- The paper introduces a candidate-guided segmentation paradigm that decouples candidate generation, language grounding, and loopback verification to enhance mask fidelity.
- It employs a semantic-spatial selector and candidate fusion module, achieving an 8.38 mIoU improvement on ScanNet and 5.34 on Matterport3D over previous methods.
- The modular design facilitates integration with off-the-shelf pretrained components, paving the way for advancements in embodied AI, robotics, and interactive scene understanding.
SEGment-And-select (SEGA3D): Structured 3D Vision-Language Segmentation with Candidate-Level Reasoning
Introduction and Motivation
The task of 3D vision-language segmentation involves segmenting target objects within 3D scenes according to natural language instructions and visual observations. This challenge extends beyond conventional 3D segmentation by requiring models to jointly perform language understanding, spatial grounding, and fine-grained mask prediction at the point level. Typical applications include embodied AI, robotics, and interactive scene understanding, where instruction-driven perception is vital.
Prior art in this area has relied heavily on superpoint-based representations to mitigate the computational complexity of segmenting large-scale point clouds. However, these approaches suffer from inadequate semantic granularity, resulting in ambiguous object boundaries and suboptimal segmentation quality. The reliance on superpoints can fragment coherent object regions or merge semantically unrelated parts, limiting the reliability of generated object masks.
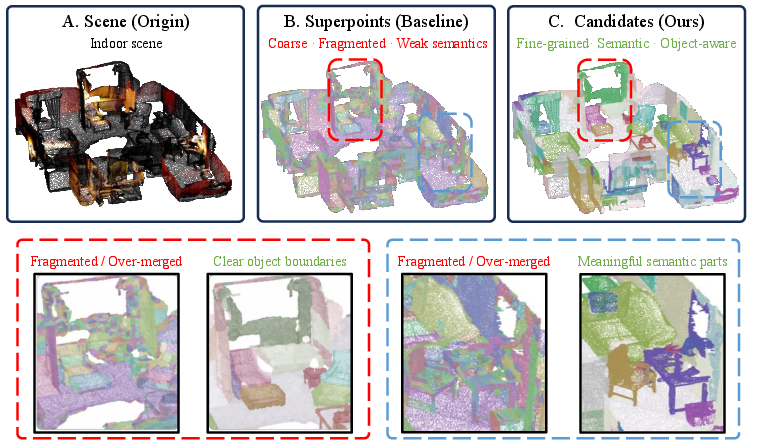
Figure 1: Visual comparison between the superpoint representation and the proposed candidate representation, highlighting improved semantic quality and boundary clarity with the latter.
Recent developments incorporate LLM-generated semantic and spatial cues via special tokens, but existing methods still couple candidate search, mask generation, and prediction within a single decoding pass, precluding explicit candidate-level hypothesis comparison or post-hoc verification. To address these shortcomings, the SEGment-And-select (SEGA3D) paradigm is introduced, reformulating the task as a structured search-and-verification process involving (a) construction of a fine-grained candidate mask bank, (b) language-informed candidate selection, and (c) mask-level loopback verification and refinement.
Framework Overview: Structured Candidate-Guided Reasoning
SEGA3D sequentially decomposes the 3D vision-language segmentation pipeline into distinct modules targeting explicit candidate hypothesis construction, efficient candidate-language grounding, and post-selection verification.
