- The paper introduces LocQA as a diagnostic benchmark with 2,156 locale-ambiguous questions across 12 languages to reveal both US-centric and regional biases in LLMs.
- It demonstrates that instruction tuning amplifies US-centric bias while reducing intra-lingual disparities through a logarithmic population-scaling mechanism.
- Empirical findings show that even with explicit locale prompts, state-of-the-art LLMs tend to default to US norms, emphasizing the need for design adjustments for global fairness.
Quantifying Implicit Localization Biases in Multilingual LLMs
Introduction and Motivation
"Location Not Found: Exposing Implicit Local and Global Biases in Multilingual LLMs" (2604.19292) systematically investigates the implicit geographic priors embedded in contemporary multilingual LLMs. Despite recent advancements in cross-lingual fluency, LLMs lack consistent mechanisms to ground factual responses in locale-appropriate contexts when confronted with ambiguities unresolvable from language choice alone. The paper distinguishes between two critical capability axes—linguistic fluency and factual localization—demonstrating empirically that multilingual generation does not ensure equitable, contextually accurate cultural representation.
The core contribution is LocQA: a diagnostic benchmark collecting 2,156 locale-ambiguous questions in 12 languages mapped to 49 regions. LocQA probes model responses when no explicit locale cue is present, thereby surfacing unprompted selection biases. The dual focus is: (1) Global Bias (the tendency to over-produce US-centric answers), and (2) Regional Bias (preferential representation of certain locales within a language cluster, commonly mapped to population size).
The LocQA Benchmark Design
LocQA is designed to elicit model priors through locale-sensitive yet context-underspecified queries. Questions (e.g., "What is the emergency phone number?", "When does the tax year end?") inherently admit distinct correct answers across locales, even within the same language, with no explicit disambiguation. For each question, multilingual human annotators supplied the full set of correct answers for all locales where the language is in major use, using careful protocols to avoid unintended de facto locale cues.
Model responses to LocQA thus act as a window into the implicit heuristics used for factual completion under ambiguity. This approach avoids confounds of explicit cues or forced-choice designs that mask selection propensities, as in previous benchmarks.
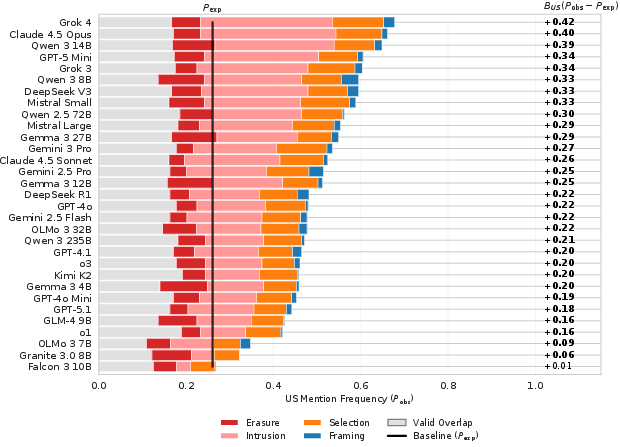
Figure 1: Global Bias scores across models (BUS quantifies excess US answer frequency over baseline locale overlap).
Dual-Metric Framework for Measuring Bias
- Global Bias (BUS): The metric quantifies the overgeneration of US-specific answers above what is expected by coincidental overlap between US and target locale answers. The collision-aware formulation ensures the metric is not inflated by cases where different locales happen to share the same factual reality for a question.
- Regional Bias (BR): This measures intra-lingual representation skews, contrasting the empirical frequency that each locale’s answer appears in model generations vs. its correct prevalence in the gold set. A value of BR>1 indicates over-representation, BR<1 under-representation (erasure). Aggregation across languages highlights systematic geographical underrepresentation.
The results demonstrate that most evaluated models show statistically significant elevation in BUS, with prominent LLMs doubling or tripling the frequency of US-centric answers over their expected rates.
