Apple Neural Engine: Architecture, Programming, and Performance
Abstract: The Apple Neural Engine (ANE) is the fixed-function matrix accelerator that has shipped in Apple systems-on-chip since the A11-class iPhone and iPad chips and the M1-class Mac chips, exposed to applications only through the Core ML model framework. This guide reports a reverse-engineered account of the engine, based on direct measurement on Apple silicon and static analysis of the private runtime, compiler, kernel driver, and firmware. It documents the datapath and the roofline that bound the engine's throughput and energy, the dispatch route that reaches it below Core ML, the compiler and on-disk program format, the weight-compression scheme, and the kernel driver, firmware, and command protocol beneath them. The account covers the A11 through A18 and M1 through M5 families, with per-chip target tables and an operation-by-device matrix; the direct measurements are on the M1 and M5. Claims are labeled as measured, decompile-derived, or predicted, and the methodology and open questions are recorded. The direct route is callable from ordinary user space but remains undocumented, unsupported, and version-fragile; it is intended for measurement, research, and on-device work, not for shipping software, where Core ML remains the supported path.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is a clear, step‑by‑step guide to Apple’s Neural Engine (ANE)—the special chip inside recent iPhones, iPads, and Macs that speeds up AI tasks like vision, speech, and on‑device language. Apple hasn’t published many details about how the ANE works, so the author carefully figured it out by measuring real devices and studying Apple’s hidden software. The paper explains what the ANE is, how to use it directly (without going through Apple’s higher‑level tools), how fast and energy‑efficient it is, and what kinds of AI operations it truly runs.
What questions does the paper ask?
In simple terms, the paper tries to answer:
- What is inside the ANE, and how does it do math?
- How can programs reach the ANE directly, below Apple’s Core ML framework?
- Which AI operations actually run on the ANE (not just advertised), and which don’t?
- How fast is the ANE, how much power does it use, and when is it better than the GPU?
- What do the software layers (compiler, driver, firmware) look like under the hood?
- How do these answers change across chips from A11/A18 to M1/M5?
The author tags every claim as measured (tested on real chips), decompile‑derived (read from Apple’s private software), or predicted (a best‑guess based on patterns).
How did the author study it?
Think of two complementary approaches:
- Measuring the real thing: The author ran test programs on Apple silicon (especially M1 and M5) to see the ANE’s true speed, latency, and power use. This is like timing a car on a track instead of just reading the brochure.
- Reading the hidden manuals: By analyzing Apple’s private runtime, compiler, kernel driver, and the ANE’s firmware, the author pieced together how programs are built, loaded, and executed on the ANE.
Some key ideas, explained with everyday language:
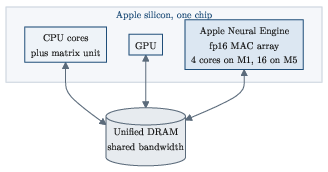
- Fixed‑function matrix accelerator: The ANE is built to do one kind of work extremely well—matrix math (the core of neural networks). It’s not a general‑purpose CPU; it’s more like a specialized kitchen appliance.
- fp16 products, wide accumulator: The ANE multiplies numbers in a smaller format (fp16—about “half‑precision”) but adds them into a much bigger “bucket” (a wide accumulator, like full 32‑bit precision). Imagine adding a lot of small cups of water: each cup is measured roughly, but the big bucket that holds the total is very precise, so your total stays accurate.
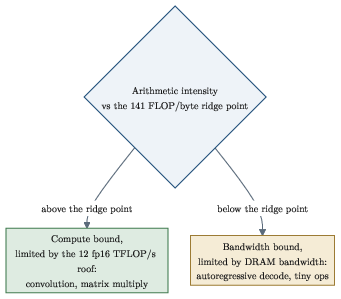
- Roofline model: This is a simple “speed limit” picture. A program’s performance is limited by either:
- how fast the ANE can compute (its peak math speed), or
- how fast it can read/write data (memory bandwidth).
- If your program does a lot of math per byte moved, you hit the compute limit; if it shuffles lots of data with little math, you hit the bandwidth limit.
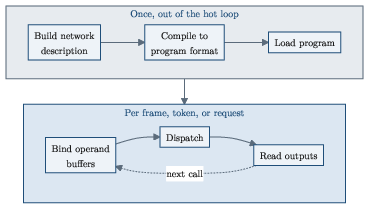
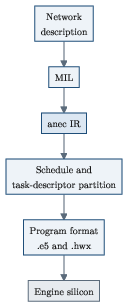
- Compile once, dispatch many: Using the ANE is a two‑step dance: 1) Compile: Convert your model into the ANE’s own program format (this is expensive and should happen outside your main loop). 2) Dispatch: Send inputs, run the already‑compiled program, and get outputs (fast and repeated often).
