Can neurons speak? Semantic narration of vision at single-cell resolution
Abstract: Identifying what individual neurons encode in higher-order visual cortex is an open problem. Responses resist intuitive parameterization, and the deep-network embeddings used in their place are black boxes. Here, we introduce NEURRATOR, a framework that decodes spiking activity into free-form natural-language narration of the viewed scene at single-neuron resolution. A learned encoder maps spike trains from arbitrary subsets of simultaneously-recorded neurons into the patch-embedding space of a frozen CLIP, from which a multimodal LLM and sparse autoencoder generates and validates a description with no language-side training. Applied to Neuropixel recordings of mouse visual cortex during natural-movie viewing, NEURRATOR narrates from thousands of neurons, singular cortical regions, local populations, or from a molecularly-defined cell-types. We use this property to (i) quantify how decoding fidelity scales with population size and cortical region, and (ii) "neurrate", in plain language, what individual neurons and genetically-tagged inhibitory cell-types contribute to visual representation. This recasts cell identity from a classification target into a functional probe of the visual system, providing a new unit of biological insights in neural systems.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
Imagine trying to tell what movie someone is watching just by listening to their brain cells. This paper introduces Neurrator, a system that “listens” to the tiny electrical spikes of brain cells (neurons) in a mouse’s visual cortex and turns that activity into short, natural-language descriptions of what the mouse is seeing. It works at single-neuron resolution and can report what different groups of neurons, or even specific cell types, “care about” in the scene.
What questions are the researchers trying to answer?
The authors focus on simple, big questions:
- Can we translate the activity of individual neurons into clear, plain-language descriptions of what’s on the screen?
- How many neurons do we need before those descriptions become accurate?
- Do different brain regions, or different kinds of neurons, contribute different kinds of information about a scene?
- Can we break down what each group of neurons represents into understandable visual concepts (like “cars,” “shadows,” or “small round objects”)?
How did they do it? (Methods in everyday language)
Here’s the core idea, with analogies to make it easier to picture:
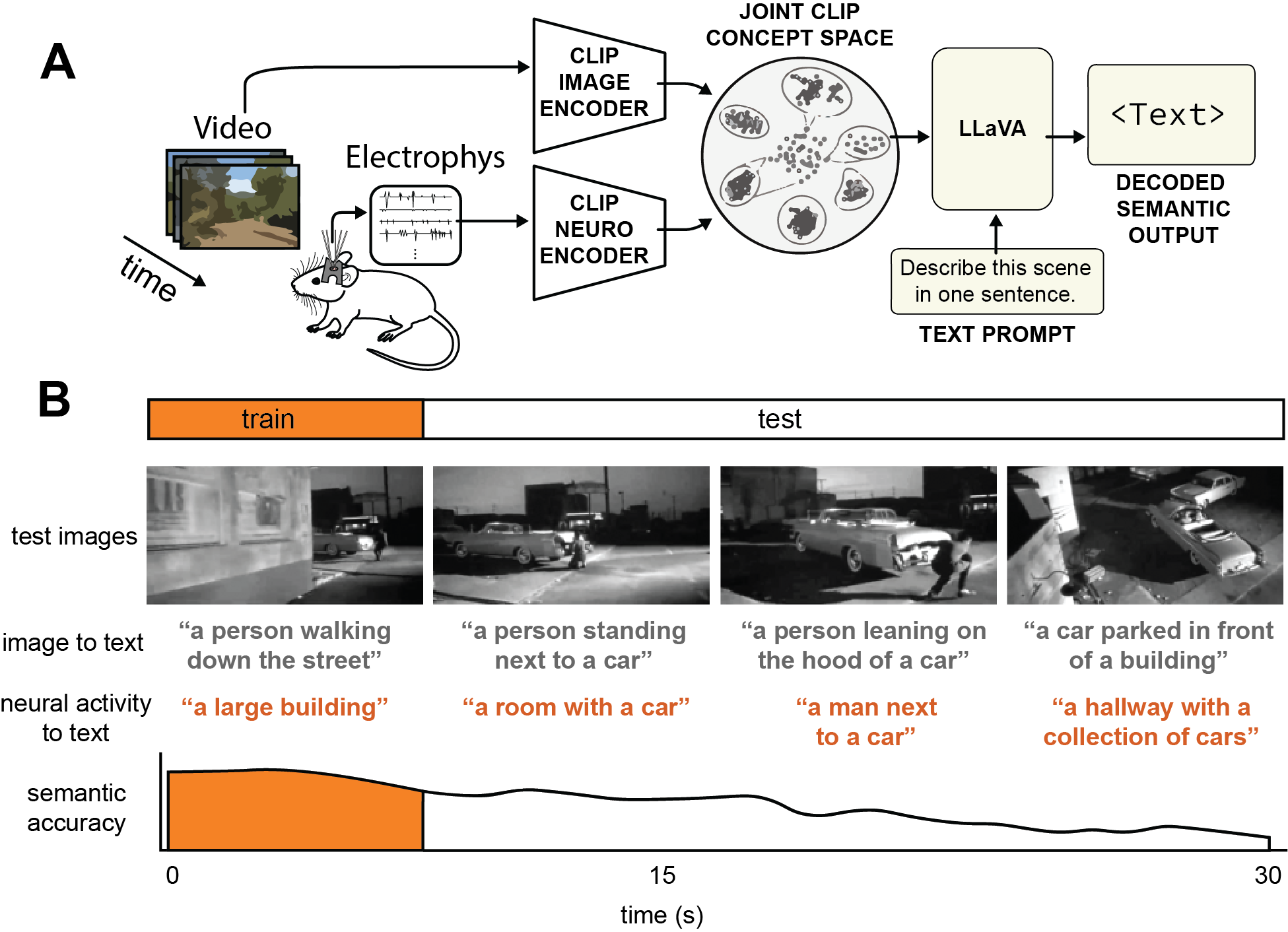
- Recording the brain: Mice watched short natural movies while a tiny, high-tech probe (called Neuropixels) recorded the electrical “spikes” from thousands of neurons in their visual cortex. Think of these spikes as the brain’s Morse code.
