FiCA: Feed-forward instant Gaussian Codec Avatars from a Single Portrait Image
Abstract: We introduce FiCA, a Feed-forward, instant Gaussian Codec Avatar generation pipeline that creates lifelike avatars from a single portrait image. Generating a photorealistic and drivable avatar from just a single image is significantly challenging due to the limited visual information available to accurately infer the 3D appearance and geometry of human heads. To address this, we develop a novel system that combines human-centric vision foundation models with a diffusion model. This system is designed to fully exploit partial visual observations to generate lifelike human avatars. Our proposed diffusion model learns a generative mapping from these partial observations to complete and authentic 3D mesh reconstruction. Additionally, we introduce a feed-forward mesh refinement network that enhances the fidelity and identity preservation of the generated avatars, eliminating the need for person-specific test-time optimization. By leveraging a universal prior model that decodes a generated mesh into a set of 3D Gaussians, we generate a photorealistic 3D Gaussian avatar, capable of being driven with novel expressions in real-time. Our experiments demonstrate that the avatars generated by our feed-forward approach faithfully represent diverse identities and surpass the visual quality of avatars produced by recent competing methods.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces FiCA, a fast system that turns a single portrait photo of a person into a lifelike 3D head “avatar” that can smile, frown, and move in real time. It does this in about 5 seconds, without special cameras, long recordings, or slow, per-person tuning.
What problem is the paper trying to solve?
Making a realistic 3D avatar usually needs lots of photos or videos from different angles and hours of processing. The authors ask: Can we build a high-quality, realistic, and animatable 3D head avatar using just one photo—and make it work instantly?
How does FiCA work? (Simple steps and analogies)
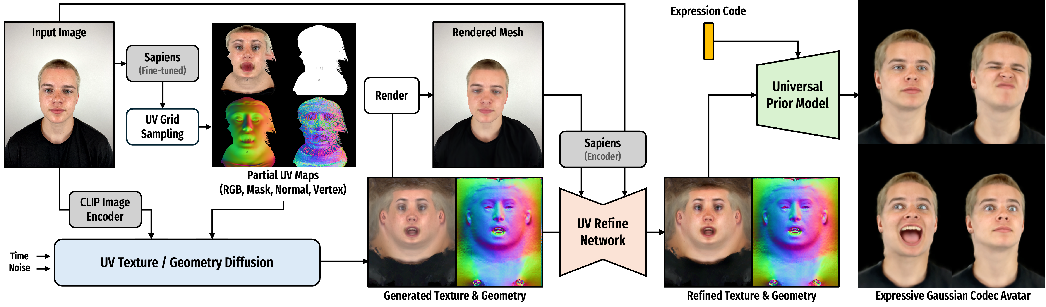
Think of building a 3D head from a single picture like completing a puzzle when many pieces are missing. FiCA uses three smart tools to fill the gaps quickly and accurately:
- Step 1: Read as much as possible from the photo
- A pretrained “vision foundation model” called Sapiens acts like super-strong “computer eyes.” It estimates:
- Where each pixel on the photo would lie on a flat “skin map” of the head (a UV map—like peeling an orange and laying the peel flat).
- The tiny directions each surface points (normals).
- Rough positions of points on the face (3D vertex hints).
- Another model, CLIP, gives a high-level summary of what’s in the photo (who it looks like, style, etc.).
- Result: partial “flat” maps of the head’s color/texture and shape. These are incomplete because one photo can’t see the whole head.
- Step 2: Imagine the missing parts using a diffusion model
- A diffusion model is like a very smart guesser trained on many faces; it “fills in” the parts you can’t see (the back of the head, inside the mouth, etc.) to produce a complete texture map and a complete shape map. It uses the partial maps and CLIP features as clues so it stays true to the person in the photo.
- Step 3: Fine-tune the details automatically
- A refinement network compares a quick render of the generated 3D head to the original photo and makes small adjustments so the avatar’s skin tone, facial features, and details match better—without slow, per-person optimization.
- Step 4: Turn the mesh into a fast, realistic avatar
- Finally, a “Universal Prior Model” (a general decoder learned from lots of people) converts the refined head mesh into a set of tiny, fuzzy 3D blobs called “3D Gaussians.” You can think of these as soft paint dots that, together, create a highly detailed 3D head that is both photorealistic and very fast to render. This makes the avatar easy to animate in real time with different expressions.
What did the researchers find?
- It works from one photo in about 5 seconds: No special capture rigs, no long tracking steps, and no per-person fine-tuning are needed.
