Emergent Capabilities Arise Randomly from Learning Sparse Attention Patterns
Abstract: Neural scaling laws for transformer LLMs predict smooth improvements in pretraining loss with increasing parameters, but downstream capabilities such as in-context learning are known to emerge abruptly past a certain model scale. In this paper, we show that emergent capabilities arise stochastically throughout training, with larger models acquiring them earlier on average. We demonstrate that the emergence of capabilities such as pattern completion and indirect object identification corresponds to the abrupt learning of task-relevant attention patterns. To isolate this phenomenon, we train transformer models on synthetic linear map and cellular automata datasets, and we show that the difficulty of learning attention patterns depends on context length and pattern sparsity. Moreover, scaling the number of attention heads improves learning efficiency on our synthetic tasks, while increasing the head dimension yields diminishing returns past a minimum capacity. We additionally investigate architectures with alternative attention mechanisms, showing that MLP-Mixer outperforms a transformer on linear map tasks with complex attention patterns. Our findings provide a mechanistic insight into emergence, showing that downstream capabilities arise abruptly due to the intrinsic difficulty of learning sparse attention patterns in transformer models.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big idea)
This paper tries to answer a simple question: Why do bigger LLMs suddenly learn new skills (like copying patterns or following rules) instead of getting better little by little? The authors show that these “aha!” moments happen when the model finally figures out the right “attention patterns” — basically, which earlier parts of the text it should look at to make the next prediction. Learning these patterns is hard, and that difficulty explains why new abilities appear suddenly and sometimes randomly during training.
What questions the researchers asked
They focused on five main questions, in everyday terms:
- Why do some skills pop up suddenly during training instead of growing gradually?
- Why do some models learn a skill while others (trained the same way) don’t?
- What exactly changes inside the model when a skill appears?
- What makes the “look-at-the-right-places” attention patterns hard to learn?
- Can changing the model’s design make it learn these patterns more easily?
How they studied it (methods in simple language)
To keep things clear and testable, they used two kinds of experiments.
1) Watching real LLMs learn
- They looked at a family of transformer models (same design, different sizes).
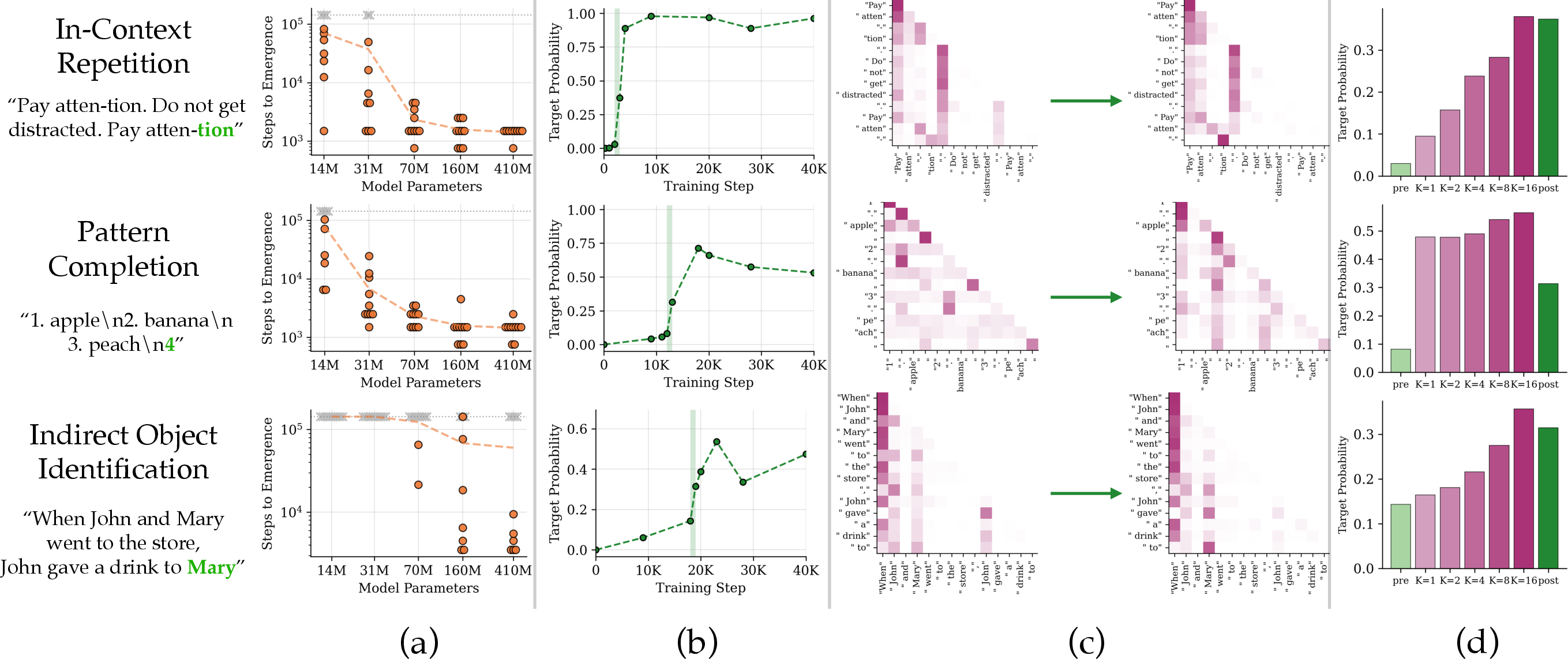
- They tracked training over time on small tasks like:
- Copying a repeated sequence (e.g., 1…9 followed by 1…8 → predict 9).
