- The paper introduces a block-level routing strategy that aggregates token-level scores into adaptive core sets to control expert activation in diffusion LLMs.
- It reduces the mean unique expert count from 69.5 to 14.6 (a 79% decrease) while maintaining over 99% of baseline accuracy on reasoning tasks.
- The method achieves a 76-80% drop in memory usage and up to 1.66× faster inference, enabling scalable deployments on resource-limited platforms.
dMoE: Block-Level Expert Routing for Diffusion LLMs
Introduction and Motivation
Diffusion LLMs (dLLMs) represent a major paradigm shift from traditional autoregressive LLMs, leveraging iterative masked-token denoising to facilitate parallel token generation within a block. This architecture unlocks significant efficiency potential at test time, particularly when paired with Mixture-of-Experts (MoE) techniques for scalable capacity expansion. However, integrating MoE’s token-level routing—inherited from autoregressive models—into the block-parallel regime of dLLMs results in a substantial increase in the number of uniquely activated experts per forward pass, intensifying memory bottlenecks during inference.
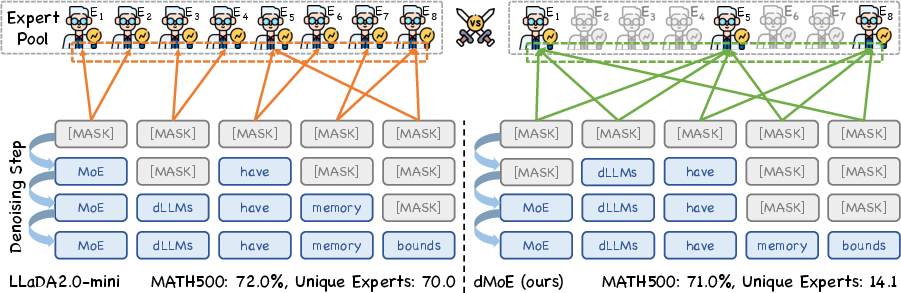
Figure 1: Comparison between the original LLaDA2.0-mini and dMoE, where dMoE replaces token-level expert routing with block-level routing, sharply reducing unique expert activation without loss in performance.
Empirical Bottleneck Analysis
The authors conduct extensive empirical analyses using LLaDA2.0-mini, focusing on observed inference bottlenecks. Their studies demonstrate that in the MoE-enabled dLLMs, MoE execution latency dominates total inference time, scaling nearly linearly with the number of unique experts activated per block-parallel step.
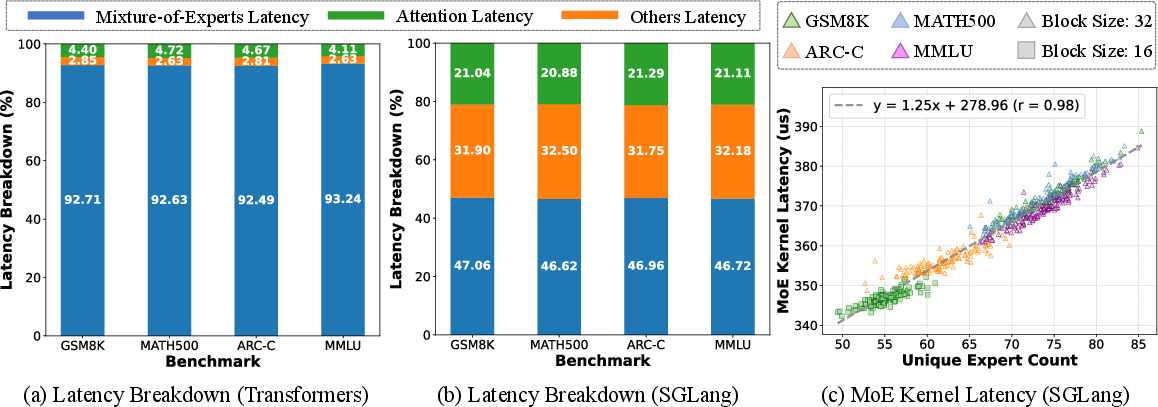
Figure 2: (a) Additional empirical guidance (b) Latency breakdown showing MoE as the primary contributor to inference time. (c) Linear relationship between unique expert count and MoE kernel latency.
Further diagnostic analysis establishes two critical observations:
- Token-level router weights are predictive of expert importance, evidenced by a positive correlation between router confidences and loss increases upon expert masking.
