- The paper introduces a curriculum-grounded LLM marking pipeline that systematically incorporates authorized syllabi and marking guidelines to improve assessment traceability.
- It employs modular stages—syllabus matching, marking criteria generation, and feedback loops—to align automated marking with official standards.
- Empirical results demonstrate high human-LLM agreement with robust transparency, operational consistency, and adherence to curricular benchmarks.
Curriculum-Grounded LLM-as-Judge for Educational Assessment
Motivation and Problem Statement
The deployment of LLMs for automated assessment is a rapidly evolving practice, especially within high-stakes contexts such as university admissions. While generative AI offers scalability and efficiency, unconstrained model-driven marking often lacks curriculum grounding and traceability, leading to concerns over consistency, auditability, and alignment with official assessment standards. This paper addresses these deficiencies by proposing a curriculum-grounded LLM-as-Judge pipeline architected to systematically operationalize authorized curricular artefacts—including departmental syllabi, performance band descriptors, glossaries, and marking principles—within automated marking software. Notably, the pipeline is instantiated and evaluated within the NSW Higher School Certificate (HSC) Economics subject, with integration into a real-world online platform for exam preparation.
System Architecture and Pipeline Design
The marking pipeline comprises several architecturally modular and verifiable stages, supporting both transparency and adaptability to evolving curricular requirements. The system decomposes the marking task into syllabus matching, marking criteria generation, automated marking and feedback generation, and process verification. Each stage integrates curriculum artefacts as structured, machine-interpretable inputs rather than prompt augmentations.
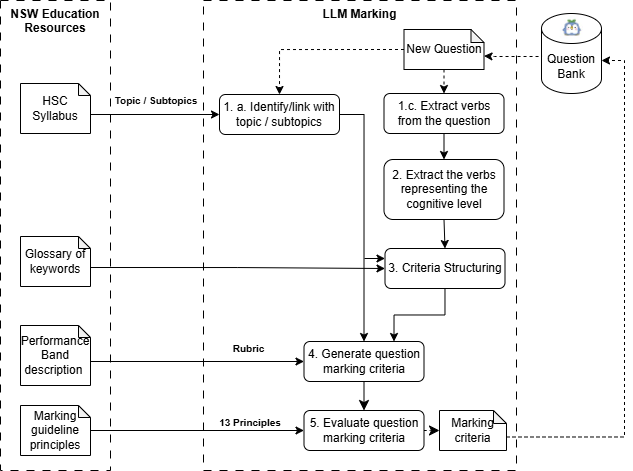
Figure 1: An overview of the curriculum-grounded LLM marking pipeline, highlighting stages and curricular artefact integration.
Syllabus Matching
The pipeline's initial stage identifies the relevant topics, subtopics, and cognitive skills from the authorized HSC syllabus using both semantic retrieval via vector databases and similarity ranking. This disambiguates the mapping between question demands (cognitive verbs, topic coverage) and syllabus statements, enhancing alignment with intended curriculum outcomes and supporting dynamic adaptation to new syllabus versions.
Marking Criteria Generation
Marking criteria are generated through a two-stage process: criteria structuring and normative performance calibration. The pipeline integrates glossary definitions for directive verbs and jurisdiction-specific performance band descriptors as explicit semantic and qualitative constraints. Marking guideline principles are embedded as normative boundaries, ensuring the generated rubrics adhere to authoritative specifications like consistency, allowance for alternative correct solutions, and proportional allocation of marks. This process supports both analytic (behavior-level) and holistic banded criteria, tightly coupling observable student evidence to authorized outcome expectations.
Marking and Feedback Loop
Student responses are scored according to the generated criteria, with independent evaluation per criterion to robustly support partial credit and fine-grained error analysis. The pipeline produces structured, syllabus-aligned feedback directly tied to curriculum outcomes and cognitive skills, mitigating the risk of generic or misaligned automated commentary. All process steps, including criteria, inferences, and calibration, are persistently recorded with provenance metadata, supporting post-hoc auditability and fault isolation.
Empirical Evaluation
The primary empirical focus is on alignment between pipeline-generated marks/justifications and human tutor marks, evaluated using Lin’s concordance correlation coefficient (CCC), weighted Cohen’s kappa, and BLEU scores for justification-curriculum overlap.