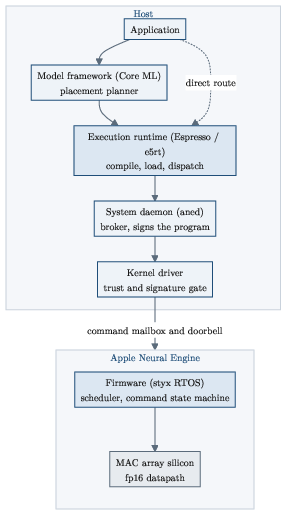
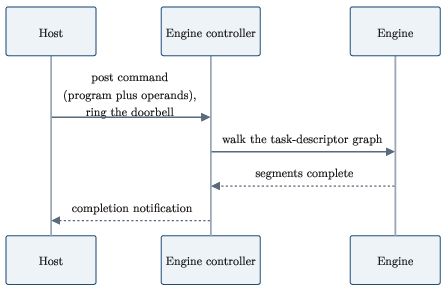
- Mailbox command and autonomous coprocessor: The ANE runs on its own. The CPU drops a “to‑do card” into a mailbox (naming the program and buffers), rings a doorbell, and the ANE does the work and reports back. The CPU doesn’t micromanage it.
- Static graph, not live branching: The compiled program is a fixed plan decided at compile time. The ANE walks this plan; it doesn’t make “if/else” decisions based on values it computes mid‑run. If your model needs data‑dependent branching, that decision must happen on the CPU/GPU, or be turned into a “do both and mask” pattern.
- Keeping state on the ANE: You can keep large tensors (like a key‑value cache for LLMs or optimizer state for training) resident across calls so you don’t copy them back and forth. You only send the small per‑step inputs (like the next token).
What did the study find?
Here are the main takeaways, explained simply.
- How the math works (numerics)
- The ANE multiplies in fp16 but sums with a wide accumulator. That means long chains of additions stay very accurate.
- This setup is great for convolutions and matrix multiplies (vision, audio, encoders), where partial sums should be precise.
- Some transformer steps (especially cancellation‑heavy projections) can still lose precision because each product is rounded to fp16 before being added, even though the sum itself is precise. Those steps may need wider math on CPU or GPU.
- How fast and efficient it is (roofline on M1)
- Peak math speed: about 12 fp16 TFLOP/s.
- Memory bandwidth: about 85 GB/s.
- “Ridge point” (the math‑per‑byte level where you switch from bandwidth‑bound to compute‑bound): about 141 FLOP per byte.
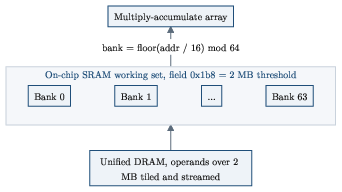
- There’s a 2 MB on‑chip working‑set limit. If your “live” data tiles don’t fit under that, you’ll stall on off‑chip traffic.
- Energy: about 0.5 picojoules per FLOP sustained, as low as ~0.37 pJ/FLOP at the sweet spot.
- Compared to the GPU
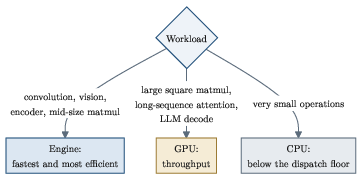
- On a 256‑channel 3×3 convolution (a classic vision workload), the ANE is about 3.8× faster and ~9× more energy‑efficient than the GPU on the same chip.
- On batched matrix multiply, the ANE stays more energy‑efficient at every batch size and is faster up to around batch size ~2048.
- The GPU can win on bandwidth‑bound tasks like autoregressive decode (where you mostly move weights rather than crunch numbers).
- What runs on the ANE (and what doesn’t)
- Not everything that’s “advertised” actually lowers to and runs on the ANE once you try to compile and execute it. For example, true 3D convolution may be listed but won’t actually reach the engine.
- Weight compression on the direct path reduces real bandwidth, not just file size:
- int4 LUT weights: ~2.37× faster than fp16 on the unentitled path.
- Structured sparsity: ~1.55–1.64× faster with ~0.43× the bytes.
- The “two core counts” puzzle
- Apple markets “16 cores” on M1 (and higher on newer chips).
