TimpaTeks: Automatic In-place Text Sequence Modification via Diffusion Language Model Steering
Abstract: We extend activation steering to diffusion LLMs (DLMs) and study a novel problem that arose due to the inference mechanism of DLMs: Modifying a text in-place to manifest a different concept. We propose TimpaTeks, an automatic in-place text modification mechanism using DLMs. Experiments on IMDB movie reviews (sentiment) and a synthetic Cats and Dogs Dataset (arbitrary, more unconventional concept steering) show that TimpaTeks provides a feasible novel mechanism to steer diffusion LLM outputs in-place. TimpaTeks enables in-place modification while simultaneously lowers sentence perplexity and retaining the original sentence structre without the need of instruction tuned models. TimpaTeks is also computationally cheaper than prompt-based DLM steering, as it performs denoising in-place rather than constructing an additional prompt-conditioned output sequence.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces TimpaTeks, a new way for AI to edit text “in place.” Instead of rewriting a whole sentence from scratch, the AI changes only a few words so the sentence shows a different idea (like changing a negative movie review into a positive one) while keeping the original style and structure as much as possible. The method does this by gently “steering” the AI’s internal thoughts toward a target idea during generation.
What questions are the authors trying to answer?
- Can diffusion LLMs (a kind of text AI that revises words anywhere in a sentence) be guided to change a sentence’s meaning in place without messing up its flow?
- Can this be done automatically (the AI decides which words to change), efficiently (without extra heavy prompts), and without retraining the model?
- Will the edited sentences still sound fluent and keep the original structure?
- How sensitive is the method to different settings (like how many steps to edit, or how aggressively to pick words to change)?
How does TimpaTeks work?
Think of a sentence like a necklace made of word “beads.” Autoregressive models are like a typewriter—they add beads from left to right. Diffusion LLMs (DLMs) are more like an eraser-and-pencil: they can erase and redraw beads anywhere in the necklace. TimpaTeks uses this “erase and redraw anywhere” ability to make small, targeted changes that shift the overall idea.
Here’s the approach in everyday terms:
- Build a “steering direction” for a concept
- The model looks at many examples of two opposite ideas (like positive vs. negative, or cat vs. dog) and computes their average internal “fingerprints.”
- The difference between these two fingerprints becomes the steer vector—a direction in the model’s idea space that points from one concept to the other.
- Decide which words to change
- For each word in the sentence, the model checks how aligned it is with the steer vector using a similarity score (cosine similarity).
- Words that don’t fit the target concept are more likely to be chosen for replacement.
- Edit in small steps
- The chosen words are masked (temporarily hidden).
- The model refills those masks while being gently nudged in the steer direction.
- It does this over a few steps, each time unmasking the easiest words first (those it’s most confident about), until the sentence matches the target idea.
Key idea: instead of writing a new sentence, TimpaTeks edits only what’s needed, keeping the rest of the sentence intact.
What did they test and how?
They tested TimpaTeks on two tasks:
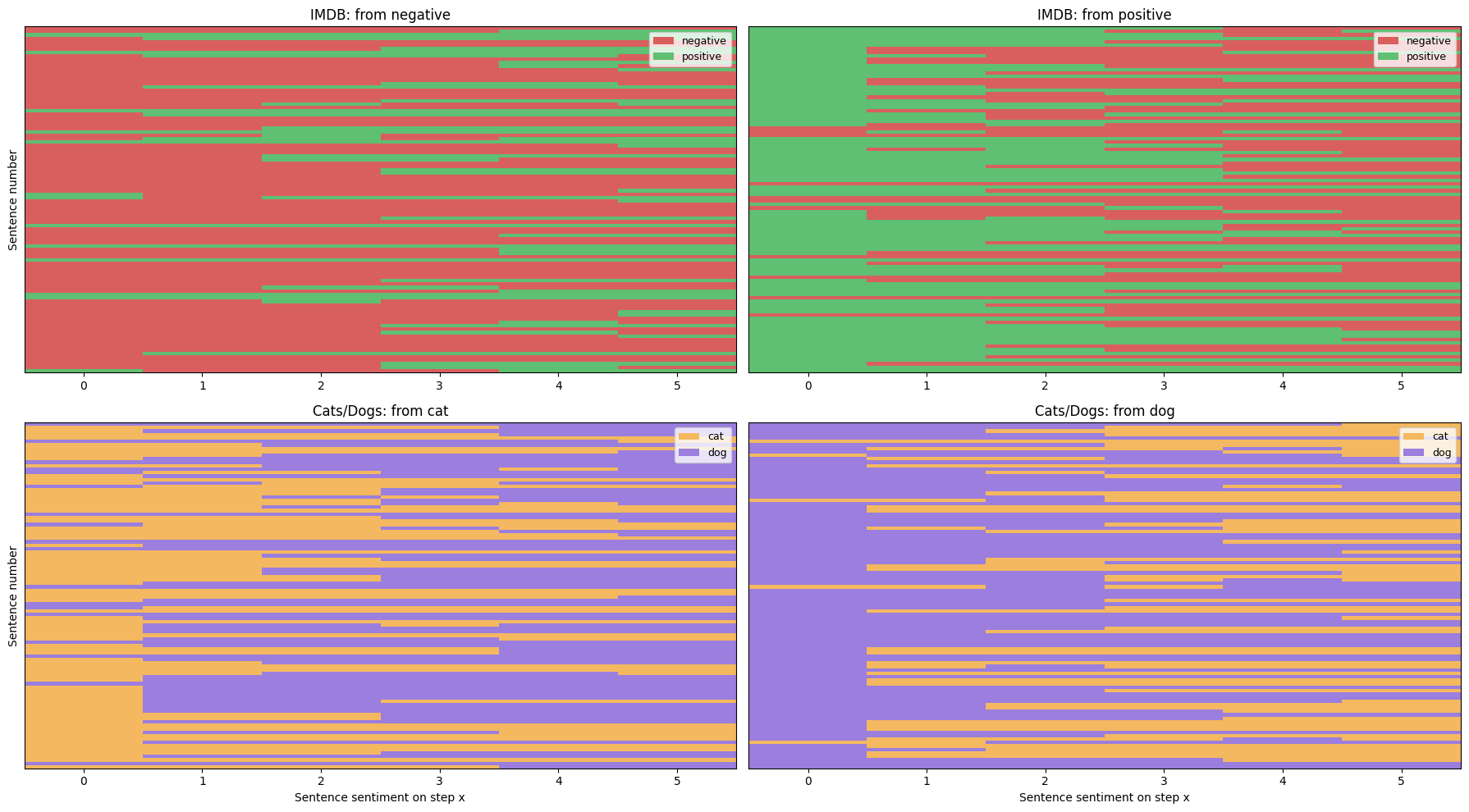
- IMDB movie reviews: flip sentence sentiment (negative → positive and positive → negative).
- A synthetic “CatDog” dataset: flip mentions and related wording between “cat” and “dog.”
How they measured success:
- Target concept success: Does an external checker think the result is the target class (e.g., “positive” or “dog”)?
- Fluency (perplexity): Does the sentence sound natural to a LLM? Lower perplexity means more fluent.
- Human preference: Do people think the edited sentence kept the original structure better than a prompt-based baseline?
