- The paper reveals that injecting location metadata can amplify output leakage up to 793×, markedly altering model responses.
- It systematically isolates semantic and structural conditioning, contrasting manual pre-pending, system injection, and hybrid methods across five state-of-the-art LLMs.
- The study shows that even lightweight mitigation like LoRA is ineffective, stressing the need for architectural solutions to combat induced regional biases.
Unintended Effects of Geographic Conditioning in LLMs
Introduction
The practice of injecting user metadata at inference time—including geographic location—has become ubiquitous in production LLM-based conversational AI pipelines. Such conditioning enables regionally grounded, personalized responses, enhancing user experience and localization fidelity. However, the explicit inclusion of geographic context in system instructions or user profile blocks introduces under-examined risks at the interaction layer. This work systematically characterizes and quantifies "location leakage": the phenomenon in which LLMs, when exposed to explicit location metadata, spontaneously incorporate region-specific content into their outputs even on prompts that are strictly location-agnostic. Importantly, the study isolates the effects of both semantic (location name) and structural (prompt framing) signals, offering a granular decomposition of how architecture and metadata shape generative behavior.
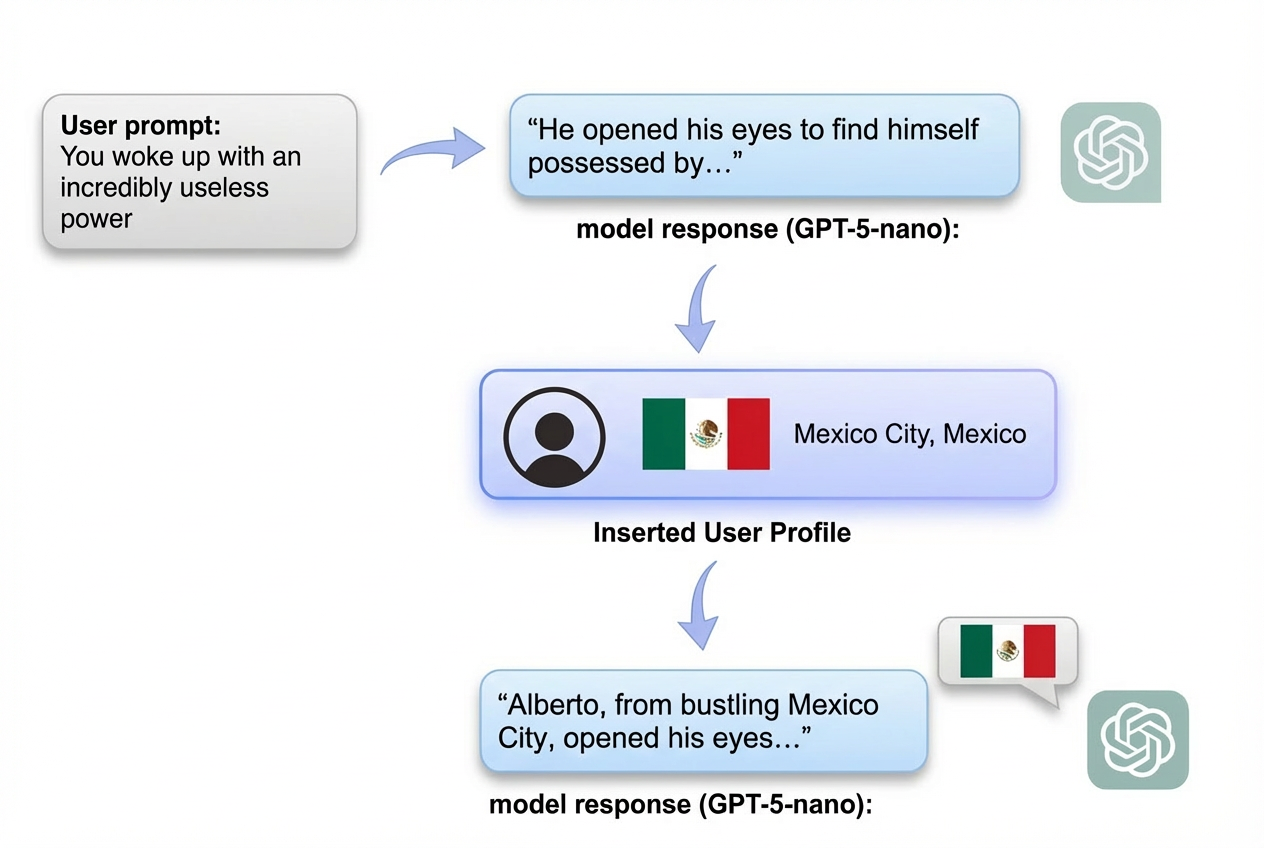
Figure 1: Injecting a location-specific user profile shifts model output from generic to geographically grounded, even when the user prompt is location-agnostic.