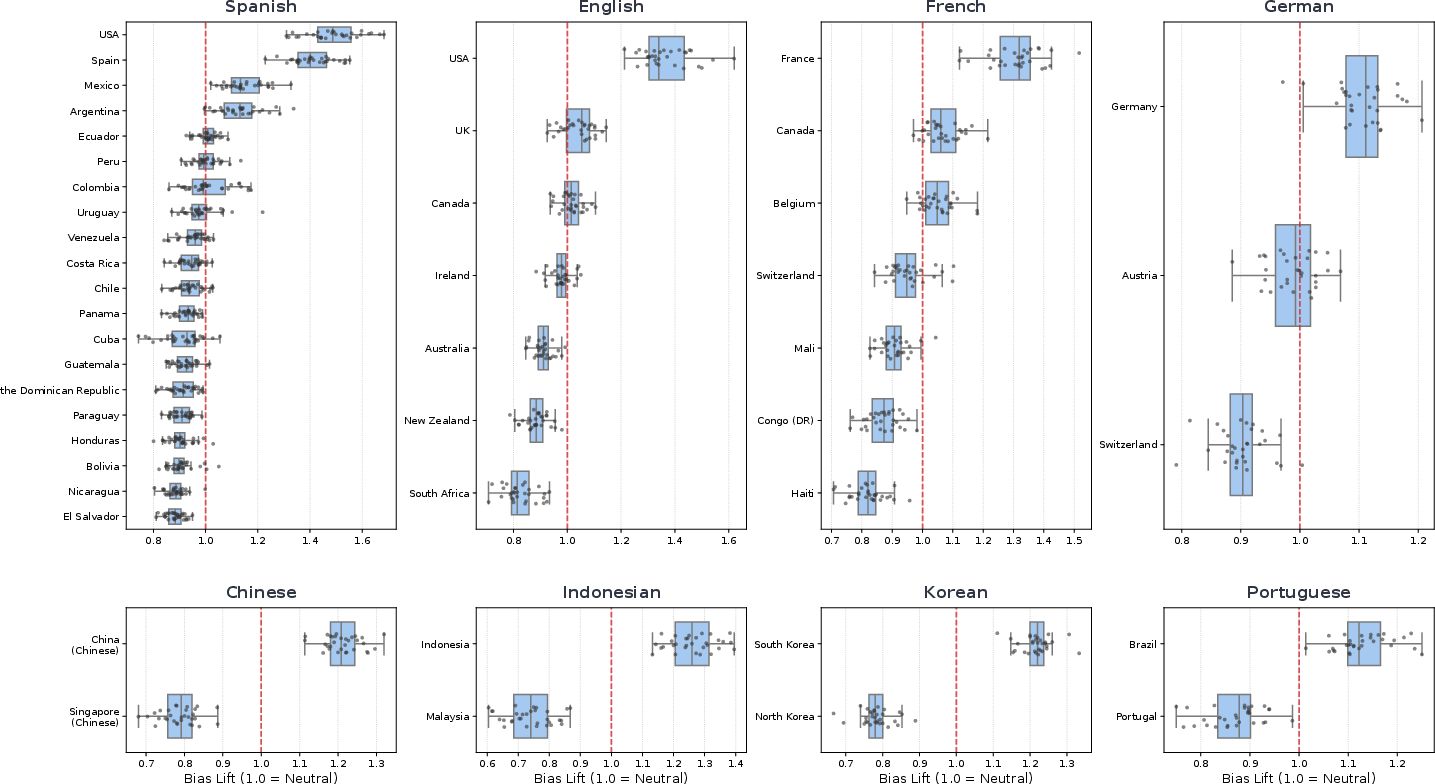
Figure 2: Distribution of Regional Bias scores; major population centers and Western nations dominate, while less populous/peripheral locales are systematically erased.
Empirical Findings
Pervasive US-Centricity (Global Bias)
Across 32 LLMs (proprietary and open-weights, zero-shot), the typical BUS is 0.24 (with models outputting US answers in ~50% of cases where gold standard would predict 26%). The strongest bias is observed in Gemini, Claude, and Grok model families. The error analysis decomposes US-centricity into (a) Erasure (replacing local norms), (b) Intrusion (gratuitous addition of US norms), (c) Selection (ambiguity-resolving in favor of US), and (d) Framing (using US as comparative anchor). Intrusion constitutes the majority error mode.
Demographic Probability Engine: Population-Scaling in Regional Bias
A central finding is that models resolve intra-lingual ambiguities by probabilistically sampling answers according to locale population size, but in a compressed fashion: BR correlates strongly with log-population, not linear raw counts. This "logarithmic compression" ensures baseline visibility for large nations without allowing them total dominance.
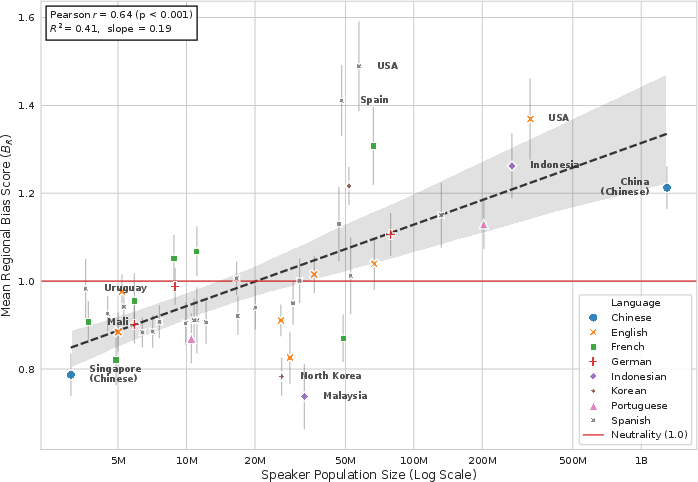
Figure 3: Regional bias scales logarithmically with locale population (R2=0.41), not linearly, indicating diminishing returns for demographic size.