- Completing patterns and identifying which word relates to which (indirect objects).
- They checked when a model suddenly started getting the right answer with high confidence.
- They then looked inside the model’s “attention” — think of attention as spotlights that shine from the word being predicted to earlier words that might help. An “attention pattern” is the way those spotlights are arranged.
Key trick: They took the learned attention pattern from the “after the aha moment” model and pasted it into an earlier checkpoint (“before the aha moment”) to see if that alone makes the model succeed. This is like borrowing a friend’s highlight notes and seeing if you can answer the question right away.
2) Building simple, controlled “toy worlds”
Real language is messy. So they made two clean testbeds where the correct attention pattern is known:
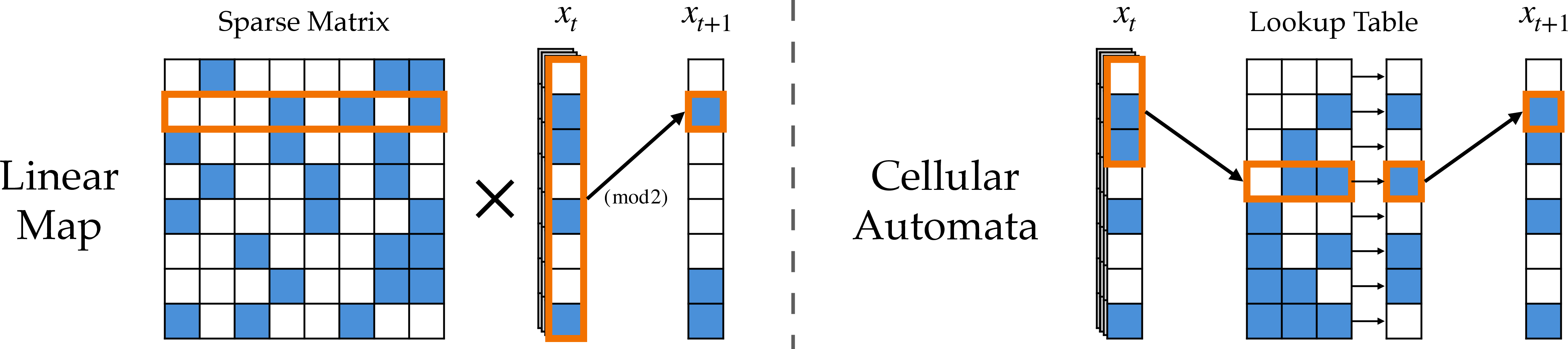
- Linear map task:
- Imagine a row of bits (0s and 1s). Each new bit is decided by checking a few specific earlier bits and combining them (like flipping a light if an odd number of those earlier lights are on).
- The model has to learn to “look at exactly those few bits” — a sparse pattern (few important places among many).
- Cellular automata task:
- Think of a long line of colored cells. Each cell’s next color depends on its three neighbors (left, itself, right) using a fixed rule.
- Sometimes, they mixed multiple rules, so the model had to figure out which rule was active just from the earlier part of the sequence.
- Here, the attention pattern is simple (always look at a small window), but the “context length” (how long the line is) can be very large, making it harder to find the right spots.
They also tested different model designs:
- More or fewer “attention heads” (you can think of heads as separate mini-spotlight teams that each look for different patterns).
- Different head sizes (how much each head can store).
- A different architecture called MLP-Mixer, which mixes information in a fixed way instead of using attention.
