Wild3R: Feed-Forward 3D Gaussian Splatting from Unconstrained Sparse Photo Collection
Abstract: Feed-forward 3D Gaussian Splatting (3DGS) removes the need for time-consuming per-scene optimization required by traditional 3DGS. However, existing feed-forward approaches struggle with real-world photo collections that include diverse lighting conditions and transient objects. In this paper, we present Wild3R, a feed-forward approach for unconstrained sparse photo collections. The main bottleneck is the lack of training data that provides multiple viewpoints, a variety of illuminations, and transient variations necessary for learning robust scene representations. To address this, we introduce the WildCity dataset, which comprises 200 scenes, 170 lighting conditions, and transient objects, resulting in 337,500 images in total. By leveraging the dataset, our model learns appearance consistency across viewpoints conditioned on reference views, while removing transient content. Extensive experiments demonstrate that our method outperforms existing feed-forward approaches and achieves results competitive with prior per-scene optimization-based methods.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Wild3R: Feed-Forward 3D Gaussian Splatting from Unconstrained Sparse Photo Collections”
Overview
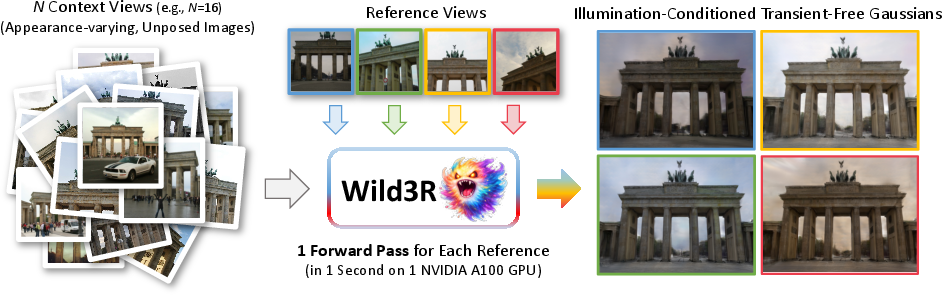
Imagine you have a bunch of photos people took of a famous building at different times: sunny days, cloudy evenings, with tourists walking by, cars passing, and different camera angles. Turning these messy, real-world photos into a clean, consistent 3D scene is hard and usually slow. Wild3R is a fast method that builds a 3D model from such photos in about a second, while matching the look of a chosen “reference” photo and ignoring temporary things like people and cars.
To make this possible, the authors also created a new training dataset called WildCity. It’s a large set of synthetic city scenes rendered under many lighting conditions with added “transient” objects (like people or vehicles) to teach the model to handle the chaos of the real world.
Key goals and questions
- Can we quickly turn a small, unorganized set of real-world photos into a clean 3D scene without slow, per-scene training?
- How do we keep the 3D scene’s look consistent across different viewpoints, even if the input photos have very different lighting?
- Can we automatically remove transient objects (people, cars, signs) that appear in some photos but aren’t part of the permanent scene?
- Is the main bottleneck the model design or the lack of the right training data?
How it works (in everyday terms)
- 3D Gaussian Splatting: Think of the 3D world as made of millions of tiny, soft, colored “paint blobs” floating in space. When you “look” from a certain angle, these blobs blend to form a realistic image. This is fast to render on a computer.
- Feed-forward: Instead of spending minutes or hours fine-tuning a model for each new scene, a feed-forward model produces the whole 3D scene in one quick pass, like a calculator giving an instant answer.
- Reference view: You pick one input photo to set the scene’s overall look (its lighting and color mood). The model makes the 3D scene match this reference appearance from all other viewpoints.
- Training with the WildCity dataset:
- The team built nine synthetic cities in Blender, combined many building models (including from Sketchfab), and rendered 200 scenes.
- They used 170 different lighting environments (HDRI “sky domes”) and rendered many views per scene, ending up with 337,500 images.
- To simulate real-life clutter, they added transient objects to some images using an AI image editor (e.g., insert a person or a car).
- Teaching the model consistency:
- During training, the model sees photos of the same place under different lights and with transient objects present.
- It’s asked to reconstruct the scene as if it were lit like the chosen reference photo and to leave out transient objects.
- It also learns “clean” depth (how far things are) that doesn’t include the temporary objects.
