Closing the Loop to Discover Psychological Theories with an Automated Cognitive Scientist
Abstract: Across the sciences, autonomous systems are increasingly being used in closed-loop discovery, proposing new theories and designing and running experiments to test them. This approach is yet to be applied in the field of cognitive science, where the central bottleneck is theory-building: the creative step of turning the accumulated failures of existing models into better ones. Theory generation has remained manual even as data collection, modeling, and experiment design have been automated. We present the Automated Cognitive Scientist (AutoCog), a fully autonomous agentic-AI system that closes this loop. Large-language-model agents advocate competing theories, each expressed as an executable cognitive model, design experiments that best discriminate them, collect behavioral data from participants recruited online, score theories against collected data based on their generative performance, diagnose why they fail, and synthesize a better successor. Repeating this cycle allows them to search the space of theories, models, and experiments. In the domain of decision-making, AutoCog recovered known decision-making strategies from simulated behavior, including unconventional ones, showing that its discoveries are ultimately driven by the data rather than strictly bound by the priors of the underlying LLMs. When run with human participants, it produced theories that outperformed the established theories it was seeded with and generalized to held-out studies in two different experimental settings. It also surfaced a novel theory of multi-cue decision-making in which choices show diminishing sensitivity to feature values. The distinctive predictions of this theory were confirmed in a preregistered study with new participants. AutoCog demonstrates how an automated discovery system can be used to turn cognitive theory-building into an explicit, executable, and cumulative science.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper introduces AutoCog, an “automated cognitive scientist.” It’s an AI system that does the full science cycle on its own to discover how people think and make decisions. Instead of just running one step (like collecting data), AutoCog:
- suggests new theories about how people decide,
- designs experiments to test those theories,
- runs the experiments with real people online,
- checks which theory best matches the results, and
- improves or replaces the weaker theory.
By repeating this loop, the system learns better and better explanations of human decision-making.
The big questions the paper asked
- Can an AI system invent and improve psychological theories, not just analyze data?
- If given some starting ideas (like well-known decision strategies), can it discover the correct strategy that generated the data?
- When tested with real people, can it create new theories that predict behavior better than classic ones?
- Can it uncover genuinely new patterns in how people choose?
How AutoCog works (in everyday terms)
Think of science as a loop: plan → test → learn → improve → repeat. AutoCog automates that loop.
Here’s the idea using an analogy: imagine two coaches with different training plans (theories). AutoCog asks, “What drills (experiments) would make their predictions differ the most?” It runs those drills with players (participants), sees who performs as predicted (data), judges which plan fits better, and then helps the weaker coach redesign their plan (revise the theory). Then it repeats.
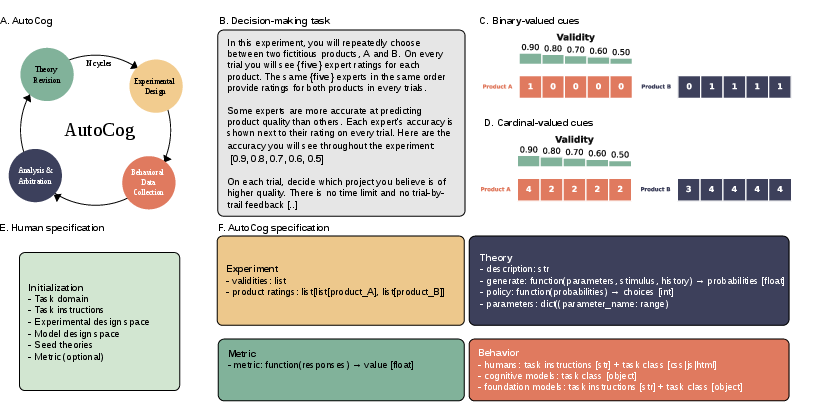
AutoCog’s loop has four steps:
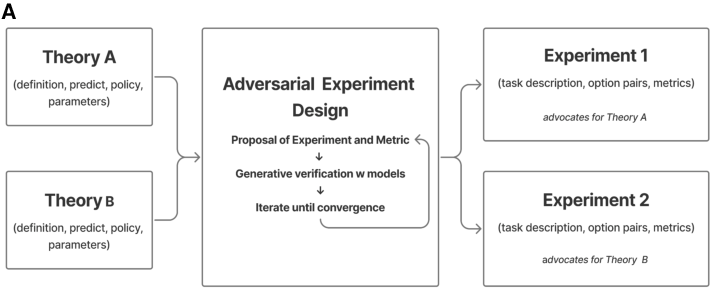
- Experimental design: It picks or creates tasks where the current two theories disagree the most. That makes the test informative.
- Behavioral data collection: It runs the tasks with people online (sometimes also with computer models or AI stand-ins).