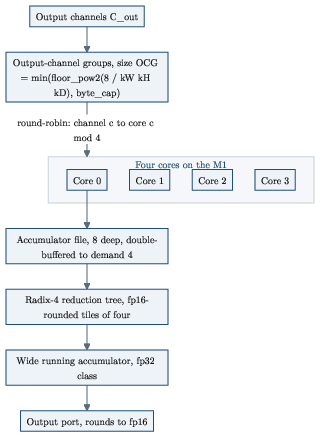
- Internally, the compiler’s throughput unit for M1 base parts is 4 “architectural cores” (8 on M1 Pro/Max; 16 on M5). Each architectural core emits about 4 fp16 output channels per cycle, which lines up with the measured 12 TFLOP/s peak.
- How to reach it below Core ML
- Core ML is the official route, but it may split work across CPU/GPU/ANE, and it doesn’t tell you what ran where.
- The author shows a direct, unsupported route through Apple’s private Espresso runtime that compiles and dispatches straight to the ANE. This is meant for research, measurement, and on‑device experiments (not App‑Store shipping apps).
- Under the hood there’s a stack: frontend (Core ML or direct runtime), compiler, engine framework/daemon, kernel driver, firmware (with a 93‑command host protocol), and the silicon.
- Latency and queuing behavior
- A tiny test dispatch on M1 costs about 190 microseconds total, with ~98% of that being software/firmware overhead (not ANE compute).
- The driver keeps one command “in flight,” so two threads submitting concurrently mostly serialize.
- Cross‑chip coverage
- The decoded targets span A11–A18 and M1–M5. Claims are checked across generations where possible. A seeded training run reproduced to within 0.001 final accuracy across generations.
Why does this matter?
- For developers and researchers: This guide turns the ANE from a black box into a usable, measurable target. Knowing its strengths (fp16 products + wide accumulator, strong convolutions/matmuls, energy efficiency) and limits (fixed control flow, 2 MB on‑chip threshold, bandwidth‑bound cases) helps you design models that run faster and sip power on Apple devices.
- For performance and battery life: On tasks the ANE is built for, it can be much faster and far more energy‑efficient than the GPU. That means snappier apps and longer battery life for vision, speech, and on‑device AI.
- For the ecosystem: The paper documents the path below Core ML, the program format, compiler behavior, driver/firmware protocol, and real roofline numbers. This shared knowledge can guide tools, benchmarks, and future research on mobile NPUs.
- For future chips and models: The roofline picture and the fp16+wide‑accumulator design apply across generations. If you fit your workload to those contours—keep working sets under ~2 MB, increase math per byte, compress or sparsify weights—you’re more likely to hit the ANE’s “sweet spot” on today’s and tomorrow’s Apple silicon.
In short, this paper shows what the ANE is good at, how to reach it directly, how fast and efficient it can be, and where its limits are—so people can build smarter, faster, and more battery‑friendly AI on Apple devices.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete issues unresolved or only partially addressed; each item suggests a direction for future validation or measurement:
- Exact accumulator width and rounding semantics are unspecified beyond “fp32-class.” Quantify accumulator bit width, rounding mode, subnormal handling (flush-to-zero?), NaN/Inf propagation, and saturation behavior across ops and chips.
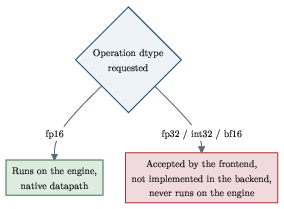
- Non-fp16 datatype support remains unclear. The frontend accepts fp32/int32/bf16, but the backend “does not implement them.” Verify on M2–M5/A16–A18 whether any non-fp16 execution paths exist and characterize their performance/accuracy if present.
- The 2 MB on-chip working-set threshold is measured on M1; its size, topology, and associativity across chips (M2–M5/A14–A18) are not mapped. Quantify per-generation on-chip memory capacity, banking, and its impact on tiling and ridge point.
- The roofline parameters (P, B, ridge, pJ/FLOP) are measured mainly on M1 (with some M5 checks). Systematically replicate on intermediate generations (M2/M3/M4) to establish scaling trends and variability under thermal throttling and DVFS.
- DRAM bandwidth attribution to ANE vs shared fabric is not isolated. Measure effective bandwidth to ANE under CPU/GPU load to model contention and scheduling implications.
- Three-dimensional convolution is “advertised” but reportedly never lowers to the engine. Identify precise conditions, firmware/compiler gates, and whether newer chips enable it; if not, document substitutes (e.g., decompositions) and their costs.
- Operation coverage vs “capability bits” is only partially validated. Complete a compile-and-run reachability census across chips/OS versions; publish a machine-readable operation-by-device matrix with negative cases and repro scripts.