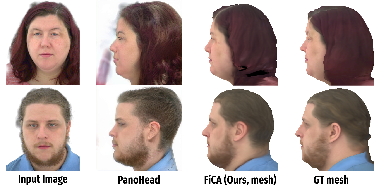
- Realistic and consistent results: The avatars look like the person, keep details (like tattoos or accessories), and remain consistent from different viewpoints (front, side, back).
- Animates well: The avatars can be driven by expression signals (like “smile,” “raise eyebrows”) in real time, handling even big expressions and different skin tones better than recent methods.
- Better than previous systems: In tests against other single-image avatar tools, FiCA’s avatars looked more realistic and preserved identity better. It also avoids the “jitter” and artifacts some other methods show.
- Works for many people: The system was trained and tested on large, diverse datasets (multi-camera studio captures and regular phone videos), and generalizes to new faces.
Why is this important?
- Easier and faster avatar creation: Anyone with a single portrait can get a high-quality, controllable 3D avatar quickly. This helps virtual meetings, games, education, and social apps.
- Real-time performance: Because the final avatar uses 3D Gaussians, it renders and animates smoothly, which is great for live experiences like VR/AR.
- No expert setup needed: It removes the need for hours of tracking or special equipment, making realistic avatars more accessible to everyone.
Limitations and future directions
- Tough cases: Photos with extreme lighting or heavy motion blur can still cause problems. Future work could teach the system to correct lighting and blur.
- Accessories: Handling layered items like glasses more explicitly is a next step.
- Creative editing: Because it’s feed-forward, you can edit the portrait in 2D (e.g., stylize it) and instantly get a stylized, animatable 3D avatar—opening fun possibilities for creators.
In short, FiCA shows that a fast, feed-forward pipeline can build realistic, expressive, and drivable 3D head avatars from just one picture—bringing high-quality virtual avatars much closer to everyday use.
Knowledge Gaps
Below is a single, consolidated list of gaps, limitations, and open questions that remain unresolved in the paper. Each point is phrased to be concrete and actionable for future research.
- Robustness to capture conditions: No systematic evaluation or mitigation for extreme lighting, strong shadows, color casts, lens distortion, or motion blur; develop lighting-disentangling priors, photometric calibration, and deblurring modules integrated with the diffusion stage.
- Out-of-distribution generalization: Unclear performance on highly non-frontal poses, partial occlusions, unusual camera intrinsics, multi-person scenes, or in-the-wild social media images; establish OOD test sets and stress tests.
- Accessory handling: Lacks layered modeling for occluding accessories (glasses, hats, masks, earrings, facial piercings); design a joint layered geometry/texture generation and occlusion-aware UPM decoding.
- Hair modeling/completion: No explicit treatment of complex hairstyles (long hair, curls, wisps) and back-of-head completion from a single view; develop hair-specific priors (strand- or sheet-based) and evaluate multi-view consistency for hair regions.
- Relighting capability: The generated avatars are not demonstrated to be relightable; investigate coupling with relightable UPMs (e.g., URAvatar) or introduce albedo/illumination disentanglement during diffusion.
- Mouth interior and eyes: The pipeline “imagines” teeth, tongue, and irises without personalization; add intra-oral and ocular priors, personalized tooth/iris modeling, and uncertainty-aware rendering for occluded regions.
- Uncertainty estimation: No mechanism to quantify or propagate uncertainty from Sapiens predictions and diffusion completions; add confidence maps and calibration to guide refinement and downstream decoding.
- Expression/pose control coverage: The expression basis and gaze/eyelid/tongue coverage are not quantified; measure controllability limits, retargeting fidelity, and extreme-expression robustness across identities.
- Driver dependence: The system still requires driving codes (e.g., FLAME expressions) at runtime; integrate robust, real-time expression/gaze estimators and evaluate end-to-end tracking-free animation (e.g., audio-driven, text-driven).
- Temporal stability: Although results are “real-time drivable,” temporal coherence metrics and analysis of flicker/jitter over long sequences are missing; benchmark temporal stability across expressions and head motion.
- Geometry accuracy: No 3D reconstruction metrics (e.g., landmark, depth, normal, or mesh error versus ground truth); introduce geometry-specific evaluation beyond image-space PSNR/SSIM/LPIPS.
- Multi-view consistency: Claims of multi-view consistency are not backed by quantitative metrics; evaluate reprojection error and cross-view consistency on held-out multi-view captures.