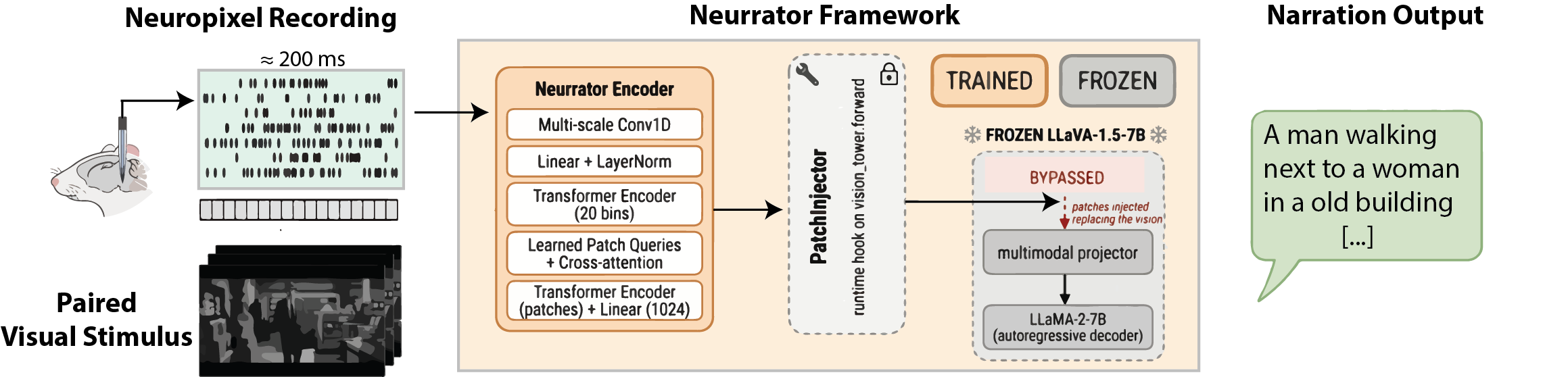
- A smart translator: The team built a translator (a learned encoder) that takes in these spike patterns and tries to guess the same kind of internal picture-features that a powerful image-captioning AI uses. Those features are like a grid of “puzzle pieces” describing different parts of the image.
- Passing the features to a captioner: Instead of showing the captioning AI the real image, they feed it the guessed features produced from the spikes. The captioner (a frozen multimodal LLM, similar in spirit to an AI that turns pictures into sentences) then writes a one-sentence description—now based only on the mouse’s neural activity.
- Why this works: The image captioner understands a special “shared space” where pictures and words line up. The translator learns to drop the neural activity into that space, so the LLM can talk about what the brain saw.