What they found (main results and why they matter)
Here are the key takeaways, expressed simply:
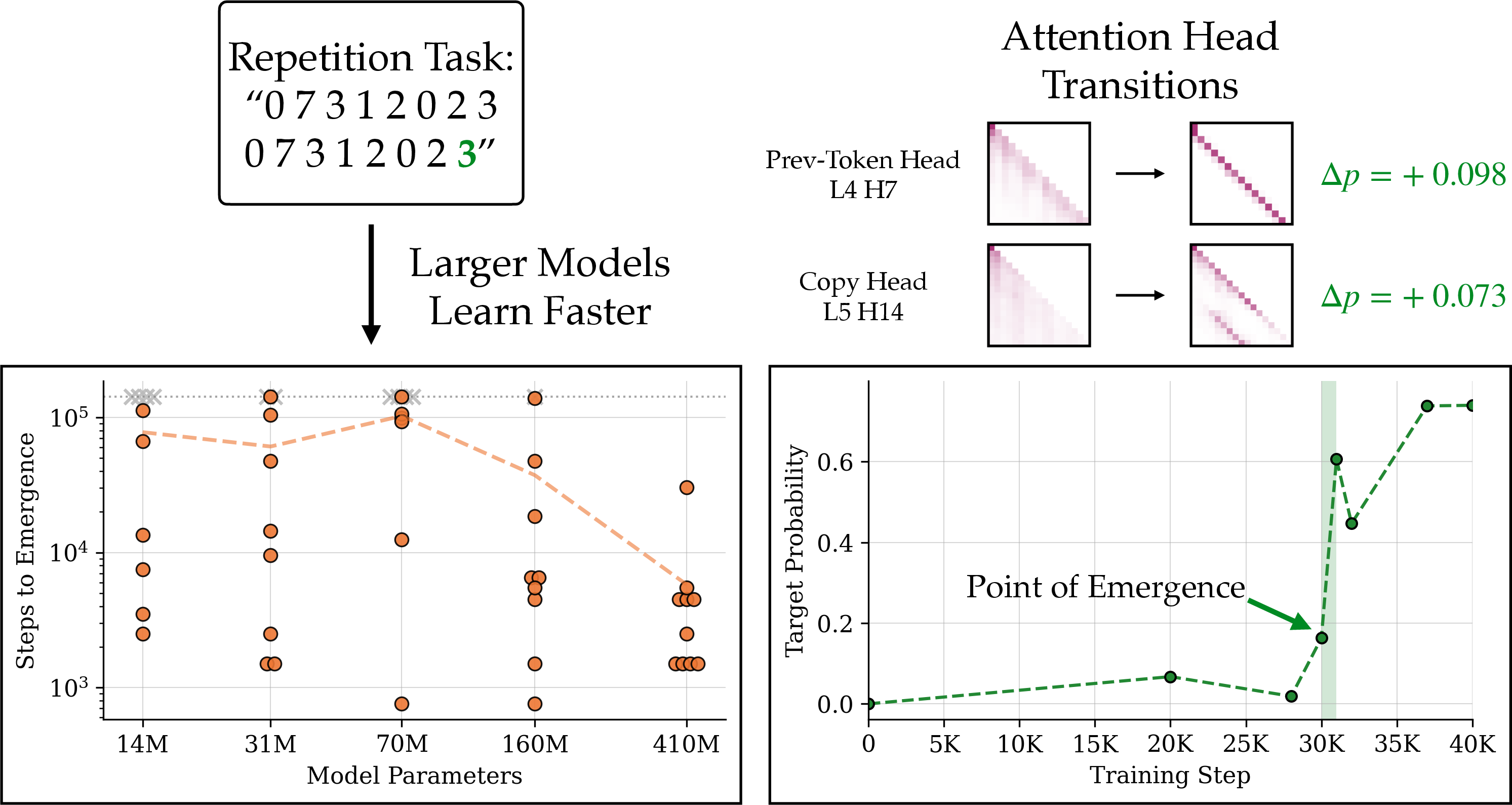
- Sudden “aha!” moments are real and random:
- Even during one training run, a skill can appear out of nowhere.
- Different models (started with different random seeds) can learn the same skill at different times—or not at all.
- Bigger models tend to get the skill earlier and more reliably.
- The switch happens when the model learns the right attention pattern:
- The model’s confidence in the correct answer jumps at the same time as certain attention heads start pointing to the right places.
- Pasting those learned attention maps into an earlier model checkpoint recovers most of the performance — meaning learning the attention pattern is the main bottleneck.
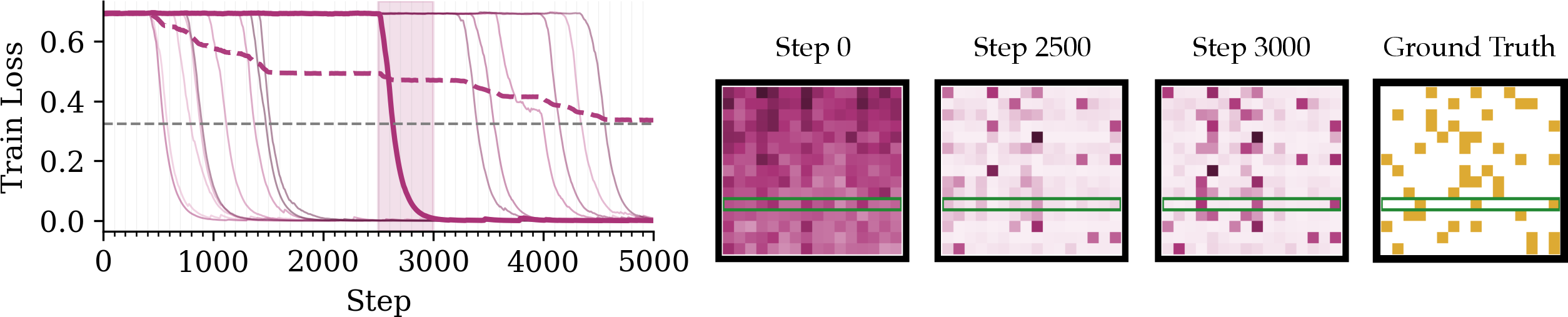
- What makes attention patterns hard to learn:
- Longer context (longer sequences to search through) makes learning much harder.
