Diffusion Policy Optimization without Drifting Apart
Abstract: RL post-training has become increasingly pivotal for improving diffusion policies, but existing diffusion policy-gradient methods are often unstable and cannot achieve reliable policy improvement. We identify the cause as the double-drift phenomenon: optimizing a variational surrogate can let the ELBO separate from the true log-likelihood, which then makes the resulting proxy policy gradient misaligned with the true policy gradient of expected return. We propose \textbf{DiPOD}, a diffusion policy optimization framework that maintains tight-bound behavior throughout training by interleaving self-distillation with policy-improving gradient updates. This leads to a simple and practical algorithm: augmenting each diffusion policy-gradient update with an on-policy ELBO regularizer. Across diffusion LLM post-training and continuous-control diffusion policies, DiPOD substantially stabilizes training and reaches higher rewards than previous methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Diffusion Policy Optimization without Drifting Apart (DiPOD) — Explained Simply
What is this paper about?
This paper is about teaching “diffusion” AI models to make better decisions using reinforcement learning (RL) without becoming unstable. The authors show why many current methods wobble or break during training, and they introduce a fix called DiPOD that keeps learning steady and improves results.
Diffusion models are a kind of AI that generate things (like text, images, or robot actions) by starting from noise and gradually cleaning it up. They’re fast and flexible, but hard to fine-tune with RL because a key quantity (how likely the model is to choose an action) is very hard to compute exactly.
What questions did the researchers ask?
- Why do existing RL methods for diffusion models sometimes start strong but later become unstable or worse?
- Can we design a way to keep training both:
- improving rewards (doing better on the task), and
- preserving the “diffusion-ness” of the model (so its math still makes sense)?
- Is there a simple, practical trick that we can add to current methods to make them stable and reliable?
The main idea in everyday language
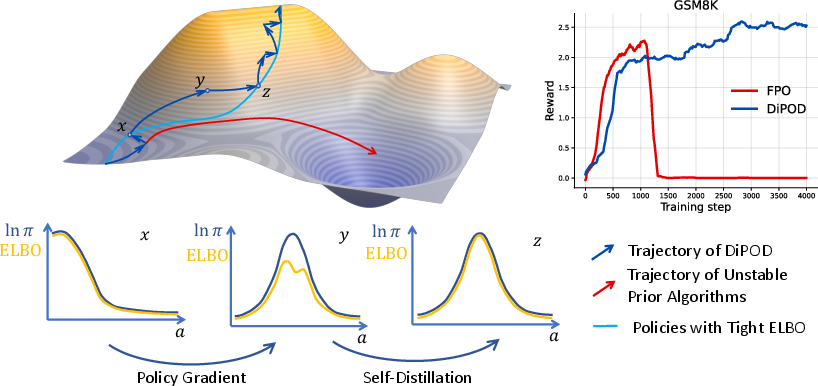
The problem: double drift
Think of training like hiking to the top of a mountain (higher is better reward). You don’t have the real landscape—only a map. For diffusion models, people use a map called the ELBO (Evidence Lower Bound). When the map is accurate (tight), walking uphill on the map leads you uphill in the real world. But as training goes on, the map can warp and drift away from the true landscape. Two bad things happen:
- The map (ELBO) drifts away from the true landscape (the real likelihood).
- Because you follow the map’s uphill direction, your steps drift away from the true best direction. This is the “double drift.” You start walking in directions that don’t actually help.
The fix: keep the map tight while you climb
DiPOD keeps the map accurate while you train. It does two things in a loop:
- Step 1: Self-distillation (tidy the map). The model teaches itself to make ELBO match the true behavior better, without changing what the model currently does. Think of it like copying your own homework neatly so it’s clear, but not changing the answers.
- Step 2: Policy-gradient update (take a step uphill). Now that the map is tidy, the “uphill” direction you follow is trustworthy.
In practice, instead of fully pausing to tidy the map, DiPOD adds a small “ELBO regularizer” to every training step. That’s like cleaning the map a little bit at each step, which is simple and works well.
What methods did they use?
- Reinforcement Learning (RL): The model tries actions, gets rewards, and learns to choose better actions over time.
- Policy gradients: A common RL method that nudges the model to make good actions more likely and bad actions less likely.
- Diffusion models: Generative models that sample by denoising. They’re powerful but make the exact “how likely is this action” calculation intractable (too hard to compute directly).
