- The paper introduces SpliceLeak, a novel side-channel attack exploiting deterministic timing in non-prefix KV cache fusion to extract private tokens with single-token granularity.
- It demonstrates high experimental efficacy with a 100% extraction success rate and as few as 63 requests per token under realistic multi-tenant serving conditions.
- The authors propose SpliceDefense, a two-layer defense using quantized chunk padding and constant-time boundary fusion to nullify the attack’s timing leaks while maintaining cache efficiency.
Agent-Assisted Side-Channel Attacks on Non-Prefix KV Cache in RAG
Introduction and Motivation
The accelerating adoption of Retrieval-Augmented Generation (RAG) in LLM serving has driven major advances in throughput and factual grounding. Unlike classical prefix-based caching, contemporary RAG serving frameworks (e.g., LMCache, CacheBlend) exploit non-prefix key-value (KV) cache fusion, enabling the modular reuse of retrieved document chunks at arbitrary prompt positions. While this increases efficiency for multi-tenant, long-context inference, it introduces nontrivial new privacy attack surfaces. The discussed paper identifies and exploits a structural micro-architectural vulnerability in RAG-optimized KV cache fusion, demonstrating that previously proposed prefix-matching timing attacks are inadequate for realistic RAG use cases.
The paper introduces SpliceLeak, the first practical side-channel attack explicitly targeting non-prefix KV cache fusion in RAG settings, bypassing strict prefix-matching barriers that underpin existing works. The authors further propose a practical defense, SpliceDefense, preserving cache efficiency while eradicating the deterministic timing-channel exploited by the attack.
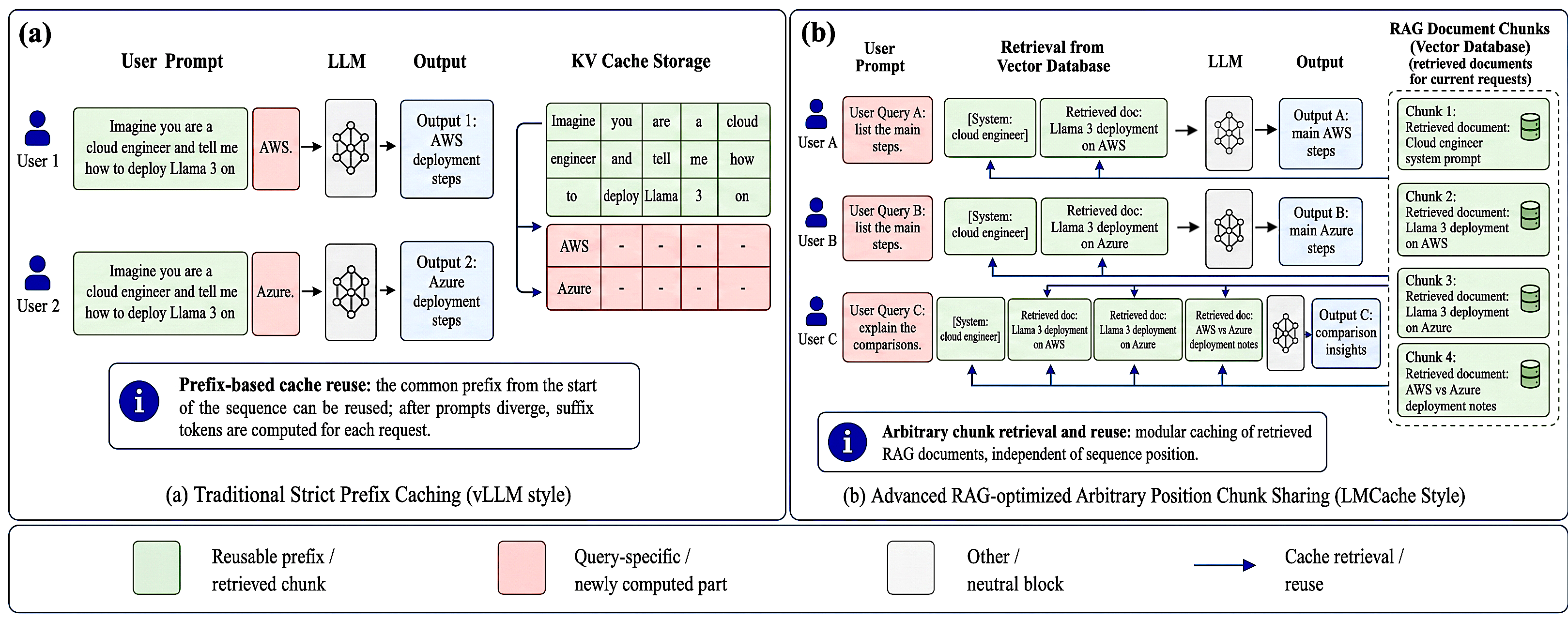
Figure 1: Comparison of KV cache sharing mechanisms. (a) Traditional strict prefix caching restricts reuse to common prefixes only; (b) RAG-optimized architectures allow arbitrary-position chunk sharing.
