A2D2: Fine-Tuning Any-Length Discrete Diffusion for Adaptive Decoding
Abstract: Discrete diffusion models offer a simple and stable likelihood-based framework for sequence generation, recently extended to any-length settings via token insertion. Principled reward-guided fine-tuning for any-length discrete diffusion, however, remains largely unexplored. We introduce Fine-Tuning Any-Length Discrete Diffusion for Adaptive Decoding (A2D2), a unified framework for reward-guided fine-tuning of any-length discrete diffusion models via joint optimization of the insertion and unmasking policies together with a quality-based inference schedule. We derive the Radon-Nikodym derivative for the joint insertion-unmasking path measures, enabling theoretically guaranteed convergence to the intractable reward-tilted sequence distribution without requiring target samples. Building on this, we establish unmasking and insertion quality as tractable approaches for minimizing decoding error and introduce the Adaptive Joint Decoding (AJD) loss, which provably yields the optimal path measure that generates the reward-tilted distribution. Empirically, A2D2 improves reward optimization while enhancing generation flexibility and accuracy over prior fixed-length fine-tuning and inference-time guidance methods.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1) What is this paper about?
This paper introduces A2D2, a way to train and use a kind of AI generator (called an “any-length discrete diffusion model”) so it can:
- Make sequences of symbols (like text, molecules, or peptide strings) that can grow or shrink in length while being generated.
- Aim for specific goals (rewards), like “be more drug-like” for molecules or “solve the math problem correctly” for text.
- Keep generation high-quality and efficient by checking which parts of its guesses are reliable and which aren’t, then fixing the weak parts on the fly.
In short, A2D2 helps a flexible sequence generator learn to produce higher-scoring, higher-quality results by adapting as it decodes.
2) What questions were the researchers trying to answer?
They focused on one big question:
- Can we fine-tune any-length diffusion models so they prefer high-reward outputs, without hurting the overall quality and while staying efficient?
To do that, they needed to solve sub-questions:
- How do we decide which parts of a partial sequence are trustworthy and which should be changed?
- How do we train the model so it learns from both good examples and good rewards, even when it proposes many changes at once?
- How do we combine adding new spots (insertions) and filling in missing spots (unmasking) in a smart, reliable way?
3) How did they do it? (Methods in simple terms)
Think of building a sentence or a molecule like completing a puzzle:
- You start with blanks (masked tokens).
- At each step, you can reveal some blanks (unmasking) or add new blanks where needed (insertion), then fill them.
- Doing many reveals or insertions at once can cause mistakes if pieces depend on each other. A2D2 tries to do this in parallel but safely.
Here are the main ideas, explained with everyday analogies:
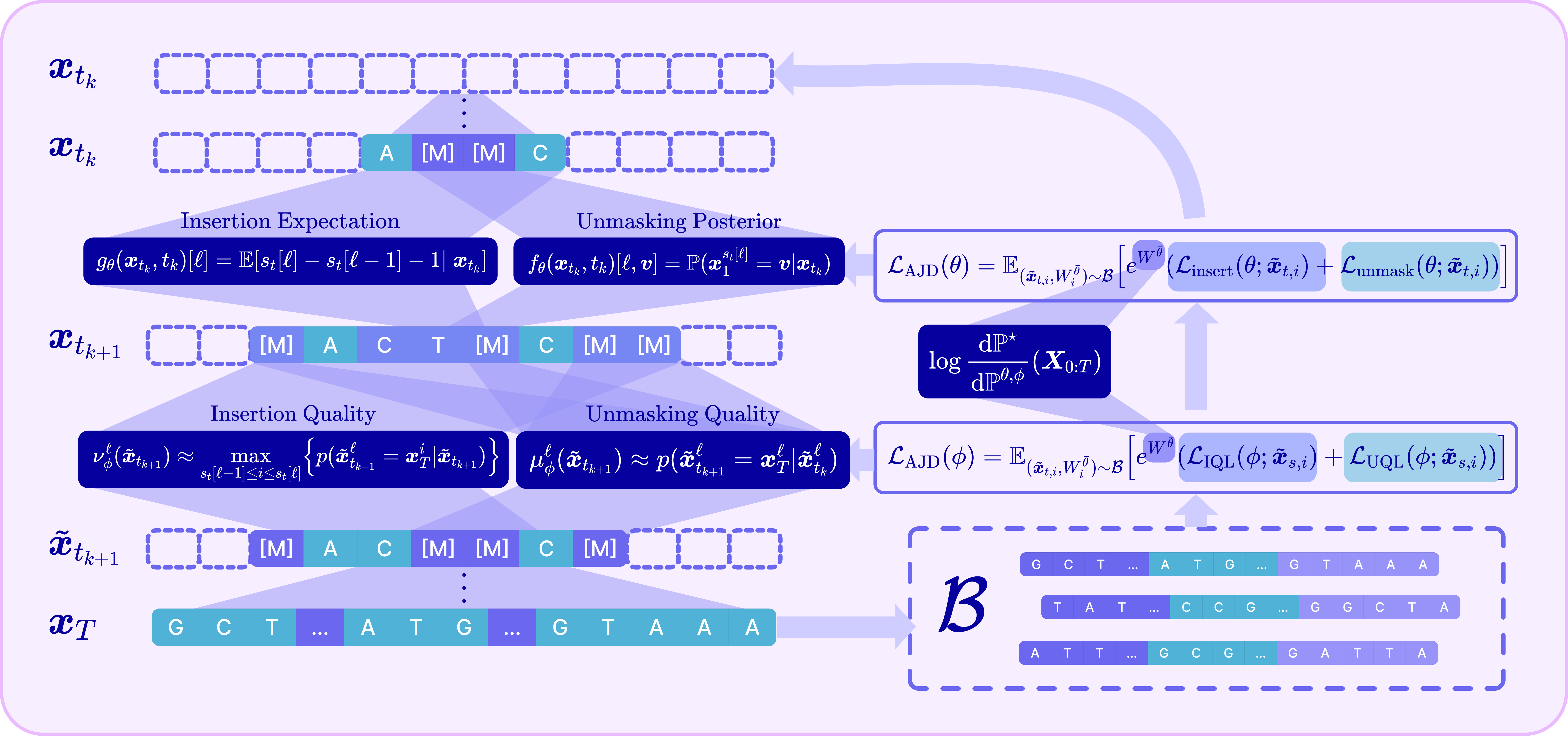
- Any-length diffusion model:
- Instead of generating left-to-right one token at a time, the model can jump around: add new slots where needed (insertion) and reveal the right symbols for masked slots (unmasking).
