- The paper introduces a method that uses essential subspace decomposition to capture dominant activation shifts, preserving key task-specific functional knowledge.
- It employs orthogonalization and eigenvalue-based weighting to merge task updates statically (ESM) and dynamically (ESM++), significantly reducing inter-task interference.
- Empirical results across vision, language, and generative domains show that the approach achieves near-oracle performance with minimal added parameters and robust data efficiency.
Essential Subspace Merging for Multi-Task Learning
The proliferation of pre-training—fine-tuning paradigms has resulted in large collections of task-specialized models adapted from the same pre-trained checkpoint. Integrating these into a single multi-task model without retraining—so-called “model merging”—poses the primary challenge of minimizing inter-task interference among task-specific parameter updates. Direct averaging or naive merging dilutes salient task knowledge due to accumulation of irrelevant or contradictory parameter directions. Prior work, including SVD-based approaches, has exploited low-rank structure in task updates, but decompositions grounded in parameter-space energy fail to optimally preserve functional behavior, since discarded directions can induce large output shifts if the input distribution aligns heavily with them.
Empirical analysis demonstrates that task-update-induced activation shifts are highly concentrated in a small number of principal directions. The subspace spanned by these directions, termed the essential subspace, robustly captures functional task knowledge. Low-energy residual directions have minimal relevance for their own tasks but, when accumulated across merged models, create substantial cross-task interference.
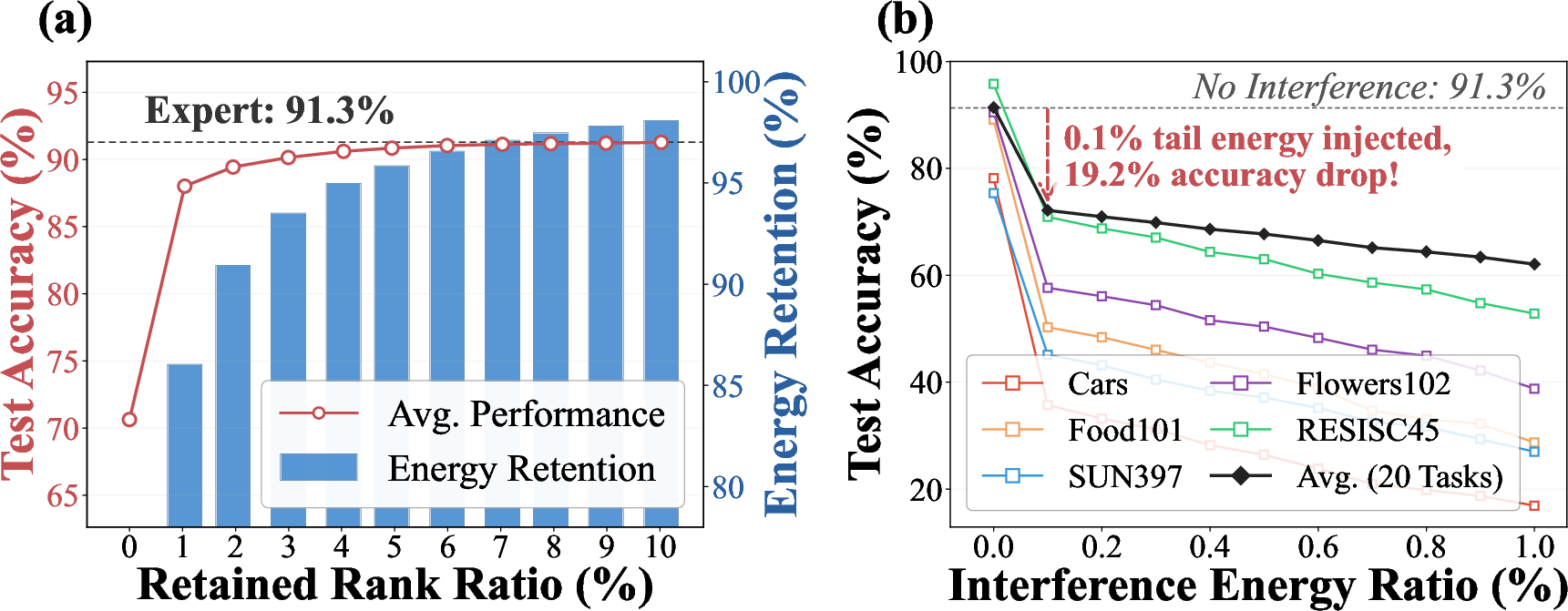
Figure 1: Fine-tuned task updates exhibit highly low-rank structure; retaining few principal directions preserves nearly all energy and task performance, while accumulation of low-energy directions across tasks sharply degrades target task accuracy.