System Model and Attack Surface
Advanced multi-tenant RAG serving architectures are modeled as a cloud system with a retrieval engine, vector database, and GPU workers sharing a unified global KV cache. Prompts in RAG are inherently composite: a private system/user-specific prefix, one or more retrieved document chunks, and a task-specific query. Non-prefix KV cache fusion supports arbitrary chunk reuse, requiring memory chunk alignment and selective re-computation of unaligned tail tokens.
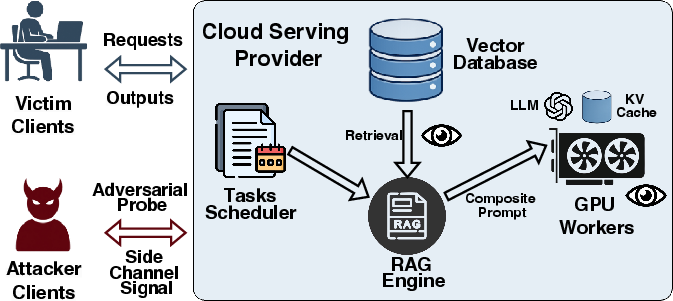
Figure 3: High-level system architecture for multi-tenant RAG serving, highlighting the components involved in document retrieval, prompt assembly, and cache fusion.
The critical insight is that chunk-aware memory management at block boundaries introduces deterministic latency artifacts, which leak structural information about the hidden prompt prefix and further enable semantic extraction.
SpliceLeak: Attack Methodology
The SpliceLeak attack proceeds in two phases:
Phase I: Structural Fingerprinting
