- The paper introduces a decoupled MoE architecture that separates expert modules and the uncertainty-aware router from the LLM backbone to enable modular and scalable knowledge injection.
- It attaches lightweight, parameter-efficient experts solely to the final FFN, preserving cache reuse and reducing inference latency while avoiding catastrophic forgetting.
- Empirical results demonstrate that DMoE outperforms dense and retrieval-based methods on several benchmarks, achieving superior answer quality and computational efficiency.
Decoupled Mixture-of-Experts for Modular Knowledge Injection in LLMs
Background and Motivation
LLMs exhibit static parametric knowledge post-pretraining, leading to deficits on domain-specific and time-sensitive queries. Existing approaches addressing knowledge injection fall into two principal paradigms: Retrieval-Augmented Generation (RAG), which appends external knowledge as context, and post-training-based methods, including fine-tuning and parameter-efficient adaptation (e.g., LoRA), which modify model parameters directly. RAG prioritizes flexibility and updateability but integrates knowledge only at the prompt level. Post-training-based approaches achieve deeper parametric integration at the cost of catastrophic forgetting, knowledge conflict, and low modularity.
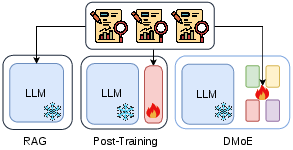
Figure 1: Comparison of knowledge injection paradigms: RAG, post-training, and DMoE.
This architectural bottleneck prevents explicit isolation of heterogeneous knowledge, scalable knowledge addition/removal, and preservation of efficient autoregressive inference. The paper introduces Decoupled Mixture-of-Experts (DMoE), an architecture that decouples both experts and the router from the backbone model, yielding modular, parameter-level integration compatible with cache-efficient decoding.
DMoE Architecture and Routing Mechanism
DMoE structures the LLM system into three distinct components:
- A frozen base model responsible for general language understanding.
- External lightweight expert modules, each encapsulating a semantic unit of knowledge.
- A decoupled uncertainty-aware router that conditionally triggers relevant experts based on token uncertainty during generation.
Unlike traditional MoE—where experts and the router are tightly coupled in the backbone—DMoE keeps both router and experts external, allowing independent expert updates. Expert modules are implemented as lightweight parameter-efficient adapters (e.g., LoRA) trained on knowledge units and attached exclusively to the final-layer FFN of the transformer, avoiding recomputation of attention KV-cache.
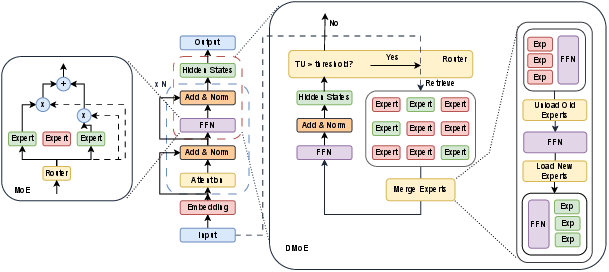
Figure 2: Architectural comparison among dense, MoE, and DMoE models; DMoE decouples router and experts and only activates them at inference as needed.
Expert Placement and Cache-Efficient Generation
A technical challenge is maintaining KV-cache reuse during dynamic expert activation. Inserting experts at intermediate layers would invalidate cached attention states, resulting in substantial inference overhead. DMoE attaches experts solely to the final-layer FFN; this guarantees that activation modifies only the output projection and does not perturb earlier hidden representations, thus preserving attention cache reusability.
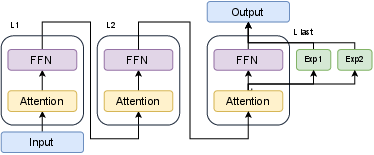
Figure 3: Illustration of expert placement in DMoE; experts applied to final FFN preserve earlier attention block states and enable cache-safe decoding.
Empirical studies reveal that performance drops if experts are applied before the last FFN due to cache incompatibility. DMoE achieves consistently superior effectiveness-efficiency trade-off by this minimal-intrusive placement.
Router Design and Activation Strategy
The router employs token entropy (“Token Uncertainty,” TU) as a trigger signal. Routing is activated only when TU exceeds a threshold, ensuring that experts are invoked only when the base model lacks sufficient knowledge. The expert selection utilizes a BM25 lexical retriever over the text surrogates associated with expert modules, and activates the top-k retrieved experts for each triggered step.
