MMDiff: Extending Diffusion Transformers for Multi-Modal Generation
Abstract: Diffusion transformers have demonstrated remarkable generative capabilities, yet the rich perceptual representations computed across their denoising trajectory are discarded once the content is rendered. We present MMDiff, a framework that transforms a frozen diffusion transformer into a multi-modal generative system that jointly produces images alongside any combination of dense perceptual modalities using lightweight decoder heads. Our central finding is that perceptual information is temporally distributed along the denoising trajectory, and that multi-timestep feature fusion with spatially varying aggregation weights is essential, improving semantic segmentation results by up to 28.7% mIoU over single-timestep extraction. We further adopt concept-driven attention extraction for interpretable spatial guidance, and show that frozen diffusion features are competitive with and complementary to state-of-the-art encoders such as DINOv3. By training only lightweight decoder heads on a frozen backbone, we achieve strong performance in semantic segmentation, salient object detection, and depth estimation, and demonstrate that this framework enables effective synthetic data generation at scale.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces MMDiff, a way to turn a powerful image generator into an “all-in-one” tool that creates a picture and, at the same time, produces useful extra maps about that picture—like which pixels belong to which objects (semantic segmentation), what parts stand out (saliency), and how far things are (depth). The trick is to reuse the generator’s “inner thoughts” during image creation, instead of ignoring them.
What questions did the researchers ask?
They focused on three simple questions:
- Can we read the useful information a big image generator already computes while it creates a picture, without changing how it’s trained?
- If we listen to the model at multiple moments during its step‑by‑step creation process, do we get better, richer information than if we only look at the final step?
- Can we use that information to produce high‑quality labels automatically, so we can train other vision models without paying for lots of manual annotation?
How does their method work?
Think of a diffusion image generator (a “Diffusion Transformer,” or DiT) like an artist who starts with a very noisy canvas and gradually refines it into a clear image. At each step, the artist forms ideas about the overall layout (where the dog is, where the road is) and the details (fur, edges). Normally, all those in‑between thoughts are thrown away at the end.
MMDiff “listens in” to those thoughts and turns them into useful maps.
Listening across multiple steps
- The generator refines an image over many steps, from super noisy to clean.
- Early steps capture big picture ideas (rough shapes and layouts).
- Later steps capture details (sharp edges and textures).
- MMDiff collects features from several of these steps because each one adds something different.
Fusing features smartly
- Instead of just averaging everything, MMDiff learns how much to trust each step for each pixel.
- For example, a smooth sky region might rely more on early, broad information; an object boundary might rely more on late, detailed information.
- This “per-pixel weighting” blends the best of coarse and fine information.
Asking for guidance with concepts
- MMDiff can ask the model targeted questions like “where is the object?” or “what’s near vs. far?” without changing how the image is generated.
- It does this by adding “concept tokens” (like simple labels) that look at the image features and produce clean, focused attention maps. Think of it as pointing a spotlight where a specific concept appears.
Small decoders on top of a frozen generator
- The big generator stays “frozen” (unchanged). This keeps things efficient and stable.
- Small, lightweight “decoder” networks are trained to turn the fused features into:
- semantic segmentation maps (coloring each object category),
- saliency maps (what draws your eye),
- depth maps (distance of each pixel).
Optionally, MMDiff can also mix in features from a different kind of model trained for recognition (like DINOv3). These discriminative features and the generator’s features often complement each other and work even better together.
What did they find?
Here are the main takeaways:
- Multi-step fusion matters a lot. Combining information from several steps of the generator greatly improves results. For example, semantic segmentation improved by up to about +28.7% (mIoU) compared to using only one step.
- The generator’s features are strong—even when frozen. Reading features from a large diffusion transformer (without retraining it) gives competitive performance compared to specialist recognition models.
- Better together: generative + discriminative features. Combining the generator’s features with a recognition model’s features (like DINOv3) gives the best results, because they learn different things.
- High‑quality automatic labels. MMDiff can generate images and accurate labels (segmentation, saliency, depth) at the same time. Using these labels to train other models often beats older methods that tried to do similar things with different generators.
Why does this matter?
- Cheaper, faster training data: Creating labeled datasets is expensive. MMDiff lets you generate images and their labels automatically and at scale, which can save a lot of time and money.
- Consistent multi‑modal outputs: Because the labels come from the same inner process that made the image, the labels fit the image well (for example, the depth map matches the scene layout).
- Works beyond images: The idea of reading and fusing information across steps can help with video and 3D generation too, where keeping things consistent over time and space is crucial.
- Practical and flexible: You don’t need to retrain the huge generator for each new task. You can keep it frozen and only train small decoders, making the approach more accessible.
In short, MMDiff shows how to recycle the rich information inside modern image generators to produce multiple kinds of useful maps alongside the image itself—making AI systems smarter, more efficient, and easier to train.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of unresolved issues that future work could address:
- Generality across backbones: Results rely on FLUX.1-dev (12B) as the frozen DiT. It is unclear how well the approach transfers to other DiT families (e.g., SD3, PixArt-α), smaller/larger model scales, or different tokenizer/patch-size configurations.
- Resolution and token-scaling: FLUX maintains 1024 image tokens of dim 3072; the method’s behavior for higher/lower resolutions and different token counts (and resulting memory/latency) is not evaluated.