- ELBO (Evidence Lower Bound): A stand-in score that’s easier to compute than the true likelihood. If ELBO is “tight,” it’s a very good stand-in; if it’s “loose,” it misleads you.
- Self-distillation: The model learns from its own recent behavior to reduce the mismatch between ELBO and the true likelihood, keeping ELBO tight “on-policy” (on the data the model actually produces).
- Adequate estimators: Gradient formulas that are correct when the ELBO is tight. DiPOD makes sure to keep that tightness, so these estimators stay accurate.
Two versions of DiPOD:
- Ideal version (conceptual): Alternate between “tidy the map” and “take an uphill step.”
- Practical version (easy to use): During every training step, add an ELBO regularizer term. This constantly keeps the ELBO tight enough so the steps go the right way.
What did they find, and why is it important?
The authors tested DiPOD in three settings:
- A tiny “two-token” toy problem: Here they can measure exactly how much the ELBO drifts away from the true likelihood. DiPOD kept this gap small, while previous methods let it grow.
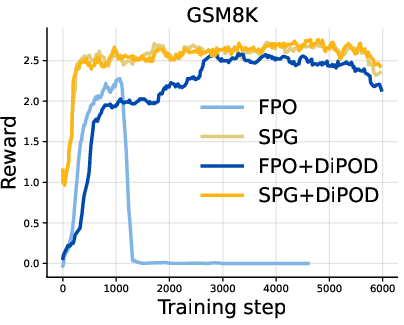
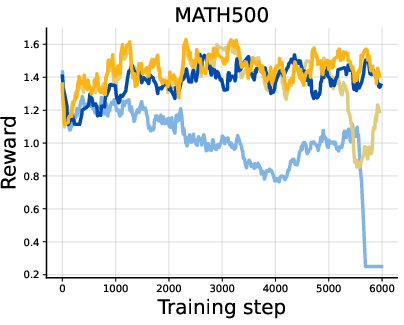
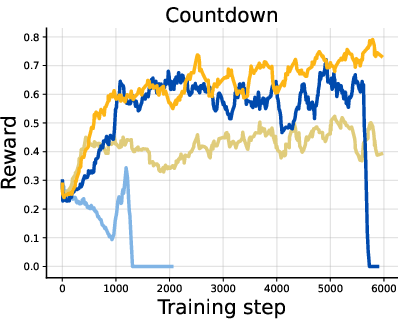
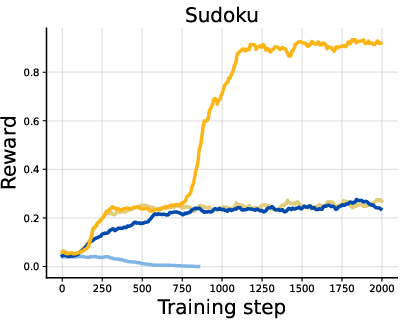
- Diffusion LLMs on reasoning tasks (like GSM8K math word problems, MATH500, Countdown, and Sudoku):
- Training became much more stable.
- Rewards generally got higher.
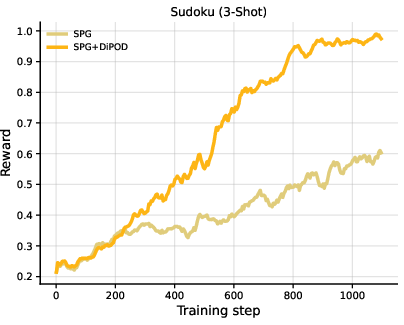
- On logic-heavy tasks (Countdown and Sudoku), DiPOD gave especially large gains. In fact, it is the first method to reach near-perfect zero-shot Sudoku performance in their setup.