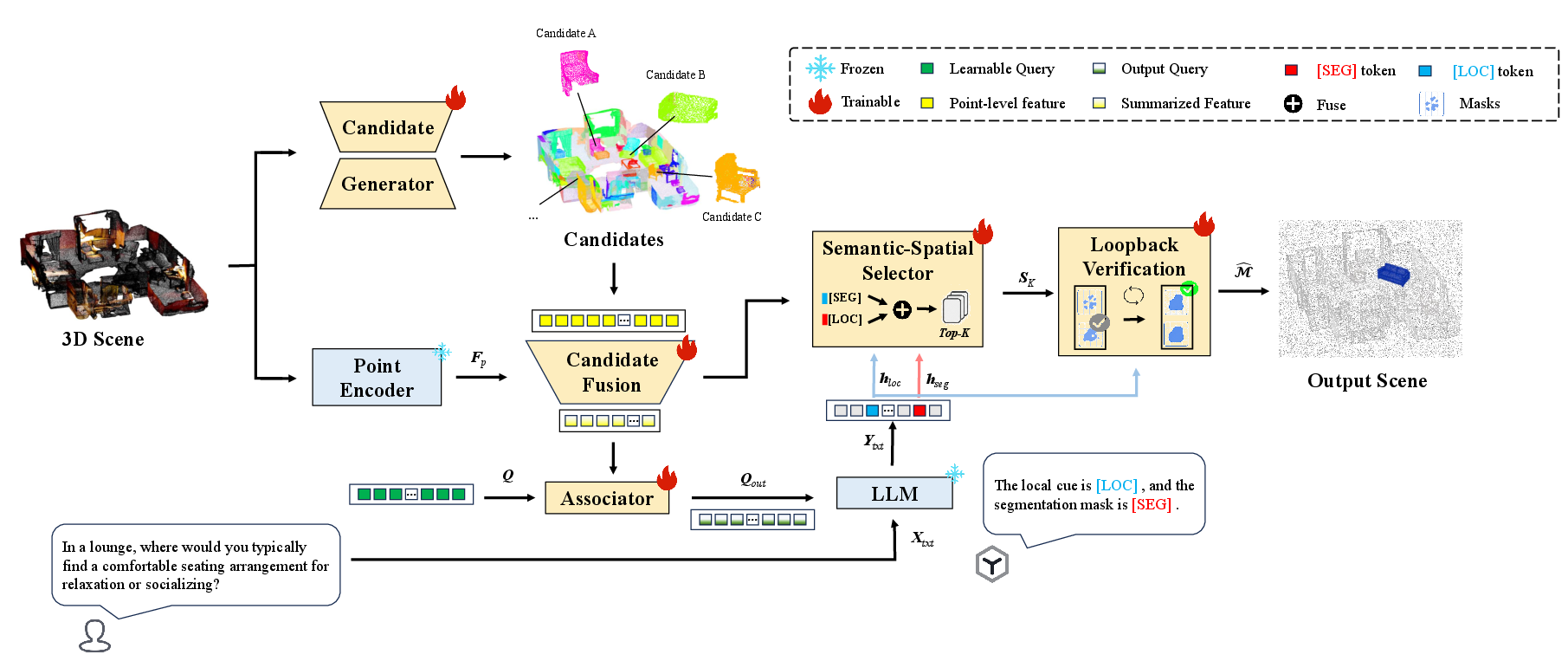
Figure 2: Overview of the SEGA3D framework, illustrating candidate bank construction, candidate-feature fusion, LLM interaction yielding [SEG]/[LOC] representations, Semantic-Spatial Selector-based Top-K filtering, and Loopback Verification for refined mask prediction.
The process begins with the generation of a bank of object-level mask candidates using an independently pretrained 3D segmentation network (e.g., PTv3). Simultaneously, a Point Encoder extracts point-wise features for the entire cloud, which are aggregated with candidate-specific geometric descriptors (center, box, spatial extents, etc.) via a learnable Candidate Fusion module. This aggregation yields candidate-level features, each comprehensively encoding local semantics and geometry.
Learnable scene queries (as in Q-Former) then interface these candidate features to a frozen LLM, which, upon conditioning on the text instruction, generates two critical token representations: SEG and LOC. These LLM-derived cues enable the Semantic-Spatial Selector to joint-model semantic relevance and spatial consistency, ranking the candidate hypotheses.