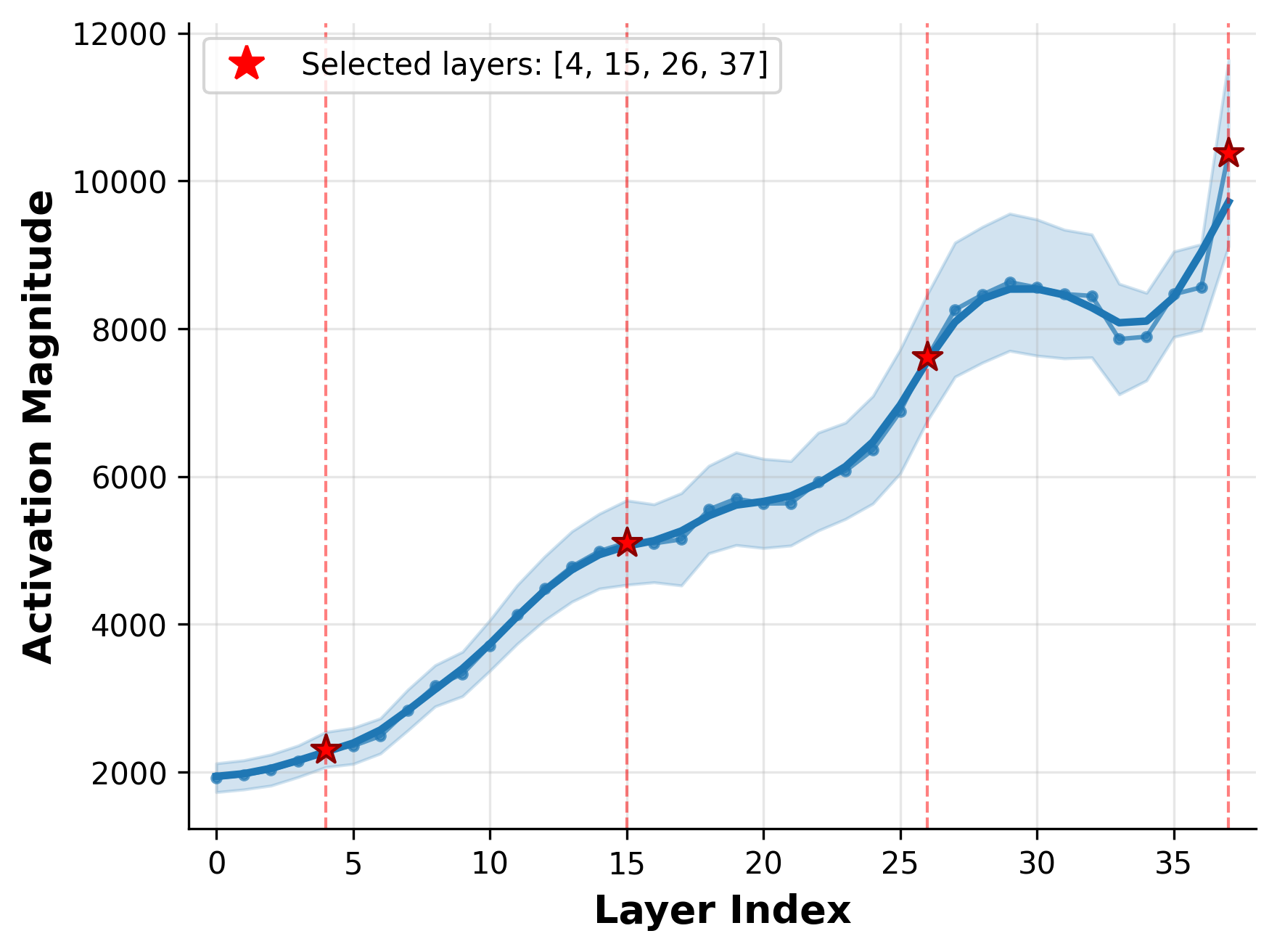
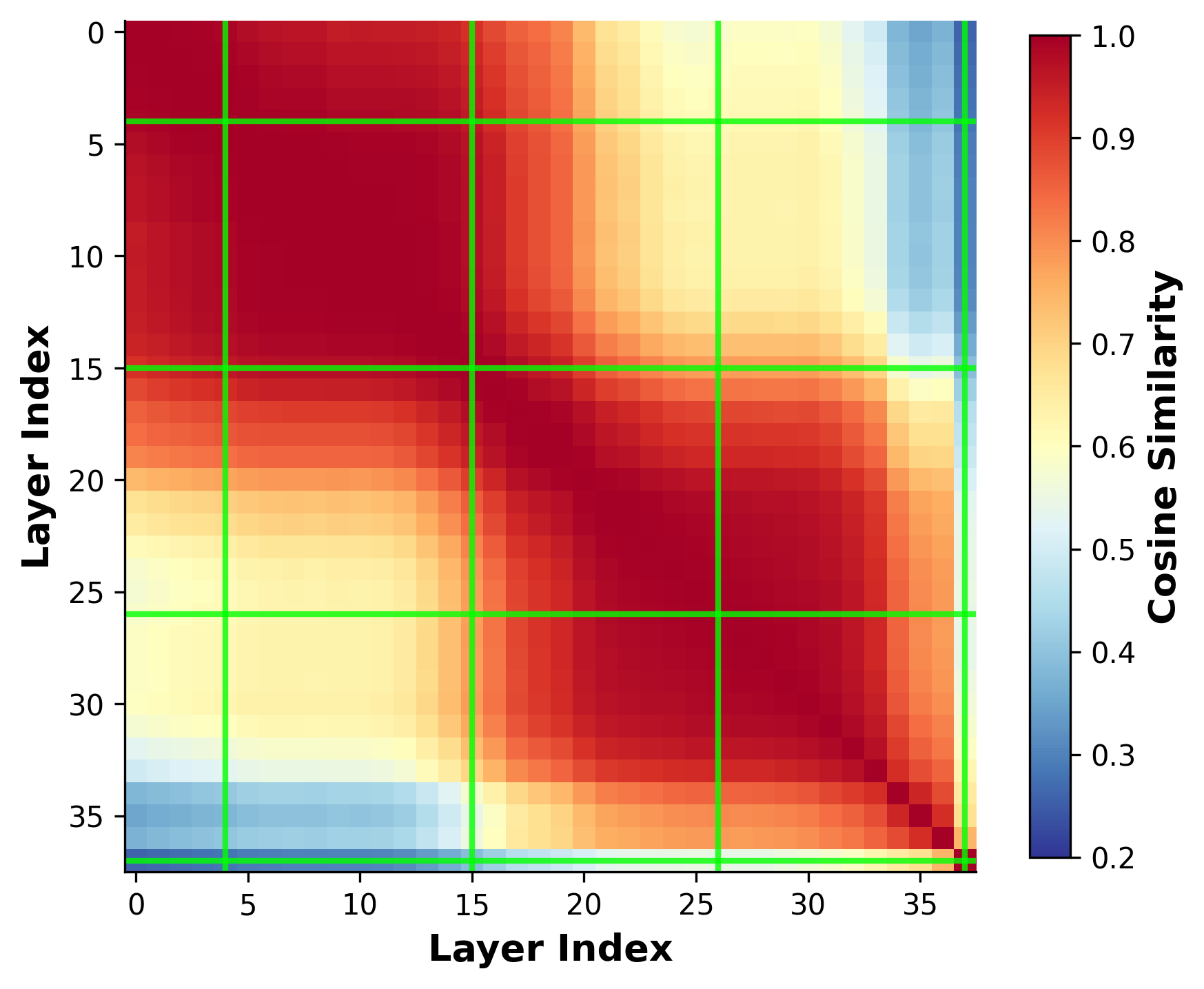
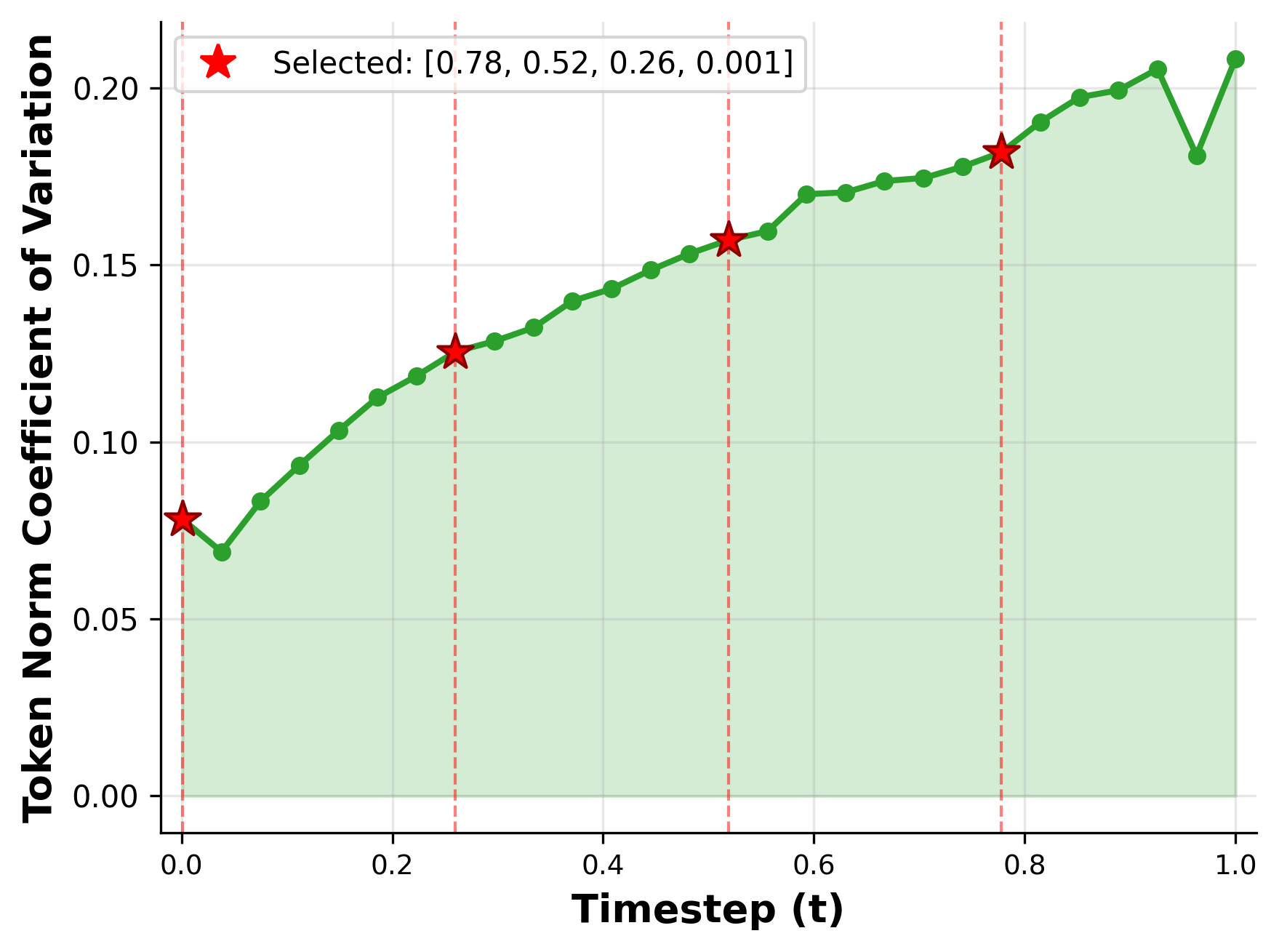
- Layer/timestep selection policy: The chosen layers L={4,15,26,37} and timesteps T={0.78,0.52,0.26,0.001} are fixed and hand-picked. There is no principled selection, sensitivity analysis, or automatic policy for selecting optimal layers/timesteps under compute/memory constraints.
- Scheduler dependence: The denoising schedule (e.g., cosine vs linear), mapping of t∈[0,1] to actual diffusion steps, and sensitivity of feature quality to the scheduler are not specified or studied.
- Aggregation model design: The 3-layer, 8-head, 768-dim aggregation transformer and CBAM were adopted without systematic architecture search or ablation on depth/width/heads; the compute-accuracy trade-offs and minimal viable complexity are unknown.