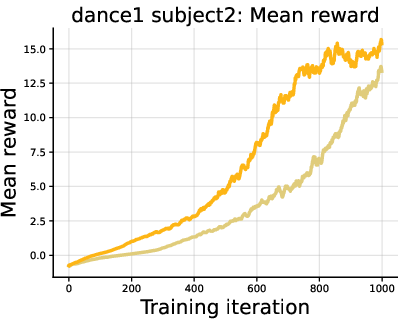
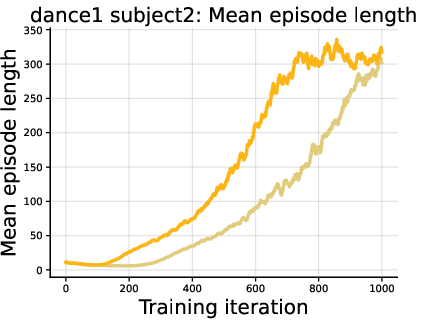
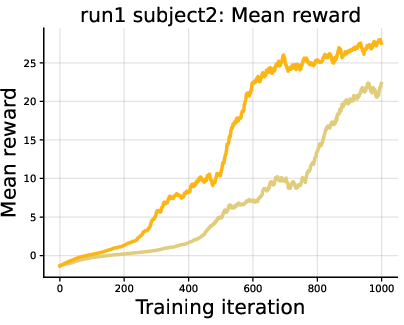
- Continuous control (robot motion tracking with a humanoid):
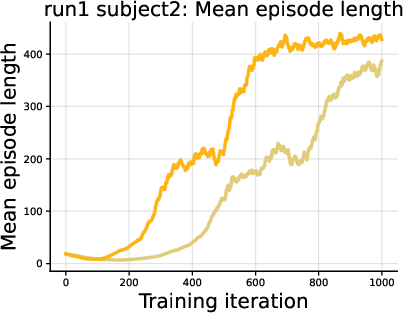
- DiPOD improved reward and how long the robot could follow the target motion.
- This shows the idea isn’t just for language—it also helps in physical control tasks.
Why this matters:
- Stability: RL post-training often becomes shaky for diffusion models. DiPOD fixes a key cause by keeping the ELBO tight.
- Better performance: More reliable training leads to better results, especially in tough reasoning tasks.
- Simple to use: The practical trick (add an ELBO regularizer each update) is a small change you can drop into existing methods.
What’s the broader impact?
- For diffusion LLMs: More stable and effective RL post-training means stronger reasoning without giving up diffusion’s advantages (fast, parallel decoding and flexible sampling).
- For robotics and control: Better stability helps complex systems (like humanoid robots) learn smoother, longer, and more accurate behaviors.
- For other models trained with ELBO-like bounds (such as VAEs): The same principle—keep the bound tight while optimizing—can make training more reliable across many generative models.
In short, DiPOD is a simple idea with big payoff: keep your stand-in (the ELBO map) accurate while you train, so every learning step stays aligned with true improvement.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of concrete gaps and unresolved questions that the paper leaves open, aimed at guiding follow-up research.
- Formal theory beyond the informal theorem: provide a complete, non-asymptotic analysis with explicit assumptions, convergence rates, step-size conditions, and monotonic-improvement guarantees in the nonconvex setting; quantify how approximate self-distillation (ε-suboptimality), stochasticity, and clipping affect improvement and final ELBO tightness.
- Adequacy characterization: develop general, verifiable criteria for when a diffusion-RL gradient estimator is “adequate” (beyond FPO/SPG/FPO++), and analyze how deviations from adequacy (e.g., partial dependency restorations, mean-field surrogates) bias policy gradients as ELBO drifts.
- Practical drift diagnostics: design tractable, on-policy estimators for the ELBO–likelihood gap in diffusion LLMs and flow policies (where exact gap is intractable), and establish thresholds that can trigger or modulate self-distillation.
- Adaptive scheduling and weighting: replace fixed β and fixed interleaving frequency n with adaptive controllers that adjust β and self-distillation effort based on estimated gap, reward improvement, or trust-region criteria; analyze stability and sample efficiency of such controllers.
- Policy-preserving guarantees: quantify and control how much the “self-distillation” step changes the policy (e.g., KL between pre/post steps); design constraints or proximal updates that provably tighten ELBO while keeping the policy distribution invariant up to a specified tolerance.
- Interaction with negative-advantage updates: for methods that use ELBO on both signs (e.g., FPO), rigorously analyze and mitigate the “cheating” failure mode where decreasing ELBO via increased discrepancy undermines correct down-weighting of bad actions.
- EUBO tractability and approximation: develop tractable, general EUBO estimators for diffusion LLMs; quantify how EUBO approximation error propagates into policy-gradient bias and whether DiPOD-style regularization can correct or compensate for that error.
- Exploration and diversity effects: study how on-policy bound tightening influences entropy, exploration, and mode coverage; determine whether ELBO regularization induces premature convergence or mode collapse and how to counteract it.