- This makes it flexible: sequences can grow or shrink to the right length.
- Quality checks for safer parallel steps:
- Unmasking quality: Imagine you reveal a letter in a crossword. How confident are we that this letter fits with the rest of the puzzle? The model learns a “quality score” for each revealed token. If the score is low, it re-masks (hides) it and tries again later.
- Insertion quality: When adding new empty slots to fill later, how likely is it that a correct symbol belongs there? If an insertion looks unhelpful, the model removes it.
- These quality checks reduce “compounding parallelization error,” which is the extra error you get when changing many things at once instead of one-by-one.
- Training with rewards (learning to prefer better outcomes):
- The model doesn’t just copy data; it also tries to score higher on chosen goals (e.g., molecule drug-likeness, peptide properties, math correctness).
- They use a mathematical “reweighting” trick (you can think of it like giving more importance to better examples) so the model learns from samples that are both likely under the pre-trained model and high-scoring under the reward.
- They combine everything into a single training objective called the Adaptive Joint Decoding (AJD) loss. “Adaptive” refers to using those quality scores to guide what to trust or redo; “Joint” refers to handling both insertions and unmaskings together.
- How they fine-tune and decode:
- Off-policy RL: They collect generated sequences into a replay buffer (like a practice notebook), score them, reweight them by quality and reward, and then update the model.
- Alternating updates: They take turns training the main generator (“policy”) and the quality heads, which keeps training steady.
- Adaptive inference: At generation time, they propose changes, score the quality of each change, keep the good ones, and discard or redo the bad ones. This leads to cleaner, more accurate sequences without slow search.
4) What did they find?
Across three areas, A2D2 improved results meaningfully:
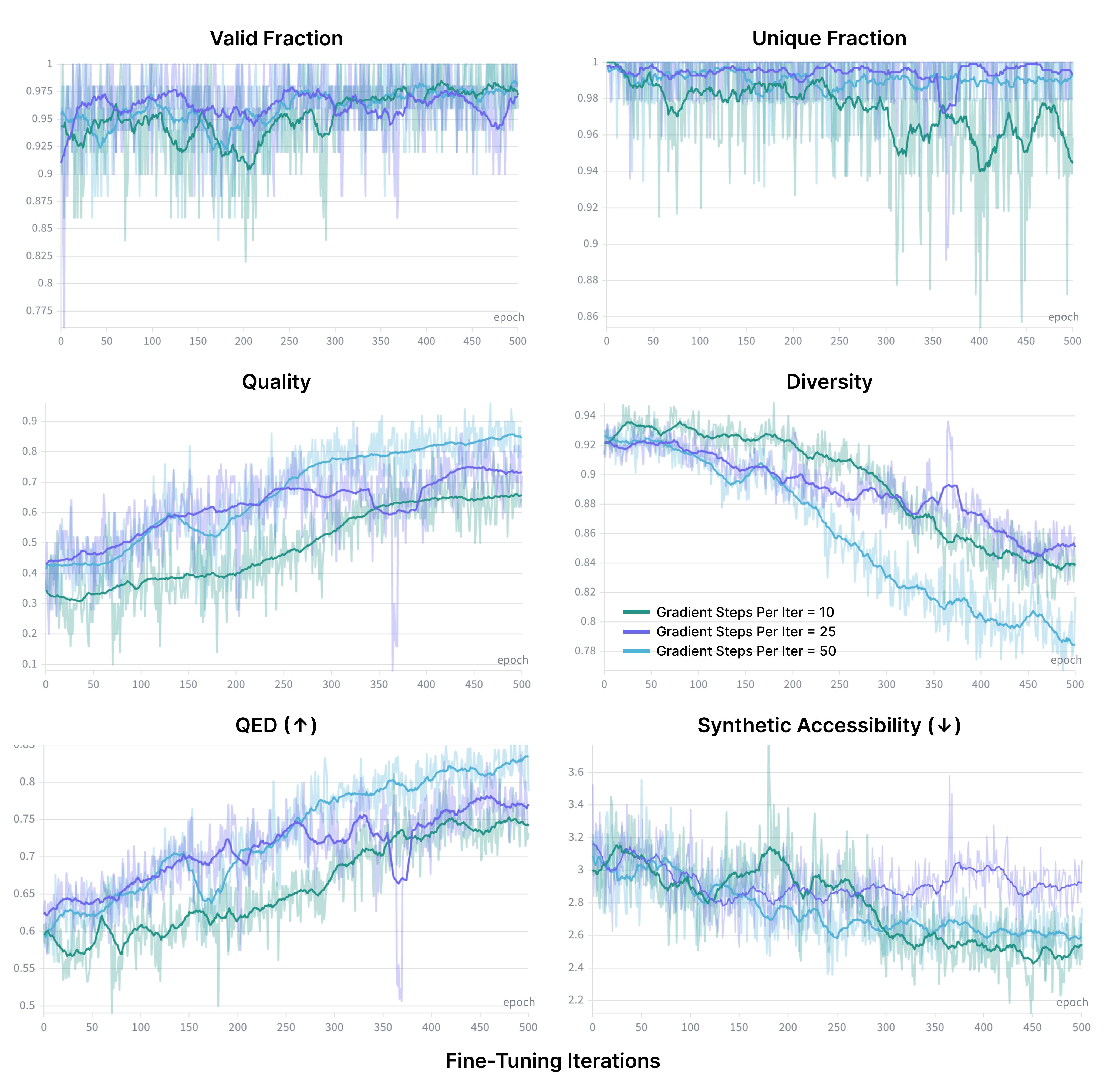
- Drug-like small molecule design:
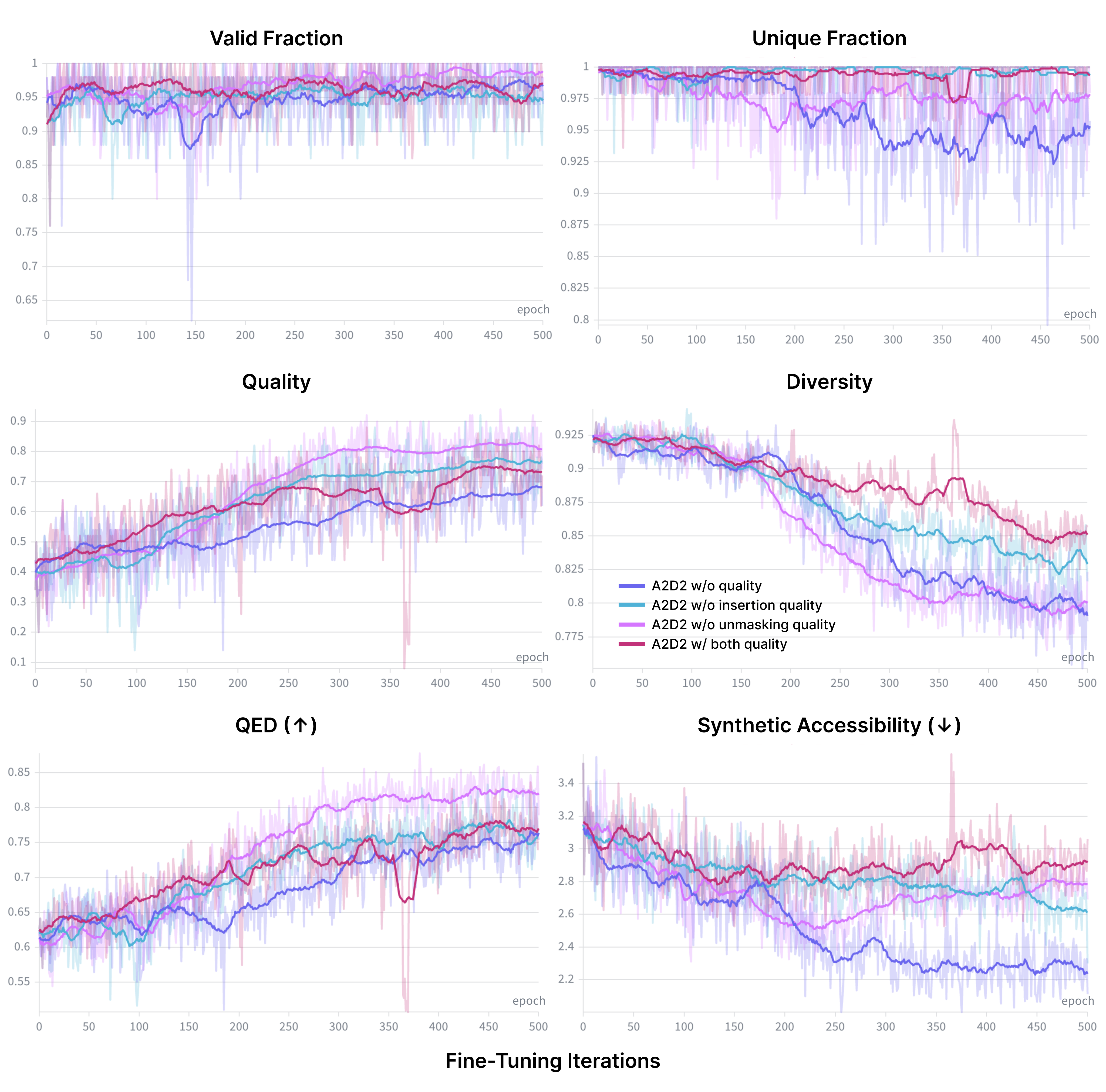
- A2D2 improved overall “quality” (valid, unique, drug-like, synthesizable) compared to the same model before fine-tuning.
- It increased a standard drug-likeness score (QED) and reduced synthetic difficulty (SA).
- It approached the performance of a strong fixed-length baseline while being more flexible (it can change sequence length).