- Inference cost and latency: Extracting features at multiple layers and timesteps from a 12B DiT is expensive. Detailed runtime, memory footprint, and throughput analyses (per image, per task) are missing, hindering deployment planning.
- Stability and precision: Extracted activations have large magnitudes; the robustness of the proposed normalization/LayerScale choices under mixed precision (FP16/bfloat16), across hardware, and for very long prompts is unreported.
- Real-image feature path: For real images, the inversion path into the DiT latent space is under-specified (e.g., VAE encode/decode alignment, noise schedule matching), leaving uncertainty about reproducibility and potential inversion-induced artifacts.
- Dependence on captions: Real-image processing uses captions (Gemma-3-4B). The method’s sensitivity to caption errors, missing objects, language choice, negations, or out-of-vocabulary terms is not quantified.
- Prompt-free or weak-prompt settings: It is unclear how the system performs without text (unconditional) or with minimal prompts, both for generation and for real-image annotation extraction.
- Concept-driven attention integration: Injecting concept tokens “without affecting generation” in a frozen backbone is described at a high level; concrete implementation details (interfaces, blocks modified, constraints) and portability to other DiTs are not provided.
- Concept vocabulary design: The approach uses generic concepts (“object/background,” “near/far,” “salient/contour”) but does not address how to select, expand, or learn concept sets for large taxonomies, fine-grained classes, or open-vocabulary scenarios.
- Class-specific spatial guidance: It remains unclear how concept-driven attention scales to hundreds/thousands of semantic classes for class-specific maps, or how to map arbitrary class names to robust concept tokens.
- Robustness to ambiguous or compositional text: No evaluation on multi-object, relational, negation-heavy, or attribute-rich prompts; the effect on attention guidance and fused feature quality is unknown.
- Multi-task training dynamics: Although the framework supports “any combination” of modalities, it is not shown whether joint multi-task training of heads improves or hurts performance vs. single-task training (e.g., interference, capacity sharing).
- Additional dense tasks: The approach is not tested on instance/panoptic segmentation, normals, optical flow, surface edges, keypoints, or material/illumination; generality across diverse dense modalities is unproven.
- Video and 3D settings: Despite motivation for video/3D, there is no demonstration of temporal coherence, multi-view consistency, or geometry-aware consistency across frames/views.
- Cross-dataset generalization: Evaluations focus on VOC (segmentation), DUTS (saliency), and NYU-v2 (depth); performance on broader, more challenging datasets (e.g., ADE20K, COCO, Cityscapes, KITTI) and out-of-domain generalization is unknown.
- Synthetic-to-real transfer analysis: While synthetic pretraining helps, there is no analysis of label noise characteristics, calibration, class balance in synthetic sets, or how synthetic distributions should be curated to maximize real-data gains.
- Pseudo-GT protocol reliability: Consistency evaluation uses 200 generated images with pseudo-GT (depth and seg. from other models plus manual edits). Statistical reliability, inter-annotator agreement, and scalability of this protocol are not characterized.
- Uncertainty estimation: The framework does not expose confidence or uncertainty for the produced labels; mechanisms to filter low-confidence synthetic annotations are not provided.
- Failure modes: There is limited qualitative/quantitative analysis of where the approach fails (small/thin objects, heavy occlusion, clutter, extreme viewpoints), which would guide targeted improvements.
- Interaction with discriminative encoders: While DINO-v3 features help, the framework does not explore other discriminative backbones (e.g., CLIP, EVA-CLIP, ConvNeXt), joint adaptation strategies, or when generative/discriminative features conflict.
- Ablations on concept attention vs cross-attention: Although concept-driven attention outperforms averaged cross-attention, the study does not explore alternatives (e.g., token filtering, learned token reweighting, attention rollout) or provide theoretical insight into why output-space similarity is superior.
- Scaling number of timesteps: Only four timesteps are used. The existence of diminishing returns, optimal timestep counts/placements, or adaptive timestep selection at inference remains open.
- Per-layer vs per-timestep contributions: Beyond a coarse selection, the framework does not quantify which layers/timesteps are most informative per task, nor whether task-adaptive selection can reduce compute.
- Privacy, safety, and bias: The implications of using a large generative model for annotation at scale (content bias, stereotype amplification, copyrighted content leakage) are unaddressed.
- Licensing and reproducibility: FLUX.1-dev availability, licensing terms, and compatibility with the concept-token injection are not discussed, affecting reproducibility and deployment.
- Environmental cost: Training and large-scale generation on a 12B frozen backbone are compute-intensive; carbon footprint and efficiency strategies (e.g., caching, distillation) are not considered.
- Distillation and compression: There is no attempt to distill the fused multi-timestep features or the decoder into a smaller, task-specific student for efficient deployment.
- Real-time or on-device usage: Feasibility on constrained hardware is not evaluated; methods to prune layers, quantize, or approximate multi-timestep fusion are unexplored.
- Theoretical understanding: The paper asserts “temporal distribution of semantics” but lacks a formal analysis linking score evolution, attention dynamics, and task-relevant information across timesteps.
- Robustness to noise schedule mismatch: Using forward diffusion on real images assumes a schedule compatible with the backbone’s training; the effect of schedule mismatch or alternative noising schemes is untested.
- Error propagation from VAE: If the DiT operates in latent space, reconstruction/inversion errors from the VAE encoder-decoder pipeline and their impact on downstream predictions are not analyzed.
- Automatic concept discovery: No mechanism is proposed to learn useful concept tokens from data (e.g., via clustering or self-supervision) rather than hand-specifying them per task.
- Open-vocabulary segmentation: The framework has not been evaluated for zero-shot or open-vocabulary segmentation, despite its text-conditioning and concept attention components.
- Handling long or multi-sentence prompts: The effect of long prompts on attention quality, token dilution, and feature fusion is not studied.