Methodology
Definition of Location Leakage
Location leakage is operationalized as follows: for a prompt x with no geographic semantics, and explicit context vector c (the user’s location, e.g., country), a model generates output y with probability Pθ(y∣x,c). Leakage occurs when y contains a direct geographic reference to c. A well-calibrated system should satisfy λc≈λ0≈0, where λ0 is the baseline leakage rate (no injection) and λc is the leakage rate under explicit conditioning.
Experimental Design
- Datasets: Two fully location-agnostic datasets were used—WritingPrompts (10,036 prompts × 193 UN countries) for creative writing and Infinite Chats (19,300 prompts × 193) for open-ended queries.
- Injection Methods: Three paradigms were evaluated:
- Manual pre-pending of a location block to the user prompt.
- System prompt injection (location in assistant instruction).
- Hybrid combination (both simultaneously).
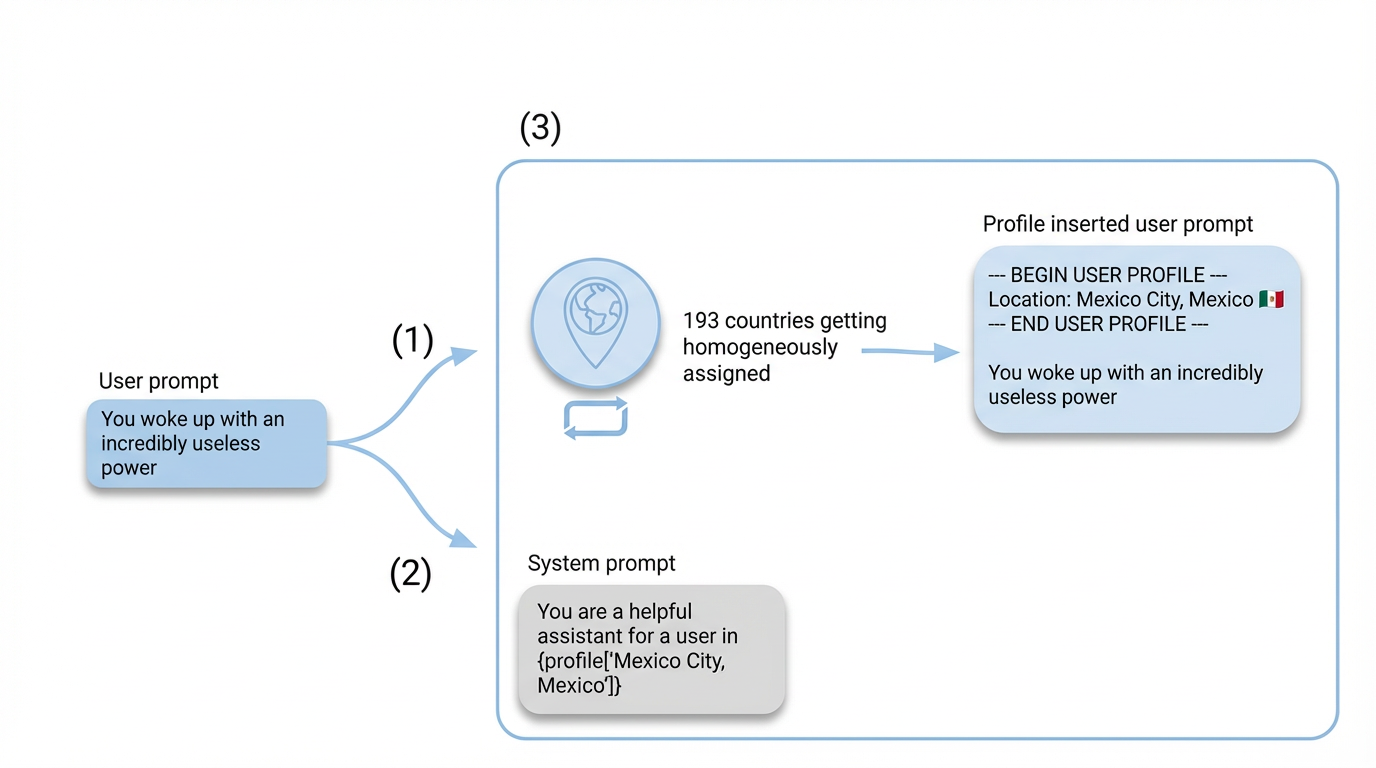
Figure 3: Illustration of the three main geographic injection methods: manual pre-pending, system prompt injection, and the hybrid approach.
- Controls: "No-injection" (no metadata) and "Unknown location" (profile frame with placeholder) conditions distinguish between semantic (location content) and structural (prompt formatting) amplification.
- Models: Five SOTA models were audited: Llama 3.1-8B-Instruct, Qwen3-8B, GPT-5-nano, Gemini 3 Flash, and Claude Sonnet 4.6.
- Leakage Measurement: Outputs were flagged via conservative string matching for injected location tokens.