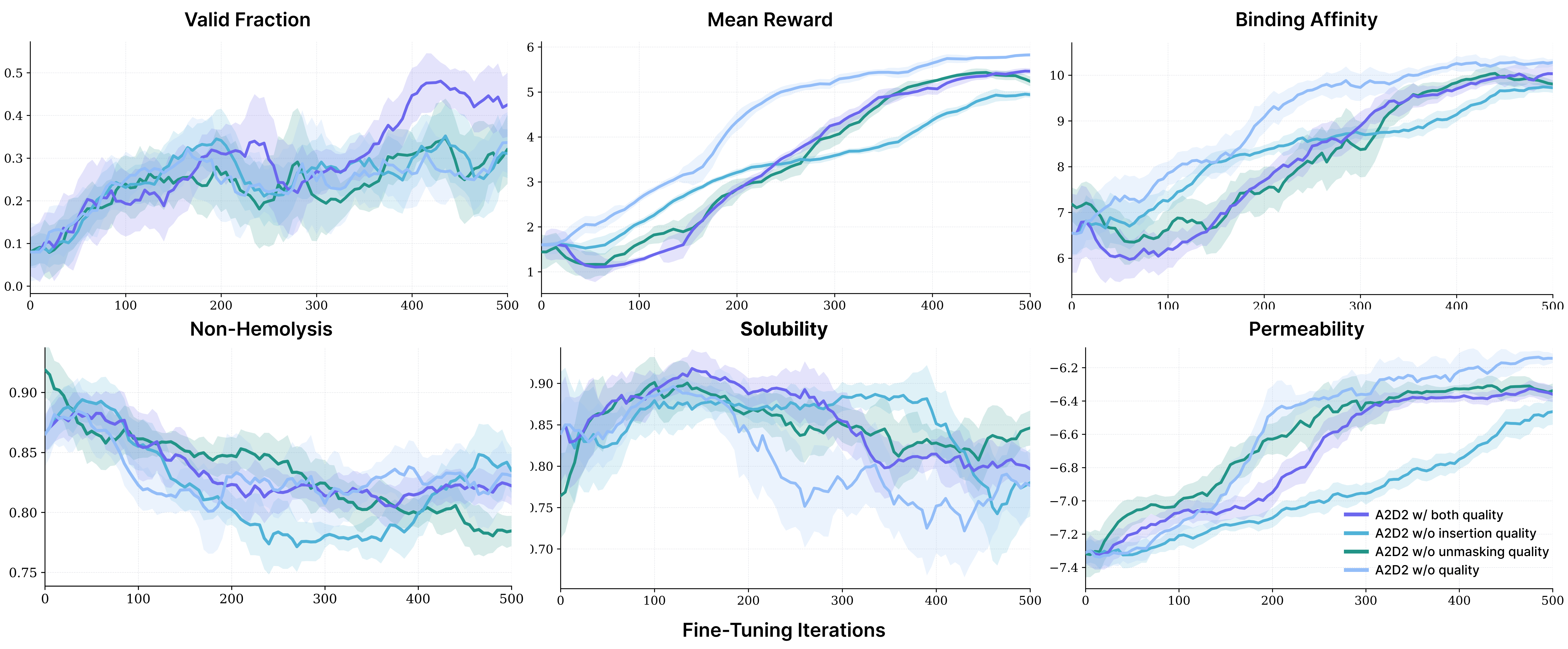
- Multi-objective therapeutic peptide generation:
- A2D2 boosted multiple properties at once (e.g., binding to target proteins, solubility, permeability).
- Adding the quality checks greatly improved validity (the fraction of decodable, correct peptide sequences), reaching higher validity than all baselines they compared against.
- It outperformed fixed-length methods that needed heavier guidance or more expensive search.
- Language reasoning (math word problems; also evaluated code infilling):
- On GSM8K (a math dataset), adding A2D2 on top of an instruction-tuned model raised accuracy (Pass@1) from about 41% to about 61% with moderate sampling steps—quite a jump.
- They also evaluated code infilling; A2D2 is designed to help here by flexibly inserting and refining tokens, though the paper highlights the biggest gains on math.
Why this matters:
- These are hard problems where you often need to add, remove, or reorder tokens. A2D2’s “any-length + quality checks + reward learning” combo gives big gains without slow, expensive search at inference time.
5) Why does this matter? (Implications and impact)
- Flexible generation you can trust: Many tasks need changing sequence length on the fly (molecules, peptides, code edits, reasoning steps). A2D2 makes that flexible process more reliable by keeping only high-quality changes as you go.
- Better use of rewards: It turns “optimize for what we care about” into a practical training signal, so models learn to produce not just likely outputs, but useful ones.
- Faster and more scalable: By reducing errors that come from doing many things in parallel, A2D2 keeps generation efficient—no heavy search loops required.
- Broad applications: The same approach helps in biology (designing drug-like molecules and therapeutic peptides) and in language (math and code), and could be extended to other structured generation problems.
In a sentence: A2D2 teaches a flexible, insert-and-reveal generator to aim for what we want (rewards) while constantly checking and improving its own steps, leading to higher-quality, higher-reward sequences across very different domains.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored and where further research is needed:
- Independence assumptions in theory: Key propositions assume conditional independence among parallel unmaskings and inserted masks; quantify the impact when this assumption fails and develop bounds or corrections for realistic dependencies.
- Compounding parallelization error (CPE): The paper motivates unmasking/insertion quality via CPE but does not measure CPE empirically or show that quality-guided decoding reduces it; establish metrics and empirical validation.
- Radon–Nikodym derivative normalization: Clarify the treatment of the normalizing constant in the importance weights (whether includes ); verify that -estimation and self-normalization are consistent and unbiased.
- Importance sampling variance: Characterize variance/ESS of the trajectory weights , sensitivity to policy mismatch, and introduce variance reduction (e.g., clipping, control variates, baselines, stratification).
- Absolute continuity and coverage: State and test conditions under which holds in any-length settings (variable state spaces), and devise diagnostics when coverage fails.
- Discretization bias of the CTMC: The algorithm simulates a time-inhomogeneous CTMC via discrete steps with parallel events; quantify discretization error and its effect on convergence to the reward-tilted path measure.
- Integral term in the RND: The continuous-time integral over rate differences appears in the log-RND; specify its numerical approximation and analyze the induced bias/variance.
- Training–inference mismatch for insertions: is trained via a Bregman divergence on expected counts but sampled as Poisson at inference; assess calibration of , and test alternative count models or calibrated sampling.
- Quality predictor targets depend on the model: Insertion quality labels sum probabilities from (self-referential target), risking propagation of miscalibration; study calibration, detachment, ensembles, or teacher models to mitigate bias.
- Gradient leakage in quality training: Clarify whether targets from are stop-gradient during training; quantify effects if not, and test stabilization strategies.