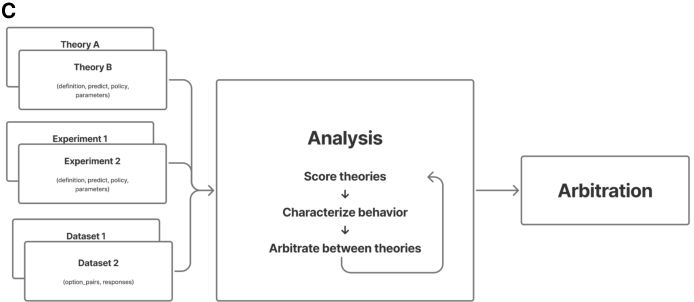
- Analysis and arbitration: Instead of forcing models to fit the data, it “presses play” on each theory’s code to generate what it would do, then compares those predictions to what people actually did. An AI “arbiter” explains who did better and why.
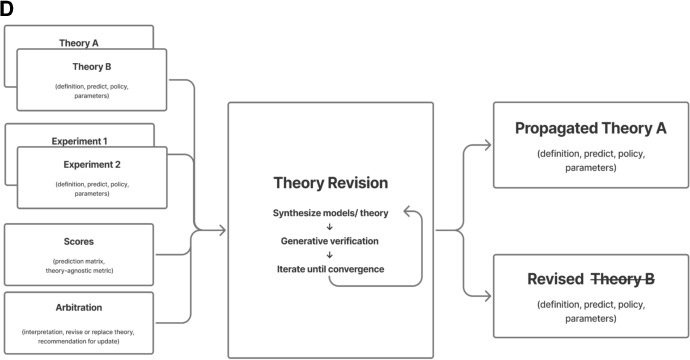
- Theory revision: The weaker theory is rewritten or replaced as executable code (a working program), using AI to synthesize a better idea that addresses the failures.
Key terms in simple language:
- Theory as code: A theory isn’t just words; it’s a small computer program that outputs choices. Think of it as a recipe you can run to see what it would choose on each trial.
- Closed loop: The system completes the full plan–test–learn–improve cycle repeatedly, not just one part.
- Generative comparison: Rather than bending a model to match data, you let the model act, then compare its actions to humans’ actions.
What experiments they ran
They focused on decision-making where people pick between two products described by several “cues” (like expert ratings). They tried two versions of the task:
- Binary cues: Each cue is either 0 or 1 (e.g., no vs. yes).
- Cardinal cues: Each cue is an integer like 0 to 5 (so size of differences matters).
They seeded AutoCog with classic strategies:
- Take-The-Best (TTB): Look at the most important cue first and decide as soon as that cue differs.
- Tallying: Count how many cues favor each option; pick the one with more.
- WADD (Weighted Additive): Sum up cue values, multiplying each by how reliable that cue is (its “validity”).
They tested AutoCog in two ways:
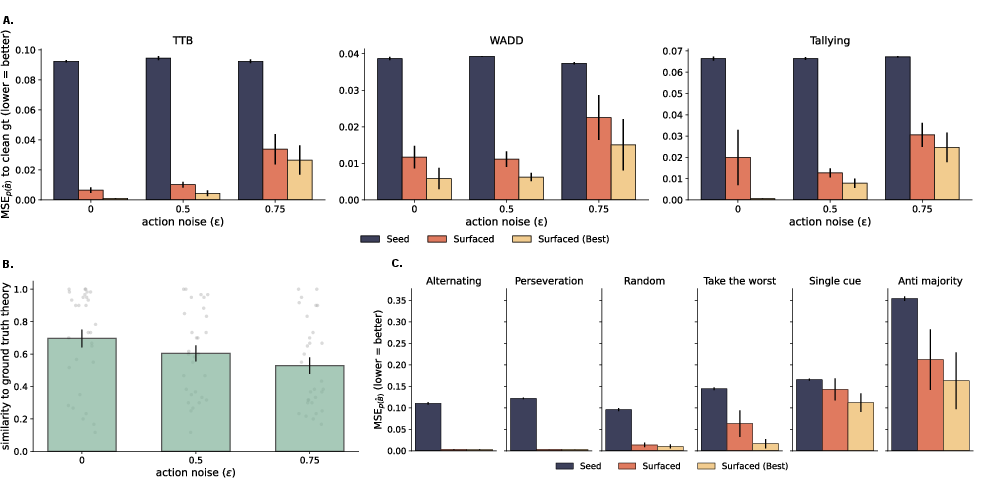
- With simulated data: Could it rediscover the true strategy that generated the data (including some unusual strategies like alternating choices or sticking with the last choice)?
- With real people online: Could it improve on the starting theories and find better ones that generalize to new studies?
Main findings and why they matter
- Recovery of known and unusual strategies
- With simulated data, AutoCog reliably rediscovered the ground-truth strategy—even when the data had noise (randomness).
- It also learned less common patterns (like alternating choices or always picking the worse option) after enough cycles. This shows the system isn’t just biased toward famous theories; it can follow the data.
Why it matters: It proves the loop can “home in” on the correct explanation, not just repeat what it already knows.