- Compute and sample-efficiency trade-offs: measure wall-clock, memory, and FLOP overheads of the extra ELBO term; analyze whether the regularizer increases, decreases, or leaves unchanged the number of rollouts needed for a given reward gain.
- Robustness and variability: the paper notes large seed variance; conduct broader multi-seed studies with statistical analysis, sensitivity to β, learning rates, clipping thresholds, and advantage estimators (GRPO/PPO variants).
- Empirical measurement of drift in real tasks: beyond the toy two-token example, introduce practical surrogate metrics to monitor gap tightening over training for dLLMs and continuous control, and correlate them with reward stability and final performance.
- Off-policy and replay settings: extend DiPOD to off-policy algorithms (experience replay, importance sampling) and study whether off-policy ELBO tightening remains effective or introduces bias/instability.
- Trust-region integration: investigate combining ELBO-tightening with explicit trust-region (e.g., KL) constraints to obtain TRPO-like monotonic improvement guarantees for diffusion policies.
- Decoding-order and sampler flexibility: empirically validate that DiPOD preserves the claimed non-autoregressive sampling flexibility by testing multiple decoding orders and inference budgets; quantify any degradation vs. pretraining.
- Long-context scaling for reasoning: the paper attributes limited math gains to context length bottlenecks; directly test DiPOD with longer contexts, hierarchical CoT, or chunked decoding to disentangle optimization from capacity limits.
- Reward misspecification and verifier noise: analyze how ELBO regularization interacts with noisy or imperfect verifiers/reward models; determine whether tighter bounds reduce or exacerbate reward hacking.
- Generality beyond diffusion: the paper posits applicability to other VI policies (e.g., VAEs); validate with controlled experiments and theory on latent-variable policies to test whether “tighten-the-bound to prevent gradient drift” transfers.
- Continuous-control interleaving: develop and evaluate fully interleaved self-distillation+policy-update schedules for flow-control tasks (not just an initial distill step), including measurements of on-policy gap and stability under high-dimensional dynamics.
- Scheduling criteria and stopping rules: propose principled criteria for how long to self-distill, when to refresh the reference policy, and when to stop tightening (e.g., gap plateaus, KL thresholds, or reward-improvement stalls).
- Compatibility with clipping and baselines: analyze interactions between ELBO regularization and PPO/GRPO clipping, advantage normalization, and value baselines; identify conditions where these components synergize or conflict.
- Negative-result regimes: identify regimes where bound-tightening competes with reward maximization (e.g., highly nonstationary rewards, sparse rewards, or rapidly shifting advantage landscapes) and propose mitigations.
- Diversity–fidelity trade-off: quantify how pushing toward tight bounds affects sample diversity vs. reward-aligned fidelity in text and control, and design multi-objective training schemes to balance them.
- Benchmarks and coverage: extend evaluations to more diverse reasoning tasks (code, proofs, long-form QA), more motion primitives and terrains, and different diffusion LLM backbones to test robustness of the observed gains.
- Monitoring and interpretability tools: create tooling to visualize double drift (proxy vs. true gradient surrogates) during training, even when likelihood is intractable, to help practitioners intervene before instability emerges.
- Safety and calibration: evaluate whether ELBO-regularized diffusion policies maintain calibration, truthfulness, and constraint adherence under RL pressure; assess if tightness helps or harms safety properties.
Practical Applications
Overview
The paper introduces DiPOD (Diffusion Policy Optimization without Drifting Apart), a practical framework for reinforcement learning (RL) post-training of diffusion and flow policies that stabilizes training by preventing a “double-drift” failure mode: (1) the evidence bound (e.g., ELBO) drifts away from the true log-likelihood, and (2) the resulting proxy policy gradient drifts from the true policy gradient. The key innovation is to interleave (or approximate) on-policy self-distillation with policy-gradient updates, yielding a simple drop-in algorithmic change: add an on-policy ELBO regularizer to each diffusion policy-gradient step.
Below are actionable applications derived from the paper’s findings, methods, and innovations. They are grouped by deployment horizon and linked to sectors with suggested tools, products, or workflows. Each item notes assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed now using the paper’s “drop-in” ELBO-regularized update with existing diffusion policy-gradient methods (e.g., FPO, SPG). Public code is provided.
- Diffusion LLM post-training stabilization for reasoning-intensive tasks
- Sector: Software, Education, Research
- Use cases:
- Improve math and logic reasoning for diffusion LLMs (dLLMs) in tutoring apps, study aids, and coding assistants (e.g., math word problems like GSM8K, puzzles like Sudoku, Countdown-style combinatorics).