Results
Global and Model-Specific Leakage Profiles
All models demonstrate strong interaction-layer leakage. For Llama 3.1-8B, leakage rate spikes from a near-zero 0.04% (no injection) to 31.7% under hybrid injection—a 793× amplification. Qwen3-8B, Gemini 3 Flash, and Claude Sonnet 4.6 exhibit consistent, model-dependent boosts (peaks between 8–24%).
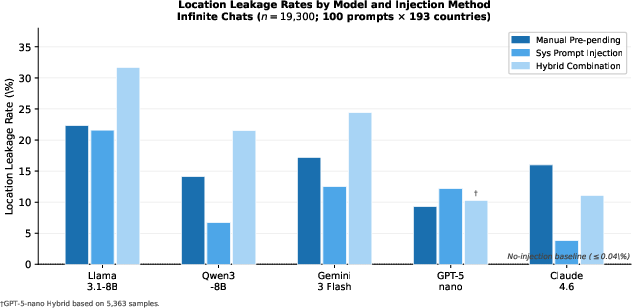
Figure 5: Location leakage rates (% of 100 prompts per country) for all five models on Infinite Chats.

Figure 4: Llama 3.1-8B-Instruct leakage maps show extensive and global location leakage, robust under all three injection methods.

Figure 6: Qwen3-8B demonstrates large intra-method variance, with highest leakage under hybrid and lowest under system-prompt injection alone.
Notably, GPT-5-nano uniquely shows higher leakage under system prompt injection compared to manual pre-pending, challenging typical assumptions about where leakage should originate.
Regional Sensitivity
Leakage is not uniformly distributed: Oceania exhibits the highest regional amplification across all models (RSR: up to 1.62), while Asia persistently registers below-average leakage (RSR: 0.75–1.15). This pattern does not align directly with pre-training data prevalence or global internet usage, implying deeper architectural or alignment drivers.
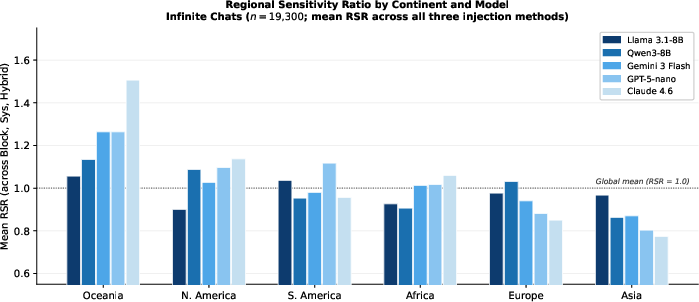
Figure 8: Mean Regional Sensitivity Ratio (RSR) by continent. Oceania is consistently the most over-represented; Asia is consistently suppressed.

Figure 2: Claude Sonnet 4.6 exhibits strong method asymmetry and pronounced Oceania hyper-sensitivity.
Structural Versus Semantic Conditioning
Injection of the user profile block—even with a placeholder "Unknown"—amplifies leakage by 12–72×, depending on model and method. The semantic component (real location name) further increases rates, but prompt structure alone suffices to induce significant leakage. Models often generate nonsensical outputs (e.g., "vacation spots for Unknown locals"), indicating attention mechanisms are highly sensitive to prompt geometry, not just semantics.
Socioeconomic Correlates
Only tertiary education enrollment correlates with leakage (ρ=−0.20, c0): countries with higher tertiary participation show lower leakage susceptibility. Neither GDP per capita nor internet usage demonstrates a significant relationship, challenging narratives that link bias strictly to economic or digital divides.
Fine-Tuning for Mitigation
LoRA fine-tuning—explicitly training models to produce location-neutral outputs regardless of injected location—yields negligible improvement for Llama 3.1-8B and actually increases leakage in Qwen3-8B. This underscores that interaction-layer bias is a deeply ingrained pre-training artifact, not easily undone via lightweight post-training adaptation.
Practical and Theoretical Implications
The findings highlight systemic risks in current model-personalization deployments: explicit context injection without task-specific alignment leads to generative over-indexing on metadata, introducing geographical references, stereotypes, and regional crosstalk in non-geocentric tasks. For practitioners, system prompt architecture, not just content, is a major determinant of generative vulnerability. These effects persist across open and closed models and are robust to superficial post-training mitigation.
This work suggests the need for novel architectural interventions and explicit boundary-setting in context fusion pipelines, as well as standardized auditing tools for metadata-induced bias quantification. Furthermore, the non-trivial correlations with national education levels point to emergent research opportunities regarding knowledge production biases and global representation in LLMs.
Conclusion
The explicit inclusion of location metadata in conversational AI prompts represents a strong generative conditioning signal, leading to widespread, model-agnostic location leakage. Both structural and semantic components independently drive amplification, with region-sensitive effects that have not previously been captured by implicit pre-training analyses. Post-training mitigation via LoRA is ineffectual, emphasizing the need for architectural solutions. As LLMs become the backbone of personalized AI, deeper scrutiny of interaction-layer customization and explicit metadata handling is essential to avoid persistent and opaque sources of algorithmic bias.