- Thresholding strategy for adaptive decoding: Provide a principled procedure for setting/removing thresholds for re-masking/removal (e.g., via calibrated risk, target CPE, or learned schedules) and analyze sensitivity.
- Termination guarantees: Re-masking/removal could yield oscillations or non-termination; provide guarantees or bounding strategies and measure how termination criteria shape the induced distribution.
- Replay buffer design: Explore buffer size, staleness control, prioritized sampling, and off-policy corrections; quantify their effects on stability, bias, and sample efficiency.
- Alternating optimization schedule: The choice of and is heuristic; analyze convergence/stability vs. schedule, and propose adaptive alternation rules.
- Reward aggregation in multi-objective tuning: Specify how multiple objectives are combined into (weights, normalization, dynamic scheduling) and study Pareto-front exploration vs. scalarization sensitivity.
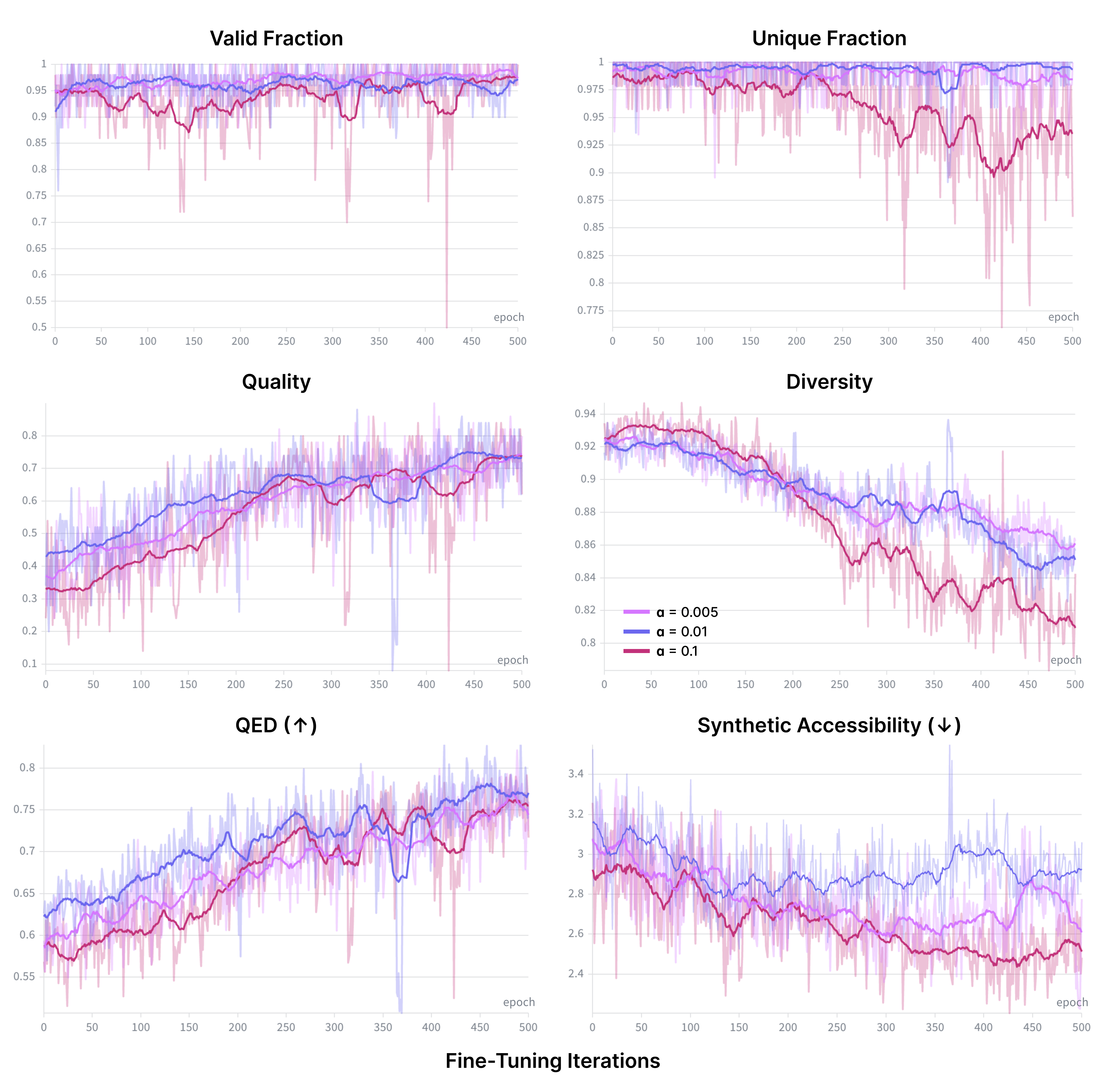
- Choice of tilt temperature : No ablation or adaptive selection is provided; characterize its effect on reward–diversity trade-offs and propose methods to set or learn .
- Diversity preservation: Uniqueness drops in some settings without quality guidance; develop explicit diversity regularization (entropy/coverage constraints, KL to pretrain) and evaluate trade-offs.
- Robustness to reward misspecification: Analyze susceptibility to reward hacking and oracle error (biophysical predictors, property regressors), and incorporate uncertainty-aware or adversarial defenses.
- Validity as a constraint vs. reward: Investigate constrained optimization (e.g., validity/syntax as hard constraints in the path measure) vs. soft rewards to prevent wasteful sampling and mis-optimization.
- Length distribution control: Quantify how any-length decoding alters length distributions, accuracy of length targeting, and provide mechanisms to control or regularize length.
- Computational efficiency: Benchmark end-to-end sampling speed, memory, and wall-clock vs. fixed-length baselines and confidence heuristics; measure overhead from computing and quality scores.
- Effect of adaptive re-masking/removal on parallelism: Assess how quality-based steps reduce effective parallelism and throughput; propose batching/compaction schemes to recover speed.