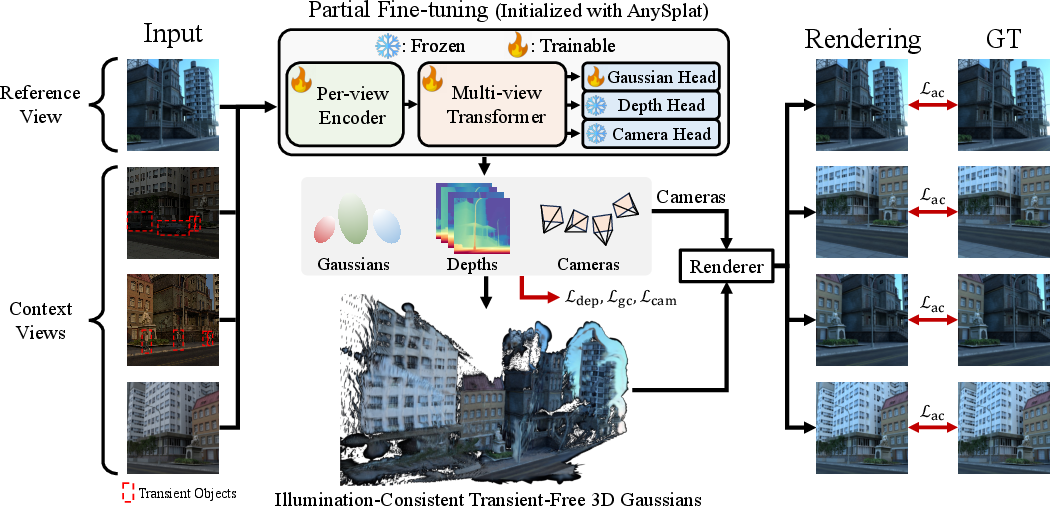
- Under the hood: They start from an existing fast model (AnySplat), then fine-tune it on WildCity with special training objectives that enforce consistent appearance and transient removal. No complicated new architecture is needed—better data and clever training do the trick.
Main findings and why they matter
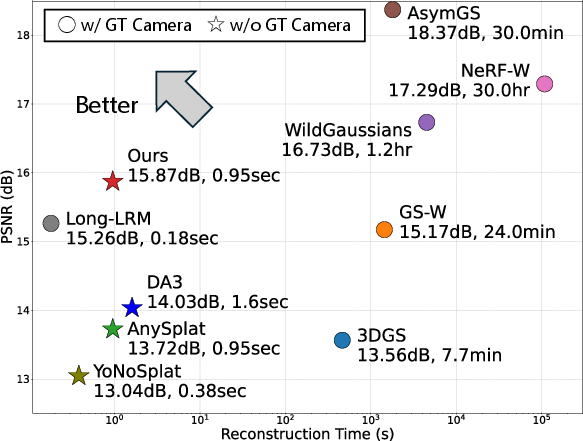
- Better than other fast methods: On a popular “in-the-wild” benchmark (Photo Tourism), Wild3R beats other feed-forward methods that don’t rely on known camera info, and it gets close to the quality of slower methods that do heavy per-scene optimization.
- Much faster: Wild3R builds the 3D scene in about 1 second on a high-end GPU, while older methods can take minutes to hours per scene.
- Works with few photos: It can handle sparse, unorganized photo sets (like 16 images) and still produce stable, consistent results.
- No camera parameters required: Many traditional methods need exact camera settings and a starting 3D point cloud; Wild3R does not, making it more practical for everyday photo collections.
- The key was data: By mainly fine-tuning an existing model using a better dataset (WildCity) and training strategy, they showed that the main barrier was the lack of the right kind of training data, not the need for a fancy new architecture.
Implications and impact
- Practical 3D from casual photos: Faster, cleaner 3D reconstructions can help with virtual tourism, AR/VR experiences, games, digital heritage, and city planning—without requiring controlled photo shoots.
- Data that benefits others: The WildCity dataset gives researchers the variety (many views, many lights, and transient objects) needed to train robust, real-world-ready models.
- A path forward: As feed-forward 3D models keep improving, pairing them with realistic, richly varied training data can push quality even closer to slow, optimization-heavy methods—while staying fast.
Limitations to keep in mind
- Shiny and complex reflections are tough: The method doesn’t explicitly model detailed material physics, so very reflective surfaces can be challenging.
- Depends on the reference photo: If the chosen reference view is heavily blocked by transient objects, the lighting it sets may be less accurate.