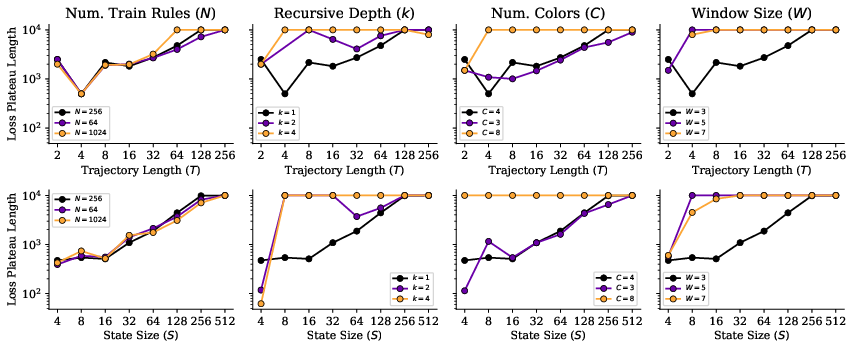
- “Sparsity” matters: when you need to look at just a few specific positions among many, it’s especially tough — the medium-sparse cases can be the hardest.
- In the toy tasks, if they “nudged” the model toward the correct pattern (by slightly biasing the spotlights), the long training plateaus disappeared. That shows the bottleneck is finding the right places to look.
- Architecture choices change how fast patterns are learned:
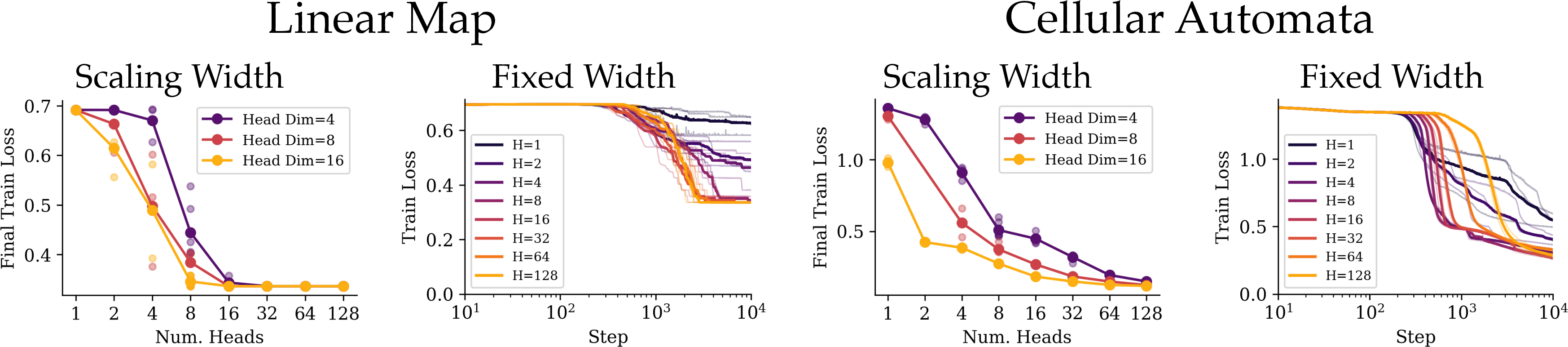
- More attention heads usually helps. Think of more heads as more teams searching for the right pattern — higher chances that one finds it.
- Each head needs some minimum capacity (head dimension). Too tiny, and even many heads won’t do well on some tasks.
- MLP-Mixer (no attention) worked much better than transformers on the linear map task (very sparse positional patterns), but worse on the cellular automata task. This suggests no single design is best for every kind of pattern.
Why this matters (implications and future impact)
- Training efficiency: If we can help models learn attention patterns faster (by architectural tweaks, training tricks, or pre-training on pattern-finding tasks), we can unlock new abilities sooner and with fewer resources.
- Model design: More attention heads and better token-mixing mechanisms can reduce the time models spend “searching” for patterns, especially in long texts.
- Task design: Understanding that context length and sparsity drive difficulty helps researchers build better benchmarks and curricula that teach models to look in the right places.
- Bigger picture: This work gives a clear, mechanical story for “emergence” — many new skills appear when the model finally learns where to look. That can guide future AI that’s more capable, predictable, and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Scaling and generalization:
- Whether the identified “attention-pattern bottleneck” holds for models >1B parameters and for more sophisticated capabilities (e.g., multi-step reasoning, tool-use, code synthesis) remains untested.
- Generality of results beyond Pythia checkpoints and the specific pretraining regime is unknown; replication on other families (e.g., Llama, GPT-NeoX) and data mixtures is needed.