Essential Subspace Decomposition (ESD)
Contrasting SVD—which minimizes parameter-space error—Essential Subspace Decomposition (ESD) targets functional preservation by decomposing each task update with respect to its output activation shifts. For each task, PCA is performed on the activation-shift matrix induced by the update, yielding principal directions (eigenvectors) and corresponding eigenvalues quantifying explained variance. Truncating to the top-r directions optimally bounds expected functional error by the sum of discarded eigenvalues, directly linking retained capacity to task behavioral fidelity.
This principled functional decomposition is provably superior to SVD, as confirmed both theoretically and empirically, in concentrating energy and preserving task-specific features.
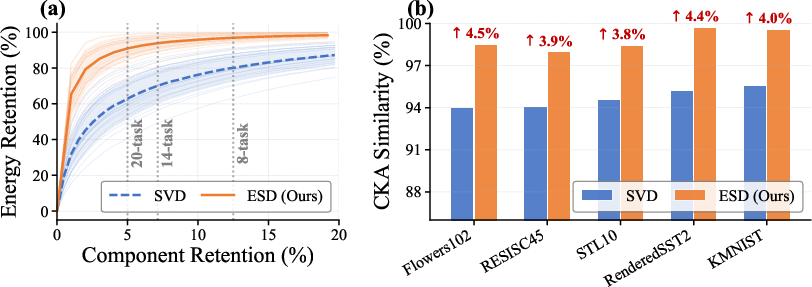
Figure 2: ESD retains more activation-shift energy and achieves higher CKA similarity to fine-tuned experts compared to SVD, for equal retained rank.
Static Merging via ESM
The Essential Subspace Merging (ESM) framework fuses task knowledge into a single model in a completely training-free, static manner. For each task, ESD is applied to each matrix parameter, essential components are truncated to the allocated rank, and then concatenated across tasks. To mitigate cross-task interference, concatenated bases and coordinates undergo orthogonalization (via SVD and polar normalization), overweighting high-eigenvalue directions to prioritize information-rich updates. The merged model is constructed as the sum of the pre-trained weights and the orthogonalized, concatenated essential updates, scaled globally via a coefficient optimized on a validation set.
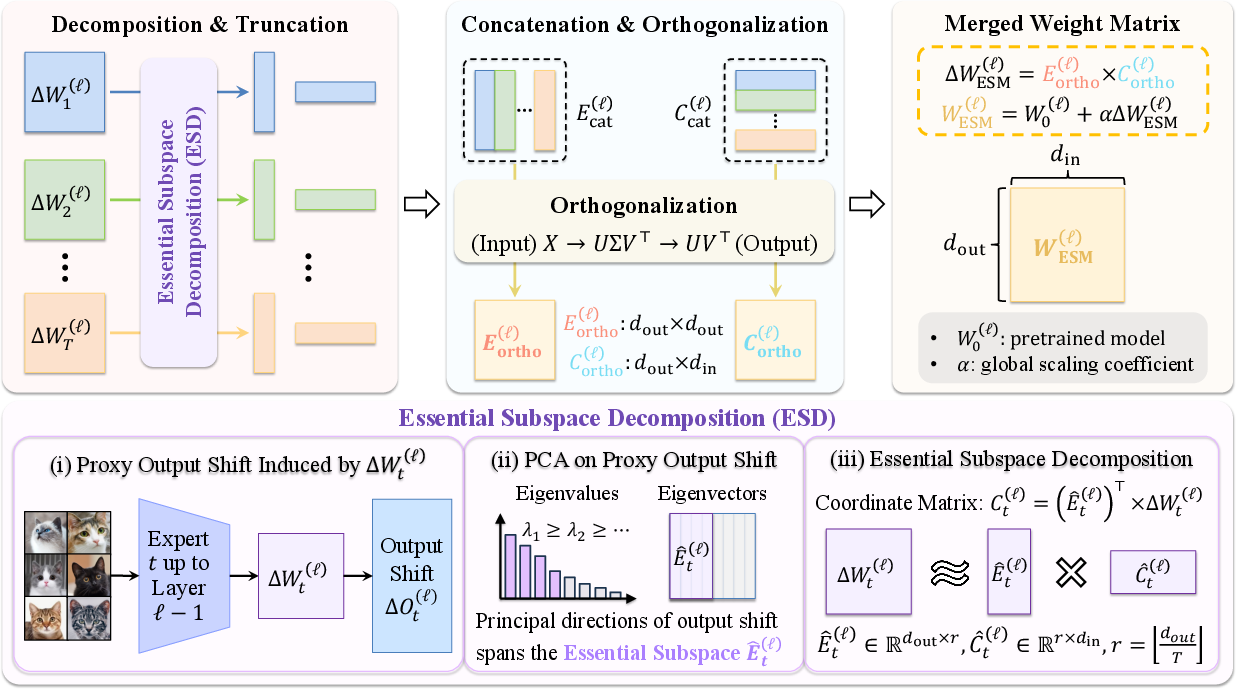
Figure 3: Schematic of ESM: per-task ESD decomposition, aligned concatenation, and cross-task orthogonalization followed by global scaling yields a compact merged weight matrix.