They also studied:
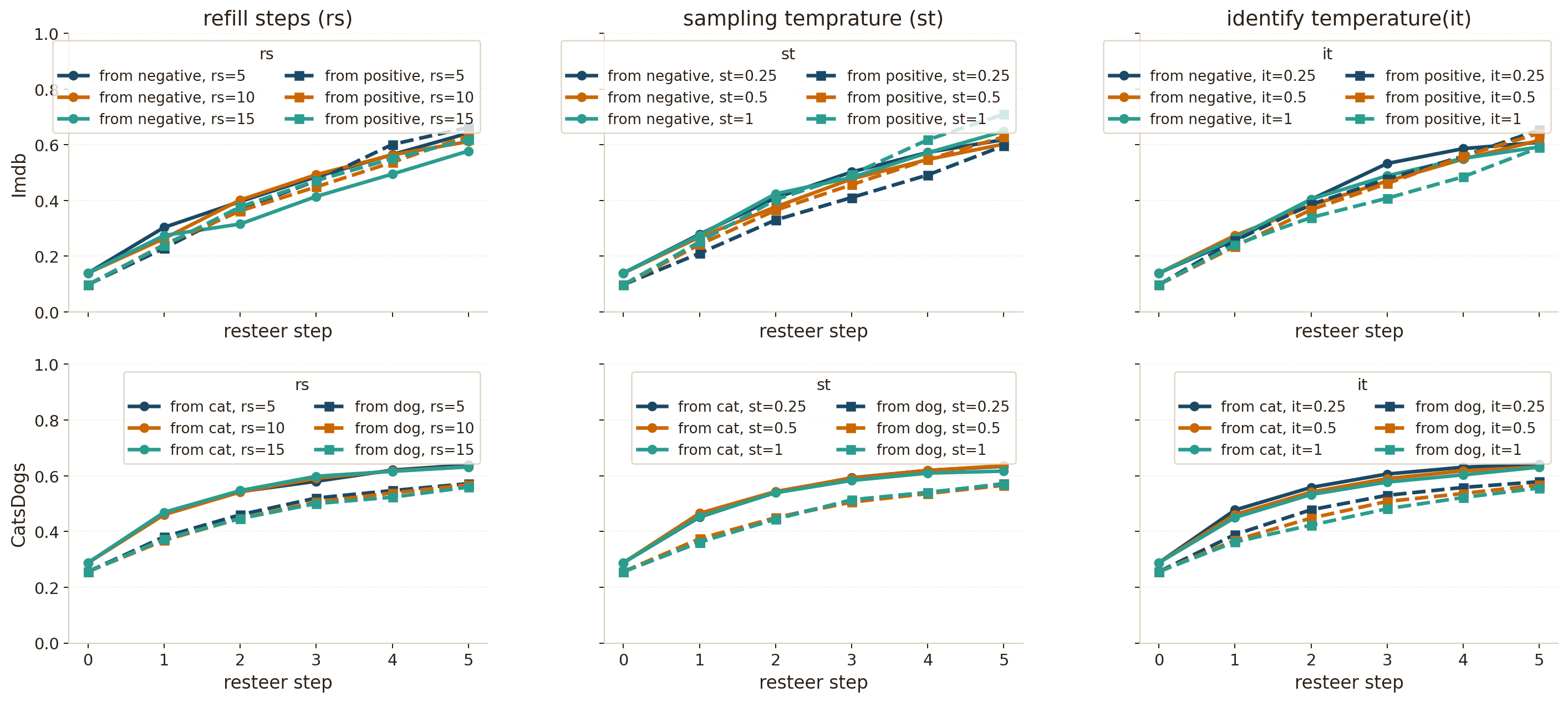
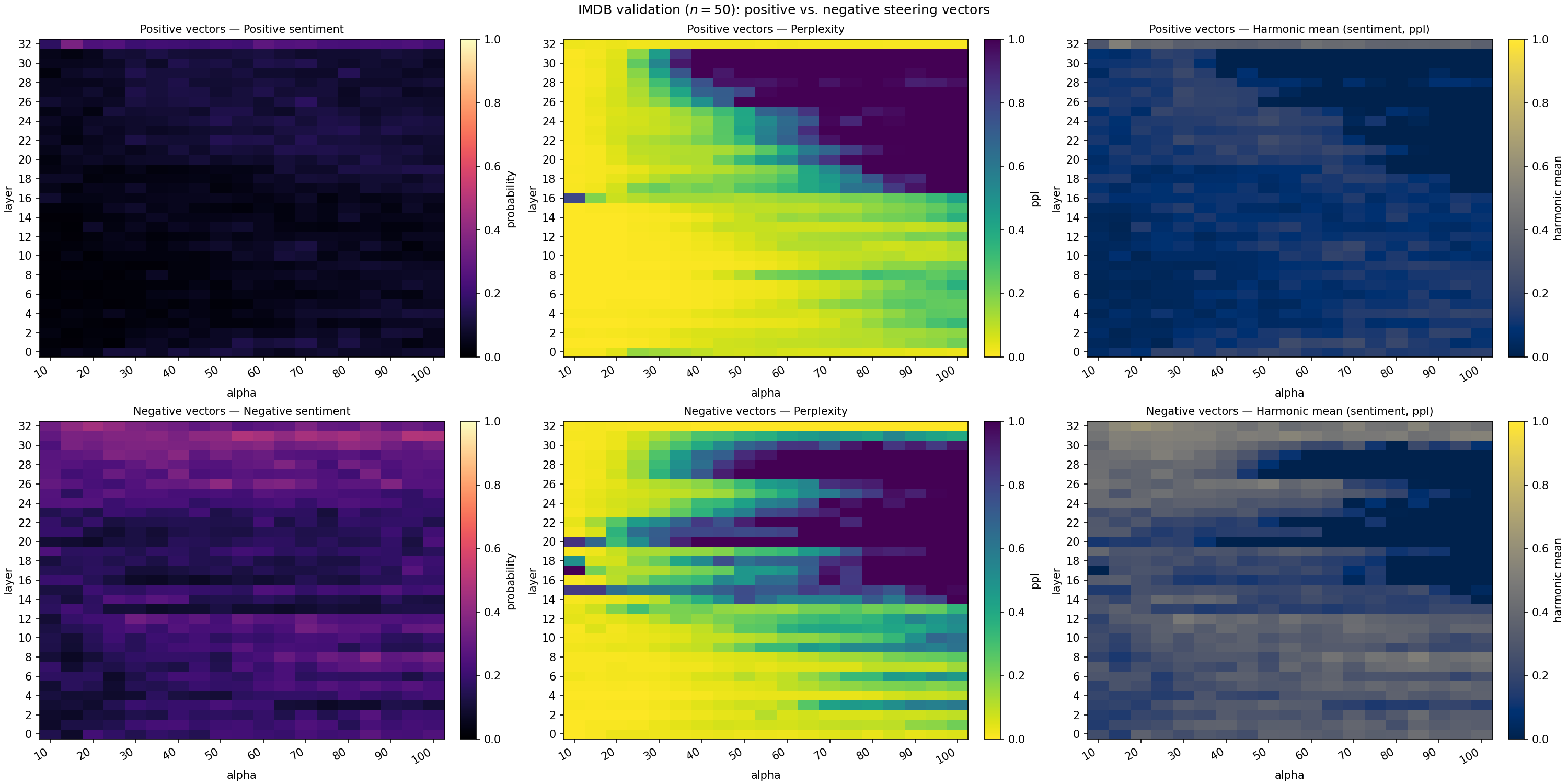
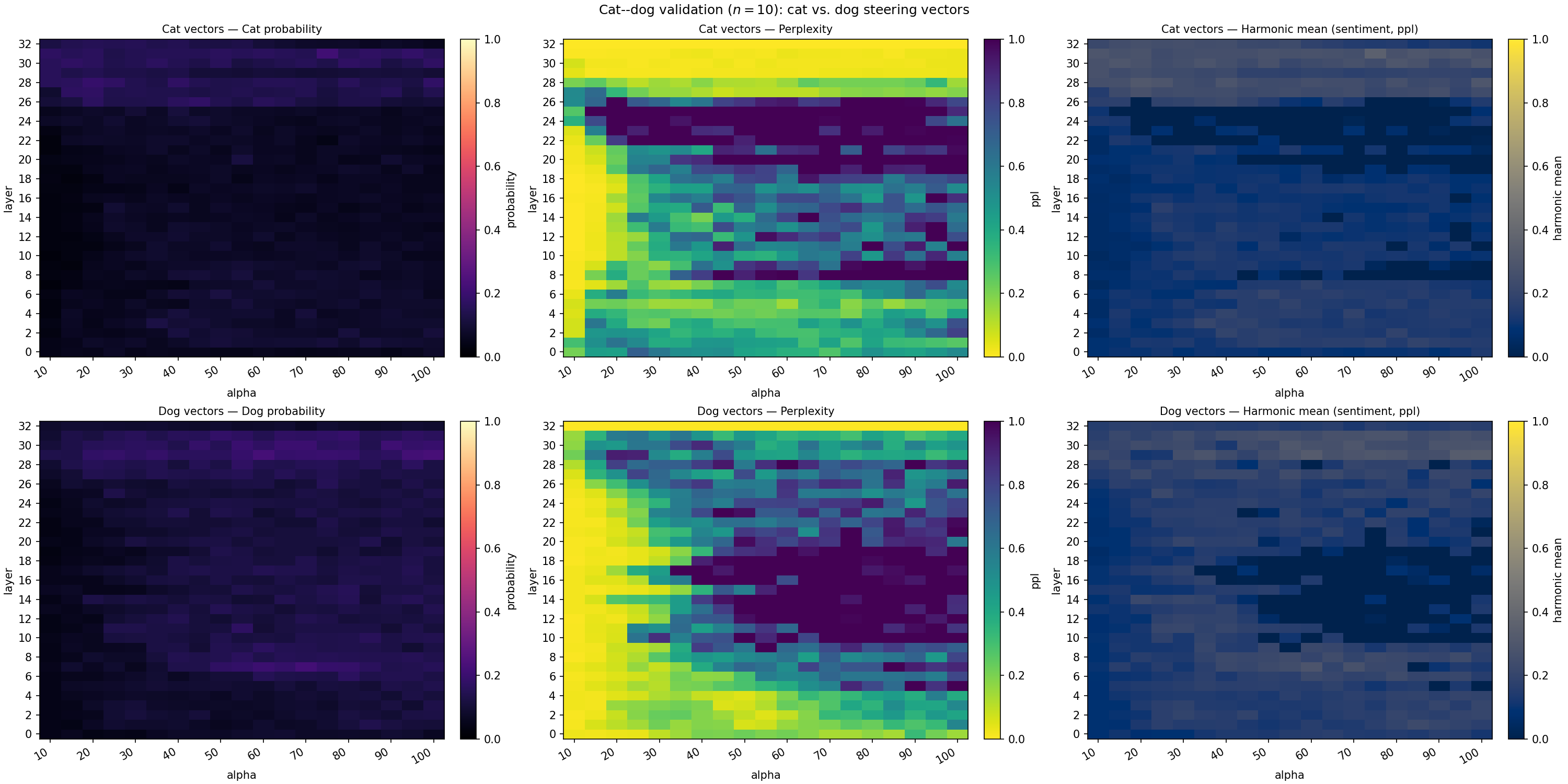
- Which layers of the model to steer (they found mid-to-late layers work best).