- Finest details: Optimization-based methods can still capture very tiny, high-frequency details better in some cases.
- Bound by the base model: Overall quality depends on the underlying feed-forward backbone, though this will likely improve over time.
In short, Wild3R shows that with the right training data and a smart learning setup, we can build fast, reliable 3D scenes from messy real-world photo collections—making 3D reconstruction far more practical outside the lab.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research:
- Sim-to-real generalization: The model is trained on synthetic WildCity scenes; its robustness across broader real-world conditions (e.g., night-time, low light, weather, seasonal changes, heavy exposure/gain variation) remains unquantified and unaddressed.
- Limited scene diversity: WildCity focuses on outdoor urban scenes built from SceneCity + Sketchfab; generalization to indoor environments, natural landscapes, water bodies, glass-heavy facades, and highly reflective/transparent materials is untested.
- 2D transient augmentation: Transient objects are inserted via 2D image editing, often without multi-view, geometric, or photometric consistency; the impact of this training signal on test-time transient removal for true 3D-consistent occluders is unclear.
- Transient density and distribution: Only 12.5% of views are transient-augmented; the model’s performance under heavier transient prevalence (e.g., 50–80% of views) and different transient types (crowds, dynamic traffic, construction machinery) is unexplored.
- Illumination coverage gaps: HDRI maps exclude very dark/night cases and likely under-represent extreme lighting (e.g., strong backlighting, hard cast shadows, high dynamic range sun glints); robustness to these illumination regimes is untested.
- Reference-view dependency: Appearance is anchored to a single reference image; how to handle references largely occluded by transients, suboptimal exposure, or atypical lighting is not resolved (e.g., multi-reference fusion, reference selection strategies).
- Lack of explicit reflectance/illumination disentanglement: Without material/light modeling, complex specularities, interreflections, and view-dependent effects are inadequately captured; integrating BRDF- or inverse-rendering-aware priors remains open.
- Camera/trajectory distribution bias: Training cameras are constrained to a fan-shaped region at 1–2 m height and pinhole intrinsics; generalization to aerial/drone, close-up macro, wide-baseline, fisheye/rolling-shutter, or heavily distorted smartphone imagery is unknown.
- High-resolution scalability: All training uses 512×512 images; fidelity and efficiency at higher resolutions (e.g., 2K/4K) and the effect on Gaussian count, memory, and rendering speed are not studied.
- Geometry and pose metrics: Evaluation relies on PSNR/SSIM/LPIPS; there is no measurement of 3D geometry accuracy (depth error, point-to-mesh distances) or camera pose accuracy, making geometric fidelity and pose robustness unclear.
- Camera and depth heads freezing: The paper freezes camera/depth heads while supervising depth; the trade-offs and gradients paths are not analyzed, and there is no ablation comparing frozen vs. fine-tuned camera/depth heads under illumination/transient variation.
- Loss-design ablations: Only limited ablations are provided; the specific contributions and sensitivities of each loss term (e.g., LPIPS weight, geometric consistency, depth supervision, transient augmentation probability) are not dissected.
- Number of context views: Training samples N∈[2,24] but evaluation omits N=2; capabilities at the extreme low-view regime (1–2 images) and how to gracefully degrade are not examined.
- Large-scale/long-range scenes: Scalability to wide-coverage, city-block or campus-scale reconstructions (beyond local façades) is untested, especially compared to long-sequence methods (e.g., trajectory drift, accumulation of errors).
- Resource footprint: With ~940M parameters, inference is timed on an A100; memory/latency on commodity GPUs, mobile/edge feasibility, and model compression/quantization strategies are unaddressed.
- Lens and sensor realism: The dataset assumes idealized pinhole cameras; robustness to real sensor artifacts (noise, HDR bracketing, rolling shutter, vignette, color calibration shifts) is not evaluated.
- Illumination canonicalization vs. conditioning: The method conditions on a reference illumination but does not address producing a canonical, reference-free appearance (e.g., albedo-shaded decomposition) or generalizing to unseen lighting at test time.
- Evaluation protocol limitations: The Photo Tourism test protocol uses a half-image as both reference and target source, potentially understating cross-image illumination adaptation difficulty; evaluation under mismatched lighting across unrelated images is missing.
- Transient removal evaluation: There is no quantitative benchmark (e.g., transient masks) to assess transient suppression quality; future work could include labeled datasets or synthetic 3D-consistent transients for measurable comparisons.