Dynamic Merging via ESM++
Despite ESM's effectiveness, static fusion inevitably suppresses task-unique specialization. ESM++ addresses this by decomposing the residual difference between each expert and the ESM-merged model into low-rank experts via ESD. At inference, prototype-based routing selects the most relevant expert for each layer based on cosine similarity between input activations and per-task prototypes, allowing dynamic composition of the ESM base with task-specific refinements.
ESM++ does not require training a router or test-time adaptation; prototypes are precomputed via a forward pass over a proxy dataset. This ultra-lightweight routing (without new parameters or retraining) achieves near-oracle performance.
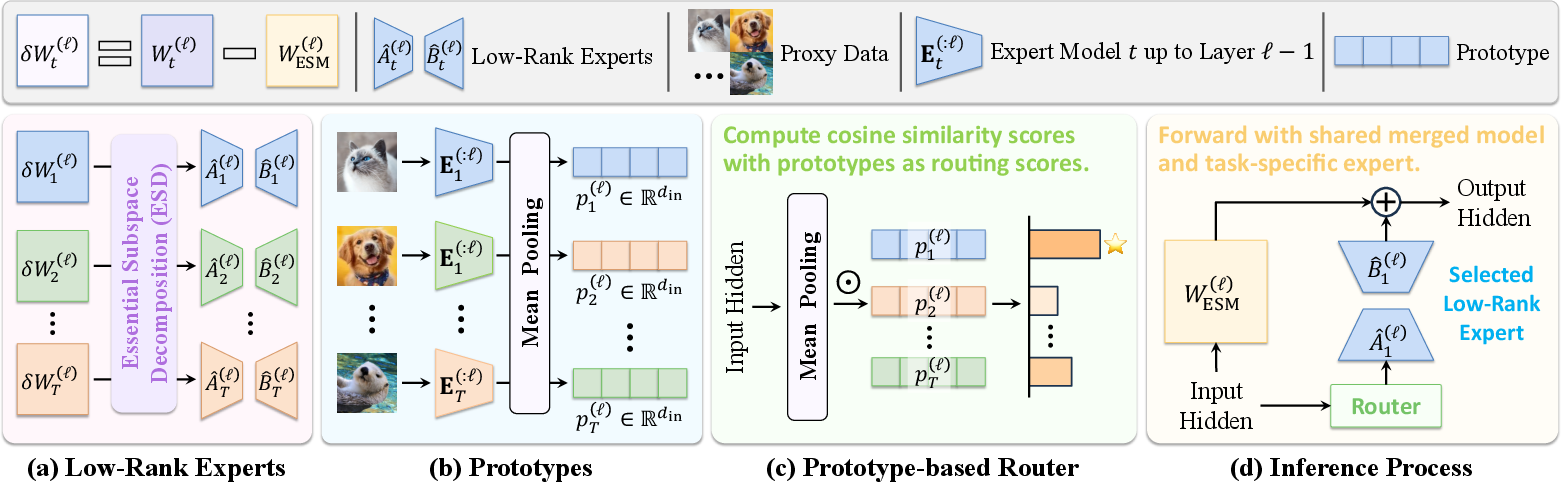
Figure 4: Illustration of ESM++: residuals between expert models and ESM base are decomposed into low-rank experts and routed layer-wise via prototype similarity for inference-time specialization.