- Precision loss in transformer decoders is attributed to fp16 input/weight rounding under cancellation, not the accumulator. Evaluate compensated/blocked summation, scaling, or reordering strategies that remain ANE-admissible and quantify accuracy recovery.
- Quantization details for int8/int4-LUT paths are not fully characterized. Determine supported quantization schemes (per-tensor/per-channel/groupwise; signed/unsigned; zero-points; dequant precision), dequant microarchitecture, and calibration constraints across chips.
- Structured sparsity support is only reported via speedup factors. Reverse-engineer the accepted sparsity patterns (e.g., NxM), enforcement granularity, pruning tolerance, and compiler acceptance criteria per device.
- Weight compression is said to reduce bandwidth on the direct path, but the compression formats, decompression costs, and interactions with tiling/caching are not fully quantified. Benchmark compression efficacy vs shapes and layer types across chips.
- The exact size and behavior of the ANE address-translation unit (page sizes, TLB reach, walk costs, coherency) are not documented. Measure mapping/binding overhead and TLB miss penalties; evaluate huge-page benefits for large models.
- Dispatch overhead (~190 µs on M1) dominates small inferences; only a coarse breakdown is given. Identify which stages are tunable (runtime copies, request building, firmware kick, kernel completion) and test low-latency event paths/timeouts to reduce overhead.
- The driver “keeps at most one firmware command in flight,” serializing submissions. Determine whether this is a policy or hardware limit; test kernel/runtime versions and newer chips for true concurrency and its effect on latency/throughput tail.
- Multi-stream overlap is “unfinished” on M1 (second stream completion event not firing). Root-cause the eventing issue, test on M2–M5, and document safe patterns for concurrent streams and cross-process multiplexing.
- Preemption is described at task-queue granularity with mid-flight abort, but fairness and priority scheduling are not evaluated. Measure latency/throughput isolation across priorities and processes; characterize starvation risks and preemption overheads.
- Persistent state: native resident-state operations are rejected on M1, with aliasing used instead. Verify whether native persistent-state DMA/ops exist and work on M2–M5, the maximum resident size, lifetime across power-gates, and performance vs aliasing.
- Control-flow constraints are fundamental (static, compile-time only). Catalog common dynamic-model transformations that produce ANE-admissible graphs (e.g., masking both branches, fixed unrolls) and quantify their compute/memory overheads.
- The parametric-to-register program expansion occurs below the host boundary; no instruction-level trace is available. Explore safe instrumentation hooks or firmware logging to extract per-segment timing and register sequences without entitlements.
- Firmware protocol: 93 host commands are mentioned, but the completeness of decoding and semantic validation is unclear. Enumerate unknown/undocumented commands, their suspected roles, and generate fuzz/trace frameworks to resolve them safely.
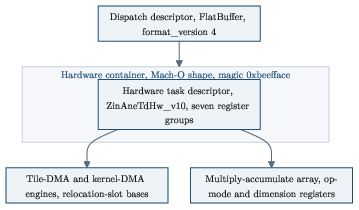
- Program signing and loader behavior (magic 0xbeefface) are noted but the signature scheme, versioning, and cache invalidation policies are not detailed. Document signature verification, cache eviction strategies, and cross-OS upgrade compatibility.
- Secure/exclusive mode (quiesce and power-cycle) is described without API details or costs. Measure transition latency, impact on mixed workloads, and implications for multi-tenant scheduling and protected-content isolation.
- The Core ML planner is opaque and provides no device attribution to callers. Develop methods to attribute per-op/device execution (e.g., tracing, counters, power signatures) and validate planner decisions against a transparent cost model.
- Energy measurements are derived from software-based tooling; ANE-specific hardware counters/PMUs are not exposed. Seek or emulate per-engine power/energy counters; quantify CPU/GPU runtime contributions during dispatch for accurate attribution.
- Validation breadth: many claims are measured on M1 (and some on M5) or are decompile-derived/predicted. Expand silicon validation across A14–A18 and M2–M5 for all key claims (core counts, channel/cycle rates, rooflines, op reachability).
- Exact mapping from M-series to internal H-series identities is asserted; verify on more SKUs and OS builds, and document any anomalies (e.g., binning variants, frequency caps).
- Training support is hinted (seeded run reproduces accuracy), but available ops for backprop/optimizers, memory pressure, and step latency/energy are not comprehensively characterized. Provide a minimal end-to-end training suite with ANE-heavy segments and profiled bottlenecks.
- GPU vs ANE crossover for autoregressive decode is discussed qualitatively. Quantify crossover points vs model size, quantization/compression, KV-cache residency, and batch size; propose hybrid scheduling policies with measured break-even curves.