This mechanism is training-free, incrementally updatable, and scales to large expert banks, supporting modular insertion/removal of knowledge units. Analysis of the impact of top-k selection and TU threshold reveals robustness: downstream metrics remain stable across wide ranges, and the architecture does not require careful hyperparameter tuning.
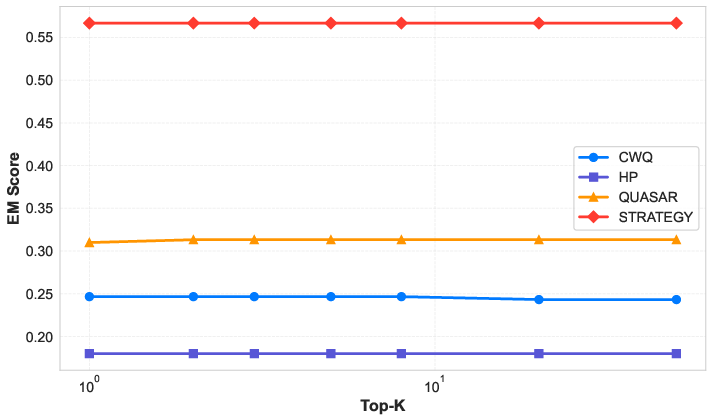
Figure 4: DMoE downstream performance is robust to the number of activated experts.

Figure 5: Effectiveness and inference speed are stable across broad triggering threshold ranges.
Efficiency and Ablation Results
DMoE is markedly more computationally efficient than coupled MoE or dynamic retrieval-based methods. When compared to FLARE or standard MoE backbones, DMoE achieves 3× lower inference latency and 1.6×–1.9× lower GPU memory footprint, attributed to cache-safe expert placement. Ablation further demonstrates that DMoE’s gains arise from architectural decoupling—not merely increased parameter capacity.
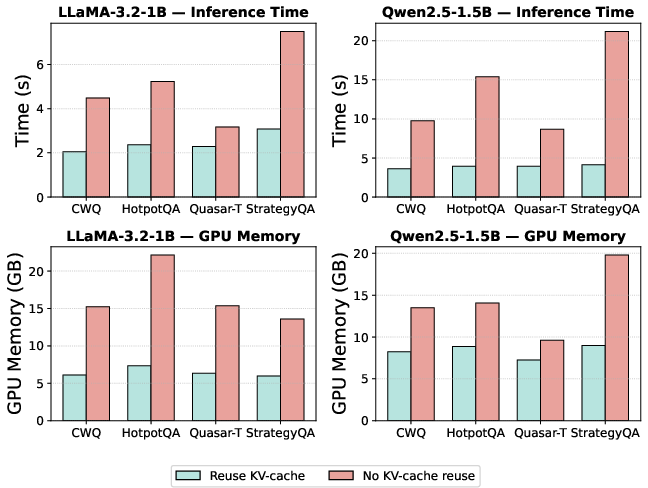
Figure 6: KV-cache reuse in DMoE yields consistent reductions in GPU memory and inference time across benchmarks and base models.
Empirical Evaluation
On four knowledge-intensive benchmarks (HotpotQA, ComplexWebQuestions, Quasar-T, StrategyQA) and two base models (Llama3.2-1B, Qwen2.5-1.5B), DMoE consistently outperforms dense baselines and is competitive with retrieval and adapter-based methods. Across 14 effectiveness metrics, DMoE achieves the best or tied-best score on 11 metrics. This demonstrates modular knowledge injection at parameter-level can yield both high answer quality and efficiency.
Implications and Future Directions
DMoE’s architectural decoupling of experts and router from the base model introduces a principled framework for scalable, modular, and updateable knowledge injection in LLMs. The expertise is composable and incrementally updatable; isolated modules prevent knowledge conflict and catastrophic forgetting. Practically, this supports rapid insertion/removal of knowledge without backbone retraining. Theoretically, DMoE’s conditional computation aligns with advances in sparse model architectures and conditional routing. Future directions include hierarchical expert banks, dense retriever-based routing, cross-domain knowledge fusion, and adaptive expert capacity scaling.
Conclusion
DMoE establishes a modular, cache-compatible architecture for parametric knowledge injection in LLMs. By decoupling both experts and the router from the base model and confining expert activation to the final-layer FFN, DMoE achieves parameter-level integration, updateability, and efficiency not afforded by RAG or post-training approaches. Extensive empirical evidence supports both its effectiveness and inference efficiency. DMoE lays the foundation for scalable expert modularization in LLMs and opens new possibilities for high-fidelity, continually updateable LLM systems (2606.14243).