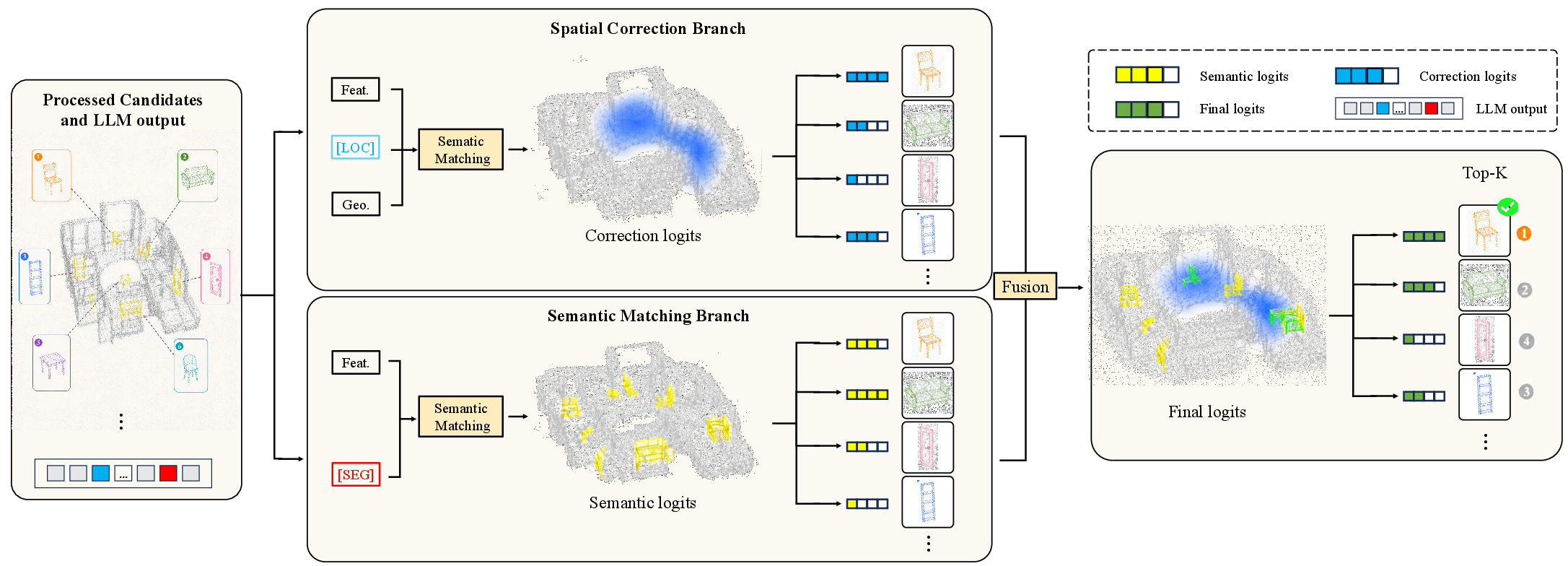
Figure 3: Design of the Semantic-Spatial Selector, which fuses semantic and spatial logit branches to select Top-K candidates based on multimodal matching.
The highest scoring K candidates are advanced for mask refinement and verification using local features and LLM cues through the Loopback Verification module, which yields the final point-level mask through mask refinement and learnable reranking.
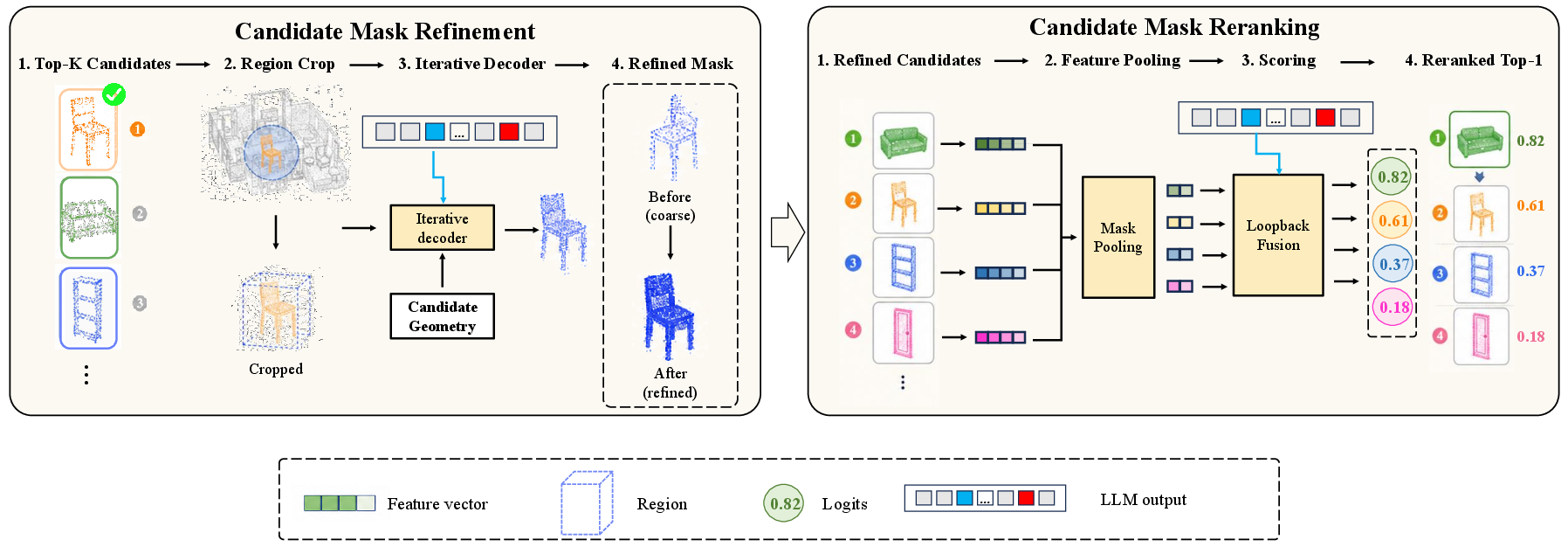
Figure 4: Loopback Verification comprises mask refinement within the candidate’s local region using spatial localization prior, followed by mask-aware feature reranking for final output selection.