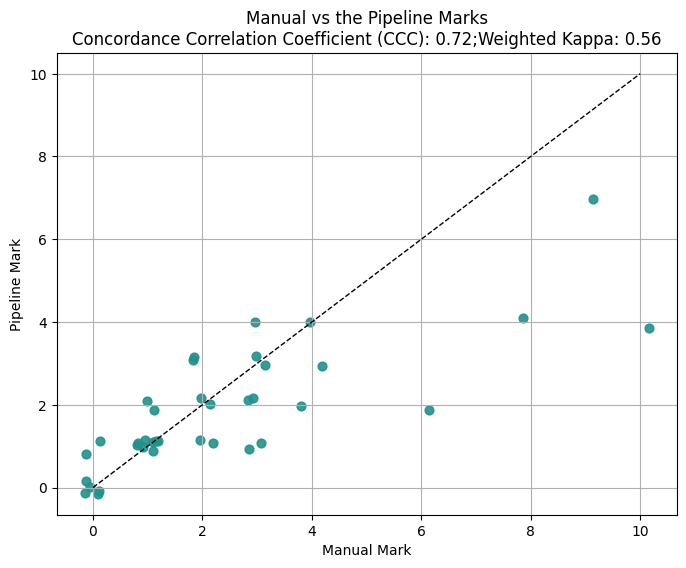
Figure 2: Agreement between human marks and pipeline-produced marks (gpt-5 for marking criteria generation and evaluation).
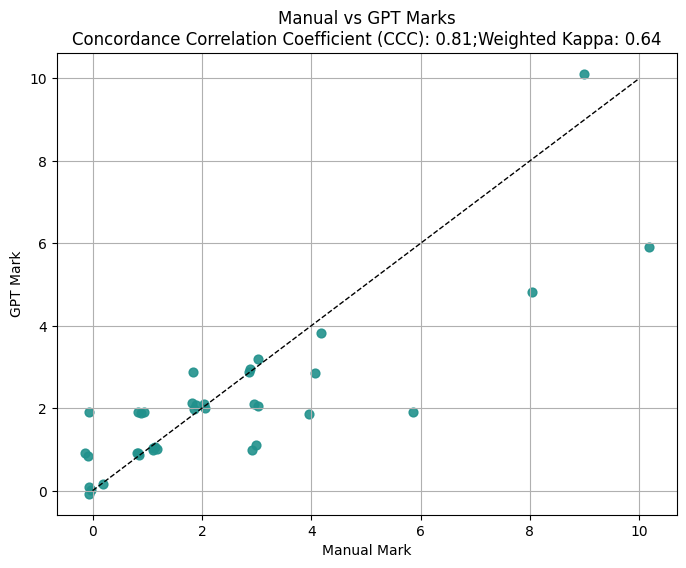
Figure 3: Comparison when LLMs are prompted with syllabus and outcome descriptions before marking (gpt-5 as marker).
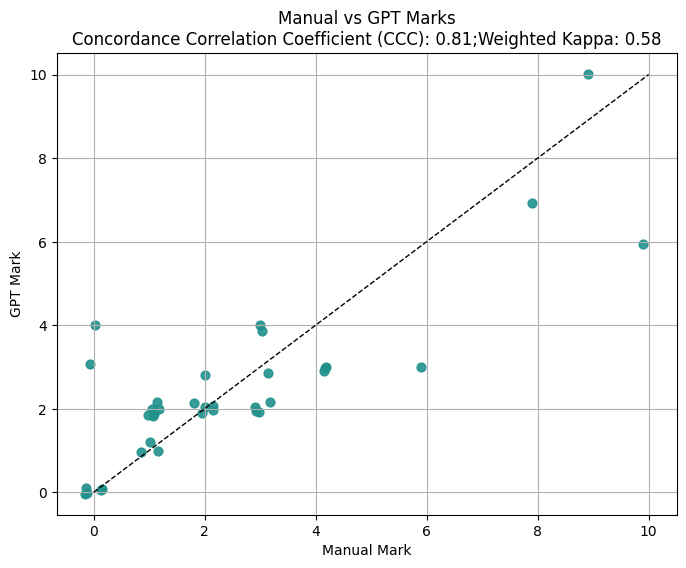
Figure 4: Marking alignment for a smaller LLM (gpt-5-nano).