- Understanding concepts: They also used a tool called a sparse autoencoder (think: a “concept finder”) on the same feature space to pull out human-friendly visual concepts (like “car,” “kitten,” or “stage lights”) and measure how strongly different neuron groups signal them.
- Checking quality: They used a sentence-similarity score (SBERT). You can think of it as a “meaning meter” that tells how close two sentences are in meaning. Higher = more similar.
What did they find, and why does it matter?
Here are the main takeaways, explained simply:
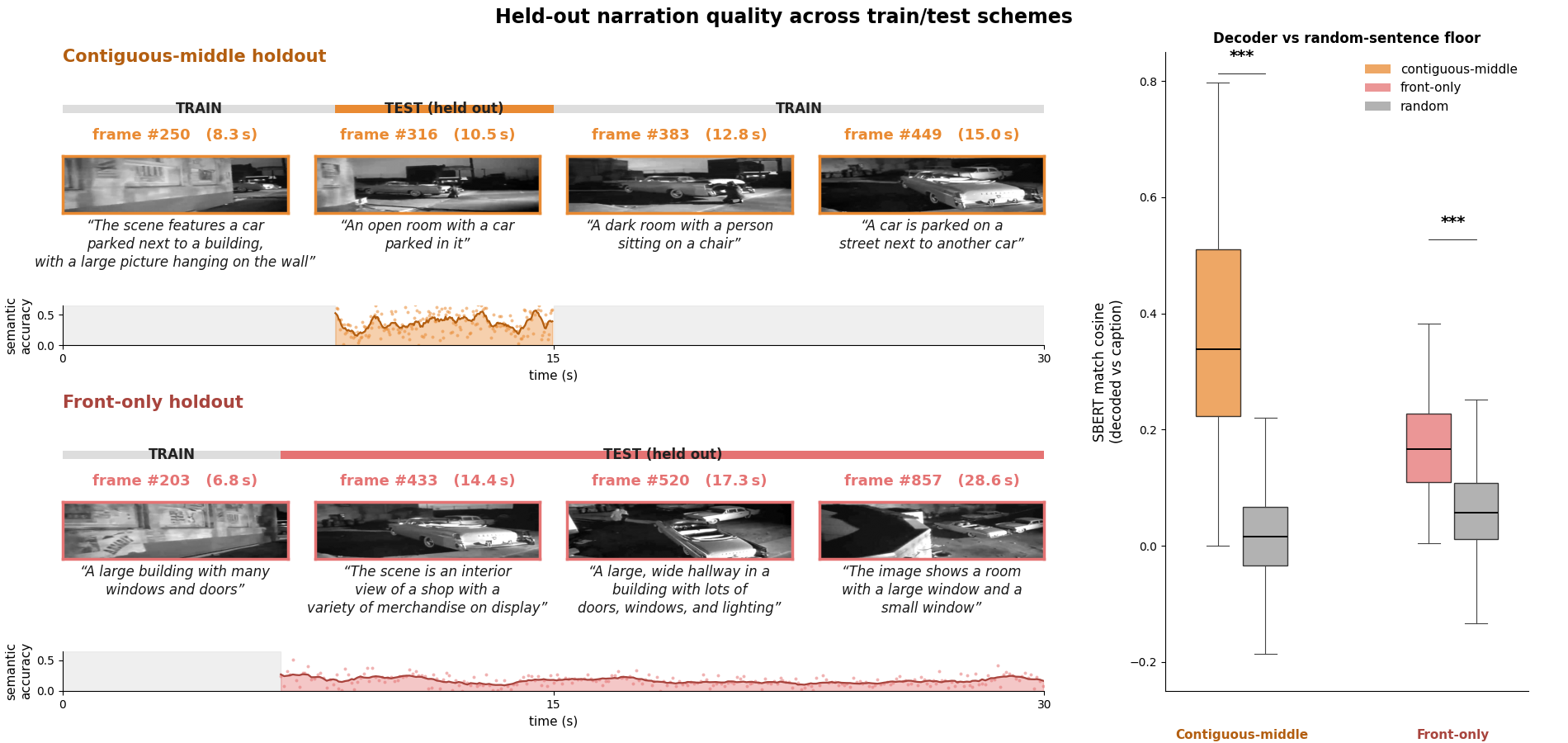
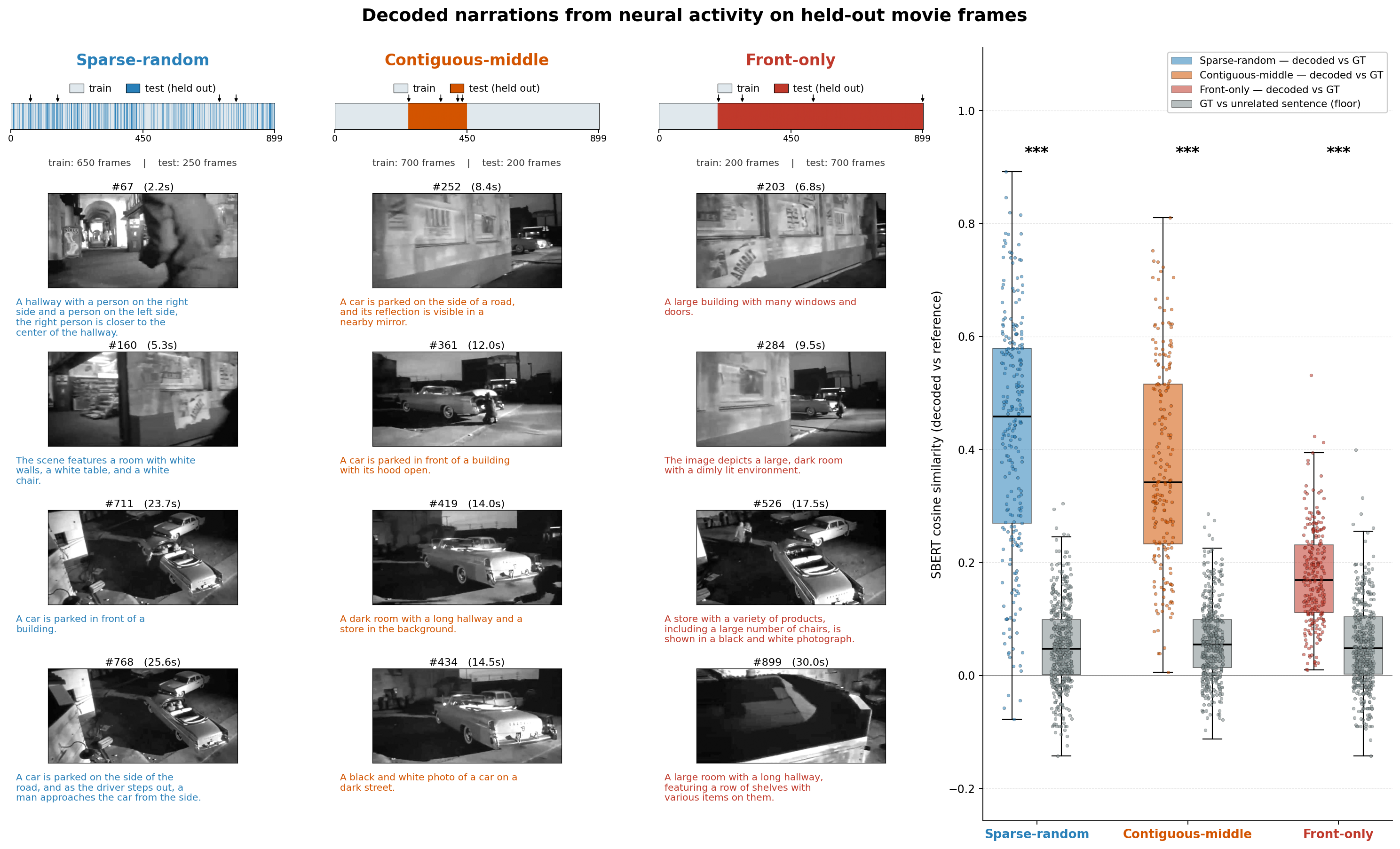
- The system can narrate scenes from spikes alone: Neurrator produced meaningful one-sentence captions that matched what was on the screen—even when tested on parts of the movie it never saw during training, and even on completely new images.