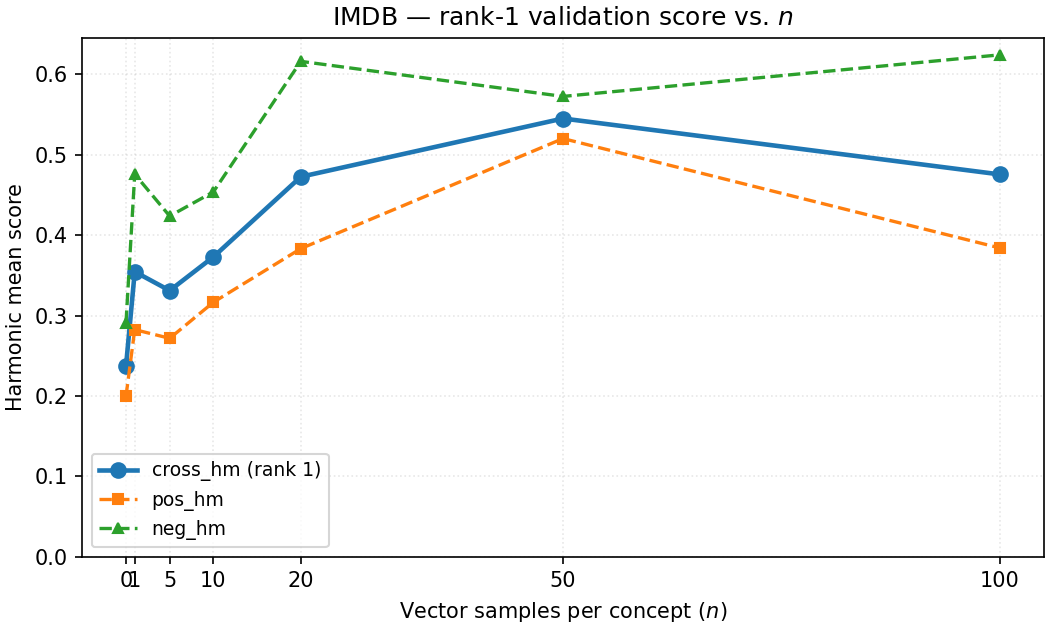
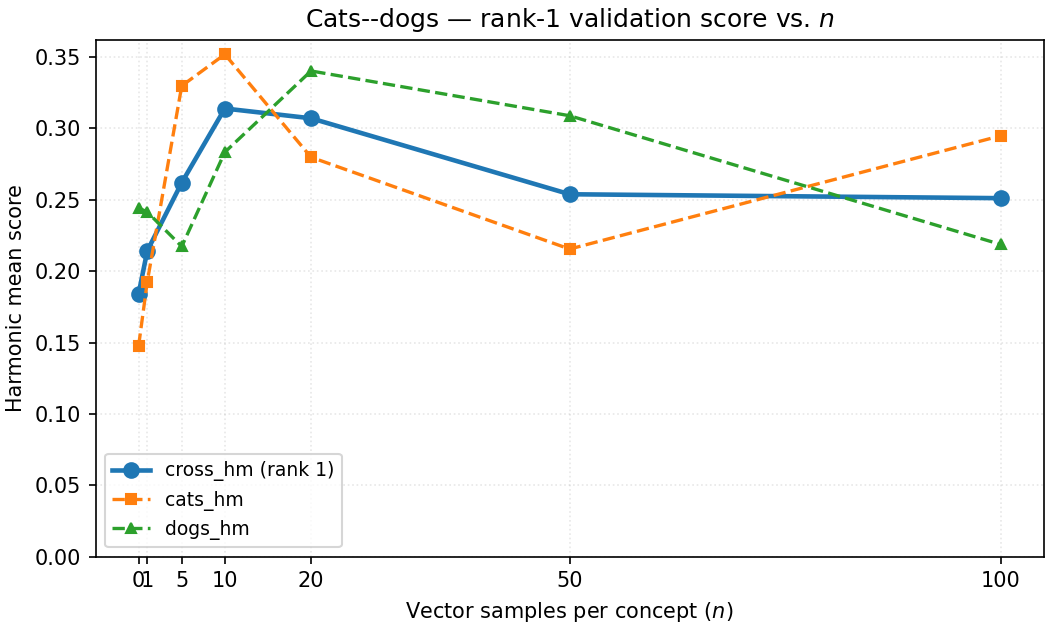
- How many examples to use when building the steer vector (a moderate amount worked best; too many didn’t help).
