- The paper introduces Maestro, a scheduling system that leverages workload-aware prediction and agent semantics to optimize multi-agent LLM workflows.
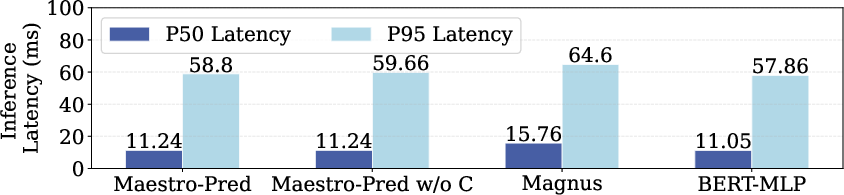
- It uses a two-phase regressor-classifier to predict output token lengths and KV memory demands, reducing prediction MAE by 19.2%.
- The system achieves 23.6% SLO improvement and 67.2% HBM reduction through elastic multi-model colocation and dependency-aware routing.
Maestro: Workload-Aware Cross-Cluster Scheduling for LLM-Based Multi-Agent Systems
Motivation and Problem Statement
The increasing adoption of LLM-based Multi-Agent Systems (LLM-MAS) enables decomposition of complex tasks into interdependent agent workflows, each involving specialized LLM calls. Unlike single-turn LLM serving, LLM-MAS workloads exhibit complex, dynamic resource demands due to iterative pipelines, input-dependent output lengths, and heterogeneous agent roles. The result is a dramatic amplification of compute and memory pressure, especially under strict or heterogeneous GPU budgets typical of private cloud and on-premises deployments. Major challenges impeding efficient, scalable LLM-MAS serving include: (1) high variance in execution costs due to input, role, and reasoning complexity; (2) long-tailed, dynamic multi-model invocation patterns leading to memory fragmentation and cold-start penalties; and (3) cross-cluster routing tradeoffs where network, memory, and model readiness interact nontrivially.
Maestro System Architecture
Maestro is designed as a workload-aware, hierarchical, cross-cluster scheduling system, leveraging direct access to agent- and workflow-level semantics to orchestrate LLM-MAS workloads efficiently. Its design integrates cost prediction, memory-safe multi-model colocation, elastic key-value (KV) cache management, and latency/resource-aware scheduling at node, cluster, and global levels.

Figure 2: The system architecture and workflow of Maestro.
Cost Prediction and Agent Context Modeling
A central innovation of Maestro is semantic and structural modeling of each workflow stage. At dispatch, Maestro extracts agent roles, workflow positions, tool intent, and prompt embeddings (via MiniLM-style BERT), generating a compact descriptor. It then predicts output token length (L^(T)), KV footprint, and tool-use probability using a calibrated two-phase regressor-classifier architecture:
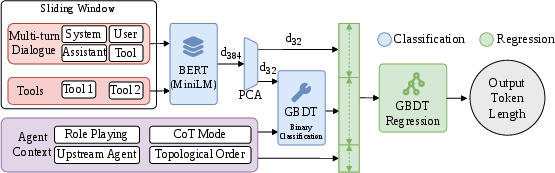
Figure 4: Agent-aware output-length prediction architecture in Maestro.
This approach differentiates between short-structured (tool-based) completions and open-ended Chain-of-Thought (CoT) generative steps, reflecting the actual output token distributions observed in LLM-MAS traces.
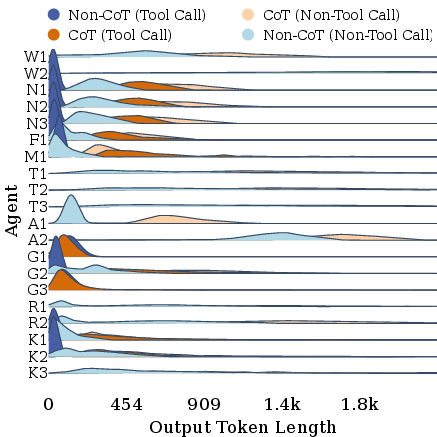
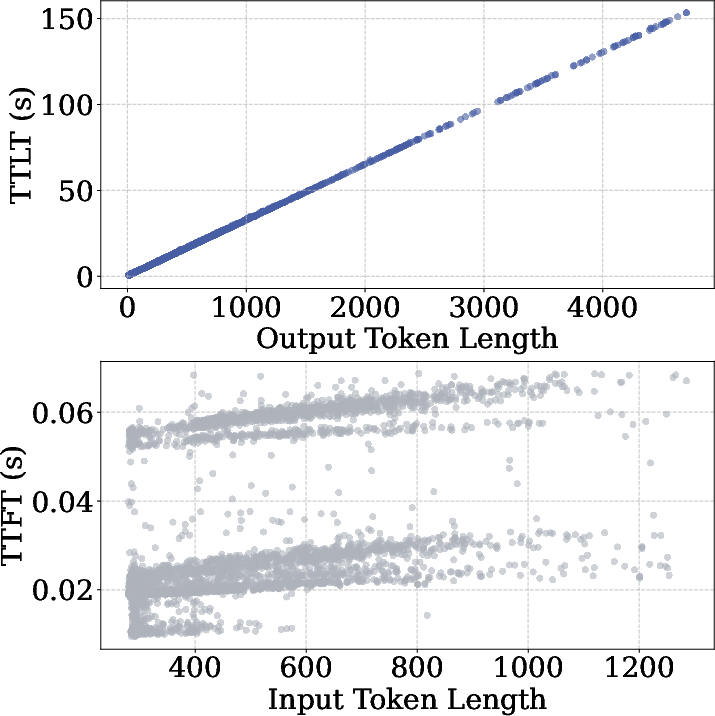
Figure 5: Output-token length distributions under non-CoT and CoT settings, tool-call and non-tool-call.