- Class imbalance and rare concepts: The behavior on rare classes or long-tail distributions in both generation and decoding is not investigated.
- Negative and counterfactual prompts: How negations or counterfactuals in prompts affect concept attention and fused features is unknown.
- Re-ranking or refinement: No label refinement (e.g., CRF, diffusion-guided post-processing, test-time ensembling) is explored to further improve boundary quality or depth consistency.
- Public release completeness: While a website is linked, the paper does not inventory what artifacts (code, configs, prompts, trained heads, inference scripts) will be released to fully reproduce the results.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases enabled by MMDiff’s findings (multi-timestep feature fusion, concept-driven attention, and lightweight decoders on a frozen DiT), together with likely sectors, workflows/products, and key dependencies.
Software, AI Tooling, and Data Platforms
- Self-annotating synthetic data generation at scale
- Sector: Software/AI, Robotics, AV, AR/VR, Finance (document vision), Retail
- What it enables: Generate images that are automatically paired with pixel-accurate semantic segmentation, saliency, and relative depth maps in a single pass. Use to pretrain/fine-tune discriminative models when labeled data is scarce.
- Product/workflow: “Annotate-as-you-generate” pipeline/API (Prompt → Image + Segmentation + Depth + Saliency); Dataset balancing and long-tail class synthesis via prompt programming; QC hooks to filter low-confidence outputs.
- Dependencies/assumptions: Access to a strong DiT with internal feature taps (e.g., FLUX.1-dev), GPU memory (multi-timestep features increase compute/VRAM), light task-specific decoders (≈36M params) trained on some real labels, licensing for backbone/weights.
- Semi-automatic labeling for real images
- Sector: Data labeling services, Platform ML teams
- What it enables: Use the forward-diffusion trick plus decoders to extract segmentation/saliency/depth for existing images; humans validate and correct to boost throughput.
- Product/workflow: “Auto-label then verify” tool; caption real images (e.g., with a small LLM) to supply prompts → noising → multi-timestep feature extraction → decoder predictions → human-in-the-loop corrections.
- Dependencies/assumptions: Image captioning quality impacts guidance (used Gemma-3-4B in paper); compute overhead for multi-timestep extraction; taxonomy alignment between predicted classes and project labels.
- Complementary feature fusion for better perception models
- Sector: Vision model development (academia/industry)
- What it enables: Fuse diffusion features with discriminative encoders (e.g., DINO-v3) to improve segmentation or depth training pipelines; shown to outperform either alone.
- Product/workflow: Feature-fusion training kit; drop-in module that concatenates DINO features with MMDiff fused features/attention maps before the decoder.
- Dependencies/assumptions: Access to DINO(-v3) inference; careful normalization of DiT features; added latency/VRAM.
Media, Entertainment, and Design
- Generation of “production-ready” image layers for post-production
- Sector: VFX, Gaming, Creative suites
- What it enables: Alongside an image, produce per-object masks, saliency, and depth for compositing, relighting, DoF, parallax effects, inpainting, and matte extraction.
- Product/workflow: “Prompt-to-layers” export (e.g., PSD/EXR layers: RGB, masks per class/object, depth); Adobe/Blender plugins.
- Dependencies/assumptions: Class taxonomies must fit creative needs; model prompts may need style conditioning; runtime and VRAM budget for multi-timestep fusion.
- Content safety and editorial tooling
- Sector: Social platforms, Ad-tech, Newsrooms
- What it enables: Concept-driven attention maps to localize categories (e.g., “logo,” “nudity,” “weapon”) without altering the image; faster moderation/edits.
- Product/workflow: “Concept attention inspector” UI to highlight regions per concept for review or automatic redaction.
- Dependencies/assumptions: Concept tokens must be curated per policy; false positives/negatives require human review; model bias auditing is needed.
Robotics, Autonomy, and Simulation
- Synthetic corpora for perception pretraining
- Sector: Robotics, AV/ADAS, Logistics
- What it enables: Cheaply produce diverse, labeled scenes (masks + relative depth) to pretrain detectors/segmenters before real-world fine-tuning, including rare events via prompts.
- Product/workflow: Scenario factory for long-tail cases; use class-conditional prompts; generate plus filter for quality; pretrain then fine-tune on real driving/warehouse data.
- Dependencies/assumptions: Domain gap (photorealism, sensor characteristics) must be addressed (style prompts, color augmentation, domain adaptation); depth is relative, not metrically-calibrated.
E-commerce, Marketing, and UX
- Automated product cutouts and focus analysis
- Sector: Retail, Ad-tech, Web UX
- What it enables: Saliency maps for creative/layout A/B tests; segmentation masks for background removal/compositing; depth-aware AR previews.
- Product/workflow: Batch processing pipeline to extract masks/saliency from catalog images; integration with creative ops.
- Dependencies/assumptions: For real images, prompts from captions must be reliable; class taxonomy alignment (e.g., “shoe,” “bag”).
Academia and Education
- Rapid curation of teaching/benchmark datasets
- Sector: Academia, Education technology
- What it enables: Generate multi-modal datasets with paired RGB, segmentation, and depth for classroom labs and challenge benchmarks.
- Product/workflow: Course kit with scripts for prompt sets, generation, and evaluation; dashboards for concept attention visualization.
- Dependencies/assumptions: Institutional compute or cloud; clear dataset licensing and provenance.
Policy, Risk, and Governance
- Privacy-preserving data augmentation
- Sector: Regulated industries (Finance, Health-adjacent, Public sector)
- What it enables: Replace or supplement sensitive data with synthetic data plus labels to reduce exposure during early-stage model development.
- Product/workflow: “Red-team” prompts to stress-test models, generate balanced sets across sensitive attributes for fairness prechecks.
- Dependencies/assumptions: Synthetic data inherits biases of the generator; mandatory bias audits and documentation (datasheets/model cards); transparent labeling of synthetic content.