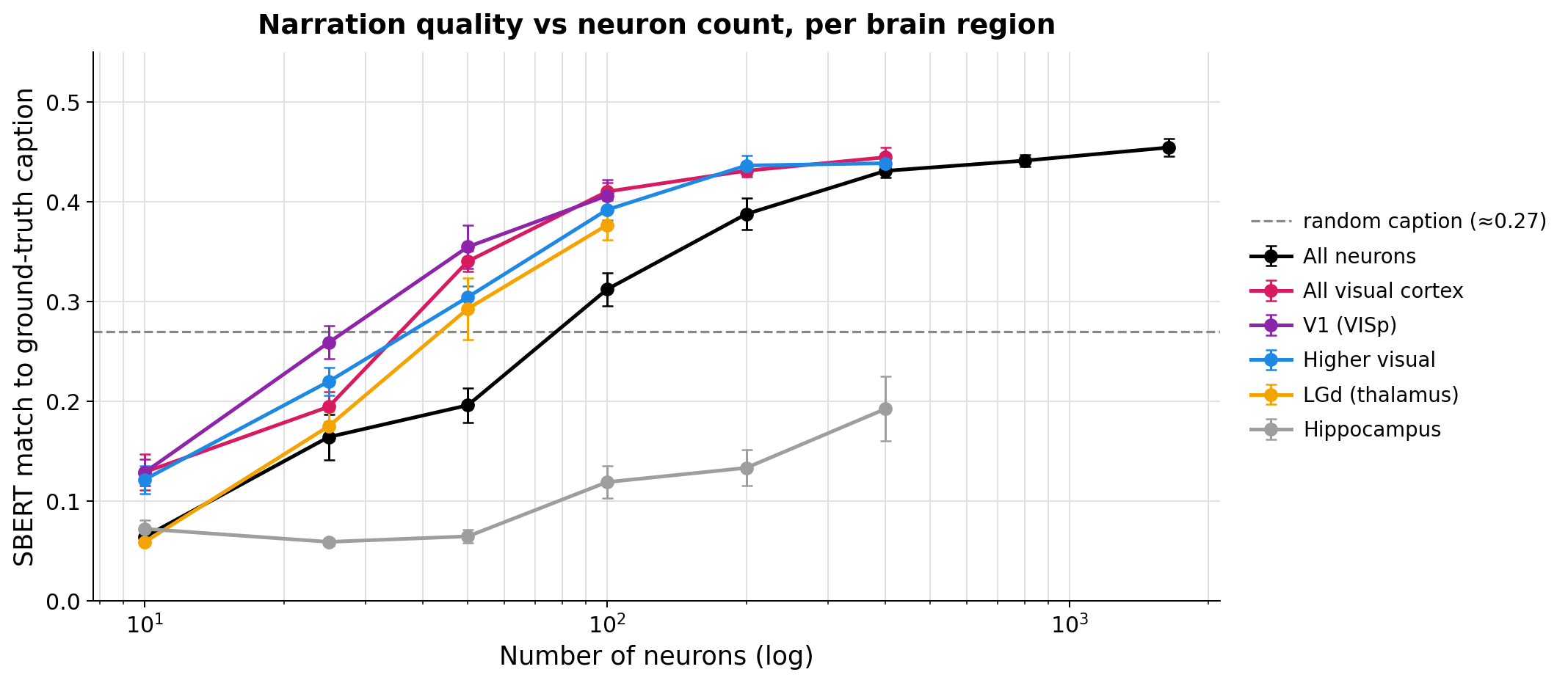
- You need enough visual neurons to “get” the scene: The captions start making sense once you include on the order of tens to about a hundred visually driven neurons. With just a few neurons, the output is basically random.
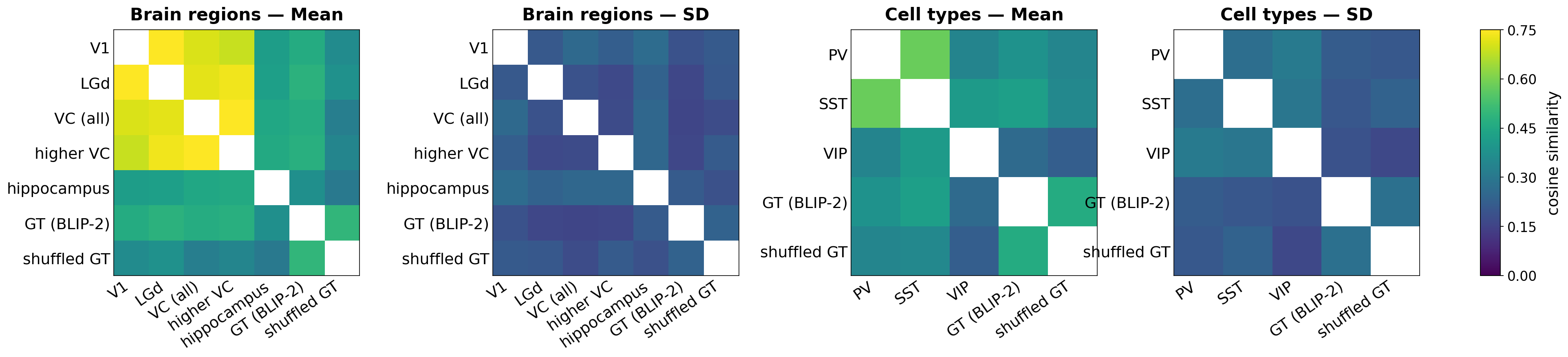
- Brain region differences: Different visual areas (like V1 versus higher visual cortex) produced very similar overall narrations of the same scene—so at this level, region labels alone didn’t strongly separate the “story” they told. A non-visual control (hippocampus) didn’t produce meaningful scene descriptions, which makes sense.
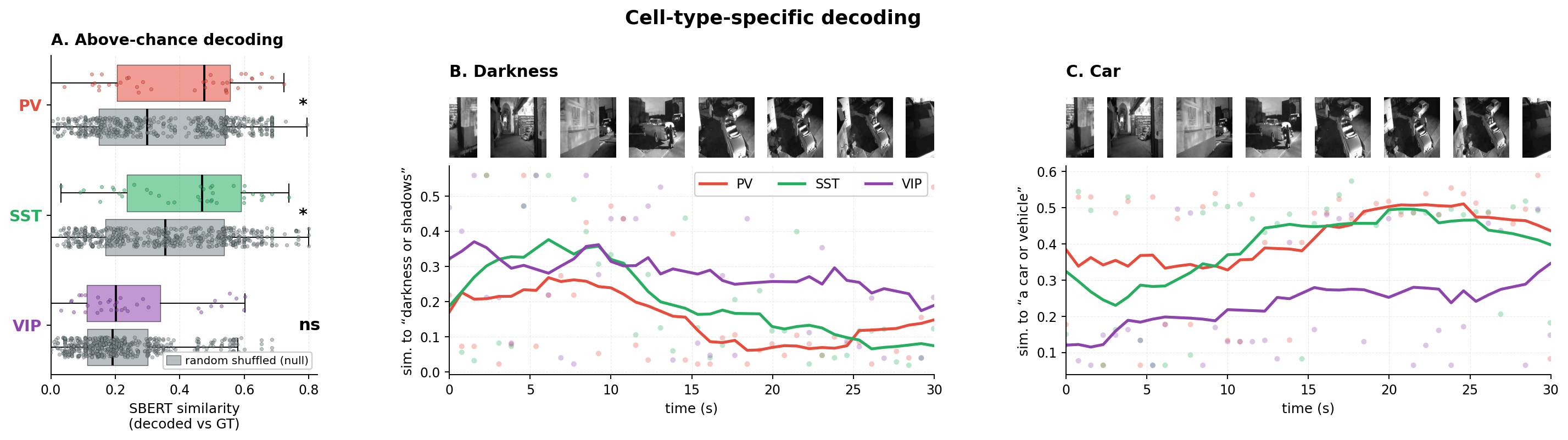
- Cell type differences:
- PV (parvalbumin) and SST (somatostatin) were somewhat similar.