- Skin tone and color fidelity: Improvements are qualitative; quantify color constancy, skin tone preservation, and bias across Fitzpatrick skin types under varied illumination.
- Demographic fairness: No fairness analysis across age, gender presentation, ethnicity, facial hair, or cultural attire; establish balanced test sets and report performance gaps.
- Failure mode analysis: Limited discussion beyond lighting/blur; curate and report systematic failure cases (e.g., occlusions, heavy makeup, face paint, extreme hairstyles) with error breakdowns.
- Comparisons and benchmarks: Some baselines are not designed for expression-driven avatars; adopt or propose standardized single-image-to-drivable-avatar benchmarks and protocols to ensure apples-to-apples comparisons.
- Reproducibility: Heavy reliance on proprietary assets (UPM, Sapiens fine-tuning, dome/iPhone datasets) impedes replication; release models/datasets or provide drop-in open alternatives and detailed training recipes.
- Data provenance and consent: Dataset consent, licensing, and privacy protections are not discussed; document data governance and user consent protocols for avatar generation.
- Ethical safeguards: The ability to generate drivable avatars from a single image poses deepfake risks; propose watermarking, provenance tracking, or misuse detection mechanisms and conduct a risk assessment.
- Segmentation/matting dependency: Refinement relies on matting/segmentation quality; quantify sensitivity to mask errors and develop mask-robust refinement losses or joint segmentation-refinement training.
- Sapiens feature dependency: The refinement network depends on Sapiens ViT features; assess domain shift sensitivity and ablate alternative feature backbones or self-supervised image features.
- Diffusion design details: The domain switcher and joint texture–geometry diffusion lack ablations versus separate models; analyze trade-offs in convergence, fidelity, and compute for joint vs. decoupled training.
- Runtime and resource profile: “5 seconds” generation and “real-time” driving lack detailed hardware specs, memory footprint, Gaussian count, and FPS under varying quality settings; provide deployment profiles (desktop/mobile/edge).
- 3D Gaussian budget vs. quality: No study of the trade-off between number of Gaussians and visual/temporal quality; characterize compression, streaming, and scalable rendering strategies.
- Neck/shoulder boundary and clothing: Artifacts at the chin–neck–collar region and limited clothing modeling are not addressed; extend geometry/texture priors beyond the cranium to upper torso and garments.
- Back-of-head fidelity: Single-view completion may be implausible for unseen regions; evaluate against multi-view ground truth and consider symmetry/hairstyle-conditioned constraints to reduce hallucinations.
- CLIP conditioning effects: CLIP can inject non-face semantics (e.g., apparel) into texture; study attribute leakage, unintended edits, and introduce conditioning controls/regularizers to limit off-face influence.
- Stylization pipeline evaluation: The 2D-edit-then-3D approach is demonstrated qualitatively; quantify edit faithfulness, identity retention, and geometry preservation post-stylization.
- Security robustness: No adversarial robustness or input sanitation analysis; test against adversarial or corrupted inputs and add detection/defense mechanisms.
- Scale and metric consistency: Single-image ambiguities may cause mismatched metric scale or IPD; introduce scale priors or canonicalization to ensure consistent decoding/driving across identities.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed today, leveraging FiCA’s feed‑forward pipeline, single-image input, and real‑time, drivable 3D Gaussian avatars. Each item lists sectors, potential tools/products/workflows, and key assumptions/dependencies.