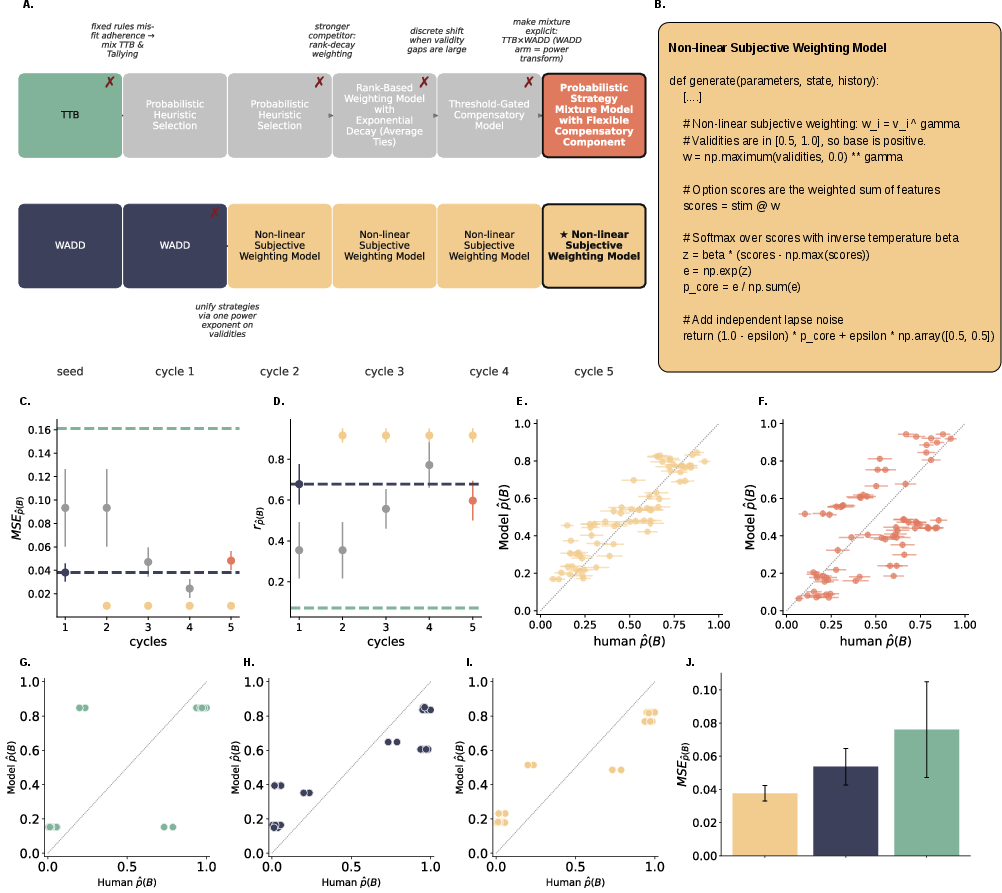
- Discovery with real people (binary cues)
- AutoCog proposed a simple but powerful idea: people transform cue importance in a non-linear way (like raising it to a power) before summing—so the same framework can behave like tallying, WADD, or TTB depending on that one exponent.
- This new model predicted human choices better than the seed theories and matched results from a classic, separate study—showing it generalized.
Why it matters: A single, compact theory can explain several well-known strategies as special cases.
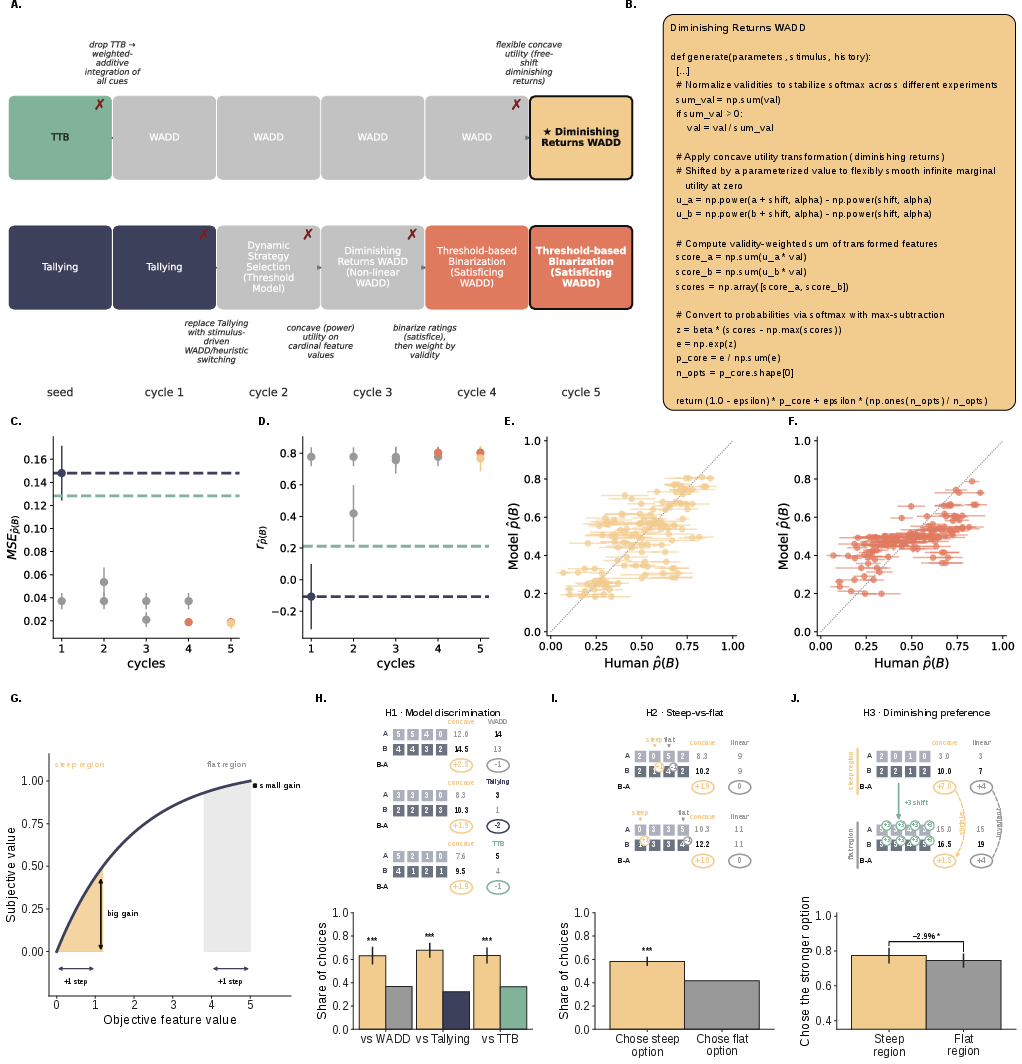
- Discovery with real people (cardinal cues) and a new psychological pattern
- When cue values could be big or small (0–5), AutoCog found a new twist: people show diminishing sensitivity to cue size. In plain terms, an increase from 1 to 2 “feels” bigger than an equal increase from 4 to 5. That’s like a “diminishing returns” curve—steep at the start and flatter later.
- AutoCog also surfaced a second, simpler idea: people might turn multi-level ratings into pass/fail based on a threshold, then do a weighted tally. Both models beat the seed theories, but the diminishing-returns model was chosen as best.
Why it matters: This “diminishing returns” pattern is a new, testable rule about human choice in this setting, similar in spirit to the famous idea from prospect theory that we feel changes less when we’re already at a high level.
- A preregistered, forward-looking test confirmed the new theory
- The team preregistered three predictions (ahead of time) and ran a new study:
- On trials designed to split the models, people matched the diminishing-returns model more often than the classic models.
- Equal-sized steps mattered more in the low-value range than in the high-value range (steep-vs-flat effect).
- The same pattern “weakened” when the whole scale was shifted up (level-shift effect).
All three predictions were supported.
Why it matters: This is strong evidence that the newly discovered theory captures how people actually choose—not just in hindsight, but in fresh data planned in advance.
What this could mean for science
- Faster, clearer theory-building: AutoCog turns the creative step of forming new theories into an explicit, executable process. Every step—experiments, code, data, decisions—is logged, so the discovery path is auditable and cumulative.
- Broader and better testing: Because the loop designs targeted experiments where theories disagree the most, it can learn faster and waste less effort.