- How sensitive the method is to settings like temperature and number of steps (it was quite robust).
They compared TimpaTeks to a prompt-based baseline that asks the model to rewrite the sentence to match a new concept.
What were the main findings?
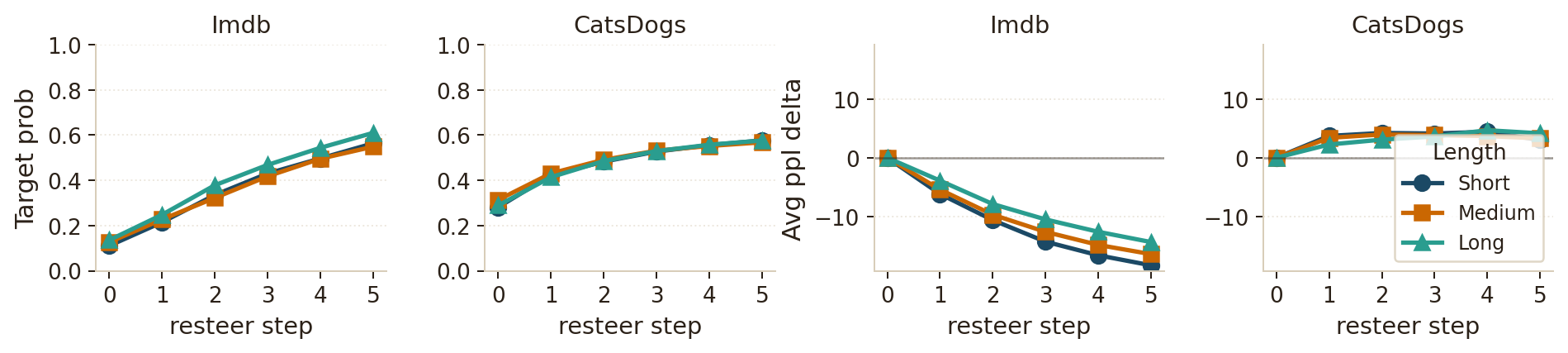
- It works: TimpaTeks reliably flips the target concept (sentiment or cat↔dog) while keeping the sentence coherent.
- Keeps structure better (for IMDB): Human judges preferred TimpaTeks over the prompting baseline for preserving the original sentence structure in movie reviews.
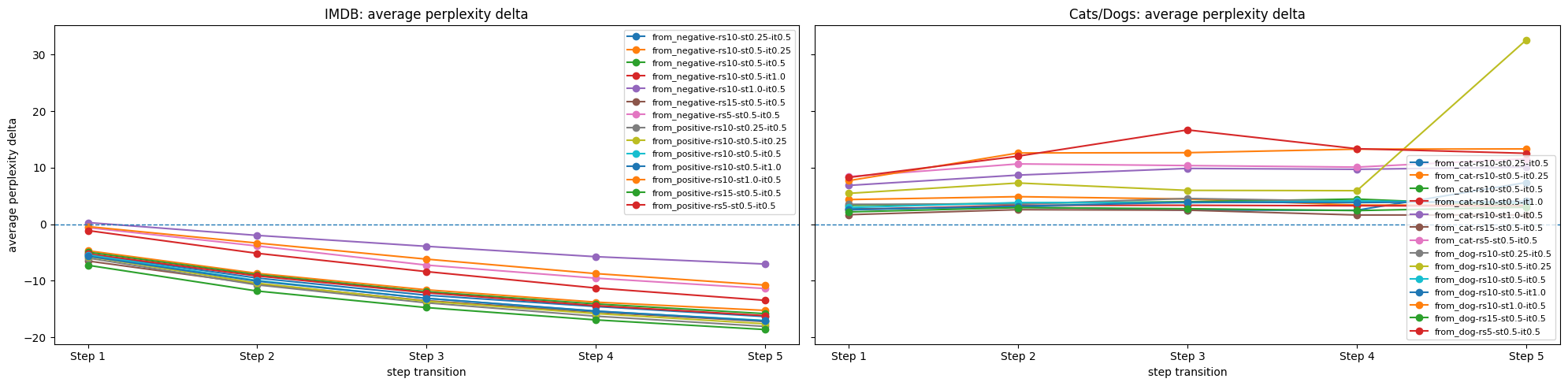
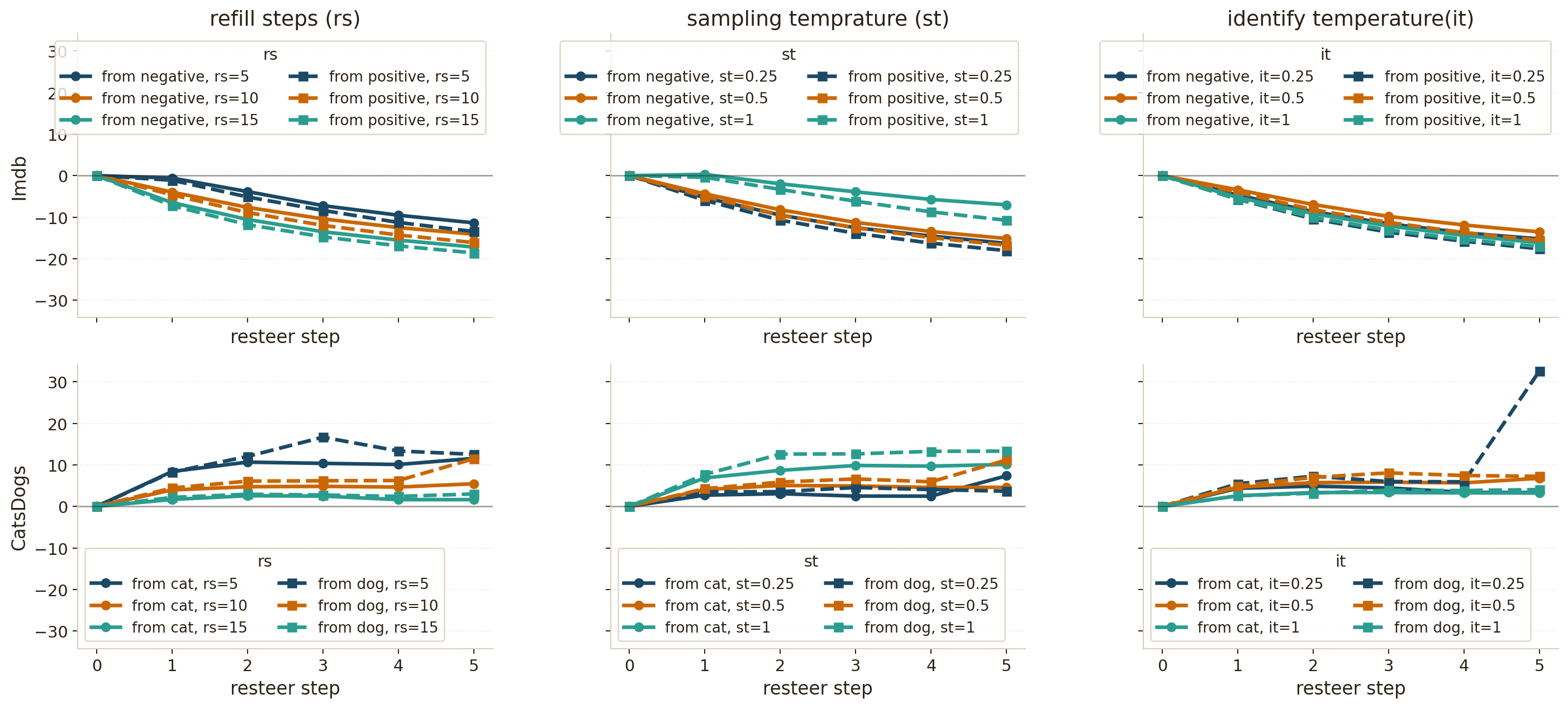
- Fluency is stable (sometimes better): The edited sentences usually stayed as fluent as the original and sometimes even became more fluent (lower perplexity).