Peripheral or low-population locales are consistently erased regardless of their representational validity in the ground truth.
Domain-Specific Patterns
Biases are domain-specific: infrastructure, legal, and language-based queries are disproportionately US-anchored, while cultural/leisure domains (sports, retirement) show less global bias but more extreme regional distortion.
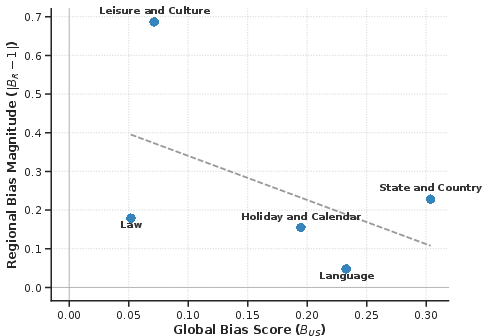
Figure 4: Domain-level scatter shows an inverse relationship between global and regional biases.
Instruction Tuning and the "Cultural Alignment Tax"
A central and strong claim is the empirical demonstration that instruction tuning, while effective at increasing answer multiplicity and providing more regionally diverse outputs, amplifies global US-centricity. All examined instruction-tuned models yield higher BUS compared to their base models, indicating a systematic "Alignment Tax": increased helpfulness/diversity mechanisms introduce a persistent bias towards using the US as an anchor for comparison.
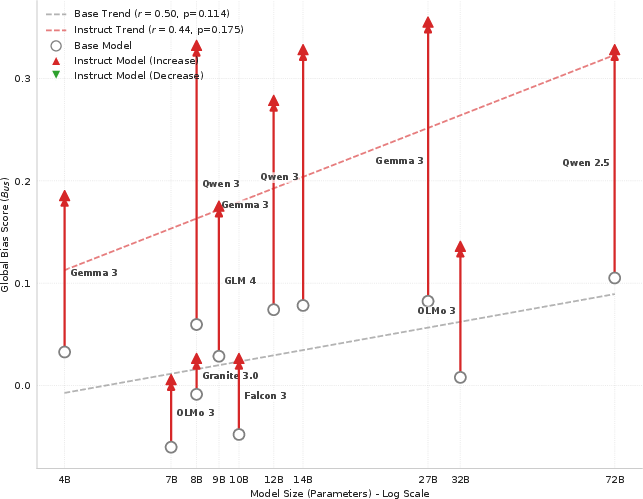
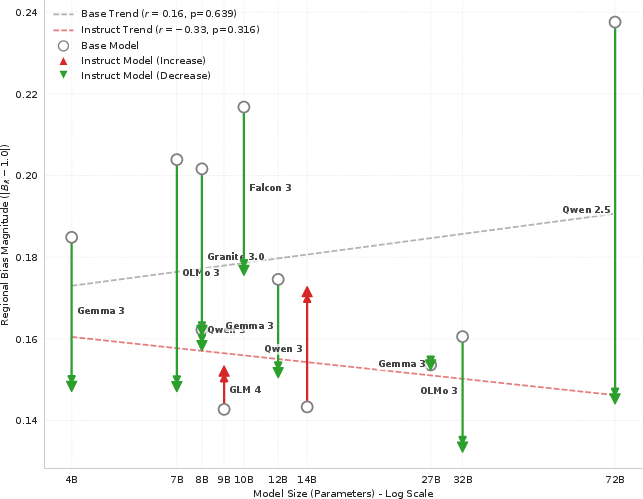
Figure 5: Instruction tuning consistently increases global (US) bias across model families—the "cultural alignment tax".
At the same time, instruction tuning reduces BUS0, i.e., it flattens intra-lingual skew, but only by making all locales more equally likely to be compared to the US.