- Domain adaptation: Strategies for adapting from synthetic WildCity to diverse real photo collections (unsupervised/semi-supervised, test-time adaptation, data selection) are not explored.
- Scale and unit consistency: As a camera-free method, how metric scale and absolute pose ambiguities are handled or calibrated in real data is not discussed, nor is the impact of scale ambiguity on downstream tasks.
- Dataset realism and biases: Although diverse, WildCity’s materials and HDRIs may not span the full space of real textures/BRDFs; adding physically accurate materials (metals, glass, water) and weather effects is an open avenue.
- Multi-reference or reference-agnostic conditioning: The paper does not test multi-reference conditioning, learned reference selection, or blending strategies to reduce sensitivity to a single (possibly flawed) reference view.
- Failure mode taxonomy: Beyond a short limitations section, systematic characterization of failure cases (e.g., repeated geometry, over-smoothing, color bleeding, pose drift) by scene/lighting/transient factors is absent.
- Reproducibility details: The 2D transient insertion via Gemini lacks guarantees of cross-view consistency or reproducibility; datasets with deterministic, controlled transient insertions and public prompts/seeds would facilitate controlled studies.
Practical Applications
Overview
Wild3R introduces a feed-forward 3D Gaussian Splatting pipeline that reconstructs appearance-consistent, transient-free 3D scenes from sparse, unposed photo collections in about one second on an A100 GPU. The accompanying WildCity dataset (200 scenes, 170 illuminations, transient augmentations) enables learning to harmonize appearance to a chosen reference view and to suppress transient objects (e.g., people, cars). Below are actionable applications derived from these findings, methods, and innovations.
Immediate Applications
The following use cases can be deployed now with current capabilities; they benefit from Wild3R’s rapid, camera-free reconstruction and appearance harmonization, and from WildCity as a training/benchmarking resource.
- Rapid landmark and streetscape reconstructions for AR/VR tourism
- Sectors: cultural heritage, tourism, software
- What: Generate browseable 3D “postcards” of famous sites from a handful of tourist photos; harmonize to a target lighting for visual consistency; remove crowds.
- Tools/workflows: “Upload 10–20 photos → pick a reference photo → get a 3DGS scene” web service; integration with web 3DGS viewers or conversion to meshes for popular engines.
- Assumptions/dependencies: Best for outdoor urban/landmark scenes; inference requires a strong GPU for near-real-time speed; quality declines with very sparse or low-overlap views.
- Real estate and AEC site snapshots from few photos
- Sectors: real estate, architecture/engineering/construction (AEC), software
- What: Create quick 3D overviews of exteriors (curbside elevations, façade conditions) for marketing, pre-bid surveys, or pre-design review; remove parked cars/pedestrians.
- Tools/workflows: Broker app plugin that turns agent photos into 3D previews; AEC pipeline step that ingests field photos for context models.
- Assumptions/dependencies: Outdoor-centric training may limit interior fidelity; fine details (e.g., small fixtures) are less accurate than optimization-heavy pipelines.
- VFX background reconstruction and crowd removal
- Sectors: media & entertainment
- What: Turn still plates into transient-free 3D backgrounds for set extensions and camera moves; harmonize appearance to a hero plate’s lighting.
- Tools/workflows: Shot-prep tool that ingests stills and returns a transient-free 3DGS; compositing pipeline with togglable transient layers.
- Assumptions/dependencies: Highly specular/reflective surfaces remain challenging; fine geometric detail may require downstream refinement.
- Crowd-sourced 3D city tiles for mapping and GIS
- Sectors: mapping/GIS, public sector, software
- What: Build consistent 3D tiles from community photo uploads without requiring camera poses; normalize to canonical lighting for map continuity.
- Tools/workflows: Backend service that processes photo batches into 3DGS tiles; QC workflow that selects a reference image representative of canonical appearance.
- Assumptions/dependencies: Requires enough overlap across uploaded views; accuracy bounded by feed-forward backbone and outdoor bias of training set.
- AR anchoring and scene previews for outdoor experiences
- Sectors: AR/VR, gaming, software
- What: Create quick 3D anchors and previews for outdoor AR experiences (events, pop-up installations) without on-site scanning.
- Tools/workflows: Mobile app uploads team photos → cloud reconstructs 3D → AR engine consumes 3DGS/mesh proxy for authoring and alignment.