- VIP (vasoactive-intestinal-peptide) often focused more on lighting and shadows—the “mood” or atmosphere of the scene—than on specific objects.
- Concept dictionary (what each group “likes”):
- PV: stronger responses for small, rounded objects (like babies, kittens, teapots).
- SST: stronger responses for vehicles, especially classic/sports cars (which matched the movie’s content).
- VIP: stronger responses for scene lighting and venue-like illumination (bright stages, markets, stadium lights)—more about how the scene is lit than the objects in it.
- These differences were stable across many checks, suggesting they aren’t just flukes.
Why it matters:
- This is the first time single-neuron spikes have been turned directly into free-form sentences about what’s being seen. That opens a new way to ask questions about the brain in plain language.
- It also turns “what type of cell is this?” from just a label into a tool for discovery: now we can ask, “What does this cell type contribute to the visual story?”
What could this change in the future? (Implications)
- A new lens for brain science: Scientists can probe what individual neurons or specific cell types “say” about the world in natural language, and link that to understandable visual concepts. This could speed up discovery by making results easier to interpret.
- Beyond vision: The same idea could help in senses where humans don’t have a good mental map—like smell. Translating neural activity directly into words might help us understand complex, hard-to-define sensations.
- Better brain–AI partnerships: Because the method plugs neural activity into the same space used by modern AI vision–LLMs, it creates a shared translation layer that could be extended to other tasks, species, or behaviors.
- Next steps and limits:
- Today’s results come from mice watching a few specific movies; captions are high-level and not ultra-detailed.
- Cell-type conclusions used pooled data across animals (for enough cells), so within-animal comparisons remain to be tested.
- The “concept finder” was borrowed from a vision–LLM; a future version trained jointly with neural data might reveal brain-specific concepts that everyday image models miss.
In short: Neurrator is like a bilingual interpreter between neuron spikes and human language. It not only narrates what the mouse sees but also helps us understand what different kinds of neurons contribute to that narration, opening a clearer, more intuitive window into how the brain represents the visual world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address:
- Cross-animal generalization: Can a single encoder trained on one cohort decode from entirely new animals’ neurons without retraining? What architectures (e.g., permutation-invariant set encoders, meta-learning) enable subject- and session-agnostic generalization?
- Within-animal validation of cell-type effects: Do the PV/SST/VIP narration differences persist when analyzed within single animals (without pseudo-mouse pooling), controlling for laminar depth, receptive-field coverage, retinotopy, and SNR?
- Behavioral-state confounds: How do running, arousal, pupil size, and reinforcement signals modulate decoded narrations, especially for VIP? Can state variables be incorporated into the encoder to disentangle visual content from state-dependent gain?
- Temporal modeling limits: The 167 ms window may be too short for scene dynamics; can sequence-to-sequence decoders over multi-second horizons improve event/action descriptions and reduce reliance on language priors?
- Eye position and receptive-field mapping: How do eye movements and RF positions influence patch-level predictions? Can neuron-specific spatial and temporal lags be learned to align spikes with CLIP patch tokens more faithfully?
- Single-neuron regime: What is the quantitative semantic fidelity for 1–10 neurons, and which neurons contribute disproportionately? Can neuron-level ablations (and targeted stimulation) map causal influence on specific semantic dimensions?
- Regional specificity under matched coverage: Does the apparent collapse across visual areas persist when populations are matched for receptive-field location, coverage, contrast sensitivity, and firing statistics?
- Latency and window tuning: What are the optimal neuron-specific temporal offsets/filters across areas and cell types, and do these improve semantic accuracy or concept attribution?
- Input normalization choices: How sensitive is decoding to z-scoring (which removes absolute rate information)? Would preserving rate scales or incorporating spike timing (sub-bin precision) improve fidelity?
- Language-model prior bias: To what extent are narrations driven by LLaVA’s prior vs. neural evidence? Can hallucination be quantified via adversarial controls (e.g., patch-noise injection, time-shifted spikes), alternative LMMs, and calibration techniques?
- Evaluation metrics and ground truth: SBERT vs BLIP-2 captions may reflect CLIP/BLIP priors; how do human-annotated captions, multiple metrics (BERTScore, CIDEr, human judgments), and out-of-distribution tests change conclusions?
- Generalization to novel stimuli: Beyond NM3 examples, can decoding be quantified on multiple unseen movies with different statistics (cartoons, high-motion sports, low-light scenes, synthetic videos) and across frame rates and contrasts?
- Data efficiency: How do decoding quality and concept stability scale with number of repeats, training frames, and neurons? What minimal dataset supports semantically grounded narration?
- Patch-level validation: Do predicted patch embeddings retrieve the correct frames/images in CLIP space (top-k retrieval), verifying that patch tensors reflect specific visual content rather than generic caption-triggering signals?
- SAE–embedding compatibility: The SAE used is trained on CLIP B/32 layer-11 while the encoder targets ViT-L/14 patch tokens; what distribution mismatches arise, and does retraining the SAE on the exact predicted embedding stream change the discovered concepts?
- Joint sparse bottleneck: Does jointly training a sparse concept bottleneck with the neural encoder reveal concepts present in neural activity but absent in CLIP/LLaVA priors? How do these differ from off-the-shelf SAE dictionaries?
- Causal validation of concepts: Can closed-loop optogenetic perturbations (PV/SST/VIP) and controlled stimulus manipulations (brightness/contrast/object occlusion) causally alter specific decoded concepts and captions as predicted?