Long-Term Applications
These require further research in scaling, domain adaptation, or architectural extensions (e.g., efficient DiT access, video DiTs), but are direct extensions of the paper’s innovations.
Video, 3D, and 4D Content Pipelines
- Temporally consistent video generation with per-frame annotations
- Sector: VFX, AV, Sports analytics, Surveillance
- What it enables: Jointly generate video frames plus temporally consistent segmentation, saliency, depth, and optical flow for training and post-production.
- Product/workflow: “Video MMDiff” with temporal fusion across denoising steps and inter-frame consistency losses.
- Dependencies/assumptions: Video-capable DiTs with accessible internal features; memory/latency scaling; temporal correspondence mechanisms.
- 3D asset and scene reconstruction
- Sector: Gaming, Digital twins, AR/VR, Architecture
- What it enables: From generated images (and depth/normals), reconstruct textured meshes or feed NeRFs; generate labeled 3D assets and scene graphs.
- Product/workflow: Prompt → multi-view image set (future extension) + depth/seg → multi-view stereo/NeRF → mesh/semantic scene graph.
- Dependencies/assumptions: Multi-view consistency from the generator; calibrated camera parameters; depth currently relative (needs scale recovery).
Domain-Specific Perception in Specialized Verticals
- Medical imaging data synthesis and annotation
- Sector: Healthcare
- What it enables: Generate and label rare pathologies for segmentation/measurement tasks (e.g., lesion masks, organ boundaries).
- Product/workflow: Fine-tune decoders on limited clinical labels; in-domain prompts; integrate clinician-in-the-loop verification.
- Dependencies/assumptions: Medical-grade DiTs or domain adaptation; strict regulatory validation; bias and safety assessments.
- Autonomous driving and robotics corner-case factories
- Sector: Transportation, Industrial robotics
- What it enables: Rare adverse scenarios (weather, night, sensor artifacts) with consistent per-pixel labels and relative depth; extend to multi-sensor simulation.
- Product/workflow: Scenario generator tied to driving taxonomies; synthetic → real adaptation; curriculum pretraining.
- Dependencies/assumptions: Domain realism and calibration; future extension to multi-camera/LiDAR fusion; licensing for commercial use.
Efficiency, Deployment, and Model Compression
- Distilled “feature-tap” student models for edge and real-time use
- Sector: Mobile/Edge AI, Robotics
- What it enables: Distill multi-timestep fused features and concept attention into compact encoders for on-device perception.
- Product/workflow: Teacher–student distillation capturing temporal fusion behavior; latency targets for edge hardware.
- Dependencies/assumptions: Retaining performance under distillation; capturing concept-guided spatial priors; dataset breadth for generalization.
Open-Vocabulary and Policy-Aware Perception
- Open-vocabulary segmentation guided by concept tokens
- Sector: Search, Moderation, Knowledge graphs
- What it enables: Define arbitrary categories at inference (e.g., “brand logo,” “safety helmet”) via concept-driven attention without retraining the generator.
- Product/workflow: Dynamic taxonomy service that emits masks for user-defined concepts; integration with compliance rule engines.
- Dependencies/assumptions: Robustness of concept embeddings; failure handling for ambiguous prompts; incremental learning of niche concepts.
- Policy enforcement and content provenance
- Sector: Platforms, Public sector
- What it enables: Automated marking of sensitive regions (faces, plates) for anonymization; provenance layers (masks/depth) attached as metadata for audit.
- Product/workflow: Pipeline that tags outputs with policy-relevant layers; downstream anonymization/redaction tools.
- Dependencies/assumptions: Governance for storage of derived layers; potential false positives; alignment with legal standards.
Foundation-Model Training and Multi-Task Learning
- Multi-modal pretraining regimes
- Sector: Foundation model developers, Academia
- What it enables: Use MMDiff as a label factory for multi-task encoders (segmentation, depth, saliency) with richer supervision than pixels alone.
- Product/workflow: Synthetic pretraining curricula that interleave tasks; self-training loops on real images using MMDiff pseudo-labels.
- Dependencies/assumptions: Careful handling of label noise; task weighting; preventing confirmation bias from generator artifacts.
Notes on feasibility and dependencies common across applications:
- Compute and access: Multi-timestep feature fusion requires internal hooks into a DiT (e.g., FLUX) and adds compute/memory overhead. Cloud deployment is often required; on-device use benefits from future distillation.
- Data and decoders: Lightweight decoders must be trained on some real labels for each target task and domain; taxonomy alignment is essential.
- Prompting and guidance: Real-image processing benefits from reliable captions; concept-driven attention requires curated concept tokens.
- Quality caveats: Depth is relative (scale recovery needed for metrically-accurate use). Annotations may reflect generator biases; auditing and human oversight are advised.
- Licensing and compliance: Ensure rights to use backbone weights, generated data, and derived labels in commercial contexts; clearly label synthetic data in production systems.
Glossary
- AbsRel: Absolute Relative Error, a common metric for evaluating depth estimation accuracy by comparing predicted and true depths proportionally. "We report mean Intersection over Union (mIoU) for segmentation, S-measure ()~\cite{smeasure}, max F-score ()~\cite{f1max}; MAE~\cite{mae} for saliency; AbsRel, RMSE, and threshold accuracies for depth."
- AdamW: An optimizer that decouples weight decay from the gradient-based update, improving generalization and convergence in deep networks. "For decoder training, we use AdamW~\cite{loshchilov2017decoupled} with a learning rate of and differential learning rates, where decoders use half the base rate."