Accurate cost prediction directly underpins memory budgeting, admission decisions, and the minimization of head-of-line (HoL) blocking, with Maestro achieving substantial improvements in prediction MAE over established methods.
Multi-Model Colocation and Memory Elasticity
Node-level orchestration in Maestro enables safe, dynamic colocation of multiple specialist models per GPU. A hierarchical weight residency mechanism, with least-recently-used (LRU) eviction across GPU, CPU, disk, and remote tiers, amortizes cold-start costs while preserving fast context recovery for frequent model transitions.
Memory allocation is rigorously controlled via explicit KV cache accounting. Physical GPU memory partitioning is elastic—admitted stages are conditioned on predicted total KV demand, and, where possible, virtual memory and page-locked structures increase concurrency and memory overcommitment safely without OOM risk.
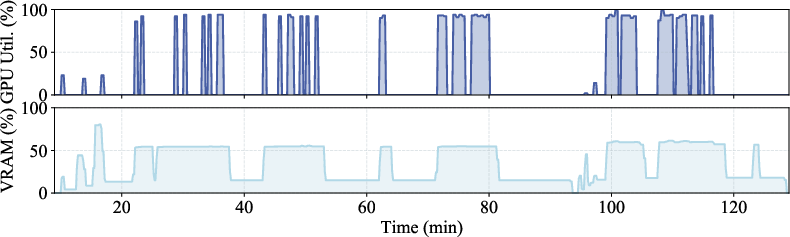
Figure 1: GPU utilization and memory usage under multi-model colocation.
Overcommitment by up to 205% of physical capacity (enabled by elastic KV allocation and accurate prediction) reduces high-bandwidth memory (HBM) reservation by 67.2% compared to statically partitioned baselines.
Cross-Cluster Scheduling and Dependency-Aware Prioritization
Maestro’s cluster-level scheduler integrates network latency, model readiness, and predicted memory feasibility into a unified fitness score for routing each agent stage. Only nodes passing flexible policy, network, and feasibility filters are candidates; among these, Maestro optimizes for a robust trade-off between low-latency (interactive SLOs) and resource availability.