- The extent to which observed abruptness and stochasticity persist under denser checkpointing (e.g., every few hundred steps or continuous logging) is not quantified.
- Measurement of emergence:
- Emergence is defined on single-sample, greedy-argmax outcomes; robustness to alternative metrics (e.g., accuracy over distributions, calibrated probabilities, AUC of $p(y^\*)$ over time) and multi-sample evaluations is only partially addressed in the appendix.
- The assumption that models do not revert after the “first emergence” checkpoint is not stress-tested under denser checkpoints or longer training.
- Sensitivity of the binary-search emergence-time estimate to checkpoint spacing, early-stopping noise, and seed variability is not analyzed.
- Causal mechanism attribution:
- Attention-only patching is used to infer causality; the roles of value projections, OV circuits, MLP blocks, and layer norms in phase transitions are not disentangled.
- The minimal set of heads required for eliciting emergence is not characterized; choice of K=16 is heuristic, and head redundancy/synergy is not quantified.
- Attention-sink dynamics are filtered heuristically; how sinks interact with (or mask) emergent patterns over training is not systematically studied.
- Synthetic task scope and realism:
- Synthetic tasks emphasize positional (content-independent) patterns; whether the same bottlenecks arise for content-dependent patterns (e.g., induction heads, entity tracking, algorithmic compositionality) is left open.
- Cellular automata experiments primarily use shallow recursion ( in main results); how recursion depth, rule-switch frequency, and latent-rule entropy interact with context length is underexplored.
- Generalization properties (e.g., out-of-distribution contexts, unseen linear maps/rules, longer trajectories than trained on) are not systematically reported.
- Context length and sparsity findings:
- The “medium sparsity is hardest” result lacks a theoretical account; no predictive model links difficulty to (context length), (sparsity), and optimization noise.
- Confounds from fixed token-batch budgets (fewer sequences per batch as grows) are not isolated; it remains unclear how much of the plateau lengthening is due to context length vs. reduced batch diversity.
- Interaction with positional encoding choices (absolute vs. relative, RoPE, ALiBi) is not examined, despite the tasks’ strong positional structure.
- Architectural factors:
- Head-count vs. head-dimension trade-offs are documented empirically but lack mechanistic/theoretical explanations (e.g., why/when head count dominates, minimal head dimension needed as a function of task complexity).
- Depth harms linear-map learning (reported in appendix), but the causes (e.g., compositional interference, optimization barriers) are not probed.
- Positional-token mixing alternatives: MLP-Mixer outperforms transformers on linear maps but underperforms on cellular automata; which architectural inductive biases drive these differences is not clarified, and parameter/compute matching across models is not reported in detail.
- Negative results for Mamba, RWKV, and Gated DeltaNet may reflect suboptimal hyperparameters; extensive tuning and fair compute/parameter matching are not presented.
- Training dynamics and optimization:
- Effects of optimizer choice, learning-rate schedule, warmup, gradient clipping, and regularization on plateau length and phase transitions are not ablated.
- Data curriculum or ordering effects (e.g., easier-to-harder sparsity or shorter-to-longer contexts) and their ability to reduce plateaus are not tested.
- Stochasticity across seeds is reported, but the distributional shape (variance, CI, outliers) and its dependence on hyperparameters are not quantified.
- Attention interventions:
- Attention-bias interventions rely on known ground-truth patterns; applicability to natural language (where patterns are unknown or latent) and the risk of mis-specification are unaddressed.
- Stability, scalability, and side effects of attention-biasing during long training (e.g., catastrophic interference, degraded performance on non-target patterns) are not studied.
- How to learn or distill proxy attention patterns from teacher models or auxiliary tasks without hand-crafted biases is only proposed as future work.
- Interpretability and evaluation breadth:
- Interpretations focus on a handful of tasks; a broader capability suite (syntax, coreference, long-range dependencies, multi-hop QA) would test the generality of the “attention-learning bottleneck.”
- Layer- and head-wise dynamics across training (e.g., early vs. late layers, interlayer dependencies) are not mapped; mutual information or causal mediation analyses could clarify circuit formation.
- The extent to which learned patterns are globally used vs. sample-specific (causal localization across many prompts) remains unclear.
- Practical implications:
- No assessment of the compute/data trade-offs implied by increasing head count vs. head dimension for large-scale training.
- How findings translate to long-context real-world pretraining (e.g., 32k–1M tokens) and memory-efficient attention variants is not explored.
- Preliminary “pre-pretraining” results are referenced but not detailed; concrete protocols and measurable gains in emergence timing are not provided.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed with today’s models and tooling, focusing on training efficiency, reliability, and interpretability.
- Training diagnostics for early detection of capability phase changes (Industry: software/AI; Academia)
- What: Add monitors for per-task correct-token probabilities and per-head attention entropy to flag abrupt emergence during pretraining/fine-tuning.
- Tools/products/workflows:
- “HeadHunter” dashboards tracking per-head attention entropy, sparsity, and pattern shifts.