- Language evaluation depth: Extend beyond GSM8K/HumanEval-infill, include more reasoning/code datasets, stronger baselines, and analyze why performance degrades at larger sampling steps.
- Generalization and OOD robustness: Test transfer to out-of-distribution sequences, long-context regimes, and unseen vocabularies; study failure modes.
- Function approximation limits: State conditions under which the AJD loss’s unique minimizer is realizable with finite-capacity ; provide approximation/error bounds.
- Comparative baselines: Evaluate against alternative reward-optimization frameworks for discrete generation (e.g., GFlowNets, edit-based PG methods, DAGGER-like training) in any-length settings.
- Safety/biological realism: For molecules/peptides, include additional safety/ADMET/toxicity constraints and structural validation; test for spurious correlations or unrealistic chemistries.
- Reproducibility at scale: Provide details on pretraining compute/data subsampling, checkpoint release, and low-resource regimes; study how A2D2 behaves when pretraining is small-scale.
- Joint policy–quality learning dynamics: Analyze interactions/conflicts between insertion and unmasking quality heads during adaptive decoding, and whether joint optimization can get stuck in suboptimal regimes.
- CPE-aware scheduling: Move beyond static thresholds to explicitly optimize a schedule that targets minimal CPE per step using predicted qualities; evaluate against heuristic schedules.
Practical Applications
Below are practical applications of the A2D2 framework—any-length masked discrete diffusion fine-tuned via Adaptive Joint Decoding, with quality-based adaptive decoding—organized by immediacy and linked to sectors. Each item lists potential tools/products/workflows and key assumptions/dependencies that affect feasibility.
Immediate Applications
- Drug-like small-molecule generation and triage (Healthcare, Pharma)
- What: Use A2D2 to generate valid, unique, and more drug-like molecules (e.g., higher QED, lower SA) with parallel decoding for low latency in virtual screening.
- Tools/Products/Workflows: Integrate with RDKit for sanitization and fingerprints; use QED/SA as reward models; plug into existing in silico pipelines for lead exploration and fragment elaboration; deploy replay-buffer fine-tuning with AJD and importance weighting; enable quality-gated decoding to retain diversity.
- Assumptions/Dependencies: Availability/accuracy of reward models (QED/SA are proxies); pre-trained any-length MDM checkpoints; compute for off-policy RL; robust chemical validity checks; safety filters to avoid hazardous compounds.
- Multi-objective peptide design (Healthcare, BioTech)
- What: Optimize binding affinity, solubility, hemolysis, fouling, permeability simultaneously without expensive inference-time search, while increasing valid peptide rates.
- Tools/Products/Workflows: Use property predictors as rewards; SMILES2PEPTIDE or equivalent for validity; A2D2 fine-tuning with alternating updates for policy and quality heads; deploy quality-based adaptive insertion/unmasking for higher validity and decoding accuracy; Pareto-front construction in downstream ranking.
- Assumptions/Dependencies: Predictor reliability and domain shift; pre-trained any-length peptide SMILES model; wet-lab validation for top candidates; compliance with dual-use/biosecurity policies.
- Replacement of expensive inference-time guidance with training-time optimization (Cross-domain)
- What: Swap Monte Carlo/tree-based guidance with AJD fine-tuning to match or surpass reward performance at lower inference cost.
- Tools/Products/Workflows: A2D2 training loop with replay buffer; track cross-entropy weights via Radon–Nikodym reweighting; deploy adaptive decoding at inference.
- Assumptions/Dependencies: Stable importance weighting (variance control, clipping); adequate replay sampling; well-calibrated rewards; monitoring for mode collapse.
- IDE-assisted code infilling with quality-gated edits (Software)
- What: Improve correctness of code infill/patches by allowing insertions anywhere and re-masking low-quality tokens; couple decoding with unit tests as rewards.
- Tools/Products/Workflows: Language Server Protocol (LSP) plugins for VS Code/JetBrains; integrate compilers/linting/unit tests as reward functions; adopt AJD fine-tuning and adaptive decoding; fallback to test-driven filters.
- Assumptions/Dependencies: Pre-trained any-length code MDMs (or adapted fixed-length backbones with insertion heads); high-quality test suites; guardrails for unsafe code; compute budget for test execution.
- Math reasoning tutors with stepwise insertion (Education)
- What: Generate chain-of-thought steps with insertions/revisions guided by quality predictors to reduce compounding errors; provide adaptive explanations.
- Tools/Products/Workflows: Fine-tune on math datasets (e.g., GSM8K) with reward shaping for correctness; deploy classroom or tutoring chat interfaces; log quality metrics to select which intermediate steps to reveal.
- Assumptions/Dependencies: Availability of datasets and automatic verifiers; managing hallucination risk; pedagogical alignment; privacy policies for student data.
- Parallel decoding acceleration with quality control (Software, Infrastructure)
- What: Maintain or improve accuracy while benefiting from parallel decoding in discrete diffusion by remasking low-quality tokens/masks to reduce compounding parallelization error.
- Tools/Products/Workflows: Scheduler that uses per-token quality thresholds; dynamic batch sizing for parallel steps; integrate into existing diffusion sampling libraries.
- Assumptions/Dependencies: Calibration of quality heads; careful threshold selection; monitoring for throughput–quality trade-offs.
- Dataset augmentation with higher-validity sequences (Academia, Industry R&D)
- What: Generate diverse, valid molecules/peptides/text snippets to augment datasets for QSAR modeling, property prediction, or pretraining.
- Tools/Products/Workflows: A2D2 fine-tuned generators producing balanced augmentations; ensure deduplication and novelty checking; automated property annotations.
- Assumptions/Dependencies: Distribution alignment to avoid dataset shift; careful curation to prevent label noise; IP/data licensing constraints.