- Assumptions/dependencies: Cloud-side inference preferable; mobile deployment would need model distillation or server streaming.
- Insurance and forensics pre-assessment from photo bundles
- Sectors: insurance, public safety
- What: Build a clean 3D of damaged exteriors from adjuster/public photos and filter transient objects for clearer assessment.
- Tools/workflows: Claim portal ingestion → automated 3D reconstruction → adjuster review in a web viewer.
- Assumptions/dependencies: Legal/ethical guardrails for removing people/vehicles; limited handling of mirror-like materials and very fine detail.
- Heritage documentation and de-occluded archiving
- Sectors: cultural heritage, museums
- What: Reconstruct monuments from mixed-condition photos and remove transient occluders, producing consistent archival models.
- Tools/workflows: Museum digitization workflow that normalizes appearance to a curatorial reference and outputs 3DGS/meshes.
- Assumptions/dependencies: Non-Lambertian details and intricate carvings may need additional refinement.
- Dataset creation and benchmarking for robust 3D vision
- Sectors: academia, R&D (software/robotics/graphics)
- What: Use WildCity to train or benchmark feed-forward 3D reconstruction models under multi-illumination and transient conditions.
- Tools/workflows: Pretraining/fine-tuning on WildCity; ablation studies on transient robustness and illumination consistency.
- Assumptions/dependencies: Synthetic-to-real gap; WildCity is urban/outdoor oriented.
- Appearance harmonization for Internet photo curation
- Sectors: software, media
- What: Normalize community photo collections to a single target appearance for consistent albums and 3D slideshows.
- Tools/workflows: Photo platform feature that picks a “canonical” reference photo and harmonizes reconstructions accordingly.
- Assumptions/dependencies: If the reference view is heavily occluded, harmonization degrades (as noted in paper limitations).
- API-as-a-service for “3D from sparse photos”
- Sectors: software/platforms
- What: Turn user-provided image sets into 3DGS assets programmatically; optional “remove transients” switch.
- Tools/workflows: Cloud API with inputs {images, reference index} → returns {3DGS, predicted cameras, depth maps}; SDKs for Unity/Unreal/web.
- Assumptions/dependencies: Throughput and latency depend on GPU capacity; licensing for downstream conversion/renderers.
Long-Term Applications
These use cases are promising but require further research, scaling, model adaptations, or tooling before widespread deployment.
- On-device, real-time AR reconstruction
- Sectors: AR, mobile software, robotics
- What: Near-instant scene recon on mobile headsets/phones for dynamic AR authoring and occlusion handling.
- Enablers: Model compression/distillation, sparse-views training on mobile-like optics, hardware acceleration for 3DGS.
- Dependencies/assumptions: 940M-parameter backbone is too heavy for mobile; latency targets demand major optimization.
- City-scale digital twins from Internet photos
- Sectors: smart cities, GIS, public sector
- What: Build wide-coverage, harmonized, transient-free urban models from heterogeneous, unposed imagery at scale.
- Enablers: Scalable data ingestion, view-selection and overlap filtering, confidence scoring, integration with aerial/LiDAR priors.
- Dependencies/assumptions: Robustness to diverse sensors and viewpoints; legal frameworks for crowdsourced data use.
- Autonomous systems map priors and SLAM bootstrapping
- Sectors: robotics, automotive
- What: Use fast feed-forward reconstructions as priors for SLAM/localization in GPS-challenged areas.
- Enablers: Joint training with VO/SLAM signals; uncertainty-aware camera/depth outputs; loop-closure integration.
- Dependencies/assumptions: Current camera/depth heads are frozen and optimized for images, not robot streams; dynamic scenes and speculars remain difficult.
- Photoreal relighting and inverse rendering integration
- Sectors: VFX, gaming, visualization
- What: Combine Wild3R with material and lighting estimation to enable consistent relighting/editing across views.
- Enablers: Augment training with physically grounded multi-illumination datasets; learn materials/BRDFs and environment maps.
- Dependencies/assumptions: Present method anchors to reference appearance and does not recover physical materials.
- Scene editing and compositing in 3DGS
- Sectors: media & entertainment, software
- What: Edit transient-removed scenes by inserting/removing assets, changing sky/lighting, and exporting to meshes.
- Enablers: Reliable 3DGS-to-mesh conversion, editable splat attributes, lighting-aware compositing tools.