SpliceLeak exploits a micro-architectural Step-Wave effect in the time-to-first-token (TTFT) latency due to deterministic chunk scheduling. By systematically varying the attacker's probe prefix length and observing TTFT, the attacker can deduce the precise length of the victim's private prefix with single-token granularity.
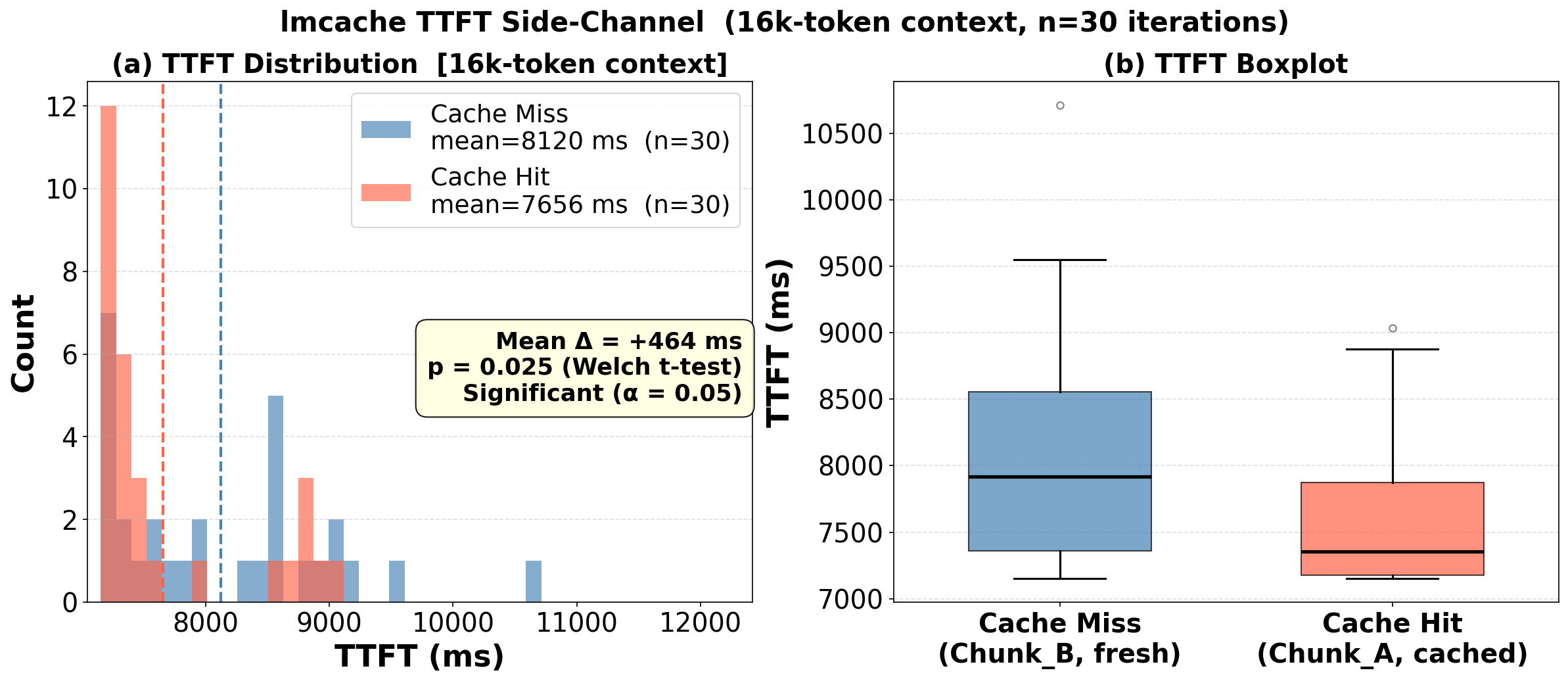
Figure 5: TTFT side-channel in a 16K-token RAG scenario reveals clear latency shifts correlated with cache hits, confirming observable timing leakage.
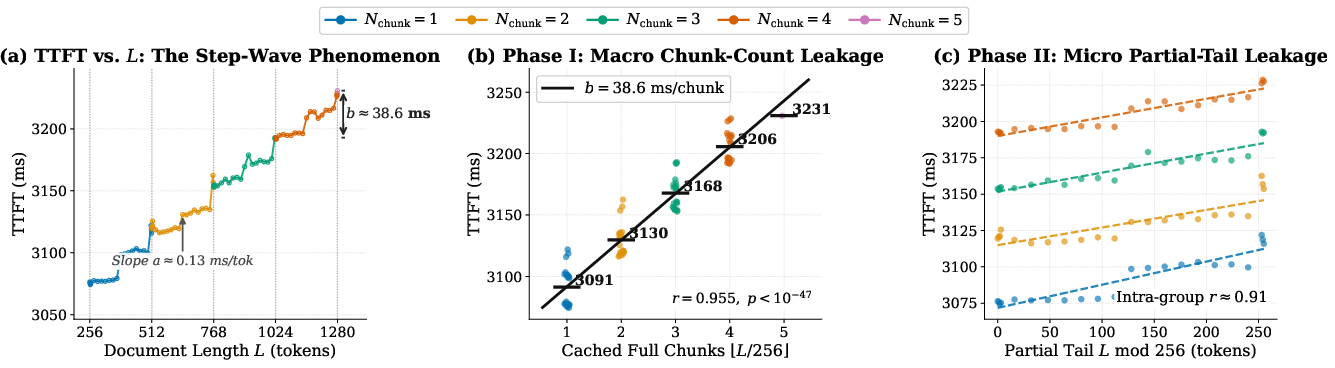
Figure 2: Step-Wave profiling in LMCache: chunk-aligned reuse causes step-function timing; tail re-computation reveals residual length, enabling token-level fingerprinting.
Once the structural length is known, the attacker launches token-by-token right-to-left extraction at the chunk fusion boundary. By observing TTFT dips when the probe’s boundary token matches the victim’s true token, semantic content is extracted via side-channel feedback. The process is enhanced with an LLM agent generating high-probability token candidates, drastically reducing the search space.
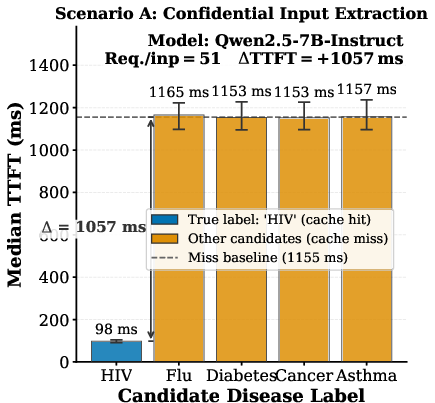
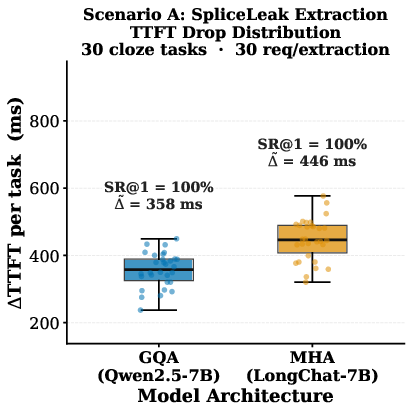
Figure 4: Benchmark of single-step confidential input extraction; correct token guess yields a marked TTFT drop, making extraction efficiently practical.