Methodological Contributions
Candidate-Level Hypothesis Space: The move from superpoints to a bank of candidate-level object masks reduces semantic ambiguity and sharpens boundaries, improving both localization and discriminability as validated through visual and quantitative ablations. The candidate bank is robust to the choice of segmentation backbone and the coverage protocol, offering flexibility for scene diversity.
Semantic-Spatial Selector: The introduction of decoupled semantic matching ([SEG]) and spatial correction ([LOC]) handles complex referential expressions, supporting both explicit (category, appearance, spatial relation) and implicit (function, intent) queries. Ablation studies confirm the necessity of both components: removing [LOC] leads to significant drops in accuracy and mIoU.
Loopback Verification: The two-stage refinement—fine-tuning candidate masks at point-level and mask-aware reranking—delivers substantial improvements compared to naive top-1 proposal selection. The mask-aware score, as opposed to the initial proposal score, better reflects final mask fidelity.
Modular Training and Optimization: Only the Candidate Fusion, the Associator, the Semantic-Spatial Selector, and the Loopback Verification are optimized during training. Backbone and LLM weights, as well as the Candidate Generator, remain frozen, simplifying integration with off-the-shelf pretrained components.
SEGA3D was evaluated on ScanRefer (explicit referring segmentation), ScanNet, and Matterport3D (3D reasoning segmentation) benchmarks using metrics such as [email protected], [email protected], and mIoU. Across all datasets, SEGA3D surpasses existing methods, with especially pronounced gains in reasoning segmentation—8.38 mIoU improvement on ScanNet and 5.34 mIoU on Matterport3D over the prior best Reason3D baseline.
For 3D referring segmentation on ScanRefer, SEGA3D achieves competitive [email protected] while outperforming other methods in [email protected] and mIoU, indicating improved boundary quality and semantic precision. In ablations, every architectural decision (semantic-spatial dual-branch selector, learned Candidate Fusion, Loopback Verification, and mixed candidate banks) is shown to contribute to overall robustness and performance.

Figure 5: Qualitative SEGA3D outputs: predicted masks closely match ground truth for explicit descriptions and tasks requiring high-level commonsense or functional reasoning in complex 3D scenes.
Implications and Future Directions
The candidate-guided, search-and-verify approach introduced in SEGA3D decouples perception and cognition, mirroring theoretical principles supporting robust multimodal grounded reasoning. By moving from dense point-level prediction to a structured candidate hypothesis space, SEGA3D provides an explicit interface for integrating external knowledge into scene understanding—a pathway towards more generalizable and interpretable embodied intelligence.
Practically, SEGA3D’s modularity facilitates extension to diverse 3D perception tasks, multi-object grounding, and mobile robotics scenarios. The two-stage selection and verification design naturally accommodates more complex language compositions and ambiguous, function-oriented reasoning forms. The main experimental limitation is the focus on indoor benchmarks; extending this architecture to outdoor scenes, dynamic and cluttered environments, and richer instruction settings is warranted.
Conclusion
SEGA3D introduces a robust candidate-guided paradigm for 3D vision-language segmentation, incorporating a high-quality candidate bank, semantic-spatial selection leveraging LLM cues, and mask-level loopback verification. The approach achieves strong quantitative and qualitative gains, particularly in functionally grounded and ambiguous settings. Its structured modularity and general applicability lay a foundation for further advances in open-world embodied 3D reasoning and interactive perception.
Reference: "Segment and Select: Vision-Language Segmentation in 3D Scenarios" (2606.10594)