- Fine-tune dLLMs for enterprise QA or analytical assistants where step-by-step reasoning quality matters (e.g., financial or legal document reasoning prototypes—non-safety-critical).
- Tools/workflows:
- Integrate DiPOD as a plug-in module to your existing RL post-training pipeline (GRPO/PPO variants with diffusion LMs): add an ELBO gradient term with coefficient β per policy update.
- Monitor and log on-policy ELBO–likelihood gap proxies and reward dynamics; use early stopping or β-tuning when gaps increase.
- Combine with FPO or SPG (as shown) by simply augmenting the gradient step with the ELBO term.
- Assumptions/dependencies:
- Availability of a tractable ELBO estimator for the diffusion LM, and an adequate policy-gradient estimator (e.g., FPO/SPG).
- Quality reward/advantage estimates (e.g., verifiers, rule-based rewards) and sufficiently strong pretrained diffusion LM initialization (tight bound at start).
- Compute overhead is manageable (extra ELBO gradient per batch).
- Robotics and animation motion tracking stabilization
- Sector: Robotics, Media/Entertainment, AR/VR
- Use cases:
- More stable RL training for humanoid motion tracking in simulation (e.g., character animation retargeting, motion imitation for games and virtual production).
- Prototype better policy optimization for diffusion/flow-based robot controllers before sim-to-real transfer.
- Tools/workflows:
- Add an initial self-distillation stage to tighten the bound, followed by standard FPO++ (or FPO/SPG) training augmented with on-policy ELBO regularization.
- Track mean episode length and reward curves; adjust β to keep bound tightness and prevent gradient drift.
- Assumptions/dependencies:
- Requires flow/diffusion policy architecture with tractable ELBO and an adequate gradient estimator (e.g., FPO++).
- Simulation fidelity and reward function shaping dominate real-world effectiveness; sim-to-real transfer remains a separate challenge.
- Research tooling for reliable VI-based RL with generative policies
- Sector: Academia, ML Infrastructure
- Use cases:
- Establish “tight-bound tracking” as a standard diagnostic when using VI-based surrogates (ELBO/EUBO) in RL for generative policies (diffusion, VAE-like models).
- Benchmarking frameworks that report both reward and bound tightness to avoid proxy over-optimization and “cheating via discrepancy.”
- Tools/workflows:
- Instrument existing RL code to log ELBO gradients, proxy–likelihood gap measures (or proxies), and correlate with policy-improvement steps.
- Add interleaved or per-batch ELBO regularization as a default baseline in ablations.
- Assumptions/dependencies:
- Access to models where ELBO is computable and improves with self-distillation.
- Realizability and smoothness assumptions hold approximately (as in the paper).
- Production-friendly RL post-training pipelines for diffusion systems
- Sector: Software, Cloud/ML Platforms
- Use cases:
- Reduce hyperparameter brittleness and training instability of masked/diffusion LMs in RL post-training, lowering operational risk and retraining costs.
- Introduce guardrails that prevent reward hacking via variational-gap exploitation.
- Tools/workflows:
- Provide a “DiPOD switch” in training orchestration: per-step ELBO regularization with user-configurable β and schedules; dashboards tracking tightness and reward.
- Canary evaluations on standard benchmarks (e.g., GSM8K subset, internal reasoning suites) to validate stability before full-scale runs.
- Assumptions/dependencies:
- Organizational willingness to add a regularizer and monitoring to existing pipelines; mild compute overhead acceptance.
- Domain-appropriate rewards and safety checks (e.g., for enterprise data).
Long-Term Applications
These require further research, scaling, or domain validation. They build on the paper’s principle—maintaining tight evidence bounds to preserve gradient fidelity—across broader systems and sectors.
- General-purpose diffusion agents with safer RL post-training
- Sector: Cross-sector (Software, Safety, Governance)
- Potential:
- Apply DiPOD-style tightness maintenance to large-scale preference optimization for diffusion LMs (RLHF/RLAIF analogs) to reduce proxy exploitation and produce more reliable behavior.
- Use bound-tightness metrics as part of compliance or model quality gates for generative AI deployments.
- Dependencies/assumptions:
- Robust, scalable reward/preference models; tractable ELBO for larger, multimodal diffusion architectures.