- Stability across stimulus domains: Are cell-type-specific concept dictionaries (e.g., VIP → venue lighting) stable across multiple, diverse movies and image sets, or are they specific to NM1 (cars/noir lighting)?
- Robustness to neuron identity/permutation: How well does the encoder handle arbitrary neuron subsets and re-orderings at inference? Would explicit set-based encoders (DeepSets/Transformers over neurons) strengthen subset generalization?
- Scaling laws and saturation: Does semantic fidelity saturate with thousands of neurons or additional areas? What are the asymptotic gains and bottlenecks (neuron quality vs count)?
- Task and cognition: In active tasks, how do decoded narrations align with latent task variables (attention, choice, expectation)? Can the model dissociate visual content from top-down signals?
- Modality transfer: Can the approach decode semantics in auditory/somatosensory systems and especially olfaction, where stimulus parameterizations are poorly defined? What target embedding spaces work best outside vision?
- Uncertainty estimation: How to quantify and calibrate confidence in decoded captions and concept activations, and implement abstention when neural evidence is insufficient?
- Controlling sampling biases: Do layer distribution, cortical depth, and recording yield differ across PV/SST/VIP datasets, and do such sampling differences (rather than true encoding differences) explain observed narration divergences?
- Fine-grained semantic benchmarks: Beyond single-sentence captions, can models be tested on attributes, relations, and spatial queries (e.g., object count, relative positions) to probe representational granularity?
- Cross-model consistency: Do key findings (e.g., VIP lighting emphasis) reproduce with different CLIP variants and multimodal LMs (e.g., BLIP-2, Qwen-VL, LLaVA-Next), or are they model-specific artifacts?
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented with current datasets, hardware, and the released Neurrator code.
- Academic neuroscience — rapid semantic exploration and hypothesis generation
- What: Use Neurrator to turn mouse Neuropixels recordings into per-trial natural-language captions and concept profiles, enabling fast inspection of what populations encode without manual stimulus curation.
- Tools/workflows: Run the open-source encoder on Allen Brain Observatory (or lab) datasets; generate frame-by-frame captions and sparse-autoencoder (SAE) concept activations; embed in an interactive notebook/dashboard for dataset triage.
- Assumptions/dependencies: Requires high-quality spike sorting, z-scored spike counts, sufficient visually driven neurons (tens to ~100+) for reliable captions; depends on CLIP/LLaVA priors and SAE dictionaries (model biases).
- Academic neuroscience — functional probing by cell type and region
- What: Restrict inputs to optotagged populations (e.g., PV, SST, VIP) or anatomical pools to narrate “what this subset sees” and to compare concept signatures across populations.
- Tools/workflows: Create frame-aligned pseudo-mice across sessions; compute narration similarity and SAE feature rankings per population; use for hypothesis formation and targeted follow-up experiments.
- Assumptions/dependencies: Requires labeled neurons (optotagging or reliable subtype classifiers); limited cell counts per population may require pooling across sessions; inferences are correlational.
- Experimental design — choosing regions, population sizes, and repeats
- What: Use the observed scaling laws (semantic fidelity vs. neuron count/region) to plan recordings (e.g., prioritize V1 for efficiency or mix higher visual areas to increase conceptual diversity) and set minimum neuron counts for semantic decoding.
- Tools/workflows: Power calculations based on SBERT-vs-neuron-count curves; pre-experiment simulations using pilot data; online monitoring of semantic fidelity during acquisition.
- Assumptions/dependencies: Scaling curves are derived from mouse visual cortex under natural movies; generalization to other tasks/modalities may differ.
- Data quality control (QC) and session triage
- What: Quickly identify visually unresponsive sessions/units by comparing decoded narrations to ground-truth image captions (e.g., low SBERT scores signal poor engagement or drift).
- Tools/workflows: Batch evaluation against BLIP-2 (or equivalent) captions; outlier detection / alerts when captions drop to random baseline; hippocampus-like controls.
- Assumptions/dependencies: Needs a caption reference or concept axes for comparison; significant autocorrelation in natural movies should be controlled for as in the paper.
- Interpretability benchmarking for vision–LLMs (VLMs) and SAEs
- What: Use spike-aligned CLIP embeddings and Neurrator outputs to benchmark VLM feature alignment with neural data and to test SAE concept dictionaries against biological signals.
- Tools/workflows: Compare different VLMs (e.g., CLIP variants, SigLIP) or SAE dictionaries; run ablations; quantify semantic alignment and feature sparsity/monosemanticity under neural supervision.
- Assumptions/dependencies: Interpretability conclusions inherit biases of the chosen VLM/SAE; performance depends on embedding compatibility (patch shape, layer selection).
- Preclinical BCI R&D — semantic decoders for animal studies
- What: Prototype “spikes-to-language” pipelines to evaluate whether a neural interface captures high-level semantic information (e.g., visual scene descriptors) during task performance.
- Tools/workflows: Integrate Neurrator-style encoders with animal neurophysiology rigs; monitor semantic readouts as a high-level behavioral/representational metric.
- Assumptions/dependencies: Currently validated in mouse visual cortex; portability to different tasks/species requires retraining; real-time deployment needs low-latency inference.
- Stimulus library annotation and retrieval
- What: Auto-annotate naturalistic stimuli used in lab protocols with captions and concept tags derived from neural responses (not just image content), enabling “neural-salience aware” retrieval.
- Tools/workflows: Index trials by decoded captions and SAE features; implement search over “neurally salient” concepts; integrate with lab LIMS.
- Assumptions/dependencies: Requires consistent alignment of frames and spikes; captions reflect a mixture of neural signal and language prior.
- Educational and outreach tools
- What: Turn spike rasters and frames into “neurons narrating” demos for classes, outreach, and lab training to build intuitions about neural coding and population sampling.
- Tools/workflows: Static or web-based visualizations showing frames, spikes, and per-trial captions; sliders for population size/area/cell type to illustrate scaling.
- Assumptions/dependencies: Didactic use; not a substitute for analysis-grade metrics.
