed modeling and data. "Beyond cognitive health, digital twin systems have also been applied in domains such as cardiac modeling and precision medicine~\cite{corral2020digital,bjornsson2019digital}."
- Sentence-BERT (SBERT): A model that produces semantically meaningful sentence embeddings using a siamese/bi-encoder setup. "Session-level embeddings were generated using Sentence-BERT~\cite{reimers2019sentence} and reduced via PCA to obtain topic descriptors for cVAE inputs."
- Stylometric cues: Quantitative features of writing or speech style (e.g., pause length, tempo) used to capture individual linguistic patterns. "The proposed approach captures linguistic style, temporal dynamics, and cognitive signatures by incorporating stylometric cues such as pause and tempo, along with contextual metadata, enabling the generation of personalized responses that resemble real human behavior."
- Supervised Fine-Tuning (SFT): Adapting a pre-trained model to a specific task using labeled examples. "We adopt GPT-4.1-mini as the base model and adapt it through supervised fine-tuning."
- Support Vector Machine (SVM): A supervised learning algorithm for classification that finds a maximum-margin decision boundary. "We evaluate identity preservation using an SVM classifier to determine whether generated responses can be attributed to the correct participant."
- Transformer-based: Describing models built on the Transformer architecture, which uses self-attention mechanisms. "Fard et al.~\cite{fard2024linguistic} introduced a Transformer-based approach to capture temporal linguistic patterns."
- Whisper: An open-source ASR system used to transcribe and correct audio data. "we reprocessed audio using Whisper~\cite{radford2023robust}."
Collections
Sign up for free to add this paper to one or more collections.