- Empirical correlation between tightness metrics and downstream safety-alignment outcomes must be validated.
- Multimodal diffusion agents for robotics and embodied AI
- Sector: Robotics, Manufacturing, Logistics, Home Assistance
- Potential:
- Stable post-training of vision-language-action diffusion policies for complex tasks (e.g., multi-step household assistance, warehouse manipulation).
- Interleaved self-distillation schedules that preserve sampler flexibility while guaranteeing local policy improvement.
- Dependencies/assumptions:
- High-quality on-policy self-distillation in the loop with partial observability; reliable reward definitions for long-horizon tasks.
- Sim-to-real transfer methods and safety layers for physical deployment.
- Control in cyber-physical systems with diffusion policies
- Sector: Energy, Smart Buildings, Mobility
- Potential:
- Use diffusion/flow policies in model-free RL controllers for HVAC, microgrids, or traffic signal control, with DiPOD reducing instability from variational proxies.
- Long-horizon planning policies where sampler flexibility is valuable (variable inference budgets, non-autoregressive decoding).
- Dependencies/assumptions:
- High-fidelity simulators or safe online learning frameworks; domain constraints and safety envelopes.
- Verifiable reward functions and failure-safe policies.
- Domain-specific reasoning assistants in regulated industries
- Sector: Finance, Law, Healthcare (non-diagnostic workflows)
- Potential:
- Post-train dLLMs to follow structured reasoning templates (e.g., audit trails in finance, evidence citation in law) with reduced instability and fewer degenerate updates.
- Combine with verifiers to shape rewards and maintain coherence during RL.
- Dependencies/assumptions:
- Strongly validated reward models, compliance audits, and rigorous red-teaming; ELBO tractability for domain models.
- For healthcare: limit to non-clinical, informational tasks unless medically validated.
- Extensions to other variational generative policies
- Sector: ML Research, Tooling
- Potential:
- Apply the “tighten-the-bound” principle to VAEs and other latent-variable models used as policies, making RL feasible where likelihood is intractable but ELBO exists.
- Develop EUBO approximations with tightness controls to complement ELBO, improving negative-advantage handling.
- Dependencies/assumptions:
- Adequate estimators and tractable (or accurately approximated) variational bounds; theoretical guarantees beyond diffusion/flow families.
- Empirical validation across tasks with different discrepancy structures.
Notes on Assumptions and Dependencies
- Adequate estimator requirement: DiPOD relies on gradient estimators that match the true policy gradient in the tight-bound regime (e.g., FPO, SPG, FPO++).
- Tractable ELBO: The on-policy ELBO must be computable for the diffusion/flow policy. EUBO remains less tractable and may require approximations.
- Initialization matters: Benefits are strongest when starting from a well-trained diffusion model (ELBO ≈ log-likelihood).
- Reward design and verifiers: Gains depend on reliable advantage estimates; poor rewards can still lead to mis-optimization.
- Compute overhead: The extra ELBO gradient per update adds cost; β must be tuned to balance stability and progress.
- dLLM constraints: Fixed context windows and decoding budgets can limit absolute reasoning performance; DiPOD improves stability but does not remove modeling limits.
- Robotics-specific: Sim-to-real gaps, hardware safety, and long-horizon credit assignment remain primary challenges independent of DiPOD.
By offering a simple, drop-in ELBO regularizer that preserves tightness on-policy, DiPOD enables practitioners to stabilize RL post-training for diffusion policies today, while opening the door to broader, safer deployment of diffusion-based agents across sectors in the longer run.
Glossary
- Adequate estimator: A gradient estimator that matches the true policy-gradient integrand when the evidence bound is tight. "A gradient estimator is called adequate"
- Advantage function: The signal estimating how much better an action is than a baseline at a given timestep. "where is the estimated advantage function at timestep ."
- Autoregressive: A modeling/decoding style where tokens are generated sequentially, each conditioned on previous ones. "reasoning gains to lag far behind those of autoregressive counterparts."