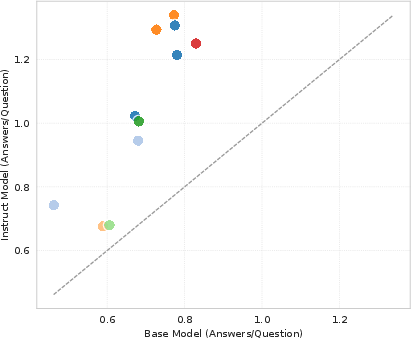
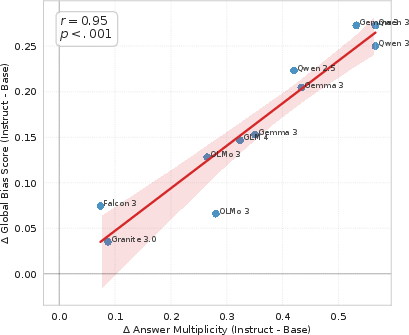
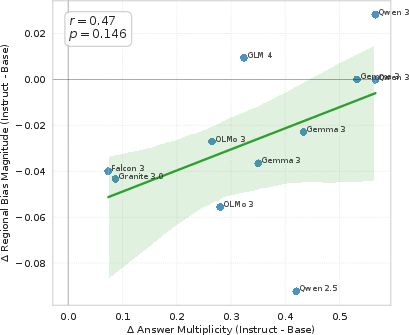
Figure 6: Instruction tuning increases the average answer multiplicity (number of locales mentioned per answer) across models.
Resilience of US Bias under Explicit Locale Prompting
When ambiguity is artificially removed via explicit locale specification ("Locale: Brazil. What is the emergency number?"), high-accuracy models are more likely for residual errors to default to the US norm, not random wrong answers. Among top models, US bias is the dominant form of persistent error regardless of base instruction.
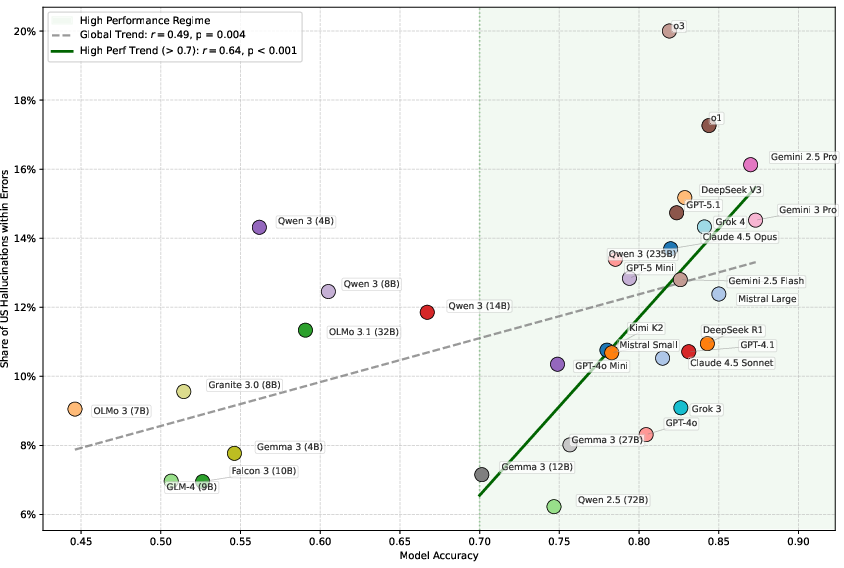
Figure 7: As overall accuracy increases, the remaining model errors are increasingly dominated by US answers—US bias is a "sticky" residual failure mode.
Theoretical and Practical Implications
The work rigorously demonstrates that linguistic fluency is inadequate as a proxy for regionally-grounded, epistemically equitable information retrieval in LLMs. Present alignment and scaling strategies, left unchecked, risk amplifying specific cultural priors, particularly those corresponding to the US and highly-populated locales. Simply increasing training data or model size does not mitigate these effects; in fact, higher capability can make bias modes more entrenched when ambiguity remains.
From a practical perspective, these findings argue for explicit modeling of locale (orthogonal to language), both in training and inference interfaces. Multicultural and multi-regional simulation must supplant naive multilingualism for models intended for global deployment.
Future Directions
Further methodological advances must address:
- Architectural or data interventions to decouple language from default locale groundings, particularly for high-ambiguity domains.
- Incorporation of low-resource locales and dialects not covered in LocQA to minimize compounding erasure effects.
- Extension to non-factual, subjectively-valued domains (moral, ethical reasoning).
- Evaluation frameworks incorporating user-centric measures of local adequacy and fairness, possibly conditioning on end-user intent estimation.
Conclusion
This work establishes LocQA as an essential tool for quantifying implicit localization biases in LLMs. The identification of persistent, instruction-exacerbated US bias, combined with population-determined regional biases, points toward systematic, model-agnostic limitations in how current architectures resolve factual ambiguity. Addressing these structural deficiencies is necessary for ensuring that future LLMs provide globally equitable, contextually appropriate information rather than defaulting to the statistical majority or US-centric worldviews.