- Pre-A13/A11–A12 devices lack a modern intermediate-language path. Explore alternative access/compatibility layers for legacy chips or conclusively document architectural reasons they cannot be targeted.
- Version fragility: the direct route (runtime/driver/firmware ABIs) is undocumented and may change across OS updates. Propose a robust compatibility layer with feature probes, ABI hashing, and automated conformance tests to detect and adapt to changes.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s measured findings (roofline, numerics, dispatch model), reverse-engineered methods (direct ANE route, firmware protocol), and practical guidance (resident buffers, compression, scheduling).
- ANE roofline–guided model tuning and placement for on‑device apps
- Sector: software, mobile AI, AR/VR, media
- What: Use the paper’s M1/M5 roofline (e.g., ~12 fp16 TFLOP/s, ~85 GB/s DRAM, ridge point ~141 FLOP/byte, 2 MB on‑chip working‑set threshold) to decide which layers to target to the ANE vs GPU/CPU and to refactor models (tiling, fusion, batch size, kernel shapes) to be compute‑bound on ANE.
- Tools/workflows: Core ML with careful operator choices and tensor shapes; internal validation via ANEForge/libane for microbenchmarks; simple arithmetic‑intensity calculators in CI.
- Dependencies/assumptions: Cannot force placement through Core ML (hint only); benefit depends on operations that actually lower to ANE; 2 MB on‑chip threshold must be respected; best fit is fp16 compute‑bound ops (convs, GEMMs).
- Energy‑aware feature design for battery and thermals
- Sector: software, consumer apps, wearables
- What: Prefer ANE for compute‑bound vision/audio stages (~9× energy efficiency on 3×3 conv vs GPU; ~0.37–0.5 pJ/FLOP sustained) and reserve GPU for bandwidth‑bound token decode when necessary.
- Tools/workflows: Feature budgeting using energy roofline; telemetry/QA gating on energy per inference.
- Dependencies/assumptions: Energy numbers depend on chip, OS, and workload; decode workloads may still favor GPU due to bandwidth limits; sustained performance requires respecting thermal envelopes.
- Resident‑state inference loops (KV caches, rolling state) to reduce host traffic
- Sector: LLMs on device, robotics, AR
- What: Keep key/value caches or other state resident across dispatches by aliasing output→input ports to avoid large host round‑trips; send only per‑step inputs (token/minibatch).
- Tools/workflows: Execution‑stream port binding and buffer aliasing (as described) via ANEForge/libane for prototyping; incorporate into Core ML graphs where feasible (via concatenation/masking patterns).
- Dependencies/assumptions: M1 path uses aliasing and masked updates (no native in‑place state DMA on M1); Autoregressive decode may remain bandwidth‑bound; correctness requires careful indexing/position updates.
- Weight compression for throughput and bandwidth reduction
- Sector: software, edge AI, model compression
- What: Use int4 LUT weights (~2.37× faster than fp16 on unentitled engine) and structured sparsity (~1.55–1.64× faster, ~0.43× bytes) to speed inference and reduce DRAM traffic.
- Tools/workflows: Post‑training quantization and sparsity pruning; validate via direct route microbenchmarks; deploy where Core ML supports equivalent compressed formats.
- Dependencies/assumptions: Full benefits observed via direct/unentitled path; Core ML support may limit deployable formats; model accuracy must be re‑validated after compression/sparsity.
- CI performance/energy regression testing for iOS/macOS models
- Sector: software tooling
- What: Add roofline‑based checks and microbenchmarks to CI (dispatch latency floor ~0.23 ms, single in‑flight limit, 2 MB threshold) to catch regressions in arithmetic intensity, working‑set size, and dispatch overhead.
- Tools/workflows: ANEForge/libane harnesses; scripted arithmetic‑intensity and memory‑footprint analyzers.
- Dependencies/assumptions: Direct route is version‑fragile and not App‑Store‑safe; use for internal validation only; Core ML models must still pass App Store policies.
- Privacy‑preserving on‑device perception (vision, speech) with improved efficiency
- Sector: healthcare, education, consumer apps, accessibility
- What: Run fp16‑friendly conv/GEMM‑heavy pipelines on ANE to keep data on device and extend battery life (e.g., offline transcription, image classification, accessibility features).
- Tools/workflows: Core ML pipelines with ANE placement hint; operator choices favoring ANE‑lowerable ops; compression and tiling to stay compute‑bound.
- Dependencies/assumptions: Data‑dependent control flow must be avoided in ANE segments; some ops (e.g., 3D conv) may not lower to ANE; final placement is planner‑controlled.