- Conditional flow matching (CFM): A training objective for flow models aligning a learned conditional vector field with a target conditional vector field. "For flow models trained by conditional flow matching (CFM)"
- Denoising chain: The sequence of denoising steps used by diffusion models, which can be framed as an MDP. "Treating the denoising chain as an MDP makes likelihoods tractable"
- Diffusion LLM (dLLM): A LLM based on diffusion processes rather than autoregressive generation. "diffusion LLMs have emerged as a promising alternative to autoregressive models for fast and flexible decoding"
- Diffusion policy-gradient methods: Policy-gradient algorithms adapted to diffusion policies using likelihood proxies. "existing diffusion policy-gradient methods are often unstable"
- ELBO (Evidence Lower Bound): A tractable lower bound on log-likelihood used as a surrogate objective in variational inference. "The evidence lower bound (ELBO) satisfies"
- ELBO regularizer: An additional ELBO term added to policy updates to tighten the bound on-policy and stabilize learning. "augmenting each diffusion policy-gradient update with an on-policy ELBO regularizer."
- EUBO (Evidence Upper Bound): An upper bound on log-likelihood used alongside ELBO to sandwich the true likelihood. "The evidence upper bound (EUBO) satisfies"
- Evidence bound: A variational upper or lower bound that approximates the intractable log-likelihood. "Variational-inference (VI) approaches instead replace with evidence bounds such as ELBO~\citep{mcallister2025flow} or EUBO~\citep{wang2025spg}"
- Expected return: The cumulative reward objective optimized by reinforcement learning. "maximizes the expected return in an environment."
- Flow model: A generative model based on continuous-time transformations with learned vector fields. "flow models more broadly support strong performance in continuous domains"
- FPO (Flow Matching Policy Gradients): A method that substitutes the intractable likelihood score with an ELBO-based score in policy gradients. "FPO replaces the intractable likelihood score in the policy-gradient update with an ELBO score."
- GRPO: A practical policy-gradient-style algorithm used in modern language-model post-training. "Well-known practical algorithms such as PPO~\citep{schulman2017proximal} and GRPO~\citep{shao2024deepseekmath}"
- KL discrepancy: The Kullback–Leibler-based measure of divergence appearing as the ELBO’s variational gap. "can be interpreted as a KL discrepancy between posterior distributions"
- Log-likelihood: The logarithm of the probability assigned by the model to observed actions, central to policy-gradient updates. "standard policy-gradient methods rely on the log-likelihood "
- MDP (Markov Decision Process): A formal framework for sequential decision-making; used here to model the denoising process. "Treating the denoising chain as an MDP makes likelihoods tractable"
- Non-autoregressive decoding: Generating multiple tokens without strictly left-to-right dependency, enabling flexible orders. "flexible non-autoregressive decoding"
- On-policy: Using data sampled from the current (or reference) policy’s distribution during training. "on-policy ELBO regularizer"
- Policy gradient: Methods that update policy parameters in the direction of the gradient of expected return. "Policy-gradient methods directly optimize a parameterized policy for expected return"
- Policy-preserving: An operation (e.g., self-distillation) that tightens bounds without changing the policy’s action distribution. "a policy-preserving self-distillation step"
- PPO (Proximal Policy Optimization): A stabilized policy-gradient method using clipped objectives. "Well-known practical algorithms such as PPO~\citep{schulman2017proximal} and GRPO~\citep{shao2024deepseekmath}"
- Proxy policy gradient: A gradient computed from a surrogate of log-likelihood, which can misalign if the bound is loose. "proxy policy gradient misaligned with the true policy gradient of expected return."
- Renyi-type posterior discrepancy: A divergence measure of Rényi type used to characterize EUBO’s discrepancy. "characterized by a Renyi-type posterior discrepancy."
- Rollout: A sampled trajectory or batch of observations and actions used for gradient updates. "for each batch of rollouts"
- Sandwiched Policy Gradient (SPG): A method using ELBO for positive advantages and EUBO for negative, to bound the objective from both sides. "SPG explicitly targets an objective that mirrors the policy-gradient structure by using ELBO for positive advantages and EUBO for negative advantages."
- Self-distillation: Training the model to better match its own induced targets to tighten evidence bounds without changing behavior. "interleaving self-distillation with policy-improving gradient updates."
- Tight-bound regime: The training region where evidence bounds closely match true log-likelihood, making proxy gradients reliable. "training stays near the tight-bound regime."
- Variational gap: The difference between the evidence bound and the true log-likelihood (i.e., the ELBO discrepancy). "Variational gap during FPO, SPG, and DiPOD training."
- Variational inference (VI): A framework that optimizes tractable bounds to approximate intractable posteriors or likelihoods. "Variational-inference (VI) approaches"
Collections
Sign up for free to add this paper to one or more collections.