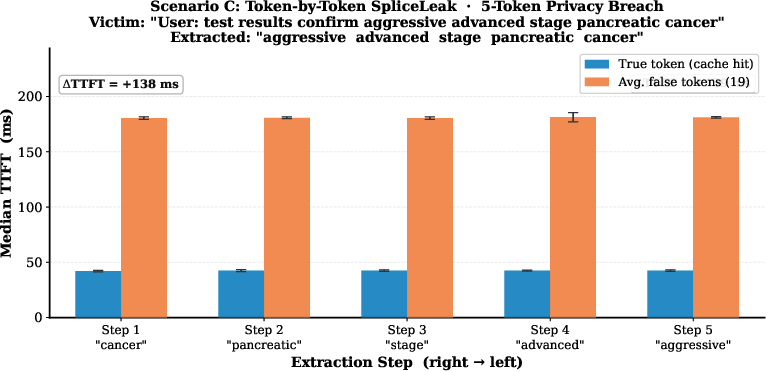
Figure 6: Sustained, deterministic TTFT gap persists across multiple right-to-left extraction steps, validating the stability of the side-channel for continuous semantic extraction.
Evaluation and Empirical Results
The authors conduct extensive evaluation using production-grade serving stacks (vLLM+LMCache, both MHA and GQA architectures) under realistic multi-tenant workloads and background traffic.
Noteworthy empirical results include:
- Success Rate: SpliceLeak achieves up to a 100% extraction success rate across bounded-entropy prompts and structured templates.
- Attack Cost: In continuous extraction scenarios, as few as 63 requests per token suffice, even in the presence of batching/system noise.
- Signal Strength: Deterministic timing voids are robust (e.g., +104 ms), vastly exceeding observable system jitter and persisting across all tested architectures and scenarios.
- Scenario Generality: The attack is effective for both highly templated confidential input extraction and high-entropy zero-knowledge prompt reconstruction.
Tabulated results (in the original) further show the completeness (reversal ratio), request cost per token, and absence of architectural mitigation by modern attention variants.
Mitigation: SpliceDefense
SpliceDefense is a two-layer defense designed to maintain cache efficiency while restoring timing isolation.
- Quantized Chunk Padding (QCP): Rounds private prefix lengths to the next chunk boundary with dummy tokens, eliminating Step-Wave length oracles at negligible latency/memory cost.
- Constant-Time Boundary Fusion (CTBF): Enforces constant-time re-computation cost at every chunk fusion boundary, eradicating the semantic TTFT dip.
Empirical evaluations show both defenses completely flatten observable timing signals (ΔTTFT≈0), with throughputs/emulated padding costs well within practical serving tolerances.
Implications and Future Directions
This research exposes a fundamental, previously underestimated privacy risk in high-performance RAG LLM serving. The work demonstrates that non-prefix KV cache fusion, essential for efficient RAG, introduces side-channel vulnerabilities not addressed by existing strict-prefix-based threat models. Critically:
- Techniques such as attention head sharing, cache compression, and batching do not eliminate the vulnerability.
- Application-layer or vector-database hardening is orthogonal; vulnerabilities are rooted in system-level scheduling and memory management, not content or retrieval logic.
- All multi-tenant LLMaaS deployments enabling memory deduplication without micro-architectural isolation are exposed to risk.
Long-term, any future memory optimization that facilitates aggressive reuse must account for side-channel isolation. The software proposals (QCP + CTBF) constitute immediate incremental mitigations, but hardware-assisted approaches (e.g., constant-time cache logic, architectural support for privacy domains) remain an open research avenue.
Conclusion
This work elucidates that deterministic, chunk-aware scheduling in non-prefix RAG KV cache fusion fundamentally compromises timing isolation, even in advanced multi-tenant LLMaaS deployments. The presented SpliceLeak attack leverages this to achieve high-precision structural and semantic extraction. The proposed SpliceDefense gives a practical, deployable software defense, imposing negligible serving cost while restoring privacy. The implications for large-scale model deployments are substantial—robust, side-channel-resilient memory schedulers must become a first-class concern for all future RAG-optimized inference platforms.