- Robust to settings: Changing editing steps or temperatures didn’t dramatically affect success. That makes the method easier to use.
- Efficient: It’s computationally cheaper than prompt-based steering in diffusion LLMs because it edits the original sentence directly, instead of building a longer sequence with an instruction prompt plus a full new output.
- Mixed result on CatDog: For the simple “cat vs. dog” switch, the prompt baseline sometimes did fine by directly swapping words. TimpaTeks still worked but wasn’t always preferred by humans since the baseline’s straightforward replacement looked good on this simple task.
Why is this important?
- Practical text editing: This method is like a smart, careful editor—it changes just the right words to shift meaning while keeping the rest of the sentence intact.
- No retraining needed: It steers the model at run time, so you don’t need to fine-tune or make a special instruction-following model.
- Faster and cheaper within DLMs: By editing in place, it saves compute compared to prompt-based diffusion methods.
- Broad uses: Could help with tasks like:
- Making feedback more polite or more direct.
- Adjusting tone (formal vs. casual).
- Aligning text to a target topic or style while preserving the original’s structure.
Limitations to keep in mind
- Not fully tuned: They didn’t exhaustively search all settings, so there might be better combinations.
- Tested on one DLM (LLaDA-8B-Base): Results may vary on different diffusion LLMs.
- Synthetic dataset bias: The CatDog set is machine-generated, which can be less diverse than real-world text.
- Facts can drift: Because it replaces words without checking facts, it might change details in ways that aren’t accurate.
Bottom line
TimpaTeks shows that diffusion LLMs can be steered to edit sentences in place—switching concepts like sentiment or topic—while keeping the sentence’s flow and often its structure. It works reliably, is fairly easy to set up, tends to be efficient, and could become a useful tool for gentle, controlled text editing.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and unresolved questions that future work can address to strengthen, generalize, and validate TimpaTeks.
- Generalization across DLM architectures: Validate TimpaTeks on multiple diffusion LLMs (e.g., MDLM, DREAM, other bidirectional diffusion variants) to test whether findings like “mid–late layer concentration” and robustness to hyperparameters generalize across depths, attention patterns, and masking strategies.
- Stronger baselines: Compare against state-of-the-art text editing and control methods (e.g., AR activation steering, constrained decoding, RL-based attribute control, instruction-tuned rewriting, Levenshtein Transformer/CoEdit-style editors) rather than only a prompt-based baseline.
- Joint hyperparameter optimization: Conduct a principled, joint search over steering steps (k), refill steps (u), identification temperature (τ), sampling temperature (τs), and layer–α schedules (including per-layer strengths), using Bayesian optimization or bandit strategies; report stability, reproducibility, and sensitivity.
- Layer selection methodology: Replace grid sweeps with theoretically or empirically grounded selection (e.g., causal tracing, feature attribution, Fisher information, or sparse autoencoder feature maps) to identify which layers to steer, where to inject (residual vs MLP vs attention), and how much.
- Steering strength calibration: Study per-layer and per-token scaling strategies (e.g., adaptive α schedules, trust-region constraints, norm clipping) to prevent oversteering, reduce incoherence, and better balance concept transfer vs content preservation.
- Token selection mechanism: Evaluate alternatives to cosine-similarity averaging for token identification (e.g., gradient-based saliency, attention-weighted relevance, learned selectors, concept-specific classifiers) and analyze which selector yields the best trade-off between minimal edits and successful steering.
- Masking/filling schedule design: Operationalize and ablate the refill schedule (NumToFill) and unmasking policy (SelUnmask)—e.g., top-k confidence vs entropy-based selection, randomization, curriculum-based schedules—and quantify their effects on coherence and steering success.
- Dynamic stopping criteria: Replace fixed k/u with adaptive stopping (e.g., halt when target-concept probability crosses a calibrated margin, or when perplexity no longer improves) to reduce unnecessary edits and compute.
- Multi-attribute and compositional steering: Test whether TimpaTeks can control multiple attributes simultaneously (e.g., sentiment + formality), compose steer vectors, and resolve interference/conflicts between attributes; define metrics for compositional fidelity.
- Directional asymmetry analysis: Investigate why dog→cat was harder than cat→dog (dataset biases, lexical asymmetry, steering vector quality) and propose remedies (balanced corpora, debiased vectors, contrastive calibrations).
- Evaluation model bias: Replace or complement Qwen2.5-0.5B-Instruct with larger or ensemble scorers; quantify scorer sensitivity and agreement across models; calibrate token-level “target probability” metrics (e.g., beyond single tokens like “cat”/“dog,” use span-level or classifier-based concept detection).
- Coherence metrics beyond perplexity: Include grammar/fluency (GEC metrics), readability scores, syntactic well-formedness, and semantic coherence (e.g., topic consistency) to reduce reliance on scorer-specific perplexity.
- Content preservation and factuality: Add dedicated measures of meaning preservation (semantic similarity, NLI-based entailment, named-entity/number consistency checks), and propose constraints (copy mechanisms, locked spans, factuality gates) to avoid unintended factual drift.
- Human evaluation rigor: Expand human studies (more annotators, blinding, inter-annotator agreement, pre-registered criteria), and evaluate attribute transfer, content preservation, and structure retention on heterogeneous, real-world text.
- Real-world concept breadth: Move beyond IMDB sentiment and synthetic CatDog to naturally occurring concepts (toxicity, politeness, style, domain/topic, political stance, reading level), and measure performance under subtle/ambiguous boundaries.
- Long-form and multi-sentence contexts: Stress-test on paragraphs/documents, dialogues, and narrative tasks; examine how in-place steering propagates across sentences and whether coherence holds at discourse level.
- Multilingual and morphological robustness: Evaluate across languages and tokenization regimes (subword, character-level), and analyze whether token-level in-place edits preserve morphology and grammar in morphologically rich languages.
- Edit analysis and interpretability: Provide edit-level diagnostics (POS categories, semantic roles, rhetorical structures) of changed tokens; analyze whether steering targets concept-bearing tokens vs generic content words.
- Mechanistic understanding in DLMs: Develop evidence for the linear representation hypothesis in DLMs (e.g., feature-level steering via sparse autoencoders), and test whether similar “concept directions” exist and behave linearly across diffusion timesteps.
- Compute analysis realism: Go beyond simplified FLOPs estimates to report wall-clock time, attention complexity (O(n2)), memory footprint, and throughput on standardized hardware; measure speedups vs baselines across N, P, and T and under KV caching for AR models.
- Robustness to negation, sarcasm, and adversarial inputs: Evaluate concept transfer under linguistic phenomena that confound sentiment/topic detection; develop safeguards or specialized steering vectors for such cases.