- Dependencies/assumptions: Handling of glossy/transparent objects and high-frequency textures requires enhanced modeling.
- Post-disaster assessment from scattered public imagery
- Sectors: public safety, insurance, NGOs
- What: Rapidly reconstruct areas from heterogeneous photos for situational awareness; reduce occlusions from crowds/vehicles.
- Enablers: Robustness to extreme lighting/weather; integration with UAV/aerial imagery and pre-disaster basemaps.
- Dependencies/assumptions: Data quality and overlap may be poor; ethics of removing individuals must be codified.
- Privacy-preserving map publishing
- Sectors: policy, public sector, software
- What: Publish 3D maps with transient objects removed to reduce exposure of identifiable individuals/vehicles.
- Enablers: Auditable pipelines and controls for what qualifies as “transient”; compliance with privacy regulations.
- Dependencies/assumptions: False positives/negatives in transient removal require monitoring; legal standards vary by jurisdiction.
- Training foundation models robust to illumination/transients
- Sectors: academia, AI platforms
- What: Use WildCity-like pipelines to pretrain vision models under appearance variance and transient distractors.
- Enablers: Scaling datasets beyond urban scenes, adding indoor/industrial domains, better synthetic-to-real bridging.
- Dependencies/assumptions: Synthetic augmentation quality and domain breadth determine transfer effectiveness.
- Insurance/real estate risk analytics at portfolio scale
- Sectors: finance, real estate
- What: Automated 3D condition assessment across many properties using web-scraped or client-submitted images.
- Enablers: Confidence scoring, QA workflows, fusion with cadastral/IoT data, regulatory acceptance.
- Dependencies/assumptions: Varying photo quality and legal rights for image use; outdoor bias may limit interior insights.
- Standards and governance for crowd-sourced 3D data
- Sectors: policy, standards bodies
- What: Establish guidelines for ingesting, harmonizing, and anonymizing public images used for 3D reconstructions.
- Enablers: Provenance tracking, consent mechanisms, interoperability formats for 3DGS/meshes.
- Dependencies/assumptions: Cross-stakeholder agreement on privacy and acceptable removal/editing practices.
Notes on Feasibility and Dependencies
- Domain bias: Wild3R is trained on WildCity’s synthetic, outdoor urban scenes; generalization to indoor or highly non-urban settings will require additional data or fine-tuning.
- Transient handling: Performance degrades if the chosen reference image is heavily occluded; selection or automatic vetting of reference views is advisable.
- Material/lighting limits: Current method harmonizes to reference appearance without explicit material/BRDF modeling; highly specular/transparent surfaces remain challenging.
- Compute: ~0.95s per reconstruction on an A100 for 16 views; production systems likely need cloud GPUs or aggressive model optimization for edge use.
- Data requirements: Works best with moderate numbers of overlapping views (e.g., 8–24) and reasonable coverage; extremely sparse or non-overlapping inputs reduce quality.
- Legal/ethical: Removing people/vehicles is powerful for privacy and clarity but must be transparent and governed to avoid misuse.
Glossary
- 3D Gaussian Splatting (3DGS): An explicit, point-based scene representation and rendering technique that uses 3D Gaussian primitives for real-time, photorealistic view synthesis. "3D Gaussian Splatting (3DGS)~\cite{kerbl3Dgaussians} introduced explicit radiance primitives that enable real-time rendering while preserving photorealistic quality."
- AdamW optimizer: An adaptive gradient-based optimizer with decoupled weight decay commonly used for training deep networks. "we train the model using the AdamW optimizer"
- Anisotropic Gaussian primitives: Ellipsoidal Gaussian elements with direction-dependent variance used as the basic volumetric units in 3DGS. "represents a 3D scene as a collection of anisotropic Gaussian primitives."
- Anisotropic scaling: Axis-specific scaling parameters controlling the shape of anisotropic Gaussians. "defines the anisotropic scaling,"
- AnySplat: A camera-free, feed-forward 3DGS model that predicts Gaussians directly from images; used here as the base architecture. "We base our network architecture on AnySplat~\cite{jiang2025anysplat}"
- Appearance consistency: A training constraint ensuring that reconstructed appearance remains consistent across views when conditioned on a reference image. "learns appearance consistency across viewpoints conditioned on reference views"
- Bidirectional scattering distribution function: A reflectance model describing how light is reflected/transmitted at surfaces in physically based rendering. "PBR models light transport using bidirectional scattering distribution function shaders, including diffuse reflection, glossy reflection, and transmission."