Empirical Results and Analysis
Experiments span vision (CLIP ViT models for 8/14/20 tasks), discriminative (GLUE benchmark with RoBERTa), and generative (Llama-3.2-3B with instruction, math, coding, safety, multilingual) domains. ESM consistently achieves best or joint-best static merging scores, outperforming prior SVD/parameter-centric baselines (e.g., Model Soup, Task Arithmetic, TSV-M, Iso-CTS, DC-Merge).
ESM++ yields further improvement, approaching fine-tuned expert upper bounds, especially as the number of merged tasks increases. Accuracy exceeds 98% of fine-tuned levels in many settings, with dynamic routing providing robust task separation and specialization.
Ablations demonstrate robustness to proxy dataset size and composition; a single unlabeled instance suffices for strong performance, and out-of-distribution proxies negligibly degrade accuracy. Eigenvalue-based weighting in orthogonalization (power ≈0.3) boosts results, while routing to more than one expert increases interference, confirming the efficiency and sufficiency of selective expert routing.
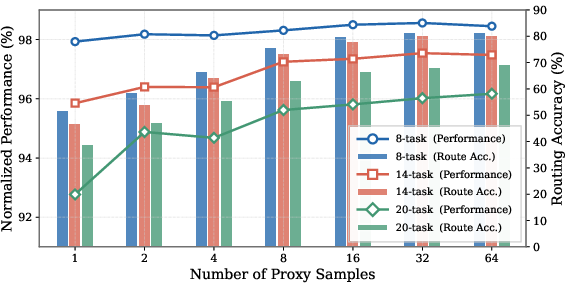
Figure 5: ESM++ performs robustly with minimal proxy samples, maintaining normalized and routing accuracy with few offline features.
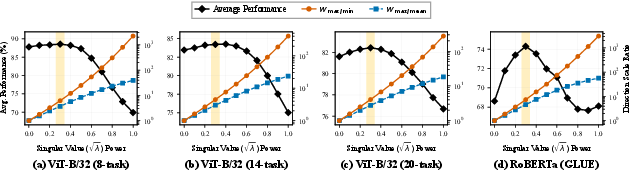
Figure 6: Moderate eigenvalue weighting power ($0.3$) maximizes post-orthogonalization performance.
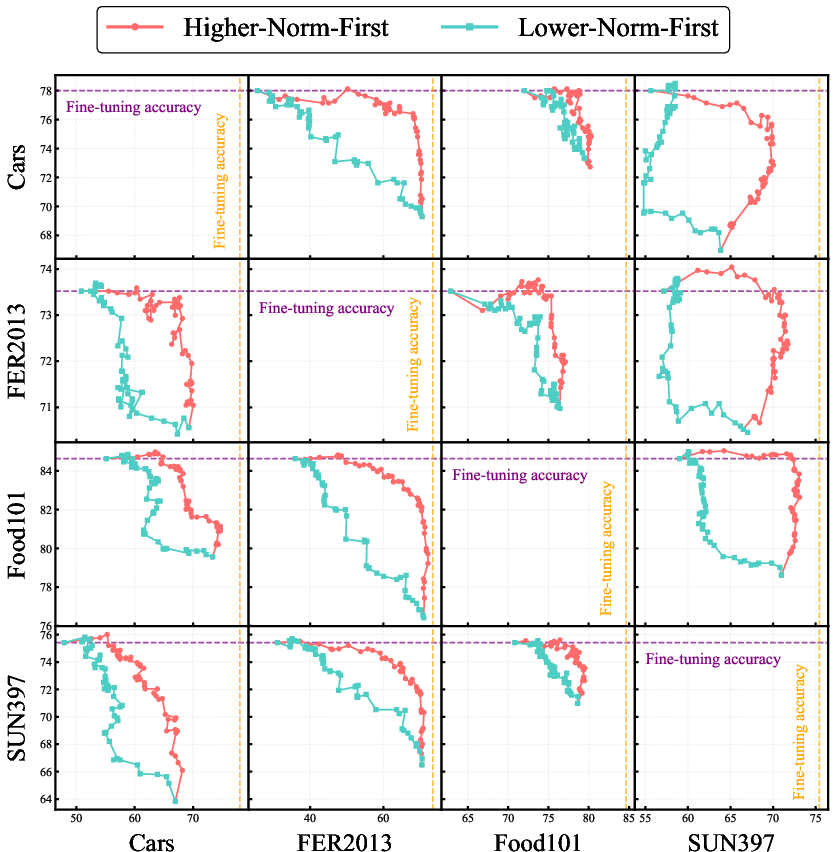

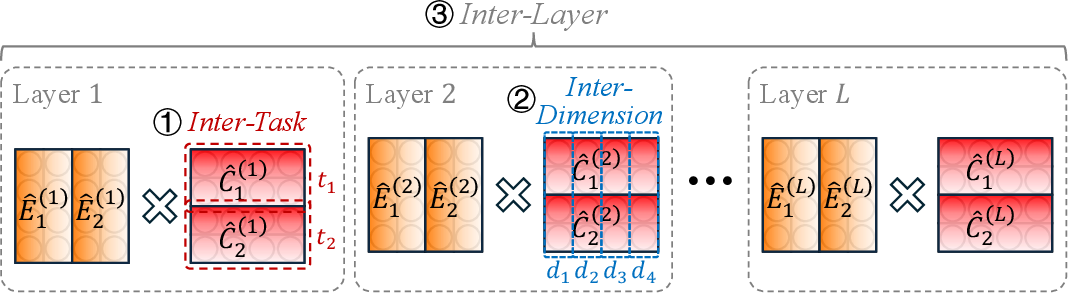
Figure 7: Polarized Scaling—emphasizing high-norm updates and suppressing low-norm ones across layers, tasks, and dimensions—improves average accuracy.
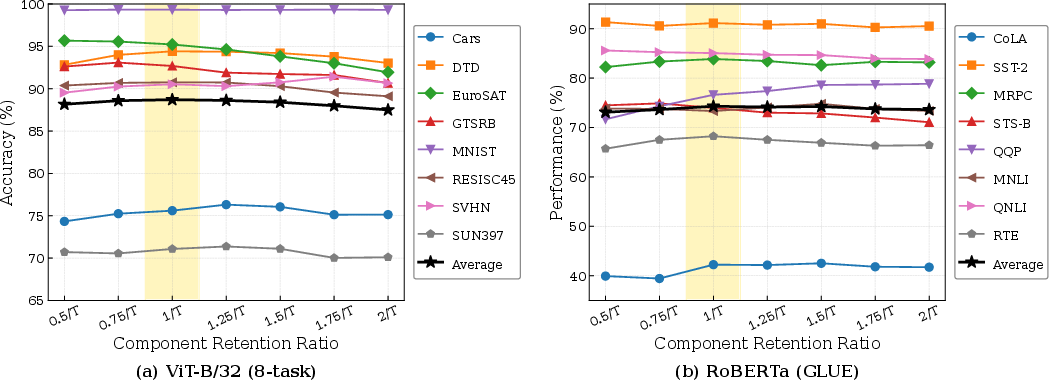
Figure 8: Model performance remains stable across a wide range of retained rank ratios; energy concentration and orthogonalization reduce sensitivity.
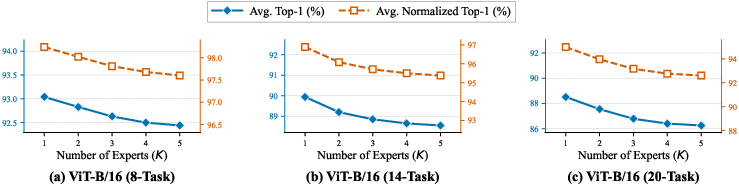
Figure 9: Routing to a single expert maximizes multi-task performance; additional experts introduce interference.
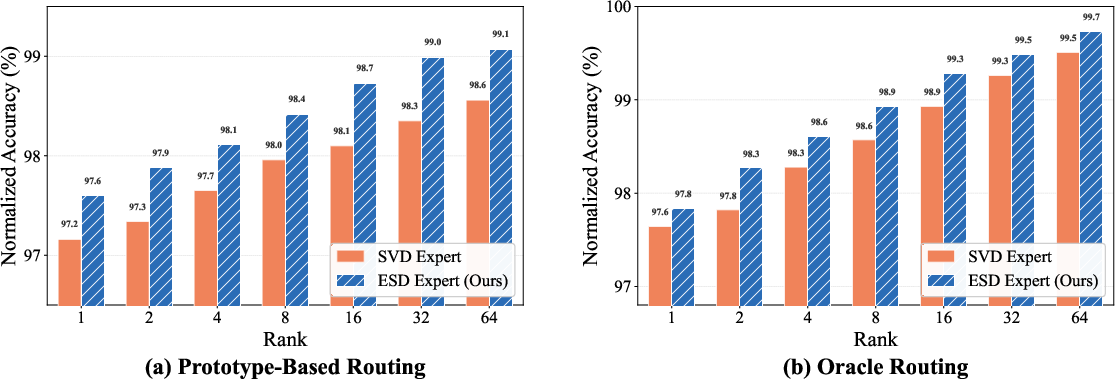
Figure 10: ESD-based expert construction outperforms SVD-based approaches in both prototype and oracle routing setups for all ranks.