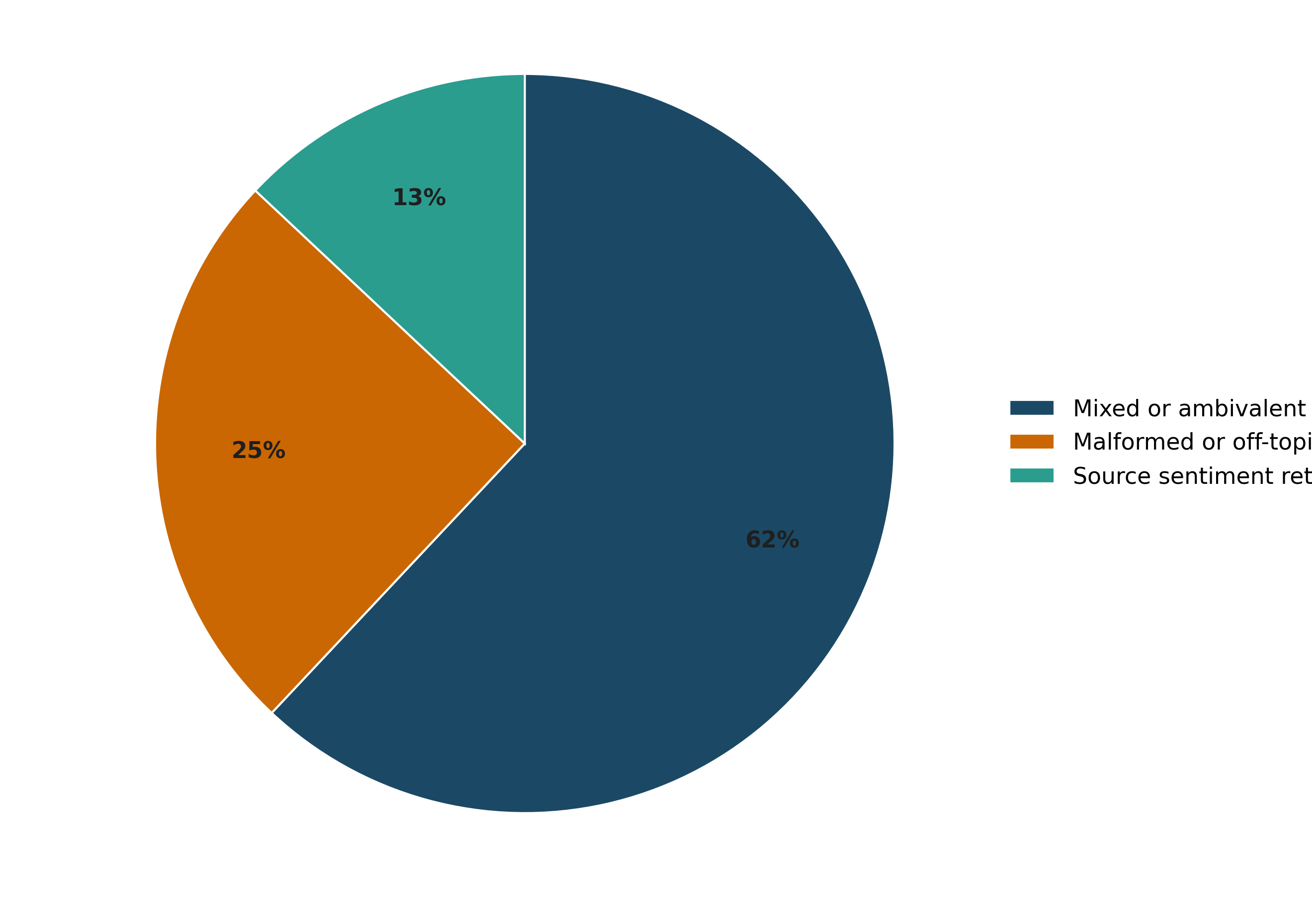
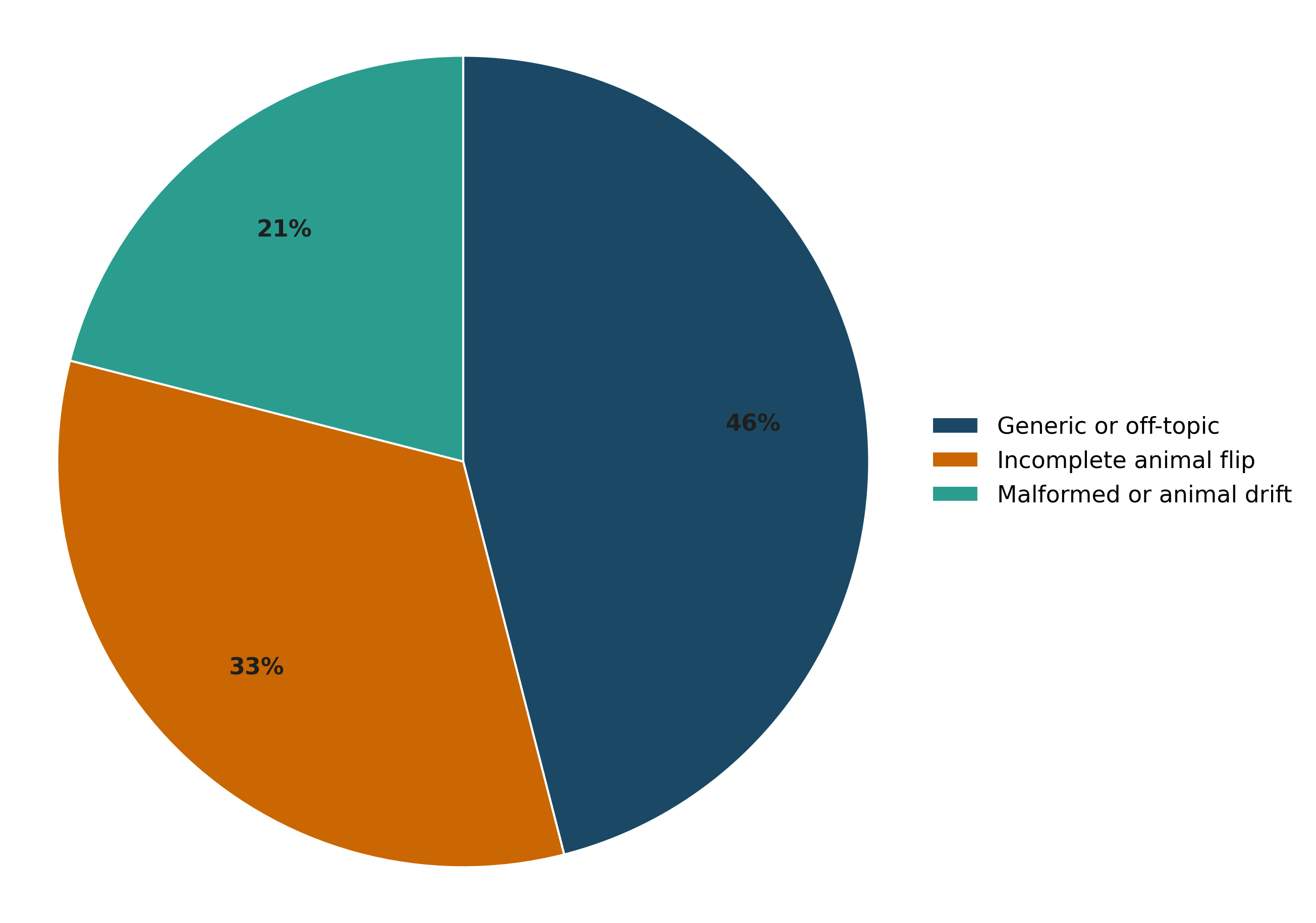
- Failure mode characterization and mitigation: Systematically categorize failures (generic/off-topic, incomplete flips, malformed outputs), correlate with hyperparameters/tokens/layers, and test targeted interventions (e.g., stronger copy constraints, improved token selection).
- Automatic steer-vector estimation: Explore robust vector estimators (whitening/shrinkage, PCA/CCA per-layer, contrastive feature extraction), justify why intermediate sample sizes maximize performance, and quantify variance across seeds/domains.