- Cross-lab standardization via a shared embedding target
- What: Map diverse labs’ visual recordings into a common CLIP space to facilitate cross-dataset comparisons and meta-analyses.
- Tools/workflows: Convert spike data to CLIP patches and SAE features; compute dataset-level semantic signatures; share only embeddings for privacy-preserving collaboration.
- Assumptions/dependencies: Embedding comparability depends on using the same CLIP/LLaVA versions and preprocessing; domain shifts require calibration.
- Software tooling integration
- What: Package Neurrator as plug-ins for analysis stacks (e.g., AllenSDK, SpikeInterface) and provide simple APIs to generate captions and concept scores from neural recordings.
- Tools/workflows: CLI/GUI wrappers, batch runners, and visualization widgets; cloud-hosted inference for heavier models.
- Assumptions/dependencies: Model weights/licenses (CLIP/LLaVA) and GPU availability; maintenance to keep pace with model updates.
Long-Term Applications
These opportunities require further research, scaling, or translation to new species/modalities.
- Healthcare (clinical BCI) — semantic communication and perception narration
- What: For patients with severe motor impairment, decode natural-language descriptions from neural activity (ECoG/single units) to support communication or perception reporting.
- Tools/products: “Semantic BCI” systems coupling intracranial recordings to a language decoder via CLIP-like embeddings; clinician dashboards.
- Dependencies: Safe and stable human recordings; robust training on human data; privacy/ethics frameworks; regulatory approval; strong generalization beyond natural movies.
- Assistive vision and sensory substitution
- What: Narrate the visual scene based on residual cortical activity (or implant signals) to aid low-vision users; potentially pair with prosthetic vision devices.
- Tools/products: Wearable or implant-linked narrator that fuses camera input and cortical signals; personalized concept filters (e.g., faces, obstacles).
- Dependencies: Translation to human cortex; real-time, low-latency inference; multimodal fusion; safety and user studies.
- Diagnostic biomarkers for cortical microcircuit function
- What: Use cell-type-distinct concept signatures (e.g., PV/SST/VIP differences) as functional readouts in animal models of neuropsychiatric disorders or for drug-response profiling.
- Tools/products: Preclinical assay kits that measure changes in concept dictionaries under interventions; translational pipelines to noninvasive human proxies (e.g., MEG/fMRI).
- Dependencies: Causal validation linking concept signatures to circuit mechanisms; feasible human proxies for cell-type activity; disease specificity/sensitivity.
- Closed-loop, concept-triggered optogenetic experiments
- What: Detect specific concept activations online and deliver targeted perturbations (e.g., inhibit VIP bursts when “lighting/contrast” concepts spike) to test causal roles.
- Tools/products: Real-time Neurrator/SAE inference pipeline, optogenetic control stack, low-latency hardware.
- Dependencies: Sub-50 ms inference; robust online spike sorting; precise opto hardware; experimental designs separating cause from correlation.
- Drug discovery and pharmacology screens
- What: Use neurally derived concept dictionaries as phenotypic readouts to assess how compounds modulate inhibitory circuitry and sensory representations.
- Tools/products: High-throughput pipelines in rodents mapping drug effects onto semantic/feature-space metrics; compound-ranking dashboards.
- Dependencies: Standardized recording/analysis protocols; sensitivity to subtle pharmacological effects; replication across labs and models.
- Extension to auditory, somatosensory, and especially olfactory systems
- What: Translate non-visual neural activity directly into language, aiding interpretation where human intuitions are weak (e.g., odor space).
- Tools/products: Domain-adapted encoders (audio–language, olfactory–language) with SAE-like concept dictionaries; cross-modal MLLMs.
- Dependencies: Suitable contrastive embedding spaces (e.g., audio–text, odor–text); large, aligned neural datasets; stimulus-control tooling.
- Human neuroscience research — single-unit and micro-ECoG translation
- What: Apply spikes-to-language mapping to human recordings (e.g., epilepsy monitoring) to study high-level representations and their temporal dynamics.
- Tools/products: Research-grade decoders integrated into hospital research workflows; privacy-preserving data pipelines.
- Dependencies: Access to datasets with naturalistic stimuli; regulatory and consent frameworks; domain adaptation to human cortex and tasks.
- Robotics and neuromorphic engineering — explainable spiking sensors
- What: Map neuromorphic camera spikes to CLIP-like embeddings for natural-language explanations of sensor input (“what the event camera sees”).
- Tools/products: On-device spiking-to-language modules; debugging/telemetry tools for autonomous systems.
- Dependencies: Domain-adapted training data; edge deployment constraints (compute, latency); safety testing.
- Safer foundation models — brain-aligned evaluation and training signals
- What: Use neural alignment metrics and concept dictionaries as auxiliary objectives or eval benchmarks for VLMs to encourage human- and brain-like representations.
- Tools/products: Benchmarks and leaderboards for brain alignment; training curricula that regularize toward neurally grounded features.
- Dependencies: Stable, diverse neural benchmarks; careful handling to avoid overfitting to limited datasets; clarity on what “alignment” implies.
- Personalized neuro-monitoring and rehabilitation
- What: Track longitudinal changes in semantic representations during recovery (e.g., post-stroke visual cortex plasticity) or training.
- Tools/products: Patient-specific dashboards showing concept trajectories; therapy feedback loops.
- Dependencies: Feasible, safe longitudinal recordings; validated clinical endpoints; robustness to day-to-day variability.
- Standards, governance, and neuroprivacy policy
- What: Develop guidelines for collection, storage, and use of semantic brain decoders; audits for language bias and hallucination risks in neural-to-text systems.
- Tools/products: Policy frameworks, audit toolkits, and disclosure standards for neural decoders.
- Dependencies: Multi-stakeholder consensus; integration with broader AI governance; empirical evidence on misuse/risks.
- Jointly learned sparse bottlenecks to discover new concepts
- What: Train the encoder and a sparse concept layer end-to-end to surface features present in neural activity but absent from current VLMs.
- Tools/products: Next-gen “neuro-discovery” models and concept libraries; tools to propose and validate neural concepts experimentally.