- Real‑time robotics/AR perception loops with deterministic budgets
- Sector: robotics, AR/VR
- What: Use the measured per‑dispatch latency and single in‑flight behavior to schedule perception/control loops; keep state resident; fuse conv blocks to remain within the 2 MB working set and ridge point.
- Tools/workflows: Fixed‑rate dispatch scheduling; graph fusion; hybrid routing of bandwidth‑bound stages to GPU.
- Dependencies/assumptions: Mid‑flight preemption occurs at task‑queue granularity; avoid overlapping streams in one process on M1; worst‑case latency must include firmware round trip.
- Academic measurement and curriculum on mobile NPUs
- Sector: academia
- What: Use the open ANEForge route to teach roofline analysis, measure energy/time trade‑offs, and replicate cross‑generation results; study numerical behavior (fp16 products, wide accumulator).
- Tools/workflows: Labs centered on arithmetic intensity, working‑set experiments, and cancellation sensitivity tests.
- Dependencies/assumptions: Requires A13/M1+ devices; private interfaces are unsupported and brittle across OS updates; ethical use of reverse‑engineered paths in coursework must be cleared.
- Security‑sensitive workloads using secure exclusive mode
- Sector: finance, DRM, enterprise
- What: For protected content or sensitive model execution, use the secure mode that quiesces and power‑cycles the engine for exclusive access.
- Tools/workflows: Firmware/driver flags through the engine framework; isolate workloads requiring stronger guarantees.
- Dependencies/assumptions: Access to secure mode may be restricted; operational overhead of quiesce/power‑cycle must be budgeted; still not a public API.
- Device selection and fleet guidance
- Sector: enterprise IT, product management
- What: Map core counts (e.g., 4→16 across M1→M5) and throughput scaling to choose devices for field deployments where on‑device AI is critical.
- Tools/workflows: Procurement checklists; internal benchmarks aligned to the paper’s envelope.
- Dependencies/assumptions: Performance scales with cores/clock but retains the same fp16/working‑set constraints; confirm on target chip revisions.
Long‑Term Applications
These require additional research, API support, or productization beyond the current, private, and version‑fragile state described in the paper.
- Supported, public ANE runtime API and placement controls
- Sector: policy, industry, developer ecosystem
- What: Apple (or standards bodies) could expose a documented, stable user‑space API for direct ANE access and/or finer placement feedback, enabling shipping apps to rely on ANE beyond a hint.
- Potential products: ANE SDKs, placement‑explain tools in Xcode, per‑op device attribution.
- Dependencies/assumptions: Requires vendor cooperation; security and stability review; backward compatibility commitments.
- Hybrid CPU–GPU–ANE schedulers integrated into model frameworks
- Sector: software, ML platforms
- What: Frameworks that use measured rooflines (compute, bandwidth, energy) and dispatch overhead to automatically partition graphs: ANE for compute‑bound tiles, GPU for bandwidth‑bound decode, CPU for control‑heavy parts.
- Potential products: Core ML planner enhancements; third‑party compilers with dynamic cost models.
- Dependencies/assumptions: Access to accurate per‑chip cost models; visibility into which ops truly lower to ANE; runtime feedback loops.
- Compiler and hardware support for broader op sets and dtypes
- Sector: compilers, hardware
- What: Add support for ops currently advertised but not realized (e.g., 3D conv) and dtypes like bf16/int8 with native accumulation paths; improve in‑place persistent‑state DMA engines.
- Potential products: Next‑gen ANE architectures; updated compilers; Core ML operator expansions.
- Dependencies/assumptions: Silicon roadmap changes; firmware and driver updates; accuracy/energy trade‑off studies.
- Model‑architecture redesign for fp16 products with wide accumulators
- Sector: research, applied ML
- What: Develop transformer and sequence modules that reduce cancellation in fp16 product space (e.g., down‑projection reformulations, scaled norms) to align with ANE numerics while preserving accuracy.
- Potential products: “ANE‑friendly” transformer blocks; libraries with numerically stable fp16 kernels.
- Dependencies/assumptions: Requires empirical validation across tasks; may interact with quantization/normalization strategies.
- Structured‑sparsity‑aware training and fine‑tuning pipelines
- Sector: ML ops, edge AI
- What: Train with hardware‑aligned sparsity patterns that the ANE exploits for 1.55–1.64× speedups and bandwidth cuts; bake in pruning and recovery techniques to preserve accuracy.
- Potential products: Training toolkits targeting ANE sparsity masks; deployment pipelines emitting compatible formats.
- Dependencies/assumptions: Needs end‑to‑end tooling support and Core ML compatibility; model‑specific accuracy impacts.