- Expert concentration is highly variable across denoising steps/blocks, meaning the active expert set changes adaptively during inference.
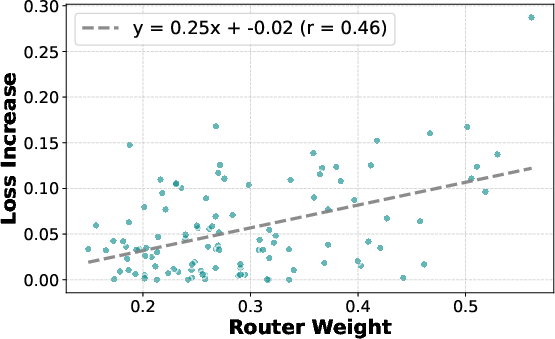
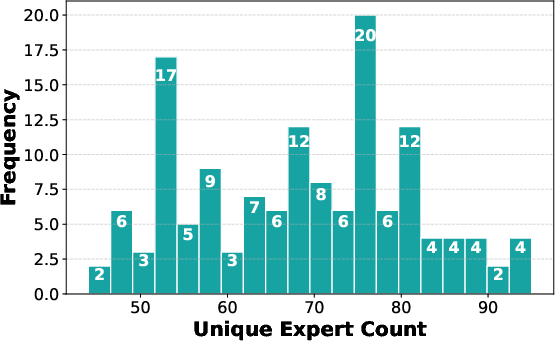
Figure 3: (a) Correlation between router weights and loss increase. (b) Distribution of unique expert count during inference, highlighting high variance.
dMoE Methodology
Block-Level Routing with Adaptive Coreset
dMoE’s core contribution is a transition from token-level to block-level expert routing. For each noisy block processed, token-level expert affinities are aggregated into block-level scores, after which a top-p selection criterion adaptively determines a coreset—a minimal expert subset sufficient to cover inference needs for that block. Subsequent token-level expert selection is strictly restricted to this coreset, drastically limiting memory usage.
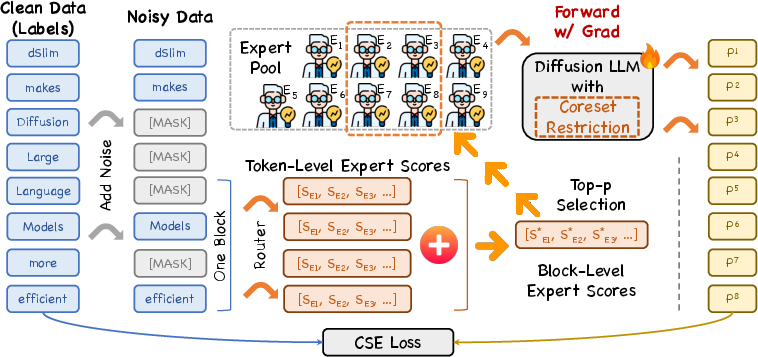
Figure 4: dMoE overview: token-level router scores are aggregated, top-p coreset selection is applied, and final token-level routing occurs within this adaptive expert subset. Training uses self-distillation with CSE loss.
The implementation maintains the same number of experts per token but sharply reduces the distinct experts used in any block. Coreset size is automatically tuned based on the block’s expert score concentration, yielding hardware- and context-adaptive efficiency.
Training and Inference Regimen
dMoE is trained on self-distilled data collected from the base model using public datasets, echoing the original routing process in the forward pass to ensure alignment between training and inference. Critical hyperparameters such as block size and top-p threshold are systematically ablated, showing robustness and tunability.
Experimental Results
The authors benchmark dMoE on multiple reasoning tasks (MATH500, GSM8K, ARC-C, MMLU) using LLaDA2.0-mini as the base model. The principal findings are:
- dMoE reduces the mean unique expert count per layer from 69.5 to 14.6, a 79.04% decrease, while preserving 99.11% of the original aggregate benchmark accuracy.
- Memory usage drops by 76.64–79.84% and end-to-end latency improves by factors of 1.14×–1.66×, attributable to a pronounced reduction in expert activation and thus memory accesses.