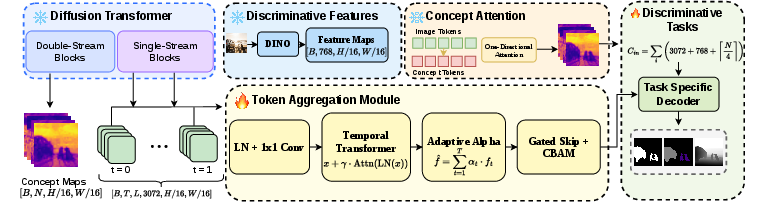
- ASPP (Atrous Spatial Pyramid Pooling): A module that captures multi-scale context by applying parallel dilated convolutions with different rates. "For semantic segmentation, we use the DeepLabV3+ decoder head~\cite{chen2018encoder} with ASPP \cite{chen2017deeplab} modules."
- Attention output space: The representation space produced by attention layers; similarities computed here can provide spatial maps. "Spatial maps are then extracted by computing dot-product similarities between concept output vectors and image patch output vectors in the attention output space:"
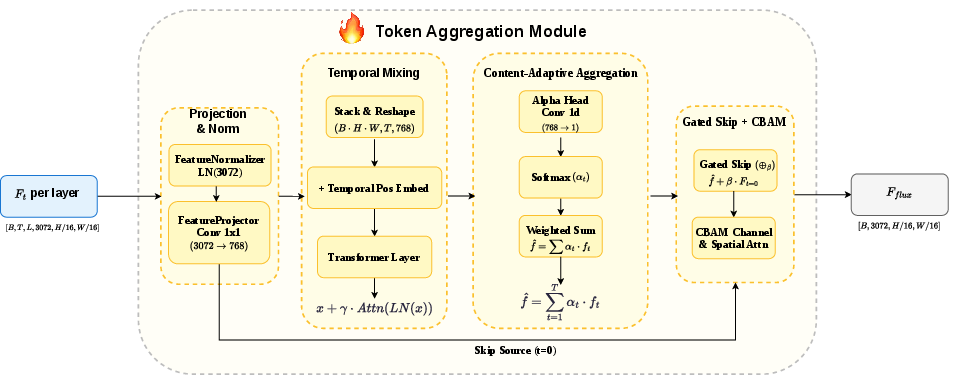
- CBAM (Convolutional Block Attention Module): An attention module that sequentially applies channel and spatial attention to refine feature representations. "The weighted combination is refined using Convolutional Block Attention (CBAM)~\cite{woo2018cbam}, which applies channel and spatial attention."
- Concept embeddings: Vector representations for user-defined concepts (e.g., “object”, “background”) that attend to image tokens to yield guidance without affecting generation. "We adopt concept-driven attention extraction~\cite{helbling2025conceptattention}, which addresses these limitations by creating a separate stream of concept embeddings that are not used for image generation."
- Concept-driven attention extraction: A mechanism that injects concept tokens that attend to image tokens (one-directionally) to obtain interpretable spatial guidance. "We further adopt concept-driven attention extraction for interpretable spatial guidance, and show that frozen diffusion features are competitive with and complementary to state-of-the-art encoders such as DINOv3."
- Contrastive learning: A training paradigm that learns representations by bringing similar samples closer and pushing dissimilar ones apart. "Diffusion features encode semantic relationships from generative training, while discriminative features capture distinct visual characteristics from contrastive learning, and the two are complementary rather than redundant."
- Cross-attention maps: Attention maps between two sequences (e.g., text and image tokens) that localize associations, often used for spatial guidance. "This differs from traditional cross-attention maps, which operate in the query-key space."
- DeepLabV3+: A semantic segmentation architecture featuring encoder-decoder design and ASPP for robust multi-scale context. "For semantic segmentation, we use the DeepLabV3+ decoder head~\cite{chen2018encoder} with ASPP \cite{chen2017deeplab} modules."
- Denoised latent: The latent representation at the end of the denoising process; often lacks some global semantic information compared to intermediate states. "However, all of these approaches extract features from the final denoised latent or the last denoising timestep, discarding all intermediate representations computed during generation."
- Denoising timestep: An index in the diffusion process that controls the noise level and refinement stage during generation. "Diffusion transformers process thousands of tokens across dozens of layers and denoising timesteps to generate a single image or video, yet all intermediate representations are discarded once the final content is rendered."
- Denoising trajectory: The sequence of representations produced across timesteps as noise is removed; semantic information is distributed along it. "We show that information in DiT is distributed across the denoising trajectory, and introduce multi-timestep feature fusion to capture the complete perceptual information encoded across them."
- Depth estimation: Predicting per-pixel scene depth from an image, typically producing a dense depth map. "By training only lightweight decoder heads on a frozen backbone, we achieve strong performance in semantic segmentation, salient object detection, and depth estimation"
- DINO-v3: A self-supervised vision transformer model producing discriminative features that can complement generative diffusion features. "We optionally integrate DINO-v3 features~\cite{siméoni2025dinov3} with our diffusion-based representations."
- Diffusion Transformer (DiT): A transformer-based architecture for diffusion models that processes tokens at uniform resolution without downsampling. "State-of-the-art models like FLUX~\cite{labs2023flux}, Stable Diffusion 3~\cite{esser2024sd3}, and PixArt-~\cite{chen2023pixart} adopt the Diffusion Transformer (DiT) architecture~\cite{peebles2023scalable}."
- DPT (Dense Prediction Transformer): A decoder design for dense tasks (e.g., depth, segmentation) that reassembles hierarchical features for pixel-wise predictions. "Depth estimation employs a DPT-style decoder~\cite{ranftl2021vision} with hierarchical reassembly."
- Dropout: A regularization technique that randomly zeroes activations during training to reduce overfitting. "We use LayerScale initialization~\cite{touvron2021going} () for stability and dropout \cite{srivastava2014dropout} (0.1) for regularization."
- Dual-stream architecture: A design with separate streams (e.g., text-image interaction and unified processing) before merging, as used in FLUX. "Modern DiTs, such as FLUX~\cite{labs2023flux}, employ a dual-stream architecture comprising double-stream blocks followed by single-stream transformer blocks."
- Exponential Moving Average (EMA): An averaging technique over model parameters to stabilize training and improve generalization. "We apply Exponential Moving Average~\cite{polyak1992acceleration} with for stability."