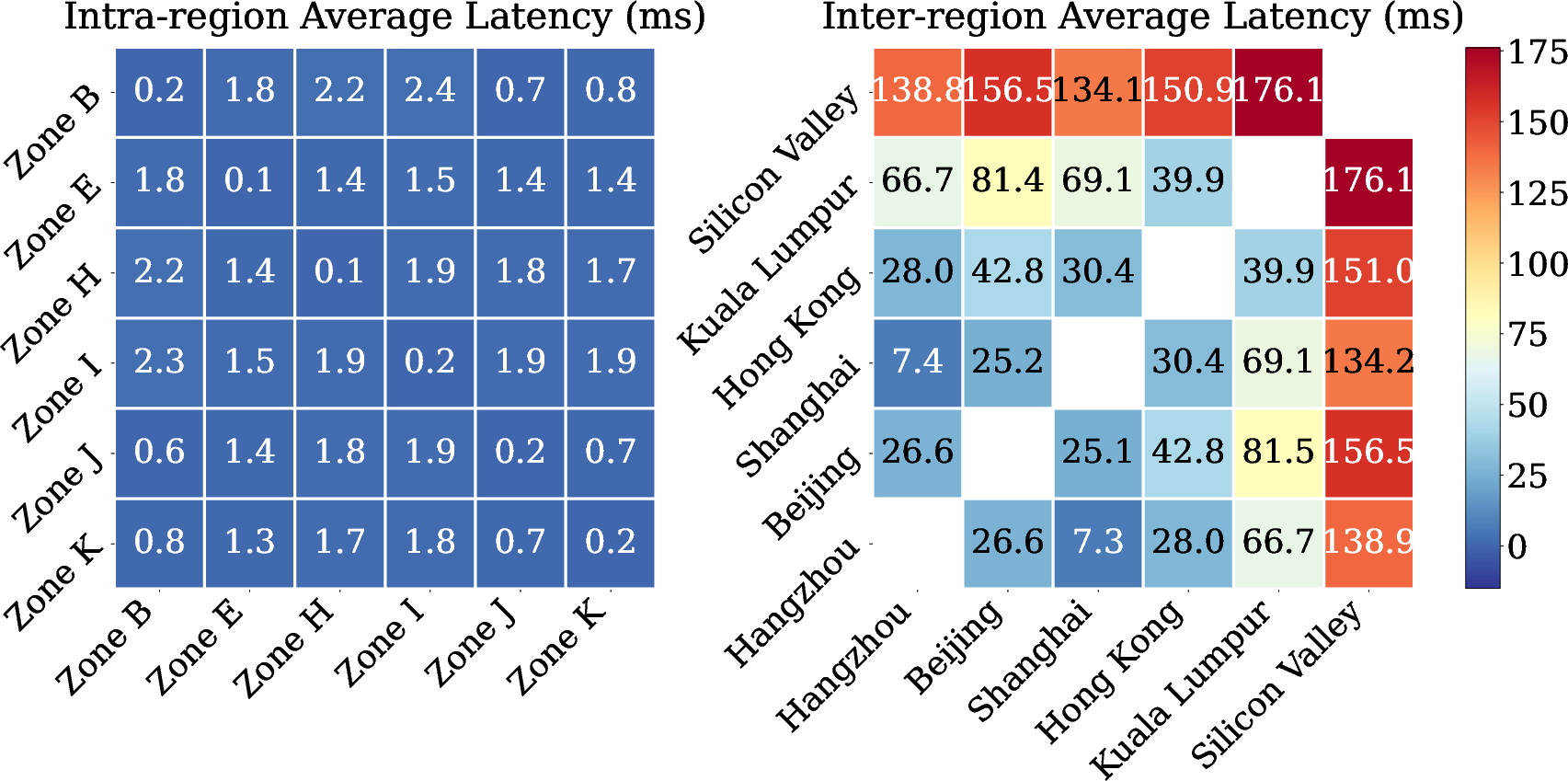
Figure 3: Intra- and inter-region network latency affecting cluster allocation efficiency.
Global scheduling leverages workflow-aware Shortest-Remaining-Time-First (SRTF) queueing, driven by rolling workflow profiles. This minimizes HoL blocking across dependent stages—a distinctive feature compared to naive deadline- or FIFO-based schedulers. Preemption is supported at stage boundaries with explicit degradation-cost accounting, further mitigating contention in mixed-workload, interactive/batch settings.
Empirical Results
Experimental evaluation uses both trace-driven simulations and deployments on a 32-node A100 cluster. Maestro is benchmarked against FCFS, EDF, Oracle-SRTF, and competing multi-model frameworks (QLM-style, etc.) under various load and SLO regimes.