- Dependencies: Larger datasets, better regularization, and rigorous validation pipelines; careful separation of biological signal from model artifacts.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient update in Adam to improve generalization. "We optimize with AdamW (lr , weight decay ), a cosine learning-rate schedule, and gradient clipping at $1.0$."
- ALIGN: A contrastive vision-LLM that aligns images and texts in a shared embedding space. "Models such as CLIP, ALIGN, and SigLIP learn a joint embedding in which images and their natural-language descriptions occupy nearby points"
- Attention-weighted temporal pooling: A pooling mechanism that aggregates temporal features by weighting time steps via attention. "attention-weighted temporal pooling"
- BLIP-2: A multimodal model that takes image features and generates text (e.g., captions). "mean SBERT cosine between decoded and BLIP-2 reference captions"
- Bootstrap resampling: A statistical method that assesses stability by repeatedly resampling data with replacement. "under bootstrap resampling"
- CLIP: A contrastive language-image pretraining model mapping images and texts into a joint embedding space. "with CLIP ViT as the target embedding space"
- Contrastive vision-LLMs: Models trained to bring paired images and texts close in embedding space while pushing mismatches apart. "Contrastive vision-LLMs offer a way past this bottleneck."
- Conv1D: One-dimensional convolutional layers used to process temporal sequences like spike trains. "via multi-scale Conv1D layers, transformer encoders, and learned patch queries with cross-attention."
- Cosine learning-rate schedule: A learning rate annealing strategy that follows a cosine curve over training. "a cosine learning-rate schedule"
- Cre line: A genetically defined mouse line expressing Cre recombinase to target specific cell types. "each Cre line yields only a few tens of optotagged units per session"
- Cross-attention: An attention mechanism where queries attend to another sequence’s representations. "learned patch queries with cross-attention."
- Disinhibitory cortical gain control: A circuit motif where inhibition of inhibitory neurons increases excitability, modulating cortical gain. "mediators of disinhibitory cortical gain control recruited by behavioral state and reinforcement signals"
- fMRI BOLD: Functional MRI measure of blood-oxygen-level dependent signal reflecting neural activity. "predict fMRI BOLD responses"
- Forward hook: A runtime function that intercepts and modifies intermediate activations in a neural network. "returned as the penultimate-layer hidden states of LLaVA's vision tower through a forward hook."
- Gradient clipping: A technique limiting the norm of gradients to stabilize training. "gradient clipping at $1.0$"
- Greedy decoding: A decoding strategy that selects the highest-probability token at each step without sampling. "runs in its default greedy-decoding configuration"
- Hippocampus: A brain region involved in memory; used here as a non-visual control for decoding. "Hippocampus, included as a non-visual control, never crosses the random-caption line"
- LGd: The dorsal lateral geniculate nucleus, a thalamic relay for visual information. "LGd, and the union of visual cortex"
- LLaMA-2-7B: A 7-billion-parameter LLM used as the text decoder. "the LLaMA-2-7B decoder"
- LLaVA: A multimodal LLM (Large Language and Vision Assistant) that generates text from vision features. "a frozen LLaVA then decodes the predicted embedding into a free-form description"
- Local field potentials: Aggregate low-frequency electrical signals recorded from neural tissue. "such as calcium imaging or local field potentials"
- Neuropixels: High-density electrophysiology probes for recording spikes from many neurons simultaneously. "Neuropixels recordings of mouse visual cortex"
- Optotagging: Identifying genetically defined neurons via optogenetic activation during recording. "optotagging tables"
- Pareto front: The trade-off curve between competing objectives; here, predictive power vs. interpretability. "The tension between modeling for raw predictive power vs. interpretability defines a Pareto front for decoding neural activity"
- Patch embeddings: Vector representations corresponding to image patches in a Vision Transformer. "The encoder's output is a patch-embedding tensor"
- PatchInjector: A module that replaces a model’s vision features with predicted patches at runtime. "A PatchInjector hooks into the frozen LLaVA model at runtime, replacing the output of its vision tower with the predicted patches."
- Penultimate-layer hidden states: Activations from the layer immediately before the final output layer. "penultimate-layer hidden states"
- Prisma-Multimodal SAE: A specific pretrained sparse autoencoder used to interpret CLIP activations. "We use the Prisma-Multimodal SAE pretrained on the CLIP\,B/32 layer-11 residual stream"
- Pseudo-mouse: A virtual population constructed by concatenating neurons across sessions/animals aligned by stimulus frames. "frame-aligned ``pseudo-mouse'' per genotype"
- PV interneurons: Parvalbumin-expressing inhibitory cortical interneurons. "PV cells uniquely emphasise features for small rounded objects"
- SBERT: Sentence-BERT, a model producing sentence embeddings used to score semantic similarity. "We use Sentence-BERT (SBERT) as a metric"
- Shuffled-pairing control: An evaluation control that pairs decoded outputs with mismatched ground-truth captions to form a null baseline. "shuffled-pairing control (decoded sentences paired with a random other held-out caption)"
- SigLIP: A CLIP-like model trained with a sigmoid loss for vision-language alignment. "CLIP, ALIGN, and SigLIP learn a joint embedding"
- Sparse autoencoder (SAE): An autoencoder with sparsity constraints that decomposes activations into interpretable, sparse features. "Sparse autoencoders (SAEs) decompose dense embedding activations into a dictionary of sparsely-activating, interpretable feature directions"
- SST interneurons: Somatostatin-expressing inhibitory cortical interneurons. "PV, SST, and VIP interneurons"
- Transformer encoder: A neural network architecture using self-attention to process sequences. "transformer encoders"
- ViT-L/14: A Vision Transformer variant (Large, 14-pixel patches) used as CLIP’s vision backbone. "CLIP ViT-L/14"
- VIP interneurons: Vasoactive intestinal peptide-expressing inhibitory cortical interneurons. "VIP cells emphasise something object-orthogonal: venue lighting and atmosphere"
- Wilcoxon signed-rank: A nonparametric statistical test for paired comparisons. "Wilcoxon signed-rank, "
- z-scored: Standardized by subtracting the mean and dividing by the standard deviation. "z-scored per neuron"
Collections
Sign up for free to add this paper to one or more collections.