- Human–AI partnership: People still set the goals and boundaries (what tasks and model forms to explore). The AI explores within those guardrails and proposes improvements.
- Scalable discovery: In some domains, early loops might run “in-silico” (with AI stand-ins) before moving to real participants, saving time and cost—then confirming with humans where it counts.
- New insights into the mind: The diminishing-returns pattern suggests people compress big values—an idea that could connect to how we judge money, time, risk, and more.
A few caveats:
- The system can only search within the experiment and model spaces we give it. If the right idea lies outside those boundaries, it won’t find it.
- It wasn’t explicitly rewarded for “simplicity” or “interpretability,” though many surfaced theories ended up being quite simple.
- Results depend on good experimental design, careful participant recruitment, and fair comparisons—all of which the loop works to automate responsibly.
Bottom line
AutoCog shows that an AI can do more than analyze data—it can help invent, test, and refine psychological theories in a full, repeating loop. It rediscovered known strategies, found a compact model that unifies classic ideas, and uncovered a new, confirmed pattern in how people weigh information: diminishing sensitivity to larger cue values. This points toward a future where building theories about the mind becomes more transparent, testable, and steadily improving.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, stated concretely to guide follow-up research.
Scope and generalization
- The system is only demonstrated in two-alternative, multi-attribute choice; it is unknown whether AutoCog scales to multi-option choice sets, ranking, or continuous response settings.
- Generalization to other cognitive domains (e.g., category learning, memory, language, reinforcement learning, planning, causal reasoning) is untested.
- All human data come from online convenience samples; cross-cultural, developmental, clinical, or high-stakes contexts are not evaluated.
- External validation uses a single held-out literature dataset; performance across a broader suite of standardized benchmarks is unknown.
- Discovered “diminishing returns” on cue magnitudes is not positioned against established multi-attribute utility theory and multi-attribute/prospect-theory models (e.g., concave attribute utilities, configural weighting); it is unclear whether the surfaced account is novel, equivalent, or a re-derivation of known formulations.