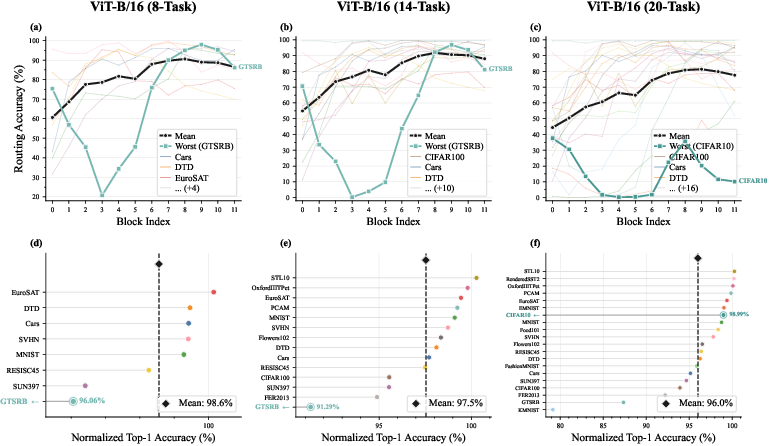
Figure 11: Layer-wise routing accuracy is high; even lowest-performing tasks retain 90%+ normalized performance.
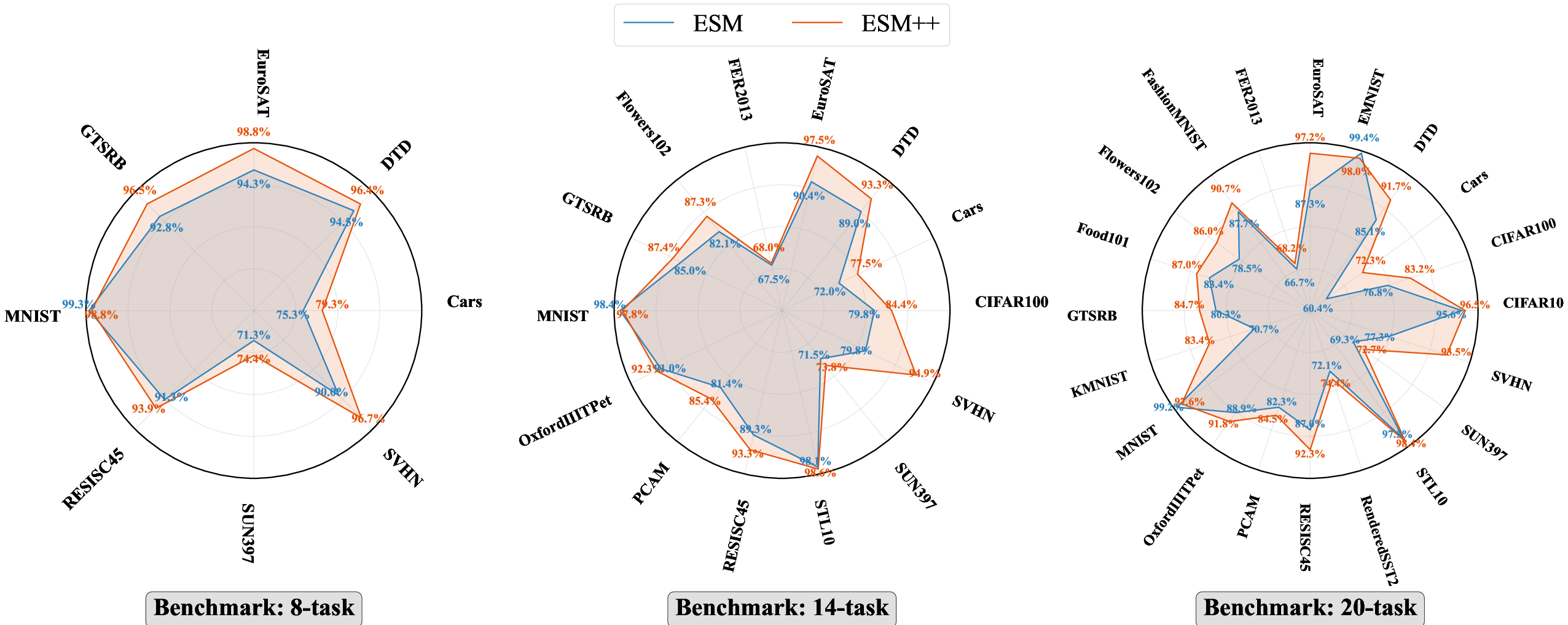
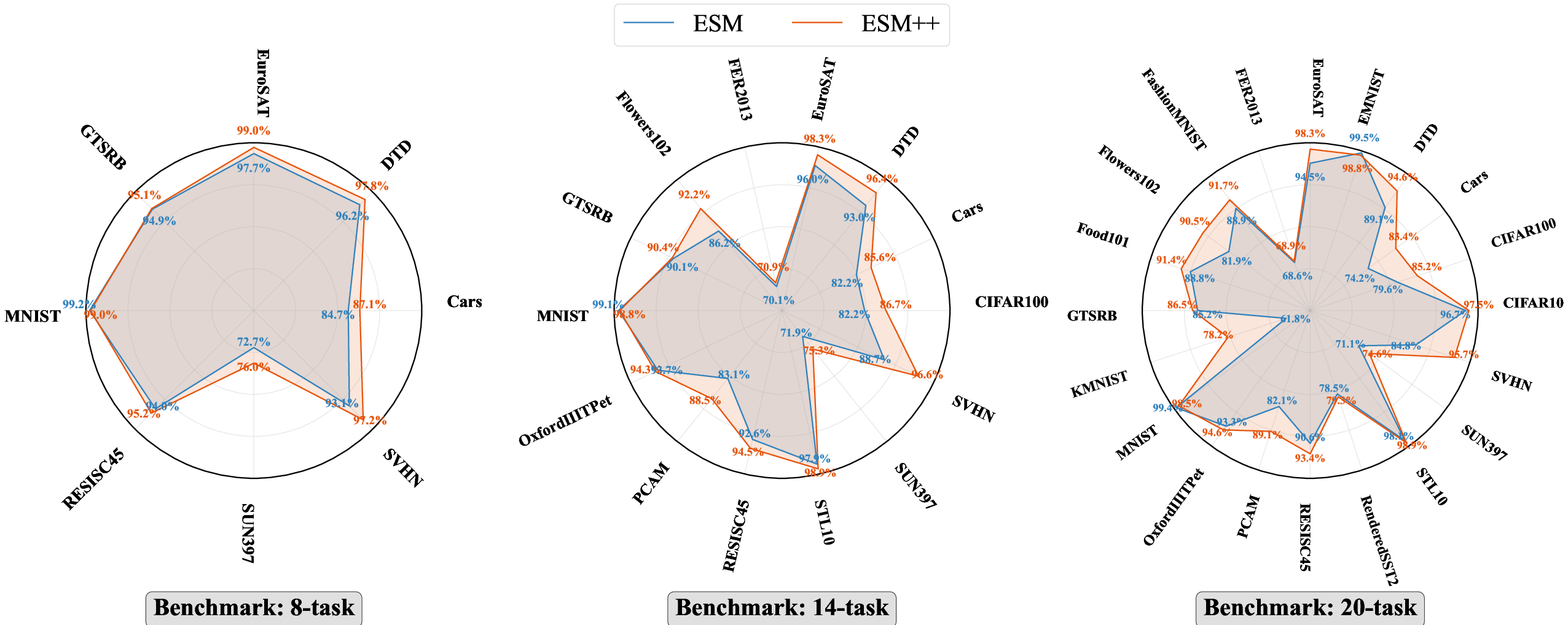
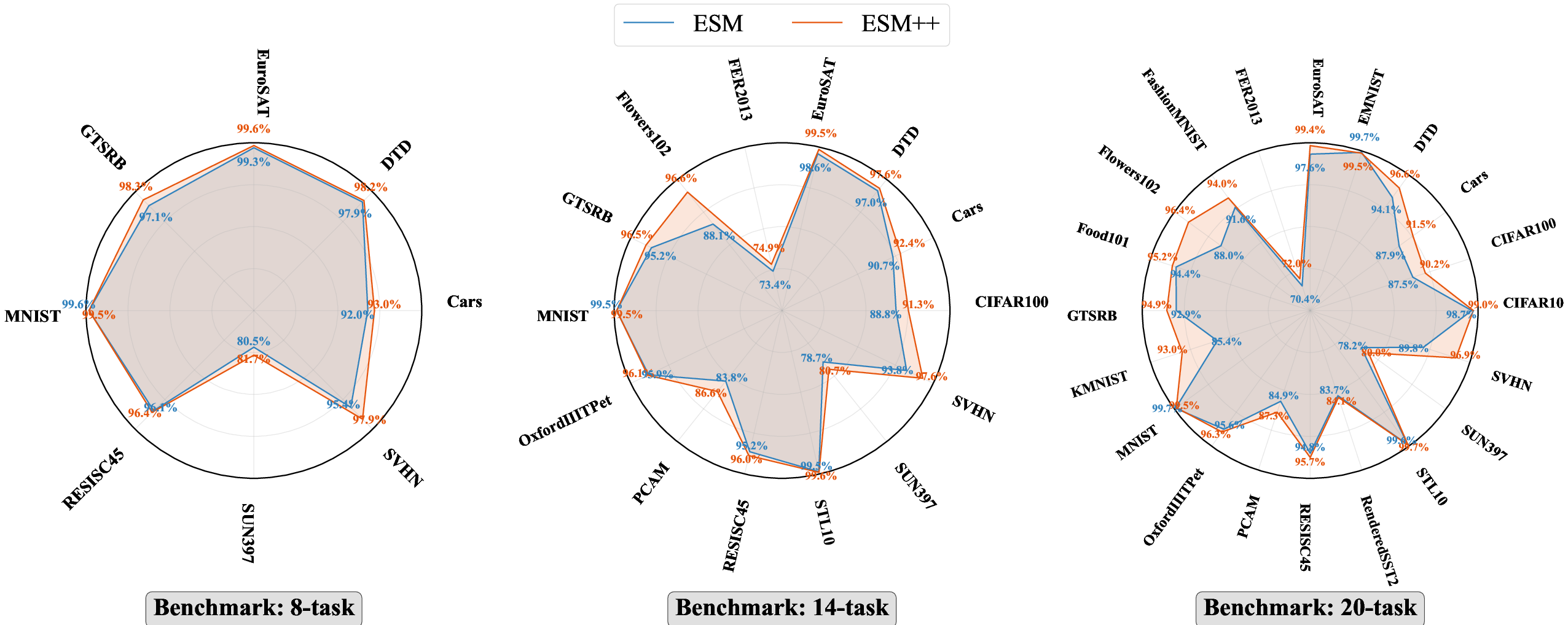
Figure 12: Detailed per-task CLIP merging results across backbones confirm ESM/ESM++ efficiency and reliability, with minimal inter-task performance degradation.
Theoretical and Practical Implications
The essential-subspace perspective advances model merging theory by tightly coupling low-rank truncation to functional preservation, departing from naive parameter-space decompositions. By isolating high-variance output directions, ESM/ESM++ minimize inter-task interference and maximize task fidelity within rank and parameter constraints. The training-free nature, orthogonalization, lightweight routing, and robustness to data scarcity render these methods highly applicable for practical deployments involving multi-task specialization, model updates, or aggregate knowledge transfer.
Computational overhead for ESM++ is trivial, with prototype routers and expert residuals consuming less than 1% of overall model parameters, as opposed to prior routing-based methods that require learning massive routers or engaging in test-time adaptation.
Extension to new scenarios—such as heterogeneous architectures or disparate pre-trained bases—remains a research direction, since the current framework assumes shared architecture and originating checkpoint.
Conclusion
Essential Subspace Merging (ESM) and ESM++ utilize output shift-aware decomposition (ESD) to merge multiple task experts into a single multi-task model with minimal inter-task interference, maximally preserving functional knowledge. Experiments across vision and language domains demonstrate state-of-the-art accuracy, robustness to proxy data, and extreme parameter efficiency, supporting practical multi-task deployment while advancing theoretical understanding of model merging. Extension to heterogeneous and cross-family merges is anticipated as a future frontier.