- Feature entropy: A measure of the variability or information content within features, used here to analyze timestep complementarity. "Figure~\ref{fig:rebuttal_analysis}b visualizes feature entropy across timesteps , demonstrating distinct information content at each denoising stage"
- FLUX: A large-scale DiT-based generative model with dual- then single-stream blocks for text-image diffusion. "FLUX~\cite{labs2023flux} extends this with a dual-stream architecture: 19 double-stream blocks for text-image interaction followed by 38 single-stream blocks for unified processing."
- Forward diffusion process: The process of adding noise to data at a given timestep during diffusion, used for feature extraction on real images. "For real images, we apply the forward diffusion process~\cite{tang2023emergent} to add Gaussian noise:"
- GELU (Gaussian Error Linear Unit): An activation function that weights inputs by their probability under a Gaussian, often outperforming ReLU in transformers. "Each layer includes pre-normalization, multi-head self-attention with temporal positional embeddings, and feedforward networks with GELU \cite{hendrycks2016gaussian} activation."
- Layer normalization: A normalization method applied across features within a layer to stabilize and accelerate training. "The module first applies learned linear projections to reduce the feature dimension... followed by layer normalization."
- LayerScale initialization: Initializing small learnable scalars on residual branches to improve stability in deep transformers. "We use LayerScale initialization~\cite{touvron2021going} () for stability"
- Latent diffusion models: Diffusion models that operate in a compressed latent space for efficiency at high resolutions. "Latent diffusion models~\cite{rombach2022high} enable efficient high-resolution synthesis by operating in a compressed latent space."
- MAE (Mean Absolute Error): An error metric that averages absolute differences between predictions and ground truth. "We report mean Intersection over Union (mIoU) for segmentation, S-measure ()~\cite{smeasure}, max F-score ()~\cite{f1max}; MAE~\cite{mae} for saliency"
- mIoU (mean Intersection over Union): A standard metric for evaluating segmentation by averaging IoU across classes. "multi-timestep feature fusion with spatially varying aggregation weights is essential, improving semantic segmentation results by up to 28.7\% mIoU over single-timestep extraction."
- Multi-head self-attention: An attention mechanism using multiple parallel heads to capture diverse relationships among tokens. "Each layer includes pre-normalization, multi-head self-attention with temporal positional embeddings"
- Multi-modal generative system: A generator that produces multiple output modalities (e.g., images and dense labels) in a single pass. "We present MMDiff, a framework that transforms a frozen diffusion transformer into a multi-modal generative system that jointly produces images alongside any combination of dense perceptual modalities"
- Multi-timestep feature fusion: Aggregating features from several denoising timesteps to capture complementary coarse-to-fine information. "multi-timestep feature fusion with spatially varying aggregation weights is essential"
- Positional embeddings (temporal): Learned embeddings encoding timestep order to inform attention of temporal position. "multi-head self-attention with temporal positional embeddings"
- Residual connection: A skip connection that adds input features to outputs, helping preserve information and stabilize training. "A residual connection from the cleanest timestep () preserves fine details."
- RMSE (Root Mean Squared Error): A metric measuring the square root of the average squared differences between predictions and ground truth. "We report mean Intersection over Union (mIoU) for segmentation, S-measure ()...; AbsRel, RMSE, and threshold accuracies for depth."
- S-measure (): A metric for evaluating salient object detection that balances region-aware and object-aware similarity. "We report mean Intersection over Union (mIoU) for segmentation, S-measure ()~\cite{smeasure}, max F-score ()~\cite{f1max}"
- Salient object detection: Identifying the most visually prominent objects in an image with a dense foreground map. "We extensively evaluate MMDiff by training lightweight decoders for three dense prediction tasks: salient object detection, semantic segmentation, and depth estimation."
- Self-attention: An operation where tokens attend to each other within a sequence to aggregate context, central to transformers. "processing all patches with equal capacity through self-attention rather than hierarchical downsampling."
- Single-stream blocks: Transformer blocks that process tokens in a unified stream after initial dual-stream interaction. "Modern DiTs, such as FLUX~\cite{labs2023flux}, employ a dual-stream architecture comprising double-stream blocks followed by single-stream transformer blocks."
- Softmax: A normalization function converting scores to probabilities, widely used in attention mechanisms. ""
- Stable Diffusion 3: A diffusion-based generative model that uses a Diffusion Transformer architecture. "State-of-the-art models like FLUX~\cite{labs2023flux}, Stable Diffusion 3~\cite{esser2024sd3}, and PixArt-~\cite{chen2023pixart} adopt the Diffusion Transformer (DiT) architecture"
- Token aggregation: The process of combining many token features into a compact representation via learned weighting or pooling. "Token Aggregation."
- U-Net: An encoder-decoder architecture with skip connections that builds spatial hierarchies via downsampling and upsampling. "Unlike U-Nets~\cite{unet}, which organize representations hierarchically through spatial downsampling, DiTs process all tokens at uniform resolution throughout the network"
- VAE (Variational Autoencoder): A generative model that encodes data into a latent distribution and decodes samples; often used as an image decoder in diffusion pipelines. "WVD~\cite{wvd} trains the diffusion transformer itself to output geometry as separate output channels alongside RGB, though geometry is only available after the full generation process completes via the VAE decoder."
- ViT-B/16: A Vision Transformer variant with base size and 16×16 patch size, commonly used as a feature backbone. "We extract features from DINO-v3-ViT-B/16 and concatenate them with our fused DiT features and concept maps."
- VPD: A diffusion-based baseline method that injects external text features and typically requires fine-tuning the U-Net backbone. "Compared with VPD~\cite{zhao2023vpd}, which requires fine-tuning the denoising UNet, we achieve a +2.08\% mIoU on segmentation and a +0.011 S-measure on saliency with a frozen encoder."
Collections
Sign up for free to add this paper to one or more collections.