Model design space and identifiability
- The theory/model interface appears to support only trial-level choice probabilities with limited use of history; applicability to learning dynamics, attentional switching, sequential sampling, or memory-based process models is unclear.
- No formal parameter estimation (individual or hierarchical) is performed; how parameters are set/aggregated for predictions is unspecified, and parameter uncertainty is not quantified.
- Model comparison relies on pooled MSE of choice proportions; likelihood-based metrics, predictive log-loss, WAIC/LOO, or Bayes factors with complexity control are not used, risking favoring flexible models without penalties.
- Pooled proportion metrics ignore within-subject patterns and heterogeneity; the system does not report individual-level predictive accuracy or hierarchical fits.
- Identifiability among closely related candidates (e.g., Diminishing Returns WADD vs. Threshold-based Binarization/Satisficing WADD) is not fully probed; there is no preregistered head-to-head discrimination between these two finalists.
- Non-additive cue interactions, context effects, and configural processing are not explicitly explored; it is unknown if the search space permits such mechanisms.
Experimental design, metrics, and arbitration
- Adversarial experimental design is LLM-driven; there is no comparison to formal optimal experimental design (e.g., information gain) or power analyses, nor guarantees on statistical efficiency.
- LLM-proposed metrics are “self-verified,” but the risk of metric selection bias and miscalibration (Type I/II error) is not assessed; statistical properties of the metrics across cycles remain unspecified.
- Arbitration and revision are performed by LLMs; stability across random seeds, prompt variants, and agent configurations, as well as agreement with human experts, is not reported.
- The search uses two concurrent theories per cycle; the effect of beam width, exploration–exploitation trade-offs, and path dependence on the seeds is not quantified.
- Focusing designs on current-theory disagreements may miss stimuli informative for discovering mechanisms outside the incumbents’ span; coverage of the broader stimulus space is not measured.
LLM dependence and robustness
- Discovery may be biased by LLM priors; while some unconventional strategies are recovered, the magnitude and structure of this bias across domains and prompts are not characterized.
- Only one foundation model (Gemini 3.1) is used; cross-LLM robustness (model family, temperature, system prompts) and sensitivity to prompt engineering are not evaluated.
- The “LLM-as-judge” measure of mechanism similarity is not validated against human expert ratings or alternative automated criteria; its reliability and calibration are unknown.
- Safety of LLM-generated code (sandboxing, dependency control) and protections against prompt injection or data leakage are not detailed.
Human experiments and data quality
- Per-experiment sample sizes are small (n≈25); statistical power per cycle and resulting sensitivity to detect model differences are not established.
- Attention/comprehension checks, exclusion criteria, and incentive structures are not described here; data-quality controls and their effects on results remain unclear.
- Only choices are modeled; richer signals (reaction times, confidence, process tracing, eye-tracking) that could distinguish theories are not collected or analyzed.
- Noise is treated as simple lapse/ε-greedy; more realistic structured noise models, individual variability, and trial-by-trial nonstationarities are not incorporated.
Validation, reproducibility, and efficiency
- Human closed-loop results are shown for one run per setting; variability and reproducibility across independent runs are not reported.
- Computational cost, wall-clock time, and resource requirements of the closed loop (LLM calls, synthesis, verification, data collection) are not provided, limiting assessment of scalability.
- The availability of code, prompts, experiment logs, and data for full reproducibility is not specified in the main text.
- There is no head-to-head comparison with alternative automated-discovery pipelines (e.g., GeCCo/ASMR) on identical tasks/datasets to quantify relative efficiency and quality.
Ethical and governance considerations
- Procedures for ethical oversight (e.g., IRB, content moderation, participant risk mitigation) in fully autonomous study deployment are not detailed.
- Governance mechanisms to prevent harmful, deceptive, or manipulative experiments/metrics and to enforce pre-registration and audit trails are not described.
Task assumptions and external validity
- Experiments assume validities are explicitly shown to participants; generalization to settings where reliabilities must be learned or inferred over time is untested.
- Only 4–5 cues and two options are used; behavior with larger attribute sets, sparsity, or correlated cues is not examined.
- Normalization choices (e.g., validity normalization across experiments) may affect comparability; sensitivity analyses for these preprocessing steps are not reported.
Open methodological extensions
- How to integrate explicit objectives for parsimony, unification, and interpretability into the loop (beyond predictive performance) remains open.
- The potential of in-silico pre-screening (foundation models as participants) to reduce human data collection without biasing discoveries is not validated.
- Methods for adaptive sample sizing and sequential experimental design within cycles (e.g., stopping rules, multi-armed bandit allocation) are not explored.
- Meta-discovery—learning or expanding the experiment/model design spaces themselves—has not been attempted.
- Incorporation of multi-modal constraints (e.g., neural/physiological data) to narrow theory space is not addressed.