- Camera calibration: The process of estimating camera intrinsics and extrinsics required by some reconstruction methods. "methods that rely on camera calibration or point cloud initialization"
- Depth maps: Per-pixel distance or depth estimates from a camera to scene surfaces. "along with the corresponding camera parameters and depth maps."
- DUSt3R: A geometric foundation model for 3D vision often used as a backbone for feed-forward reconstruction. "geometry foundation models such as DUSt3R~\cite{dust3r}"
- Feed-forward 3D Gaussian Splatting: Predicting a complete Gaussian representation in a single forward pass without per-scene optimization. "Feed-forward 3D Gaussian Splatting (3DGS) removes the need for time-consuming per-scene optimization required by traditional 3DGS."
- Geometric consistency loss: A loss term encouraging multi-view geometric agreement (e.g., depths/poses) during training. "where the geometric consistency loss $\mathcal{L}_{\mathrm{gc}$ and the camera loss $\mathcal{L}_{\mathrm{cam}$ follow AnySplat~\cite{jiang2025anysplat}."
- HDRI maps: High dynamic range environment maps used to illuminate synthetic scenes with realistic lighting. "We utilized 170 HDRI maps available from LightCity~\cite{lightcity}"
- LPIPS: A perceptual image similarity metric based on deep features. "the LPIPS loss~\cite{lpips}"
- Multi-illumination: Data captured or rendered under multiple lighting conditions to improve robustness across appearances. "Multi-illumination. We utilized 170 HDRI maps available from LightCity~\cite{lightcity} to achieve diverse lighting conditions"
- Neural Radiance Fields (NeRF): Implicit neural representations modeling color and density fields for photorealistic view synthesis. "Neural Radiance Fields (NeRF)~\cite{nerf} achieved high-fidelity novel view synthesis but relied on controlled captures."
- NeRF in the Wild (NeRF-W): A NeRF variant that models per-image appearance and transients to handle Internet photo collections. "NeRF in the Wild (NeRF-W)~\cite{martinbrualla2020nerfw} addressed this limitation"
- Novel view synthesis: Generating images from viewpoints not present in the input set. "achieved high-fidelity novel view synthesis"
- Opacity: The alpha parameter controlling a Gaussian’s transparency in 3DGS. " represents opacity,"
- Per-image appearance embeddings: Latent vectors that capture image-specific appearance (lighting/transients) for disentangling scene content. "using per-image appearance embeddings, as pioneered by NeRF-W~\cite{martinbrualla2020nerfw}."
- Physically based renderer (PBR): A renderer that simulates light transport according to physical laws to produce realistic images. "a physically based renderer (PBR) capable of generating photorealistic images."
- Point cloud initialization: Providing an initial 3D point set to guide optimization-based reconstruction methods. "require camera calibration and point cloud initialization"
- PSNR: Peak Signal-to-Noise Ratio, a distortion-based metric for image reconstruction quality. "PSNR vs. Reconstruction Time."
- Quaternion: A four-parameter representation for 3D rotations used to encode Gaussian orientations. "is the rotation encoded as a quaternion,"
- Radiance primitives: Basic rendering elements that encode emitted/reflected light; in 3DGS, the Gaussians themselves. "introduced explicit radiance primitives"
- Spherical harmonics coefficients: Coefficients of a basis used to represent directional dependencies like view-dependent color. "parameterized using spherical harmonics coefficients."
- SSIM: Structural Similarity Index Measure, a perceptual metric assessing structural fidelity between images. "We report PSNR, SSIM~\cite{ssim}, and LPIPS~\cite{lpips}"
- Transient objects: Temporarily present scene elements (e.g., people, cars) that differ across images and occlude static content. "transient objects such as moving objects or occluders,"
- Transient-free geometry: A reconstructed geometry that excludes or suppresses transient content across views. "transient-free geometry across views."
- VGGT (Visual Geometry Grounded Transformer): A transformer backbone for geometry estimation used by feed-forward 3DGS methods. "which is built upon VGGT~\cite{wang2025vggt}"
- View-dependent color: Appearance that varies with viewing direction, modeled in 3DGS via directional bases. "represents view-dependent color parameterized using spherical harmonics coefficients."
Collections
Sign up for free to add this paper to one or more collections.