- Automated intensity/working‑set analyzers and graph rewriters
- Sector: developer tools
- What: Tools that parse models (Core ML/ONNX/PyTorch), estimate arithmetic intensity and live working‑set, suggest tiling/fusion or re‑architecting to remain under 2 MB and above the ridge point; flag non‑lowerable ops.
- Potential products: Xcode plug‑ins; CI linters; graph transformers.
- Dependencies/assumptions: Accurate static/dynamic analysis; up‑to‑date knowledge of compiler reachability; vendor buy‑in increases reliability.
- Low‑power on‑device training or adapter fine‑tuning
- Sector: edge AI, personalization
- What: Use resident optimizer state and compute‑bound kernels to explore small‑scale fine‑tuning on device (e.g., LoRA adapters, personalization) within thermal/energy limits.
- Potential products: On‑device personalization frameworks; privacy‑preserving fine‑tuning kits.
- Dependencies/assumptions: Dispatch overhead and bandwidth constraints limit batch sizes; numerical stability in fp16 must be ensured; supported ops must cover training steps.
- Cross‑vendor NPU roofline and energy metrics standardization
- Sector: policy, benchmarking, procurement
- What: Establish common reporting (compute/bandwidth/energy ridge points, working‑set thresholds) for mobile NPUs to inform fair benchmarks and procurement.
- Potential products: Industry benchmarks; certification programs; energy labels for on‑device AI features.
- Dependencies/assumptions: Cooperation across vendors; standardized measurement methods (e.g., ML.ENERGY practices).
- Secure multi‑tenant ANE scheduling for enterprise
- Sector: enterprise, OS/runtime
- What: Extend priority queues and mid‑flight preemption into QoS‑aware, multi‑tenant policies for concurrent apps using the ANE, with isolation and predictable latency.
- Potential products: OS‑level ANE QoS APIs; MDM policies for AI workloads.
- Dependencies/assumptions: Requires OS and firmware support; careful design to avoid priority inversion and starvation.
- Generalized methodology to characterize other NPUs/SoCs
- Sector: academia, silicon vendors
- What: Apply the paper’s reverse‑engineering and measurement approach (dispatch paths, firmware protocols, roofline+energy) to other platforms to guide cross‑platform model design.
- Potential products: Comparative NPU atlases; portable optimization guides.
- Dependencies/assumptions: Legal/ethical limits on reverse engineering; access to devices; different vendors’ protections may prevent similar access.
Key cross‑cutting assumptions and dependencies
- Public vs private access: The direct ANE route (ANEForge/libane) is undocumented, unsupported, and fragile across OS versions; shipping apps should use Core ML.
- Device/OS requirements: Practical direct access requires A13/M1+; behaviors and core counts vary by chip (e.g., M1=4 cores internally; M5=16).
- Operator reachability: Some advertised capabilities (e.g., certain 3D conv) may not compile to ANE; always confirm by compile‑and‑run.
- Numerical constraints: Products are fp16; accumulation is wide; cancellation‑heavy steps may need CPU/GPU anchors; dtype choices affect accuracy.
- Performance model boundaries: 2 MB on‑chip working‑set threshold; ridge point ~141 FLOP/byte (M1); dispatch latency floor ~0.23 ms; single in‑flight request on M1.
- Energy and thermal behavior: Efficiency claims are workload‑ and device‑specific; sustained behavior depends on thermal design and system load.
Glossary
- accumulator (wide): A larger internal summation register that holds partial sums at higher precision than inputs/outputs. "The products are fp16 while the accumulator is wide, of fp32 class,"
- address translation unit: Hardware that maps host memory buffers into the accelerator’s address space for direct access. "Operand buffers are mapped through the engine's own address translation unit"
- arithmetic intensity: The ratio of operations to bytes moved; higher values favor compute-bound performance in roofline analysis. "the arithmetic intensity above which a kernel is compute-bound rather than bandwidth-bound"
- bf16: Brain floating-point 16-bit format with 8-bit exponent and 7-bit mantissa (plus sign); a reduced-precision FP type. "The frontend accepts fp32, int32, and bf16 type annotations, but the backend does not implement them."
- capability bit: A hardware or software flag advertising support for an operation, not necessarily indicating actual executability. "against which a capability bit only advertises."