- Integration with instruction tuning: Test whether instruction-tuned DLMs help retain structure or improve controllability when combined with TimpaTeks, and study trade-offs (e.g., instruction-following vs in-place fidelity).
- Reproducibility details: Provide seeds, full hyperparameter grids, code paths for selection policies, and dataset release for CatDog (plus natural datasets), enabling exact replication and cross-lab benchmarking.
Practical Applications
Immediate Applications
Below are applications that can be built and deployed now with modest engineering, assuming access to a diffusion LLM (e.g., LLaDA-8B-Base) and small, curated text sets to derive steer vectors.
- Bold tone-flipping and A/B testing for marketing copy (Sectors: Marketing/Advertising, Software)
- What: Generate positive, neutral, or urgent variants of existing copy while preserving structure for controlled A/B tests.
- Potential tools/products/workflows: CMS/landing-page plugin; “tone toggles” in copy editors; batch pipeline that applies precomputed sentiment steer vectors and measures engagement lift.
- Assumptions/dependencies: Availability of a DLM with mask-based denoising; small labeled corpora for target tones; human-in-the-loop review to catch occasional off-topic or mixed-tone outputs.
- Editorial neutrality enforcement in newsrooms (Sectors: Media/Publishing, Enterprise Software)
- What: Reduce subjectivity or partisan phrasing in articles in-place (subjective→neutral steering) without rewriting structure.
- Potential tools/products/workflows: “Neutrality linter” in CMS; newsroom QA step that highlights candidate tokens for change and previews steered edits.
- Assumptions/dependencies: Concept vectors for subjectivity, hedging, or bias built from house style examples; editorial oversight to avoid over-normalization or hidden bias.
- Content detox/softening for Trust & Safety (Sectors: Online Platforms, Trust & Safety)
- What: Convert toxic, profane, or harassing phrasing to non-toxic alternatives while preserving message intent.
- Potential tools/products/workflows: Post-processing step in moderation pipelines; creator-side “soften language” button; batch cleanup for archives.
- Assumptions/dependencies: Toxic vs. non-toxic steer vectors; human review for high-severity content; clear escalation when detox fails (do not replace removal policies).
- Customer support writing normalization (Sectors: CRM/Customer Support)
- What: Enforce empathetic, calm, and consistent tone in replies without losing case-specific details.
- Potential tools/products/workflows: Helpdesk plugin that applies “empathetic” or “formal” steering; inline preview of edited tokens; audit trail of changes.
- Assumptions/dependencies: Tone steer vectors from exemplar tickets; guardrails to avoid factual drift when messages include numbers, names, or SLAs.
- Counterfactual data augmentation for ML robustness (Sectors: AI/ML, Academia)
- What: Flip attributes (e.g., sentiment, subjectivity) to create counterfactual pairs for training and fairness auditing.
- Potential tools/products/workflows: “Counterfactual Augmentor” that generates label-flipped examples in-place to improve classifier robustness; automatic logging of flip quality via target-probability metrics.
- Assumptions/dependencies: Small labeled sets per attribute; quality checks to ensure only the intended attribute changes; license compatibility for derived datasets.
- Compliance-friendly copy for e‑commerce and ads (Sectors: E‑commerce, AdTech, Legal/Compliance)
- What: Remove superlatives or unverifiable claims (promotional→factual steering) while preserving product specifics.
- Potential tools/products/workflows: Listing submission checker that suggests in-place edits to meet marketplace/policy rules; redline diff view for approvers.
- Assumptions/dependencies: Steer vectors derived from compliant vs. non-compliant templates; human compliance review for edge cases.
- Cost-efficient batch rewriting at platform scale (Sectors: Software Platforms)
- What: Large-scale in-place rewriting (e.g., policy-conforming tone) leveraging the method’s lower compute cost vs prompt-based DLM steering.
- Potential tools/products/workflows: Streaming rewrite service that applies in-place denoising without extra prompt windows; throughput monitoring using perplexity deltas as a fluency guard.
- Assumptions/dependencies: DLM infra availability; monitoring to detect generic/off-topic drift; concept vectors tuned for production data.
- Research toolkit for DLM control (Sectors: Academia/Research)
- What: Baseline for studying layer-wise steering, robustness to hyperparameters, and token-level edit selection in DLMs.
- Potential tools/products/workflows: “Steer Vector Hub” repository of reusable vectors; notebooks for layer–α sweeps and compute-cost benchmarking; human preference evaluation templates.
- Assumptions/dependencies: Access to DLM checkpoints (e.g., LLaDA); curated contrastive corpora; adherence to evaluation best practices (human + automatic metrics).
Long-Term Applications
These require further research, scaling, or integration beyond the paper’s current scope (e.g., stronger factuality guarantees, broader model coverage, cross-lingual robustness, multi-attribute disentanglement).
- Factuality-preserving attribute control with retrieval grounding (Sectors: Enterprise, Legal, Healthcare)
- What: In-place edits that change tone or formality while provably preserving facts via retrieval or constraints.
- Potential tools/products/workflows: RAG-augmented steerer that blocks token substitutions conflicting with cited evidence; “no-entity-change” mode for regulated documents.
- Assumptions/dependencies: Reliable entity/number locking; constraint-aware decoding for DLMs; audited evidence stores.
- Multi-attribute, disentangled control sliders (Sectors: Productivity Software, Platforms)
- What: Simultaneous, independent control of sentiment, formality, politeness, hedging, and subjectivity.
- Potential tools/products/workflows: “Style mixer” UI with sliders for each attribute; disentangled steer vectors discovered via sparse/monosemantic features; conflict resolution policies.
- Assumptions/dependencies: Advances in interpretable features and orthogonalization of directions; robust composition across layers/timesteps.
- Cross-lingual and locale-specific tone transfer (Sectors: Localization/Globalization)
- What: Locale-aware edits (e.g., honorifics, politeness levels, idioms) for multi-language content while preserving structure.
- Potential tools/products/workflows: Localization suite that applies per-locale steer vectors; QA workflows with bilingual reviewers; cross-lingual evaluation harnesses.
- Assumptions/dependencies: Multilingual DLMs; per-locale corpora to derive steer vectors; cultural calibration and governance.
- PII anonymization and sensitive-attribute obfuscation (Sectors: Healthcare, Finance, Legal, Privacy)
- What: In-place de-identification that replaces names, IDs, and locations with safe alternatives while maintaining readability.
- Potential tools/products/workflows: Hybrid system combining detectors with in-place diffusion edits; differential privacy audits; reversible pseudonymization when permitted.
- Assumptions/dependencies: High-precision PII detection; strict guarantees against leakage; compliance with HIPAA/GDPR and retention policies.
- Regulator toolkits for bias and fairness auditing (Sectors: Policy/Government, Finance)
- What: Generate large counterfactual corpora by flipping protected-attribute proxies to stress-test models and decisions.
- Potential tools/products/workflows: “Counterfactual Sandbox” for regulators to probe systems with controlled attribute flips; reporting on disparate impact deltas.
- Assumptions/dependencies: Ethical frameworks for attribute manipulation; governance to prevent misuse; transparent documentation of steering vectors.
- On-device/private writing assistants (Sectors: Mobile, Productivity, Privacy)
- What: Local, in-place tone edits for email/messages with no server round-trips.
- Potential tools/products/workflows: Lightweight DLMs or distillations; hardware-aware denoising schedules; battery/performance trade-off tuning.
- Assumptions/dependencies: Efficient DLM deployment on edge; memory-optimized steering; privacy-preserving telemetry.