- Real‑time telepresence avatars for video conferencing and XR
- Sectors: software, AR/VR, enterprise collaboration
- Tools/products/workflows: Zoom/Teams/Horizon plug‑ins; a desktop SDK that takes a webcam headshot, generates a drivable avatar in ~5s, and drives it via facial expression tracking; WebRTC integration for low‑latency streaming
- Assumptions/dependencies: on-device or edge GPU for 5s generation and real‑time rendering; expression drivers (e.g., EMOCA/SMIRK); user consent and privacy controls
- VTubing and live streaming with quick identity setup
- Sectors: entertainment/media, creator economy
- Tools/products/workflows: OBS/Streamlabs plug‑in; selfie→avatar→webcam‑driven expressions; rapid brand/style variations via 2D edits followed by FiCA generation
- Assumptions/dependencies: GPU for real‑time; platform policies on synthetic media; guardrails against impersonation
- Customer support and sales chat widgets with humanlike agents
- Sectors: customer support, sales enablement, marketing
- Tools/products/workflows: web widget that spawns an agent from a single approved headshot; TTS + audio‑to‑expression driving; CRM integration
- Assumptions/dependencies: audio‑driven expression model (e.g., Audio2Photoreal); content moderation; data governance and consent for likeness use
- Rapid player avatars in games
- Sectors: gaming
- Tools/products/workflows: in‑game selfie→drivable NPC/player avatar; Unity/Unreal integration via a Gaussian rendering plugin or conversion to engine‑friendly runtime; minimal user friction
- Assumptions/dependencies: real‑time Gaussian rendering in engine (or a mesh/Gaussian hybrid); console/mobile GPU performance constraints
- Virtual production/previz digital doubles
- Sectors: film/TV, advertising
- Tools/products/workflows: on‑set headshot→instant drivable stand‑in for blocking, camera tests, and animatics; batch generation for extras
- Assumptions/dependencies: quality sufficient for previz (not final pixel); rights/clearance for likeness; pipeline hooks for driving expressions
- E‑learning instructors and corporate training avatars
- Sectors: education, enterprise L&D
- Tools/products/workflows: recorded lessons where an instructor’s avatar is driven by prerecorded audio and gaze scripts; self‑service portal for instructors
- Assumptions/dependencies: audio‑to‑expression models; accessibility requirements; GPU for batch rendering
- Privacy‑preserving telehealth and teletherapy
- Sectors: healthcare
- Tools/products/workflows: patient/clinician face anonymization with identity‑preserving expressions during video calls; selectable levels of stylization
- Assumptions/dependencies: clinical acceptance and compliance (HIPAA/GDPR); miscommunication risk management (faithful expression transfer); robust tracking in varied lighting
- Identity‑preserving de‑identification for journalism/whistleblowers
- Sectors: media, civil society
- Tools/products/workflows: face replacement with expressive avatars while preserving timing and affect; editorial workflows for disclosure badges
- Assumptions/dependencies: newsroom policies; legal review; high‑fidelity expression driving
- Localization and dubbing: expressive head replacements
- Sectors: media localization, advertising
- Tools/products/workflows: create a drivable head avatar from a still and drive with localized audio; lip‑sync + expression curves auto‑generated from speech
- Assumptions/dependencies: robust speech‑to‑expression pipeline; rights for likeness; quality control for uncanny valley
- Rapid academic baselines for single‑image 3D head reconstruction
- Sectors: academia (vision/graphics)
- Tools/products/workflows: use FiCA modules to benchmark conditioning (UV/normal/vertex) and diffusion designs; ablation studies on identity fidelity and generalization
- Assumptions/dependencies: access to foundation models (Sapiens, CLIP) and a UPM; compute for training/evaluation
- Feed‑forward avatar stylization (2D edit → drivable 3D)
- Sectors: creative tools, branding, social
- Tools/products/workflows: integrate InstructPix2Pix/MagicBrush for single‑image edits (makeup, color grading, toonification), then FiCA to produce a rig-ready stylized avatar
- Assumptions/dependencies: consistent edits in the portrait image; careful use to avoid style–identity drift
- Internal enterprise comms: standardized employee avatars
- Sectors: enterprise software, HR/comms
- Tools/products/workflows: batch service that turns directory photos into drivable avatars for all‑hands, town halls, and training
- Assumptions/dependencies: employee consent; governance over storage and use; SSO and access controls
Long‑Term Applications
These opportunities likely require additional research, robustness, scalability, policy frameworks, or ecosystem development before broad deployment.