Practical Applications
Below is a concise mapping from the paper’s findings and methods to practical, real-world applications. Each item notes sector(s), what can be done, and the main assumptions/dependencies that affect feasibility.
Immediate Applications
- Sector: Software, e-commerce, marketing, UX research
- Use AutoCog-like workflows to propose discriminating A/B/n tests that pit concrete behavioral hypotheses against each other, recruit participants online, and select the winning design/copy/flow based on generative model predictions rather than post-hoc fitting.
- Bundle as a “Behavioral Experiment Copilot” integrated with Qualtrics/SurveyMonkey/Prolific for near-automatic study launch, arbitration, and iteration.
- Tools/workflows that might emerge:
- Adversarial experimental design module that auto-generates stimuli where candidate explanations diverge.
- Audit-trace dashboards that log the full loop for reproducibility and governance.
- Assumptions/dependencies:
- Ready access to online participant pools; IRB/ethics alignment for rapid experimentation; LLM reliability and guardrails; clear specification of experiment and model design spaces.
- Sector: Software, search/recommendation, marketplaces, hiring, ad-tech
- Update scoring functions to apply a concave (diminishing-returns) transformation to attribute magnitudes before weighting by reliability, reflecting the paper’s “Diminishing Returns WADD” result.
- Prioritize improvements on low-rated attributes rather than over-optimizing already-high ones (e.g., product quality subscores, candidate screening attributes, ad quality metrics).
- Tools/workflows that might emerge:
- A drop-in “nonlinear weight transform” library: score = softmax(Σ w_i * f(x_i)), with f concave (e.g., power law with exponent < 1).
- Offline replay and shadow-mode A/B to validate ranking changes and monitor fairness.
- Assumptions/dependencies:
- The discovered diminishing-sensitivity regularity generalizes to your domain; availability of reliable cue validities; fairness audits to ensure the transform doesn’t entrench disadvantage on protected groups.
- Sector: Healthcare, finance, government services
- Redesign patient/investor/benefit choice interfaces to emphasize gains on low-range attributes (e.g., small reductions in co-pay or risk where baseline is low), which people weight more heavily than equal gains at high ranges.
- Present trade-offs using visualizations that highlight low-range improvements.
- Tools/workflows that might emerge:
- “Choice-Impact Calculator” that predicts user preference shifts under concave value assumptions; template libraries for steep-region-focused messaging.
- Assumptions/dependencies:
- Domain-specific validation and ethical review (e.g., avoiding manipulation); ability to estimate or elicit attribute validities and ranges; compliance with sector regulations.
- Sector: Academia (cognitive science, behavioral science, HCI)
- Use AutoCog-style loops to propose, verify, and run discriminating experiments; synthesize executable models for theory revision; publish the machine-readable trace as a research artifact.
- Tools/workflows that might emerge:
- “Theory Synthesis IDE” for programmatic model generation and self-verification; preregistration templates auto-filled from the loop’s arbitration/metrics.
- Assumptions/dependencies:
- Institutional IRB acceptance of LLM-assisted design; computational budget for multiple cycles; standards to report LLM prompts/outputs for transparency.
- Sector: ML/AI evaluation and safety
- Use the loop to create tasks that maximally discriminate between competing AI agent policies (e.g., prompting strategies, RL policies) without fitting to data.
- Tools/workflows that might emerge:
- “Behavioral Benchmark Generator” for LLMs/agents with generative arbitration and auto-metric proposal.
- Assumptions/dependencies:
- Clear specification of agent inputs/outputs; sandboxed evaluation; guardrails to avoid prompt leakage or test contamination.
- Sector: Market research, insights agencies
- Use behavioral foundation models as a first-pass stand-in for humans to down-select candidate experiments or messaging; confirm finalists with human samples.
- Tools/workflows that might emerge:
- “Hybrid Panel” workflow (foundation model → human) with confidence thresholds and divergence diagnostics.
- Assumptions/dependencies:
- Match between foundation-model behavior and target population; explicit calibration and rejection criteria to avoid over-reliance on synthetic responses.
- Sector: EdTech, assessment
- Auto-design item sets that separate candidate cognitive strategies (e.g., rule-based vs. weighted-integration) and use generative comparison to choose instructional adaptations.
- Tools/workflows that might emerge:
- Assessment item generator that emphasizes strategy-identifiability; teacher-facing dashboards with model-based diagnostics.
- Assumptions/dependencies:
- Alignment with curricular standards; student data privacy; validation of theory generalization from lab tasks to classroom contexts.
- Sector: Policy communication and public services
- Use AutoCog-like loops with representative panels to compare message frames where behavioral predictions diverge and document the evidence trail.
- Tools/workflows that might emerge:
- “Policy Message Lab” with preregistration-by-default, audit logs, and harm-minimization checks.
- Assumptions/dependencies:
- Ethical oversight; demographic representativeness; constraints on automated human-subjects experimentation in public agencies.
Long-Term Applications
- Sector: Cross-industry R&D, academia
- Always-on closed-loop systems that continuously propose theories, run discriminating experiments across panels, revise models, and update organizational knowledge bases.