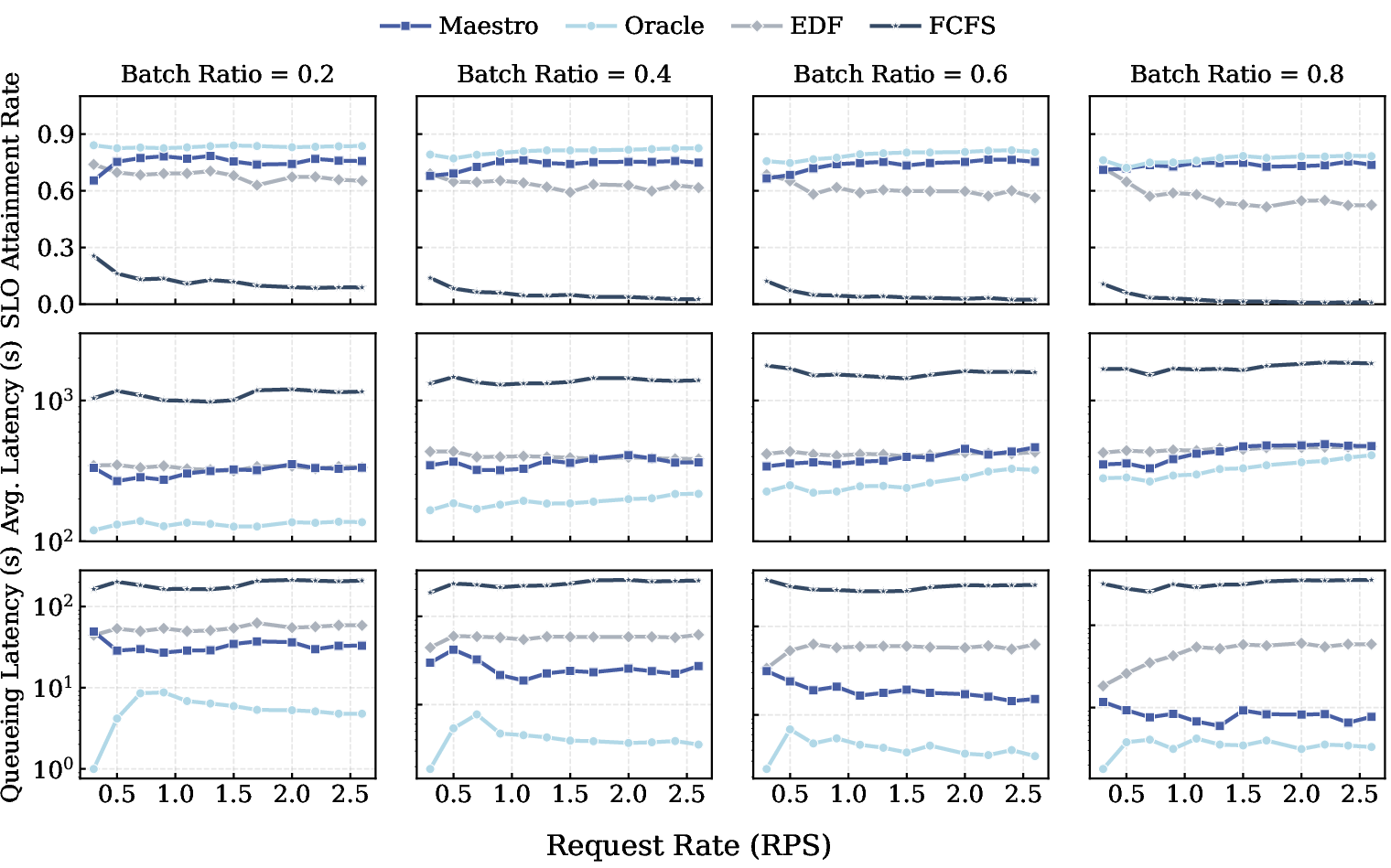
Figure 7: Overall scheduling results across arrival rates and batch ratios: SLO attainment, mean latency, and interactive queueing delay.
Key results:
Prediction latency remains sub-15ms (P95) for the two-stage model, negligible compared to network and LLM decode times.

Figure 8: Model activation latency (0.6B--14B) on a single A100 40GB GPU under Maestro’s hierarchical loading.
Theoretical and Practical Implications
The approach in Maestro establishes that explicit integration of agent semantics, workflow structure, and stage-level cost prediction is essential for resource efficiency and SLO compliance in LLM-MAS. This departs from workload-agnostic frame-works, demonstrating that viewing agentic pipelines as non-stationary, dependency-coupled jobs allows for more aggressive memory elasticity and higher GPU utilization.
The explicit disruption- and resource-awareness at the control plane creates a scheduling regime robust to cold-starts, interactive/batch mixtures, and non-trivial cluster topologies. The memory accounting and prediction-guided overcommitment strategy offers a practical path to efficient LLM serving on constrained hardware—scalability previously possible only on hyperscaler-style, stateless microservice LLM serving stacks.
Future Directions
Potential directions involve extending Maestro to heterogeneous accelerator clusters, integrating speculative decoding, KV compression, and fine-grained token-level preemption. Enhanced support for multi-tenant fairness, quota enforcement, and integration of external tool invocation scheduling are also required for robust productionizing. Dynamic adaptation to changing workload profiles and heterogeneous agent roles remains a promising research vector, especially in dynamic agent generation and evolving prompt formats.
Conclusion
Maestro provides a rigorous, empirically validated scheduling solution for large-scale LLM-MAS serving, unifying agent-aware prediction, multi-model colocation, and cross-cluster routing into a coordinated scheme. It achieves substantial gains in both SLO attainment and resource efficiency under realistic, heterogeneous workloads, providing a new reference point for multi-agent LLM system design. Its modular architecture allows integration with ongoing advancements in model architectures and low-level memory management, representing a substantial advance in the practical deployment of complex agentic LLM pipelines.