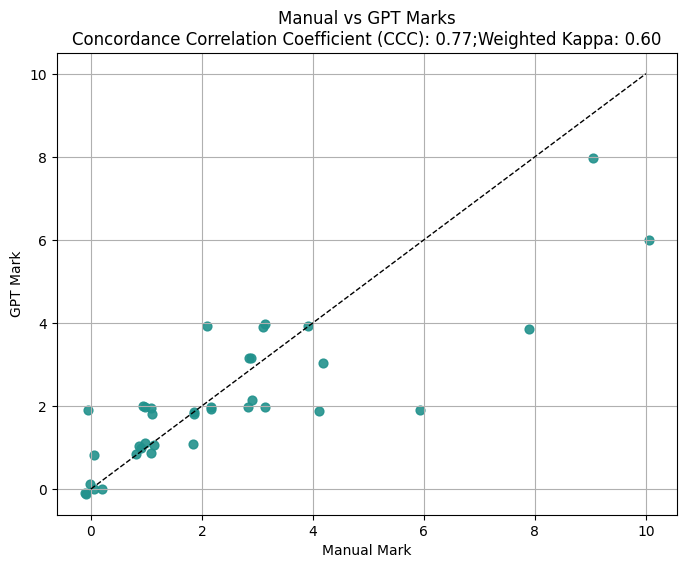
Figure 5: Effects of randomly-assigned learning outcomes on LLM marking quality (gpt-5-nano).
Key Quantitative Results
- Alignment between human tutors and pipeline is robust, with CCC and kappa metrics in the range of 0.64-0.81. Direct prompt-based LLM approaches yielded slightly higher numerical agreement, likely reflecting bias from RLHF tuning for mark-level reward signals, but lacking traceability to syllabus-grounded justifications.
- Marking justifications generated by the pipeline significantly outperform those of both humans and direct LLMs in pairwise blind evaluations, especially in criteria-traceability and curriculum-referencing (BLEU overlap with authorized material: pipeline 8.457e-3 vs. human 0.080e-3). This denotes superior transparency and accountability.
- Operational robustness is evidenced by a low manual override rate (~2.9%) in live deployment, and resilience against prompt-injection efforts.
Discussion of Contradictory and Bold Claims
A major, empirically supported claim is that curriculum-grounded, staged, and verifiable LLM pipelines can produce marking justifications that are more traceable to official curricular artefacts than both human tutors and monolithic prompt-engineered LLMs. At the same time, models with strong internalized pedagogical knowledge (from pretraining and RLHF) can numerically mimic human marks at least as closely as process-oriented approaches, but without guarantees of curricular alignment or transparency in rationales.
A contrasting observation is that while humans and out-of-the-box LLMs may provide more "creative" or less formulaic justifications, these are often less normatively valid and less auditable in relation to official standards. Furthermore, tacit knowledge embedded in human evaluation can lead to both principled discrimination and incontestable subjectivity, as highlighted by case studies with divergent human and pipeline marking rationales.
Architectural Implications and Tacit Knowledge
The pipeline’s modular architecture enables configurability for pipeline dynamism and long-term maintainability under curriculum changes. However, its approach to capturing tacit professional knowledge is limited to codifiable elements present in syllabi and marking guides. Purely tacit judgments (e.g., calibration to cohort, emergent moderation standards, or interpretation of student intent under ambiguous circumstances) are only partially addressed via artefactual embedding and conservative rule design.
Implications and Future Directions
Practically, the approach serves as a template for integrating AI assessment engines into jurisdiction-governed educational systems, supporting scaled formative feedback, reduced marking labor, and improved auditability. It mitigates fairness and bias by enforcing transparent marking and feedback aligned with external standards rather than internalized model heuristics.
On a theoretical level, the work establishes curriculum-grounded context engineering and verification as critical mechanisms for trustworthy LLM evaluation systems. The separation of tacit knowledge into codifiable artefacts versus emergent heuristics foregrounds critical challenges in AI-augmented education.
Further research directions include:
- Extension to question generation, ensuring dynamic coverage and adaptive curriculum evolution within the same verification framework.
- Transfer to other subjects and jurisdictions with distinct regulatory and curricular requirements.
- Dialogue-based, multimodal, and synergy-oriented assessment, with a focus on co-evolution of AI and student roles in assessment.
- Formalization of tacit knowledge capture for adaptation and governance.
Conclusion
This study demonstrates that a curriculum-grounded, engineered LLM-as-Judge pipeline delivers both high mark alignment and superior justification traceability compared to conventional human practice and flat LLM prompting. Explicit operationalization of curricular intent, structural verification, and rigorous architectural modularity are required for responsible deployment of generative AI in high-stakes educational assessment. This approach provides a principled pathway for integrating LLMs within regulated, auditable, and evolving educational ecosystems.