- Probe harnesses using single-sample and micro-benchmark tasks (e.g., copying, induction) to detect capability spikes.
- Assumptions/dependencies: Access to model internals (attention weights/logits), training checkpoints, and a probe suite; moderate overhead.
- Seed-portfolio training and early-stopping orchestration (Industry: software/AI; Academia)
- What: Launch multiple seeds at fixed scale, track early emergence indicators, and allocate compute to seeds that show earlier/better attention-pattern acquisition.
- Tools/products/workflows:
- “SeedFarm” scheduler that promotes seeds with earlier emergence; automatic culling of underperforming seeds.
- Assumptions/dependencies: Multi-seed budget; reliable emergence proxies; integration into MLOps pipelines.
- Attention-guided curriculum and context scheduling (Industry: software/AI; Finance; Healthcare; Education)
- What: Train with shorter contexts and/or simpler sparsity patterns early, then progressively increase context length and sparsity to reduce loss plateaus.
- Tools/products/workflows:
- Batch composers that manage state size and trajectory length curricula (e.g., gradually extending context windows for document models in finance/healthcare).
- Assumptions/dependencies: Curriculum-friendly data; task performance not harmed by scheduling; requires verifying transfer to final context window.
- Head-count–first architecture selection for attention-heavy tasks (Industry: software/AI; Academia)
- What: Given fixed width, favor more heads with smaller head dimension (respecting a task-dependent minimum) to increase the chance of discovering sparse attention patterns.
- Tools/products/workflows:
- Architecture config advisors that auto-suggest H (head count) and head dimension per task profile.
- Assumptions/dependencies: Effect strongest for attention-heavy tasks; ensure minimum head dim when rules/memory storage is needed (e.g., multi-rule cellular automata–like tasks).
- Attention pattern patching for interpretability and rapid debugging (Industry: software/AI; Academia)
- What: Use activation/attention patching to identify causal heads behind capability jumps and to validate whether attention learning is the bottleneck.
- Tools/products/workflows:
- “AttentionPatch” libraries that swap attention maps across checkpoints or seeds for causal analysis.
- Assumptions/dependencies: Access to checkpoints and inference hooks; patching for debugging rather than persistent deployment.
- Long-context training risk mitigation (Industry: software/AI; Healthcare; Finance; Policy)
- What: Recognize multiplicative difficulty from long contexts; use retrieval or chunking during training; reserve full-window training for late-stage curricula.
- Tools/products/workflows:
- Context-window schedulers; retrieval-augmented training scaffolds for EHRs, claims, or multi-document finance workflows.
- Assumptions/dependencies: Retrieval/chunking compatible with target downstream tasks; evaluation to ensure no degradation in long-context abilities.
- Reporting and governance practices for stochastic emergence (Policy; Industry: software/AI)
- What: Update model documentation and release policies to include seed variability, emergence timing, and monitoring procedures.
- Tools/products/workflows:
- Reproducibility templates requiring seed sweeps and variance reporting; gating rules based on continuous capability monitoring.
- Assumptions/dependencies: Organizational buy-in; integration with CI/CD and model cards.
- Synthetic pre-pretraining datasets for attention circuits (Academia; Industry: software/AI)
- What: Use linear-map and cellular-automata–style synthetic tasks to prime copying/induction and sparse attention before natural language training.
- Tools/products/workflows:
- “AttentionCurriculum” data generators producing sparse, long-context token-mixing tasks at controlled difficulty.
- Assumptions/dependencies: Transfer from synthetic to natural tasks; careful curriculum design to avoid negative transfer.
- Sector-specific training tips for document and code models (Industry: Finance; Healthcare; Software)
- What: Apply head-count optimization and context curricula to models handling long-form documents (e.g., legal contracts, EHRs) or code (copying/induction tasks).
- Tools/products/workflows:
- Fine-tuning playbooks that emphasize head scaling and staged context growth for cross-page referencing or code repetition and pattern completion.
- Assumptions/dependencies: Access to training; compatibility with privacy constraints (e.g., healthcare data).
Long-Term Applications
These opportunities require further research, scaling, or productization before widespread deployment.
- Training-time attention scaffolding and regularization (Industry: software/AI; Academia)
- What: Learnable or rule-based biases that nudge attention toward hypothesized ground-truth patterns (e.g., sparse or local-window templates) to eliminate plateaus.
- Tools/products/workflows:
- Loss terms on attention entropy/sparsity; logit-bias modules; curriculum that transitions from scaffolded to free attention.
- Assumptions/dependencies: Avoiding overconstraint on open-ended language tasks; robust identification of useful scaffolds without ground truth.
- Automated attention-pattern discovery and distillation (Industry: software/AI; Academia)
- What: Identify useful attention patterns in larger/teacher models and distill them into smaller/student models to accelerate capability emergence.
- Tools/products/workflows:
- “AttentionDistill” pipelines transferring attention maps/heads across models; mixed objective on logits and attention scores.