- “Theory Graph Repositories” that track lineage, arbitration decisions, and generalization across tasks/populations.
- Assumptions/dependencies:
- Scalable participant recruitment with diversity guarantees; robust governance (consent, privacy, bias mitigation); budgeted compute and human-in-the-loop oversight.
- Sector: EdTech, digital therapeutics, personalization
- Auto-discovered subpopulation- and individual-level theories driving adaptive tutoring, habit formation, or adherence support; real-time experiment selection to learn “what works for whom.”
- Assumptions/dependencies:
- Longitudinal data, privacy-preserving analytics, and regulatory clearance (e.g., for medical claims); reliable detection of strategy shifts over time.
- Sector: Robotics, HRI, autonomous systems
- Robots and agents that discover domain-specific human decision heuristics (e.g., how operators trade off speed vs. safety) and adjust interaction policies accordingly.
- Assumptions/dependencies:
- Safe, real-world experiment integration; sample-efficient loops (human time is costly); standards for testing in safety-critical contexts.
- Sector: Public policy and governance
- Closed-loop platforms that iteratively refine regulations, benefits enrollment flows, or crisis communications using discriminating experiments; audit trails that meet legislative transparency requirements.
- Assumptions/dependencies:
- New regulatory frameworks for autonomous experimentation; independent oversight boards; equity and harm assessments as hard constraints.
- Sector: Healthcare research and clinical trials
- Automated theory building for how patients respond to multi-attribute trade-offs (cost, side effects, efficacy), informing trial design or digital therapeutic content.
- Assumptions/dependencies:
- FDA/EMA and IRB approvals; integration with EHRs and secure consent flows; rigorous preregistration and monitoring.
- Sector: Finance, retail investing, insurance
- Theory-guided disclosures that account for diminishing sensitivity in multi-factor products (fees, returns, risk), tested in closed loops with suitable panels.
- Assumptions/dependencies:
- Regulatory guardrails on experimentation; suitability and fairness reviews; explainability requirements.
- Sector: Energy and sustainability
- Iterative discovery of how households weigh multi-attribute offers (rebate, comfort, peak timing), with diminishing-return-aware presentations to boost uptake.
- Assumptions/dependencies:
- Utility partnerships, seasonal dynamics, and privacy-preserving data collection; evaluation across diverse communities.
- Sector: ML/AI tooling and safety
- Synthesis pipelines with static analysis and formal methods to guarantee properties (e.g., monotonicity, boundedness) of generated models; red-teaming of experiment proposals.
- Assumptions/dependencies:
- Advances in code synthesis verification; standards for explainability and interpretability; integration with MLOps governance.
- Sector: Cognitive science and psychology
- Expanded model/experiment spaces enabling discovery beyond decision making (e.g., learning rules, generalization patterns), with preregistered, prospective validations.
- Assumptions/dependencies:
- Richer task batteries, more diverse participant panels, domain-specific metrics, and ethics frameworks adapted to sensitive topics.
- Sector: Standards and policy
- Standards for auditability, consent, preregistration, data use, and LLM-agent involvement; certification programs for “responsible automated experimentation.”
- Assumptions/dependencies:
- Multistakeholder consensus (academia, industry, regulators, civil society); incident reporting and enforcement mechanisms.
Notes on cross-cutting assumptions and dependencies
- Model and experiment design spaces must be thoughtfully bounded; garbage-in yields poor theories regardless of automation.
- LLMs need guardrails, verification, and iterative prompting; program synthesis outputs must be executable and sandboxed.
- Human-subjects protections (IRB, consent, privacy) and domain-specific regulations (e.g., healthcare, finance) are essential constraints.
- Foundation-model stand-ins require validation of human–model fidelity; use hybrid pipelines to mitigate mismatch.
- Generalization is not guaranteed; replicate across tasks, populations, and contexts; use preregistration and holdouts as in the paper.
- Fairness and equity considerations are first-class requirements whenever models impact people’s opportunities or outcomes.