- Accessory‑aware avatars and virtual try‑on (glasses, hats, earrings)
- Sectors: retail/e‑commerce, AR
- Tools/products/workflows: layered generation for accessories; pose‑aware try‑on with collision/occlusion handling
- Assumptions/dependencies: FiCA extension to layered texture/geometry; product CAD/parametric models; fit/sizing personalization
- Relightable avatars with lighting normalization and control
- Sectors: VFX/virtual production, AR
- Tools/products/workflows: joint estimation of intrinsic albedo/geometry + environment lighting; UI sliders for scene relighting
- Assumptions/dependencies: learned light disentanglement; HDRI estimation; domain‑robust texture generation
- Full‑body extension (head‑hands‑body) from minimal inputs
- Sectors: gaming, telepresence, robotics
- Tools/products/workflows: single or few images → full drivable digital human; unified Gaussian avatar with body kinematics
- Assumptions/dependencies: new datasets and priors for hands/body; kinematic/cloth/hair dynamics; performance budgets
- On‑device/mobile avatar generation and rendering
- Sectors: consumer apps, edge computing
- Tools/products/workflows: <5s generation and stable 60 fps rendering on mobile SoCs; WebGPU/WebNN runtimes
- Assumptions/dependencies: model compression, distillation, sparsity; efficient Gaussian renderers; thermal/power constraints
- Standards and interoperability for Gaussian avatars
- Sectors: standards bodies, web/graphics ecosystems
- Tools/products/workflows: glTF‑like extensions for 3D Gaussians; Web standards for streaming/driving signals (expressions, gaze)
- Assumptions/dependencies: industry consensus; reference decoders; backward‑compatible fallbacks
- Content authenticity, watermarking, and provenance for avatars
- Sectors: policy/regulation, platforms, cybersecurity
- Tools/products/workflows: C2PA‑style provenance for avatar generation events; watermarking of Gaussian assets; detection APIs
- Assumptions/dependencies: regulatory guidance; platform adoption; robust, hard‑to‑remove watermarks
- Clinical applications: facial palsy rehab and biofeedback
- Sectors: healthcare
- Tools/products/workflows: patient‑specific avatar mirroring target expressions; therapist dashboards tracking adherence and progress
- Assumptions/dependencies: clinical trials; medically validated expression metrics; safety and efficacy
- Accessible communication for users with speech or camera constraints
- Sectors: accessibility, assistive tech
- Tools/products/workflows: text‑/EMG‑/eye‑tracking‑to‑expression driving of avatars; privacy‑preserving on‑device generation
- Assumptions/dependencies: robust multimodal drivers; low‑latency pipelines; user studies and standards compliance
- Museum and heritage reconstructions from archival photos
- Sectors: culture, education, tourism
- Tools/products/workflows: create respectful, educational avatars of historical figures; narrative experiences in AR/VR exhibits
- Assumptions/dependencies: ethical review, rights clearances; bias mitigation; restoration of degraded inputs
- Synthetic data generation for detection/anti‑spoofing research
- Sectors: security, platform integrity, academia
- Tools/products/workflows: controlled avatar datasets for training evaluators of deepfakes and spoofing; systematic perturbation of lighting/pose
- Assumptions/dependencies: labeling standards; domain gap analysis; responsible disclosure norms
- Personalized cosmetics and hair simulation on avatars
- Sectors: beauty retail, AR marketing
- Tools/products/workflows: SKU‑conditioned shader/material mapping; interactive try‑on with head motion and expressions
- Assumptions/dependencies: accurate BRDF/material models; calibration from product catalogs; robust color constancy
- Human–robot interaction with expressive digital faces
- Sectors: robotics, service robots
- Tools/products/workflows: high‑fidelity facial displays for robots driven by dialog state; rapid identity swap for brand alignment
- Assumptions/dependencies: latency budgets; safety and social acceptability; cross‑modal emotion consistency
- Enterprise avatar marketplaces and UGC ecosystems
- Sectors: platforms, creator economy
- Tools/products/workflows: marketplaces for avatar styles, accessories, and expression packs; moderation and IP management
- Assumptions/dependencies: policy frameworks; revenue sharing; content moderation at scale
Cross‑cutting assumptions and dependencies (affecting many applications)
- Input quality: extreme lighting or motion blur reduces fidelity; improvements via light normalization/denoising are beneficial.
- Driving signals: require reliable expression/gaze/pose drivers (webcam trackers, HMCs, or audio‑to‑expression models).
- Compute: the reported ~5s generation implies a capable GPU; mobile/edge use requires optimization.
- Data rights and governance: explicit consent for likeness use; storage and revocation policies; demographic fairness audits of training data.
- Interoperability: 3D Gaussian rendering support in target runtimes (native, engine plugins, or standardization efforts).
- Safety: anti‑impersonation safeguards, watermarking, disclosure UX, and compliance with emerging synthetic media regulations.
Glossary
- 3D Gaussians: Point-based volumetric primitives that model geometry and appearance with Gaussian kernels for efficient rendering and deformation. "represented in a set of 3D Gaussians"
- 3DGS (3D Gaussian Splatting): A rendering technique that represents scenes or avatars as collections of 3D Gaussians and renders them via splatting. "the 3DGS decoding"
- ArcFace: A face recognition model that produces identity embeddings used to assess identity similarity. "ArcFace~\cite{deng2019arcface} embedding"
- CLIP: A vision-language foundation model whose image embeddings provide semantic conditioning to generative models. "CLIP image embedding"
- Conditional flow matching: A training objective for continuous-time generative models that aligns flows conditioned on inputs to match target distributions. "using the conditional flow matching objective"
- DiT architecture: The Diffusion Transformer architecture used to implement transformer-based diffusion models. "in the DiT architecture"
- Differentiable rasterizer: A graphics renderer that is differentiable, enabling backpropagation through rendering for learning-based optimization. "a differentiable rasterizer"
- Domain switcher: A conditioning flag that selects which output domain (e.g., texture or geometry) a shared diffusion model should denoise at each step. "domain switcher"
- Drivable avatar: An avatar that can be controlled in real time by external signals such as head pose and expression parameters. "drivable Gaussian Codec Avatars"
- FLAME: A parametric 3D face model used for tracking and driving facial expressions. "FLAME~\cite{li2017flame} meshes."