- Assumptions/dependencies: Stability of attention patterns across scales and domains; acceptable IP/privacy policies for using teacher internals.
- Architectures with more sample-efficient token mixing (Industry: software/AI; Academia; Robotics)
- What: Develop hybrid architectures that inherit MLP-Mixer’s sample efficiency on positional patterns and transformers’ context-dependent mixing (e.g., plug-in mixers, gated mixers).
- Tools/products/workflows:
- NAS/AutoML search spaces that vary token-mixing blocks; adapters switching between attention and mixer depending on pattern difficulty.
- Assumptions/dependencies: Generalization beyond synthetic tasks; efficient inference on standard hardware; compatibility with long-context memory.
- Predictive analytics for emergent capability risk (Policy; Industry: software/AI)
- What: Quantitative models predicting when/if abrupt capabilities will arise in training, to inform governance, safety reviews, and staged releases.
- Tools/products/workflows:
- “Emergence Predictors” trained on internal telemetry (entropy trends, probe performance, head changes) to forecast phase changes.
- Assumptions/dependencies: Large historical telemetry datasets; correlations validated at larger scales (>1B parameters).
- Long-context pretraining strategies for domain models (Healthcare; Finance; Legal; Education)
- What: Multi-stage training that learns long-range sparse patterns for cross-document linking, longitudinal EHR reasoning, and legal clause coupling.
- Tools/products/workflows:
- Pretraining curricula combining retrieval, sliding windows, and attention scaffolds; domain-specific synthetic pre-pretraining (e.g., reference/citation tasks).
- Assumptions/dependencies: Transfer from synthetic and scaffolded stages to domain corpora; guardrails for hallucinations when scaffolds removed.
- Inference-time capability adapters via attention reconfiguration (Industry: software/AI)
- What: Lightweight “attention adapters” or head routing that activate learned sparse patterns for tasks like copying, pattern completion, or indirect object identification.
- Tools/products/workflows:
- Runtime control knobs that increase weight on specific heads or substitute learned attention templates for particular prompts.
- Assumptions/dependencies: Stability under distribution shift; latency overhead; safety and robustness considerations.
- Standardized benchmarks and reporting for emergent variability (Policy; Academia; Industry consortia)
- What: Community standards to evaluate and report seed-to-seed variability, emergence timelines, and attention-pattern evidence during model release.
- Tools/products/workflows:
- Benchmark suites combining synthetic and natural probes; protocols for seed sweeps and publication of emergence histograms.
- Assumptions/dependencies: Broad stakeholder agreement; confidentiality constraints for commercial labs.
- Robotics and sequential decision-making curricula (Robotics; Industry: automation)
- What: Use sparse attention curricula to help policies learn long-horizon dependencies (e.g., copying subroutines, repeating behaviors, pattern completion in plans).
- Tools/products/workflows:
- Offline RL pre-pretraining with synthetic sparse-dependency sequences; attention head tuning to prioritize long-range cues.
- Assumptions/dependencies: Transfer from token-mixing insights to sensorimotor representations; integration with policy optimization.
- Education and workforce upskilling in interpretability (Education; Academia; Industry)
- What: Courseware and labs that teach causal attention analysis, emergence monitoring, and architecture choices using open-source synthetic tasks.
- Tools/products/workflows:
- Modular curricula featuring linear maps and cellular automata; hands-on “patching” assignments and entropy-tracking instrumentation.
- Assumptions/dependencies: Availability of open checkpoints; sustained maintenance of teaching materials.
Cross-cutting assumptions and limitations
- Evidence base: Many findings were demonstrated on sub-1B parameter Pythia models and synthetic tasks; generalization to larger models and richer capabilities remains to be validated.
- Access requirements: Most immediate uses require access to model internals (attention logits/maps, checkpoints) not always available for closed models.
- Task dependence: Gains from more heads vs. head dimension depend on whether tasks are purely attention-heavy or also require per-head capacity for rule/memory storage.
- Ground-truth patterns: Attention scaffolding is straightforward when the pattern is known (synthetic, algorithmic) but harder for open-ended natural language; care is needed to avoid biasing against useful patterns.
- Compute trade-offs: Multi-seed orchestration and additional telemetry/patching introduce overhead and orchestration complexity; expected to be offset by reduced training time on plateaus.
Glossary
- activation patching: An interpretability technique that replaces activations (or attention scores) from one model/run with those from another to test causal effects. "This approach is effectively activation patching~\citep{heimersheim2024useinterpretactivationpatching} on the dot-product attention scores."
- attention head: A component of multi-head attention that computes its own attention distribution and value mixing. "For each attention head at every layer, we observe the head's attention map computed on the prefix in the post-emergence model."
- attention logits: The pre-softmax scores whose values determine attention weights after normalization. "we add to the attention logits for queries and keys before computing softmax scores."