Glossary
- Adversarial experimental design: A paradigm that selects experiments to maximally distinguish competing models by targeting where they disagree. Example: "adversarial experimental design"
- Agentic-AI system: An AI setup composed of autonomous agents that plan and act to achieve goals across a pipeline without human intervention. Example: "agentic-AI system"
- Alternating (strategy): A non-canonical decision policy that alternates choices across trials regardless of stimuli. Example: "alternating"
- Anti-majority (strategy): A non-canonical decision policy that chooses against the option supported by the majority of cues. Example: "anti-majority"
- Arbitration (LLM-agent-based): A stage where an LLM agent interprets evidence and recommends which theory to revise or retain. Example: "LLM-agent-based arbitration procedure"
- Behavior adapter: A component that presents the same task uniformly to humans, cognitive models, and foundation models for comparable data. Example: "Behavior adapter"
- Behavioral foundation model: A large model used as an in-silico proxy for human behavior in cognitive tasks. Example: "behavioral foundation model"
- Cardinal ratings: Feature values expressed on a multi-level numeric scale (e.g., 0 to r_max), reflecting magnitude. Example: "cardinal ratings"
- Closed-loop discovery: An end-to-end scientific cycle where hypotheses, experiments, data collection, and theory revision are automated and iterated. Example: "closed-loop discovery"
- Compensatory strategy: A decision approach that integrates information across all cues, allowing strengths on some dimensions to offset weaknesses on others. Example: "a compensatory strategy (Weighted Additive)"
- Concave utility function: A transformation of feature values that yields diminishing marginal increases in subjective value as objective values grow. Example: "concave utility function"
- Cue validity: The reliability or predictive accuracy associated with a cue used to weight its influence on decisions. Example: "validities"
- Diminishing Returns WADD: A weighted-additive model that applies a concave utility transform to cue values before validity-weighted integration. Example: "Diminishing Returns WADD"
- Diminishing sensitivity: The property that differences between large feature values matter less than equal-sized differences between small values. Example: "diminishing sensitivity to feature values"
- Epsilon-greedy rule: A noise model where, with probability ε, choices are replaced by random selections irrespective of model predictions. Example: "an-greedy rule"
- Foundation models: Large pretrained models (e.g., LLMs) used as general-purpose components or simulators within scientific pipelines. Example: "foundation models"
- Generative behavior: Model-based simulated responses used to compare theories by forecasting full distributions of behavior. Example: "generative behavior"
- Generative performance: How well a theory’s generative model reproduces observed data, used for theory scoring. Example: "generative performance"
- Holm procedure: A multiple-comparisons correction method controlling family-wise error by stepwise adjusted p-values. Example: "Holm procedure"
- In-silico: Conducted via computer simulation rather than with human participants or physical experiments. Example: "in-silico stand-in"
- Large-language-model agents: Autonomous LLM-driven agents assigned roles such as theorist, experiment designer, or arbiter. Example: "Large-language-model agents"
- Lapse rate: The proportion of trials on which choices are random or inattentive, independent of stimuli. Example: "high lapse rate"
- Linear mixed-effects model: A statistical model combining fixed effects and random effects (e.g., random intercepts per experiment) to analyze repeated or grouped data. Example: "linear mixed-effects model"
- Multi-attribute decision-making: Choice scenarios where options are described by multiple features (cues) that must be integrated to decide. Example: "multi-attribute decision-making"
- Multi-attribute utility theory: A framework modeling choices by computing and combining utilities across multiple attributes, often with subjective value functions. Example: "multi-attribute utility theory"
- Non-compensatory heuristic: A rule-based strategy (e.g., TTB) that focuses on the most important cue(s) and does not trade off across attributes. Example: "a non-compensatory heuristic (Take-The-Best)"
- Non-linear Subjective Weighting Model: A model where cue validities are transformed nonlinearly (e.g., via a power function) before weighted summation. Example: "Non-linear Subjective Weighting Model"
- Optimal experimental design: Methods that choose experiments to maximize expected information gain or model discrimination. Example: "optimal experimental design"
- Perseveration (strategy): A non-canonical policy that repeats the previous choice regardless of current evidence. Example: "perseveration"
- Probabilistic Strategy Mixture Model: A model positing that people stochastically switch between strategies (e.g., TTB and WADD) on each trial. Example: "Probabilistic Strategy Mixture Model with Flexible Compensatory Component"
- Program synthesis: Automatically generating executable code (e.g., cognitive models) from specifications or natural language descriptions. Example: "program synthesis"
- Preregistered study: A study whose hypotheses and analysis plans are registered before data collection to curb researcher degrees of freedom. Example: "preregistered study"
- Satisficing: Choosing an option that meets a threshold rather than optimizing; here implemented by binarizing cardinal cues. Example: "Satisficing WADD"
- Self-driving laboratories: Automated lab systems that design and run experiments without human-in-the-loop execution. Example: "self-driving laboratories"
- Self-verifying: A practice where proposed models or experiments are checked against their own predictions before observing data. Example: "self-verifying"
- Softmax choice: A probabilistic choice rule mapping option values to choice probabilities via a temperature-controlled exponential (softmax) function. Example: "softmax choice with lapse noise"
- Take-the-worst (strategy): A non-canonical heuristic that selects the option with the worst value on the most important differing cue. Example: "take-the-worst"
- Take-the-Best (TTB): A non-compensatory heuristic that bases decisions on the most valid cue that discriminates between options. Example: "Take-the-Best (TTB)"
- Tallying: A simple heuristic that counts the number of favorable cues per option without weighting by validity. Example: "Tallying"
- Threshold-based binarization: Converting multi-level ratings into binary indicators based on a satisficing threshold before applying WADD. Example: "Threshold-based Binarization (Satisficing WADD)"
- Validity-weighted sum: Aggregating cues by weighting each by its validity and summing to compute an option’s score. Example: "validity-weighted sum"
- Weighted-Additive (WADD): A compensatory model that sums cue values weighted by their (subjective or provided) validities. Example: "Weighted-Additive (WADD)"
Collections
Sign up for free to add this paper to one or more collections.