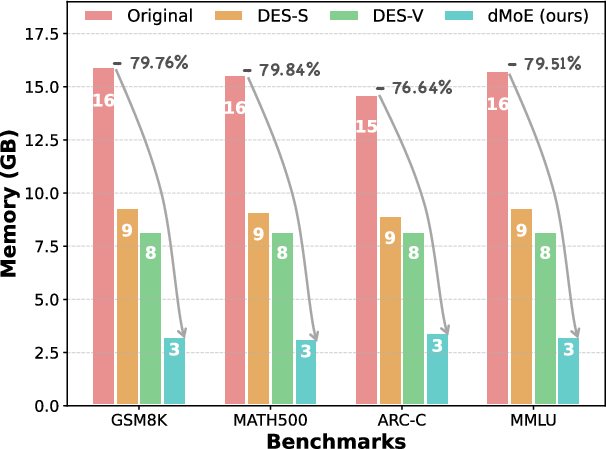
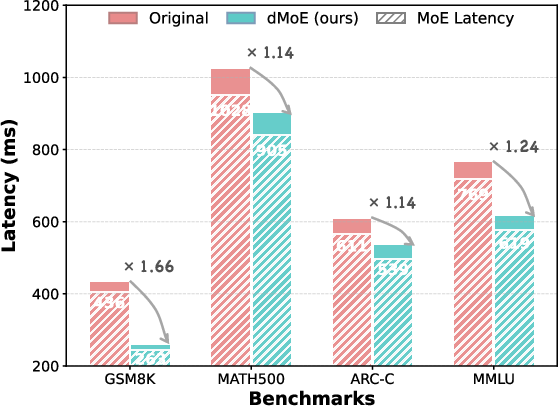
Figure 5: (a) Memory usage comparison across baselines and dMoE. (b) End-to-end and MoE-specific latency, highlighting speedup achieved by dMoE.
dMoE consistently outperforms system-level adaptive baselines such as DES-S and DES-V, especially in regimes of extreme expert compression, where the baseline models exhibit marked performance collapse but dMoE maintains high accuracy.
Extensive ablation demonstrates that dMoE’s performance-efficiency trade-off can be finely modulated via the cumulative probability threshold p and block size, enabling deployment optimization tailored to specific hardware or application constraints.
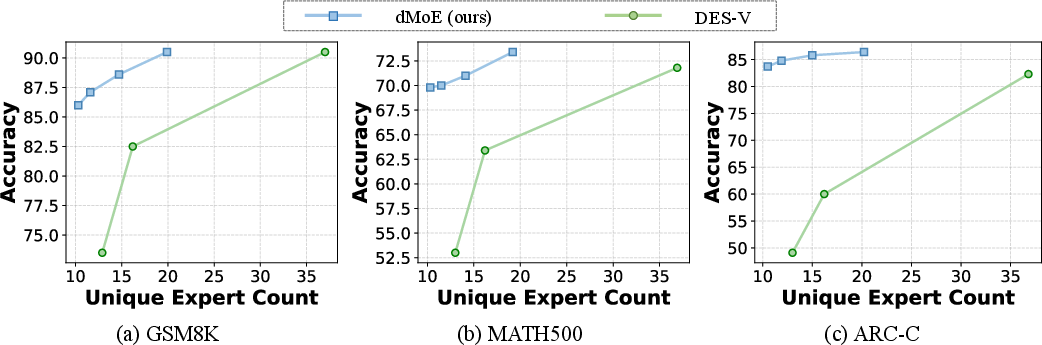
Figure 6: Performance-efficiency trade-off of dMoE versus baselines across GSM8K, MATH500, and ARC-C, confirming superior retention of accuracy at reduced expert counts.
Theoretical and Practical Implications
dMoE extends block-level routing to the diffusion model context, where traditional MoE paradigms falter due to massive blockwise expert explosions. The block-level aggregation and adaptive coreset selection provide an elegant solution, offering a hardware-friendly path toward scalable, efficient inference in densely routed diffusion models.
Practically, dMoE dramatically lowers the resource footprint of dLLMs, alleviating deployment challenges on resource-constrained or memory-bound platforms. In theoretical terms, the methodology situates expert routing as a dynamic, context-sensitive process rather than a fixed per-token operation, motivating further research into block-level and coarse-grained adaptivity in large-scale architectures.
The authors suggest multiple future advances: compressing further by harmonizing expert groups across a block, reducing per-token expert counts, and transferring the methodology to other modalities (e.g., vision, multimodal reasoning).
Conclusion
dMoE introduces a block-level, learnable MoE routing strategy specifically for diffusion LLMs, enabling substantial reductions in unique expert activation, memory usage, and inference latency with virtually no loss in task performance. The proposed method establishes a robust foundation for scalable, efficient MoE routing in parallel-generative architectures and opens several avenues for accelerating and compressing future dLLM deployments.