- attention map: The matrix of attention weights (or its ground-truth pattern) showing how tokens attend to one another. "learning this ground-truth attention map is a major bottleneck that leads to abrupt learning"
- attention pattern: A structured configuration of attention focusing on specific tokens/positions needed to solve a task. "learning long-context, sparse attention patterns is a key bottleneck"
- attention sink: A degenerate behavior where attention collapses to a fixed token (often the first) regardless of query. "We instead define an attention sink in the context of our ablation as a head where the attention weight to key position zero increases for each query token between the pre-emergence and post-emergence checkpoints."
- autoregressive LLM: A model that predicts the next token based on previous tokens in sequence. "We then train an autoregressive LLM with vocabulary size "
- bimodal distribution: A distribution with two distinct modes, here describing model outcomes (success/failure). "model performance on many downstream tasks follows a bimodal distribution"
- binary search: A logarithmic search method used here to find the first training step where a capability emerges. "we apply binary search (rather than evaluating all 154 checkpoints) to find the first checkpoint"
- causal ablation: An intervention-based analysis to identify which components causally affect an outcome. "Our causal ablations additionally show that attention pattern learning is a bottleneck for LLM capabilities"
- cellular automata: Discrete dynamical systems evolving on a grid via local update rules. "linear map and cellular automata datasets"
- checkpoint: A saved snapshot of model parameters at a specific training step. "the final training checkpoint at step $143000$."
- context length: The number of tokens available as input context for prediction. "factors such as context length and sparsity"
- dot-product attention: The standard attention mechanism computing scores via query–key dot products. "uses an MLP for its token-mixing mechanism rather than dot-product attention"
- emergent capabilities: Abilities that appear abruptly as models scale or train, not present in smaller/earlier models. "emergent capabilities arise stochastically throughout training"
- emergence: The abrupt acquisition of a capability during training or at a certain scale. "emergence coincides with learning interpretable attention patterns"
- entropy (of attention): A measure of dispersion of attention weights; lower entropy indicates more focused attention. "We also track the entropy for each head across queries and keys "
- greedy sampling: Decoding by always choosing the highest-probability next token. "i.e., the model output under greedy sampling"
- head dimension: The dimensionality of each attention head’s key/query/value projections. "increasing the head dimension yields diminishing returns past a minimum capacity"
- in-context learning: The ability to learn patterns from the input prompt without updating weights. "downstream capabilities such as in-context learning are known to emerge abruptly past a certain model scale"
- induction heads: Attention circuits that copy continuations by matching previously seen token sequences. "learn sparse attention patterns such as copying or induction heads"
- initialization seed: The random seed controlling parameter initialization that can affect training outcomes. "depends on the initialization seed"
- linear map: A task where the next state is a linear transformation (mod 2) of the previous state. "synthetic linear map and cellular automata datasets"
- lookup table: A rule table mapping local neighborhood states to next states in cellular automata. "A lookup table determines how to compute a single bit of "
- loss plateau: A training phase with little to no loss improvement before a sudden drop. "We measure the loss plateau length as the step at which the model first achieves loss ."
- MLP-Mixer: An architecture that mixes token and channel information using MLPs instead of attention. "MLP-Mixer outperforms a transformer on linear map tasks with complex attention patterns."
- neural scaling laws: Empirical laws describing how performance/loss scales smoothly with model/data size. "Neural scaling laws for transformer LLMs predict smooth improvements in pretraining loss with increasing parameters"
- parity: The XOR-sum (mod 2) of bits; used as the update in linear map transitions. "compute the parity of a sparse subset of the previous state for each cell."
- phase transition: A sudden qualitative change in behavior or capability during training. "produce a sharp phase transition in in-context learning ability."
- pretraining loss: The training objective value during large-scale pretraining, typically language modeling loss. "predict smooth improvements in pretraining loss"
- Pythia suite of LLMs: A family of open checkpoints used for controlled analysis across scales/seeds. "All experiments in this section are conducted with the Pythia suite of LLMs"
- quantization model (of neural scaling): A theory positing models acquire discrete skills whose aggregate yields smooth scaling. "The quantization model of neural scaling~\citep{michaud2024quantizationmodelneuralscaling} reconciles these two observations"
- softmax: The normalization function turning logits into probabilities for attention or outputs. "computed by softmax over key-value dot products"
- sparsity (attention pattern sparsity): The fraction of positions attended to; sparse patterns focus on few inputs. "varying the context length or attention pattern sparsity dictates whether a model solves a task completely or makes no progress at all."
- state size: The number of cells/tokens per state in synthetic tasks. "We vary the state size to control context length"
- token-mixing mechanism: The architectural method for combining information across token positions. "uses an MLP for its token-mixing mechanism rather than dot-product attention"
- trajectory length: The number of steps in the generated sequence of states. "We define a state size , a trajectory length , and a number of colors ."
- transformer: A neural architecture using attention mechanisms for sequence modeling. "Neural scaling laws for transformer LLMs"
- vocabulary: The set of possible tokens; its size or elements define prediction space. "given a model with token vocabulary "
Collections
Sign up for free to add this paper to one or more collections.