- RL fine-tuning toolkit for any-length discrete diffusion (Software Tools, Academia)
- What: Package AJD, RND-based importance reweighting, replay buffers, and alternating optimization into a reusable library for sequence design tasks.
- Tools/Products/Workflows: Open-source Python library; hooks for domain reward models; standard training recipes and diagnostics.
- Assumptions/Dependencies: Community adoption; maintenance of reproducibility; safe defaults for weight variance control.
- Safer generative chemistry through negative rewards (Policy, Compliance, Healthcare)
- What: Incorporate toxicity/disallowed motif predictors as negative rewards to reduce generation of harmful chemistries.
- Tools/Products/Workflows: Tox21/toxicity classifiers, PAINS filters; integrated safety gates; audit logs of reward contributions; pre-deployment red-teaming.
- Assumptions/Dependencies: Predictor coverage and false-negative rates; evolving regulatory guidance; cross-organization governance.
- Structured text editing assistants (Productivity, Daily Life)
- What: Editors that insert citations, definitions, or clarifications anywhere in a document with quality-based acceptance of suggestions, improving coherence without heavy beam search.
- Tools/Products/Workflows: Word processor plugins; citation databases as reward signals; style/grammar checkers incorporated as rewards.
- Assumptions/Dependencies: Pre-trained any-length language MDM; accurate citation/linking tools; privacy and security for document content.
Long-Term Applications
- End-to-end AI-driven drug discovery with variable-length sequence control (Healthcare, Pharma)
- What: Integrate A2D2 into hit identification and lead optimization with multi-property objectives (potency, ADMET, synthesizability), tightly coupled with robotic synthesis and screening.
- Tools/Products/Workflows: Closed-loop design–build–test–learn; continuous AJD fine-tuning as new assay data arrives; lab automation integration.
- Assumptions/Dependencies: High-fidelity property predictors; robust generalization; regulatory approval pathways; extensive wet-lab validation.
- General-purpose non-autoregressive LLMs for editing and drafting (Software, Productivity)
- What: Large-scale any-length diffusion LMs supporting fast, parallel, any-position editing for documents, emails, and knowledge bases.
- Tools/Products/Workflows: RL from human feedback (RLHF) adapted to AJD; enterprise deployments with on-prem controls; collaboration features.
- Assumptions/Dependencies: Availability of large pre-trained any-length checkpoints; human preference models; safety alignment; significant compute.
- Automated large-scale codebase refactoring and patching (Software Engineering)
- What: Project-wide, context-aware insertions/removals guided by tests and static analysis as rewards; quality gating to minimize regressions.
- Tools/Products/Workflows: CI/CD integration; staged rollouts; semantic-aware diff tools; dependency graph analysis as auxiliary signals.
- Assumptions/Dependencies: High test coverage; interpretable diffs; organizational change management; security review.
- Protein, RNA, and DNA design with variable-length architectures (Healthcare, Synthetic Biology)
- What: Design biological sequences with insertions/deletions under structure/function constraints using reward models from structure predictors and wet-lab surrogates.
- Tools/Products/Workflows: Coupling with AlphaFold/ESMFold and docking/MD-based surrogates; lab automation for screening; multi-objective AJD.
- Assumptions/Dependencies: Accuracy and speed of structure/fitness predictors; biosafety and dual-use concerns; robust sequence-to-function mapping.
- Materials and polymer discovery as discrete sequence optimization (Materials, Energy)
- What: Represent polymers and materials as sequences (monomer codes) and optimize for conductivity, strength, stability, or ion transport with any-length control.
- Tools/Products/Workflows: Domain-specific reward models; high-throughput simulation-in-the-loop; adaptive decoding to maintain validity (synthetic feasibility).
- Assumptions/Dependencies: Data scarcity and model reliability; costly simulation; transferability to novel chemistries.
- Efficient on-device/edge generative assistants (Software, Hardware)
- What: Leverage parallel decoding with quality control for faster, lower-energy inference on constrained devices for text/code assistants.
- Tools/Products/Workflows: Quantized any-length MDMs; kernel-level scheduling for batched parallel steps; adaptive thresholds tuned for latency/quality.
- Assumptions/Dependencies: Hardware support; memory footprint; robust calibration of quality predictors under quantization.
- Preference-optimized diffusion (RLHF-style) for discrete generators (Academia, Industry)
- What: Extend AJD to optimize against human preference reward models, delivering controllable, aligned generation without autoregressive dependence.
- Tools/Products/Workflows: Data collection pipelines for preference labels; reward model training; off-policy stabilization techniques.
- Assumptions/Dependencies: Quality and bias of human feedback; reward hacking risks; interpretability and auditing.
- Safety governance and auditing for AI-designed biological/chemical sequences (Policy)
- What: Incorporate reward shaping and post-generation screening into compliance workflows; maintain auditable traces (importance weights, quality scores).
- Tools/Products/Workflows: Standardized logs and attestations; red-team frameworks; shared benchmarks for safety performance; cross-institution protocols.
- Assumptions/Dependencies: Regulatory consensus; interoperability standards; continuous updates for new threat vectors.
- Collaborative multi-agent editing systems (Productivity, Enterprise Software)
- What: Multiple agents propose insertions with quality measures used for conflict resolution and merge policies in documents/code/design specs.
- Tools/Products/Workflows: CRDT-backed editors; per-agent reward constraints; governance rules for acceptance thresholds.
- Assumptions/Dependencies: Trust and attribution models; performance at scale; user experience acceptance.
- Adaptive learning curricula powered by quality-gated reasoning (Education)
- What: Generate step-by-step solutions and selectively reveal or revise steps based on predicted quality to match student proficiency.
- Tools/Products/Workflows: LMS integrations; per-skill reward models; analytics dashboards for educators.
- Assumptions/Dependencies: Efficacy studies; fairness and bias audits; privacy compliance.
