- The paper introduces per-token task embeddings to explicitly isolate roles, addressing token disambiguation in multi-task video editing and generation.
- It employs dual-path conditioning that fuses high-level semantic guidance from vision-language models with fine-grained spatial detail from VAEs.
- Progressive multi-task training ensures compositional generalization, enabling TIDE to outperform prior methods across diverse video editing benchmarks.
TIDE: Task-Isolated Diffusion for Unified Video Editing and Generation
Recent advances in Diffusion Transformers (DiTs) have led to substantial progress in video generation and editing, yet prevailing solutions fragment capabilities across task-specific models. While unified frameworks for image generation/editing have emerged, video models face three entrenched challenges: (1) conditioning disambiguation across heterogeneous tokens (e.g., source, reference, and target), (2) achieving the dual objectives of semantic intent and structural fidelity, and (3) harmonizing diverse multi-task objectives with conflicting data distributions.
TIDE addresses unified video editing and generation via a conditional denoising formulation, accepting text instructions, optional visual latents, and explicit task identifiers per token, thereby covering subject-reference video generation, reference-guided editing, and instruction-based editing within the same architecture.
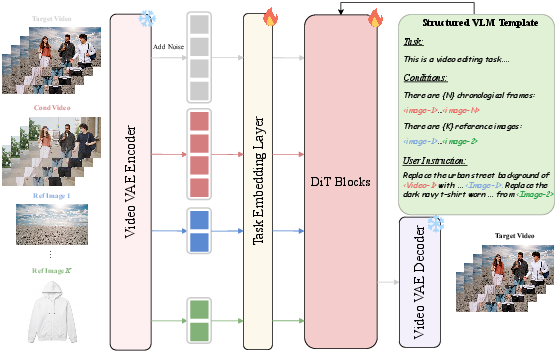
Figure 1: Overview of TIDE. Per-token task embeddings isolate heterogeneous conditioning tokens within shared self-attention (Left), while dual-path conditioning combines VLM-based semantic guidance with VAE-encoded latent detail (Right).
Core Architectural Innovations
Per-Token Task Embedding
TIDE introduces a learnable per-token task embedding table, assigning each input token a task-specific identifier. These embeddings explicitly demarcate token roles (target, source, reference) at the attention level. For multi-reference scenarios, each reference receives a unique identifier, ensuring robust identity disentanglement and preventing attribute leakage—a limitation observed in prior approaches such as VACE and VINO, which either require specialized encoders or boundary schemes that struggle as conditioning source counts vary. Task embedding enables lightweight and scalable isolation without auxiliary encoders or complex positional schemes.
Dual-Path Conditioning
No single conditioning mechanism suffices for both semantic comprehension and structural detail preservation. TIDE utilizes a dual-path strategy: (a) a vision-LLM (Gemma-3-12B-IT) encodes text and visual references jointly for high-level semantic guidance, and (b) a Video VAE path retains fine-grained latent spatial detail. These are injected respectively via cross-attention and self-attention, enabling complementary conditioning. Ablation confirms that removing either channel severely degrades both prompt compliance and identity fidelity.
Multi-Task Progressive Training
Mixing heterogeneous tasks (editing, reference-guided generation, multi-reference) without curriculum leads to severe inter-task interference. TIDE implements progressive training in three stages: (1) instruction-based editing only, (2) mixed task introduction including reference-guided editing and S2V generation, and (3) final refinement with ratio balancing for underrepresented categories. This approach prevents mode-collapse and ensures compositional generalization across tasks.
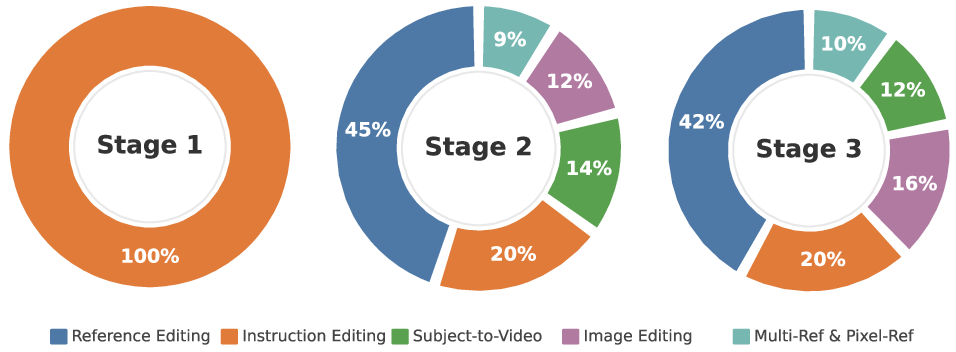
Figure 2: Data composition ratios across the three progressive training stages. Stage 1 uses only instruction-based editing data; Stage 2 introduces the full multi-task mixture; Stage 3 refines sampling ratios to balance underrepresented categories.
TIDE is evaluated on OpenVE-Bench (instruction-editing), TIDE-Bench (multi-reference editing), and OpenS2V (subject-to-video generation), outperforming prior open-source methods and matching or surpassing several closed-source baselines.
Instruction-Based Editing
TIDE achieves best average scores among open-source systems, especially in categories requiring fine-grained, localized edits (object addition, background change, subtitle editing). Dual-path conditioning is shown to be necessary for achieving both semantic compliance and structural preservation.