- Foundation models (vision): Large pre-trained models that capture broad visual priors and can be adapted to diverse downstream tasks. "vision foundation models"
- GAN inversion: Optimization to find a latent code such that a pre-trained GAN reconstructs a given image or identity. "GAN inversion optimization"
- Gaussian Codec Avatar: An avatar representation where identity-conditioned priors decode meshes into high-fidelity sets of 3D Gaussians for real-time rendering. "Gaussian Codec Avatars"
- Hypernetwork: A network that generates the parameters (e.g., biases) for another network, enabling identity-conditioned decoding. "hypernetwork-based 3D Gaussian avatar generation model"
- ID-CSIM: Identity cosine similarity; a metric computed as the cosine similarity between identity embeddings to measure identity preservation. "ID-CSIM"
- Inpainting: Filling in missing or occluded image regions using generative models. "diffusion-based inpainting models"
- Laplacian matrix: A discrete differential operator on meshes used to regularize smoothness in geometry. "Laplacian matrix"
- Latent diffusion model: A diffusion model that operates in the latent space of an autoencoder for efficiency and quality. "We design a latent diffusion model"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric comparing deep feature distances between images. "LPIPS"
- Masked autoencoding: A self-supervised pretraining task where masked image patches are reconstructed to learn visual representations. "masked-autoencoding task"
- Matting model: A model that estimates accurate foreground masks (alpha mattes) to separate subjects from backgrounds. "an off-the-shelf matting model"
- Normal map: A texture encoding per-pixel surface normals in UV space to convey fine geometric detail. "normal maps"
- Optimal transport: A mathematical framework used here to derive ground-truth flow fields for conditional flow matching. "optimal transport formulation of conditional flow matching"
- Photometric loss: A pixel-wise reconstruction loss measuring color/intensity differences between rendered and reference images. "L1 photometric loss"
- PSNR: Peak Signal-to-Noise Ratio; a distortion metric measuring reconstruction fidelity relative to a reference image. "PSNR"
- Score-Distillation optimization: An optimization technique that uses diffusion model score gradients to guide 3D reconstruction or rendering. "Score-Distillation optimization"
- SDXL VAE: The variational autoencoder component from Stable Diffusion XL used to encode/decode images or UV maps to latent space. "SDXL VAE"
- Sapiens: A human-centric vision foundation model providing dense features and estimates (e.g., UVs, normals, vertices) from images. "Sapiens"
- SSIM: Structural Similarity Index; a perceptual metric assessing structural similarity between images. "SSIM"
- Tri-plane: A 3D representation that stores features on three orthogonal planes, enabling fast 3D synthesis with 2D convolutions. "tri-plane GAN"
- U-Net with cross-attention: A U-Net architecture augmented with cross-attention layers to condition generation on external features. "U-Net architecture with cross-attention layers"
- Universal Prior Model (UPM): A learned decoder that maps identity-conditioned meshes to detailed, drivable Gaussian avatars across identities. "Universal Prior Model (UPM)"
- UV coordinates: A 2D parameterization of a 3D surface used to map textures and attributes onto meshes. "per-pixel UV coordinates"
- UV map: A 2D image (texture or attribute) laid out in UV space corresponding to a mesh’s surface. "UV texture map"
- UV refinement network: A feed-forward network operating in UV space to refine texture and geometry for improved fidelity and alignment. "UV refinement network"
- View- and gaze-direction vectors: Directional inputs specifying camera and eye orientations for driving avatar rendering. "view- and gaze-direction vectors"
- Volumetric primitives: Basic volumetric elements (e.g., Gaussians) used to represent and render complex geometry and appearance. "volumetric primitives"
- Zero-shot animation: Driving avatars for unseen identities or expressions without per-subject training or fine-tuning. "zero-shot animation"
Collections
Sign up for free to add this paper to one or more collections.