- Creative writing and narrative retargeting (Sectors: Media/Entertainment)
- What: Subtle retargeting of theme, mood, or character voice across long-form text while keeping plot scaffolding.
- Potential tools/products/workflows: “Steering brush” in creative editors to apply concept changes to selected spans; iterative review workflows; version control for story variants.
- Assumptions/dependencies: Scaling to long documents; section-aware steering; guardrails for coherence across chapters and characters.
- Enterprise-wide communications governance (Sectors: Enterprise, HR/Compliance)
- What: Organization-level controls to enforce tone and inclusivity standards across emails, chats, and docs.
- Potential tools/products/workflows: Policy-driven steering profiles, department-specific vectors (e.g., Legal-formal, Support-empathetic); audits and opt-in controls for employees.
- Assumptions/dependencies: Change management and transparency; employee consent; continuous monitoring for unintended bias effects.
Cross-cutting assumptions and dependencies (affecting feasibility across applications)
- Model availability and coverage: Current evidence is limited to LLaDA-8B-Base; behavior may differ across DLM architectures. Replication on multiple DLMs is needed.
- Steer vector quality: Requires small, well-curated contrastive corpora per concept/attribute; too few or too many samples can degrade performance.
- Reliability and safety: In-place edits can introduce subtle factual drift; high-stakes domains need entity/number locking, retrieval checks, and human review.
- Language and domain scope: Most evidence is English; multilingual and specialized domains (legal/clinical) require domain-specific vectors and evaluation.
- Evaluation and monitoring: Automatic metrics (target probability, perplexity deltas) should be paired with human preferences and task-specific KPIs; failure modes include mixed sentiment, generic/off-topic drift, and incomplete flips.
- Compute and scale: While cheaper than prompt-based DLM steering, DLM infrastructure is less common than AR LLM serving; engineering investment is needed to operationalize in-place denoising at scale.
Glossary
- ablation: A systematic removal or variation of components or settings to study their effect on performance. "Extensive analysis, ablation, and method design for steering methodology in DLMs, including hyperparameter selection, effect of sentence length on effectiveness, compute cost analysis, and effectiveness on multiple concepts (sentiment and ``Cat vs. Dog") and demonstrate the robustness and efficiency of ."
- activation steering: An inference-time technique that alters internal activations to push model outputs toward a desired concept without retraining. "Activation steering is a popular method for modifying model output without training"
- attention mask: A tensor used to indicate which token positions should contribute to attention computations or averaging. "token hidden states were averaged with the attention mask to form example-level representations"
- autoregressive (AR) LLMs: Models that generate text token-by-token from left to right, conditioning each token on previous ones. "Most work on steering focuses on autoregressive (AR) LLMs"
- bidirectional attention: Attention mechanism that allows each token to attend to tokens on both sides, not just previous ones. "They use bidirectional attention and don’t strictly generate text step-by-step"
- concept tensor: A layer-wise aggregated representation capturing a concept across many examples and tokens. "We define the concept tensor layer-wise."
- conditional steering policies: Methods that decide when and how to steer based on the input or context. "conditional steering policies"
- Continuous Diffusion Models: Diffusion models operating in continuous spaces, often for non-text modalities like images. "Continuous Diffusion Models (which typically process other modalities like images rather than text)"
- contrastive steering vectors: Direction vectors derived from differences between representations of contrasting concepts to guide steering. "We build contrastive steering vectors from text samples per concept"
- cosine similarity: A measure of angular similarity between vectors, used here to score token–steering direction alignment. "via cosine similarity between the the token representation and the steer vectors"
- denoising: The iterative process of replacing masked/noisy tokens with cleaner predictions during diffusion-based generation. "as it performs denoising in-place rather than constructing an additional prompt-conditioned output sequence"
- denoising budget: The number of denoising steps (forward passes) allocated in diffusion-based generation. "let denote the denoising budget, i.e., the number of denoising forward passes"
- Diffusion LLMs (DLMs): Text generation models that iteratively mask and denoise tokens using bidirectional attention. "Diffusion LLMs (DLMs) are different."
- diffusion timesteps: The discrete steps in a diffusion process during which noise is added/removed and interventions can be applied. "by applying steering directions across diffusion timesteps"
- FLOPs: Floating-point operations, used here as a proxy for computational cost of forward passes. "\mathrm{FLOPs}_{\mathrm{DLM}"
- harmonic mean (HM): A metric-aggregation method that balances two scores by penalizing large disparities between them. "Utilizing HM (harmonic mean) as a way to balance both directions"
- hidden state: The internal vector representation of a token at a particular layer in a neural network. "Hidden state. Let model have decoder layers and hidden dimension ."
- identification temperature: A temperature parameter controlling the sharpness of token-selection probabilities for steering. "We analyze the effect of three key hyperparameters on steering success and text coherence: refilling steps~(), sampling temperature~(), and identification temperature~()."
- instruction-tuned models: Models fine-tuned to follow natural-language instructions. "without the need of instruction tuned models."
- KV caching: A technique in autoregressive transformers that caches key–value attention states to speed up decoding. "Autoregressive models with KV caching can often be more compute-efficient"
- Linear Representation Hypothesis: The idea that semantic concepts align with linear directions in representation space. "The Linear Representation Hypothesis"
- ℓ2-normalized concept vectors: Concept vectors scaled to unit length using the L2 norm before differencing to form steering directions. "the layer-wise difference between their -normalized concept vectors"
- mask token: A special placeholder token indicating positions to be predicted during masked/diffusion generation. "replacing each selected token with the model's mask token."
- masked diffusion LLMs: DLMs that operate by masking and denoising tokens across timesteps. "extend activation steering to masked diffusion LLMs"
- monosemantic features: Latent features that represent a single interpretable concept or attribute. "monosemantic features identified with sparse autoencoders"
- optimal transport: A mathematical framework for transforming one probability distribution into another, used here for distribution-aware steering. "distribution-aware methods based on optimal transport"
- perplexity: A measure of how well a LLM predicts a sequence; lower indicates more fluent or likely text. "lowers sentence perplexity"
- prefill pass: The initial forward pass in autoregressive decoding used to populate the cache before token-by-token generation. "require one prefill pass followed by cached token-by-token decoding."
- prompt-based DLM steering: Steering generation by adding instruction prompts rather than editing activations in-place. "prompt-based DLM steering"
- residual stream: The pathway in transformer architectures that carries layer outputs and to which interventions can be added. "and added them to the residual stream to influence outputs without retraining"
- semi-autoregressive: A generation regime that produces tokens in blocks rather than strictly one-by-one. "LLaDA-style generation is semi-autoregressive at the block level"
- sigmoid function: A squashing function mapping real numbers to (0,1), used to convert scores to probabilities. "where is the sigmoid function"
- sparse autoencoders: Autoencoders that encourage sparsity in latent representations to discover interpretable features. "monosemantic features identified with sparse autoencoders"
- steering strength parameter: A scalar (possibly per layer) that scales the magnitude of the steering direction applied to activations. "A layer-wise steering strength parameter "
- steering tensor: A set of per-layer steering vectors assembled into a tensor that is added to hidden states. "Let be the steering tensor"
- steering vector: The per-layer vector that encodes a direction in activation space associated with a target concept. "where denotes the steering vector"
- TF-IDF: Term Frequency–Inverse Document Frequency, a text-weighting scheme used here for cosine similarity comparisons. "using TF-IDF cosine similarity"
- top-p: Also known as nucleus sampling; sampling tokens from the smallest set with cumulative probability ≥ p. "top- $0.95$"
- WordNet-style definition: A concise lexical definition in the style of the WordNet database used to guide synthetic data generation. "using a fixed WordNet-style definition"
Collections
Sign up for free to add this paper to one or more collections.