Figure 3: Qualitative comparison on OpenVE-Bench.
Multi-Reference Editing
TIDE exhibits significantly better Reference Faithfulness and Edit Completeness than VINO and Kling-O1, with per-token task embeddings being critical for avoiding copy-paste artifacts and for compositional control. VINO, lacking explicit task isolation, devolves into reference copy-pasting without meaningful editing.

Figure 4: Qualitative comparison on TIDE-Bench.
Subject-to-Video Generation
On OpenS2V, TIDE outperforms all open/open-source baselines in both aesthetics and naturalness, with strong Nexus alignment and motion metrics. Multi-task training enhances generation by providing cross-task semantic and structural supervision.

Figure 5: Qualitative comparison on multi-reference subject-to-video generation.
Progressive Training and Component Ablation
Removal of the VLM conditioning path or improper task embedding assignments leads to drastic drops in both edit and generation quality. Progressive training stages demonstrate significant improvement in multi-reference editing and only minimal trade-off in instruction editing specialization.

Figure 6: Progressive training ablation on a TIDE-Bench style transfer case. Stage 1 conflates reference content with style; Stage 2 partially leaks; TIDE (Full) transfers only the style.
Qualitative Analysis
Across diverse benchmarks, TIDE performs precise, instruction-following edits without unintended changes to unedited content. In multi-reference tasks, TIDE integrates the correct visual identities, preserves scene details, and exhibits consistent styling. S2V cases demonstrate accurate subject preservation (human and object), robust prompt adherence, and temporal coherence.

Figure 7: Qualitative ablation on an OpenVE-Bench editing case. Only the full TIDE model faithfully follows the instruction while preserving the scene.

Figure 8: Single-reference object addition on TIDE-Bench.

Figure 9: Multi-reference editing: background change + object removal.

Figure 10: Multi-reference editing: dual object removal.

Figure 11: Multi-reference editing: object removal + replacement.

Figure 12: Subject-to-video generation on OpenS2V with human and object references.
Guidance Scaling and Robustness
Evaluation across classifier-free guidance scale scfg shows TIDE is robust, with scfg=4.0 attaining optimal trade-off for instruction and multi-reference editing. Lower scales slightly favor editing, higher scales degrade both metrics.
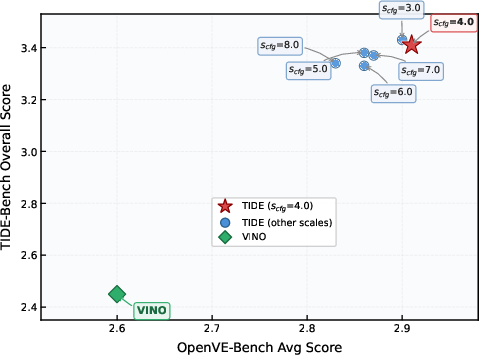
Figure 13: Effect of CFG scale scfg on OpenVE-Bench and TIDE-Bench.
Practical and Theoretical Implications
TIDE demonstrates that explicit token-level task isolation and hybrid conditioning pathways are scalable solutions to unified video generation/editing. This formalizes heterogeneous tasks into a shared generative problem, establishing the foundation for future models handling arbitrary input types and roles. The progressive training regime empirically validates curriculum-based multi-task harmonization.
Practically, TIDE enables plug-and-play expansion to new roles (object, style, subject) and compositions with minimal architectural modification, portending unified frameworks for downstream creative and industrial video applications. Theoretically, the architecture corroborates the importance of explicit role-awareness in attention models for compositional generalization and reveals that attention-bound latent concatenation without isolation is insufficient for robust multi-reference conditioning.
Future Directions
Extension to multi-shot editing (coherent edits across scene transitions/cuts) and audio-aware conditioning (joint audio-visual editing/generation) are immediate avenues. The task embedding abstraction is amenable to cross-modal expansion, and audio-visual foundation models such as LTX-2 have demonstrated the feasibility. Incorporating these aspects will accelerate the deployment of fully multimodal, unified generative/editing systems.
Conclusion
TIDE establishes state-of-the-art performance across unified video editing, reference-guided editing, and subject-to-video generation. Its per-token task embeddings and dual-path conditioning resolve the conditioning disambiguation and duality bottlenecks, while progressive curriculum training ensures robust multi-task convergence. TIDE sets a new baseline for unified generative modeling in video, with implications for multimodal expansion and compositional editing frameworks.