- cancellation probe: A test that checks numerical precision by summing large positive and negative terms with small residuals. "A cancellation probe settles the question:"
- content-addressed cache: A storage where entries are keyed by a hash of their contents to avoid recomputation. "writes a program to a content-addressed cache on disk"
- content hash: A hash derived from the data itself used as a cache key or identity. "A content hash keys the compiled program"
- Core ML: Apple’s machine learning model framework that mediates access to on-device accelerators. "The public way to use the engine is Core ML"
- data movement engines: On-chip units that orchestrate transfers between memories and compute cores. "programming the data movement engines and the multiply array"
- decompile-derived: Information inferred from disassembling and analyzing binaries rather than from direct measurement. "Claims are labeled as measured, decompile-derived, or predicted,"
- doorbell: A signaling mechanism to notify the device that a command is ready in a shared queue. "and rings a doorbell."
- execution stream: A runtime sequence used to encode and submit operations for execution on the device. "and drives an execution stream"
- flat-buffer container: A compact, schema-defined binary container format with direct access to fields without parsing overhead. "a flat-buffer container whose fused graph collapses to a three-op chain,"
- fp16: IEEE 16-bit floating-point format (half precision) used for multiplications and I/O on the ANE. "The products are fp16 while the accumulator is wide"
- hardware abstraction layer (HAL): A layer insulating software from hardware specifics, exposing uniform controls and queries. "read from the hardware-abstraction-layer offset 0x238,"
- IOKit: Apple’s kernel-level driver framework for device interaction in macOS/iOS. "the kernel-driver IOKit ABI"
- int4: 4-bit integer quantization for weights to reduce bandwidth/storage with some accuracy tradeoff. "On the unentitled engine, int4 lookup-table weights run about 2.37 times faster than fp16,"
- lookup-table weights: Quantized weights stored as indices into a small table to reconstruct values during execution. "int4 lookup-table weights run about 2.37 times faster than fp16,"
- mailbox: A shared memory queue used by host and device to exchange command descriptors. "The mailbox is a ring buffer of command records"
- masked update: Writing to selected positions of a tensor using a mask, avoiding full-tensor writes. "done as a standard masked update against a small position vector"
- microcode: Low-level control code executed by a processor’s control unit; absent here due to the graph-walk model. "There is no program counter to read and no microcode to dump."
- mid-flight abort: Preempting an executing task before completion to service higher-priority work. "preempts at task-queue granularity with a mid-flight abort"
- operation-by-device matrix: A cross-product table indicating which operations are supported on which chips. "an operation-by-device matrix"
- parametric descriptor: A compact per-operation description that is expanded to explicit hardware registers at load time. "a parametric per-op descriptor whose size does not grow with the tensor"
- program counter: A register indicating the current instruction address; not applicable when executing a walked graph. "There is no program counter to read"
- program image: The signed, loadable executable form of a compiled network for the device. "the program image"
- real-time operating system: A minimal OS on the device that schedules and manages time-sensitive tasks deterministically. "the engine's own real-time operating system"
- register-write: A low-level representation where program steps are explicit register writes to configure hardware. "with a register-write text section,"
- reverse-engineered: Derived by analyzing system behavior/binaries without official specifications. "This guide reports a reverse-engineered account of the engine,"
- ridge point: In roofline analysis, the crossover where performance shifts from bandwidth-bound to compute-bound. "The roofline has a ridge point near 141 FLOP per byte,"
- ring buffer: A circular queue structure allowing producer-consumer communication without moving elements. "The mailbox is a ring buffer of command records"
- roofline: A performance model that bounds attainable throughput by compute peak and memory bandwidth. "Performance begins with the roofline."
- secure mode: A protected execution mode that isolates the device for exclusive use, often via power cycling. "A secure mode can claim the engine exclusively by quiescing and power-cycling around the boundary,"
- static graph: A compile-time-fixed computation graph that the hardware walks; disallows data-dependent control flow. "The compiled program is a static graph of work segments that the hardware walks,"
- structured sparsity: A regular, pattern-based zeroing of weights to reduce compute and bandwidth while maintaining hardware efficiency. "and structured sparsity 1.55 to 1.64 times faster at 0.43 times the bytes."
- task descriptor: A per-task structure describing work partitions and data for the firmware/device scheduler. "The M1 task descriptor has no in-place resident-state data-movement engine:"
- TFLOP/s: Teraflops per second; a measure of arithmetic throughput. "12 fp16 TFLOP/s"
- unentitled: Running without special system entitlements/permissions, affecting accessible features and performance. "On the unentitled engine, int4 lookup-table weights run about 2.37 times faster than fp16,"
- weight compression: Techniques that reduce weight storage and movement (e.g., quantization), reconstructed before multiplication. "Weight compression on the direct path cuts bandwidth, not only stored size."
- working-set: The subset of data that fits in on-chip memory/cache during execution. "a 2 MB working-set threshold"
Collections
Sign up for free to add this paper to one or more collections.