Notes on cross-cutting assumptions and dependencies:
- Model availability: High-quality, pre-trained any-length MDMs are still emerging; adapting fixed-length backbones may be required.
- Reward design: Outcomes hinge on the fidelity and robustness of reward/predictor models; misspecified or narrow rewards can induce reward hacking or loss of diversity.
- Importance weighting stability: RND-based reweighting can have high variance; clipping/normalization and replay buffer management are important for stable training.
- Theoretical assumptions: Some bounds rely on conditional independence and calibrated quality predictors; deviations require empirical calibration.
- Compute and infrastructure: Off-policy fine-tuning and quality-guided decoding add overhead; parallel decoding recoups some inference cost.
- Safety and compliance: Particularly in chemistry/biotech, robust screening and governance are needed to manage dual-use risk and regulatory requirements.
Glossary
- Adaptive Joint Decoding (AJD): A weighted training objective that jointly optimizes insertion/unmasking policies and quality predictors to match a reward-tilted path measure via importance weighting. "This yields our Adaptive Joint Decoding (AJD) loss, defined as:"
- Any-length discrete diffusion: Discrete diffusion modeling that supports variable-length sequences by inserting tokens during generation. "fine-tune any-length discrete diffusion models"
- Any-order generation: Generating tokens in a flexible, non-left-to-right order to enable parallel or adaptive decoding. "any-order generation"
- Binary cross-entropy (BCE): A loss measuring cross-entropy between predicted probabilities and binary targets. "where BCE denotes the binary cross-entropy loss defined as"
- Bregman divergence: A class of divergences derived from a convex function; here φ(x, y)=y−x log y. "is the scalar Bregman divergence."
- Compounding Parallelization Error (CPE): The divergence induced by approximating joint parallel updates with independent marginals, which accumulates across steps. "minimizing compounding parallelization error (CPE)"
- Continuous-time Markov chain (CTMC): A stochastic process with transitions occurring at random continuous times governed by rates. "continuous-time Markov chain (CTMC)"
- Denoising cross-entropy (DCE): A training objective that reconstructs clean tokens from masked inputs by minimizing cross-entropy under a schedule. "denoising cross-entropy (DCE) loss:"
- Gumbel noise: Noise from the Gumbel distribution used for perturb-and-argmax style confidence/sampling. "scaled Gumbel noise."
- Importance weight: A trajectory or sample weight from the Radon–Nikodym derivative used to reweight expectations toward a target measure. "importance weight $W^{\bar{\theta},\bar{\phi}$"
- Insertion expectation: The model’s predicted expected number of tokens to insert at a gap during generation. "an insertion expectation "
- Insertion quality: The probability that a newly inserted mask will decode to a correct ground-truth token within the corresponding gap. "define the insertion quality"
- Insertion Quality Loss (IQL): A supervised objective to train the insertion quality predictor to match target probabilities. "Insertion Quality Loss (IQL)"
- Joint CTMC: A continuous-time Markov chain whose transitions include both insertion and unmasking events. "a joint CTMC induced by a path measure"
- Joint interpolant: The time-indexed corruption/reconstruction process used to sample intermediate states for training. "sample an intermediate state from the joint interpolant"
- KL divergence: A measure of difference between probability distributions used to quantify approximation or training objectives. "the KL divergence between the true joint distribution"
- LoRA adapters: Low-Rank Adaptation modules that fine-tune large models via small, rank-decomposed parameter updates. "LoRA adapters"
- Masked discrete diffusion models (MDMs): Discrete diffusion models that use a mask token as the corruption mechanism for sequence generation. "Masked discrete diffusion models (MDMs)"
- Monte Carlo Tree Guidance (MCTG): A guidance method that uses Monte Carlo tree search over actions to steer sampling toward higher reward. "Monte Carlo Tree Guidance (MCTG)"
- Morgan fingerprints: Circular molecular fingerprints used for similarity/distance metrics. "Morgan fingerprints"
- Off-Policy Reinforcement Learning: Learning a target policy from data generated by a different behavior policy. "Off-Policy Reinforcement Learning"
- Pareto-optimal set: The set of non-dominated solutions in multi-objective optimization. "Pareto-optimal set"
- Path measure: A probability measure over entire trajectories of a stochastic process. "the path measure "
- Poisson distribution: A distribution over counts used here to sample the number of insertions given a rate. "Poisson("
- Radon-Nikodym derivative (RND): The density ratio between two measures enabling importance reweighting of trajectories. "Radon-Nikodym derivative (RND)"
- Replay buffer: A storage of sampled sequences (and weights) used for off-policy updates. "replay buffer"
- Reward-tilted distribution: A distribution obtained by exponentiating rewards over the data distribution and renormalizing. "reward-tilted distribution"
- SAFE notation: A molecular string representation used as an alternative to SMILES for tokenization and generation. "SAFE notation ()"
- SMILES: A line notation for representing molecular structures as token sequences. "SMILES"
- Stochastic interpolant: A probabilistic path connecting clean data and corrupted states; used to define forward/backward processes. "joint stochastic interpolant"
- Tanimoto distance: A distance/similarity measure for binary fingerprints (1 − Tanimoto coefficient). "Tanimoto distance"
- Time embedding layers: Layers that encode continuous time inputs for conditioning diffusion models. "time embedding layers"
- Unmasking posterior: The model’s conditional distribution over tokens to fill a masked position given context and time. "unmasking posterior"
- Unmasking quality: The probability that an unmasked token equals the true token given the current context. "We define the unmasking quality"
- Unmasking Quality Loss (UQL): A supervised objective to train the unmasking quality predictor via binary cross-entropy. "Unmasking Quality Loss (UQL)"
- Weighted Cross-Entropy Objective: An objective that evaluates cross-entropy under importance weights from a target path measure. "Weighted Cross-Entropy Objective"
Collections
Sign up for free to add this paper to one or more collections.

