ViFeEdit: A Video-Free Tuner of Your Video Diffusion Transformer
Abstract: Diffusion Transformers (DiTs) have demonstrated remarkable scalability and quality in image and video generation, prompting growing interest in extending them to controllable generation and editing tasks. However, compared to the image counterparts, progress in video control and editing remains limited, mainly due to the scarcity of paired video data and the high computational cost of training video diffusion models. To address this issue, in this paper, we propose a video-free tuning framework termed ViFeEdit for video diffusion transformers. Without requiring any forms of video training data, ViFeEdit achieves versatile video generation and editing, adapted solely with 2D images. At the core of our approach is an architectural reparameterization that decouples spatial independence from the full 3D attention in modern video diffusion transformers, which enables visually faithful editing while maintaining temporal consistency with only minimal additional parameters. Moreover, this design operates in a dual-path pipeline with separate timestep embeddings for noise scheduling, exhibiting strong adaptability to diverse conditioning signals. Extensive experiments demonstrate that our method delivers promising results of controllable video generation and editing with only minimal training on 2D image data. Codes are available https://github.com/Lexie-YU/ViFeEdit.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces ViFeEdit, a new way to teach a video-making AI model to edit videos without using any training videos. Instead, it learns only from regular 2D images. The goal is to let the model do many kinds of video edits (like changing style or swapping objects) while keeping the motion smooth and consistent across frames.
What questions did the researchers ask?
- Can we train a video editing model using only images, without any video data?
- Can we make edits that look good in each frame (spatial quality) and also stay consistent across time (temporal consistency)?
- Can this be done quickly and with very little extra training?
How did they do it?
Think of a video as a flipbook: each page is a picture (space), and flipping through them creates motion (time). Most current video AIs learn space and time together, which makes them powerful—but also very hard to retrain without lots of videos.
The authors’ key idea is to separate “space” from “time” when fine-tuning the model, so the model can learn edits from single images while still keeping its built-in sense of motion.
Key ideas explained simply
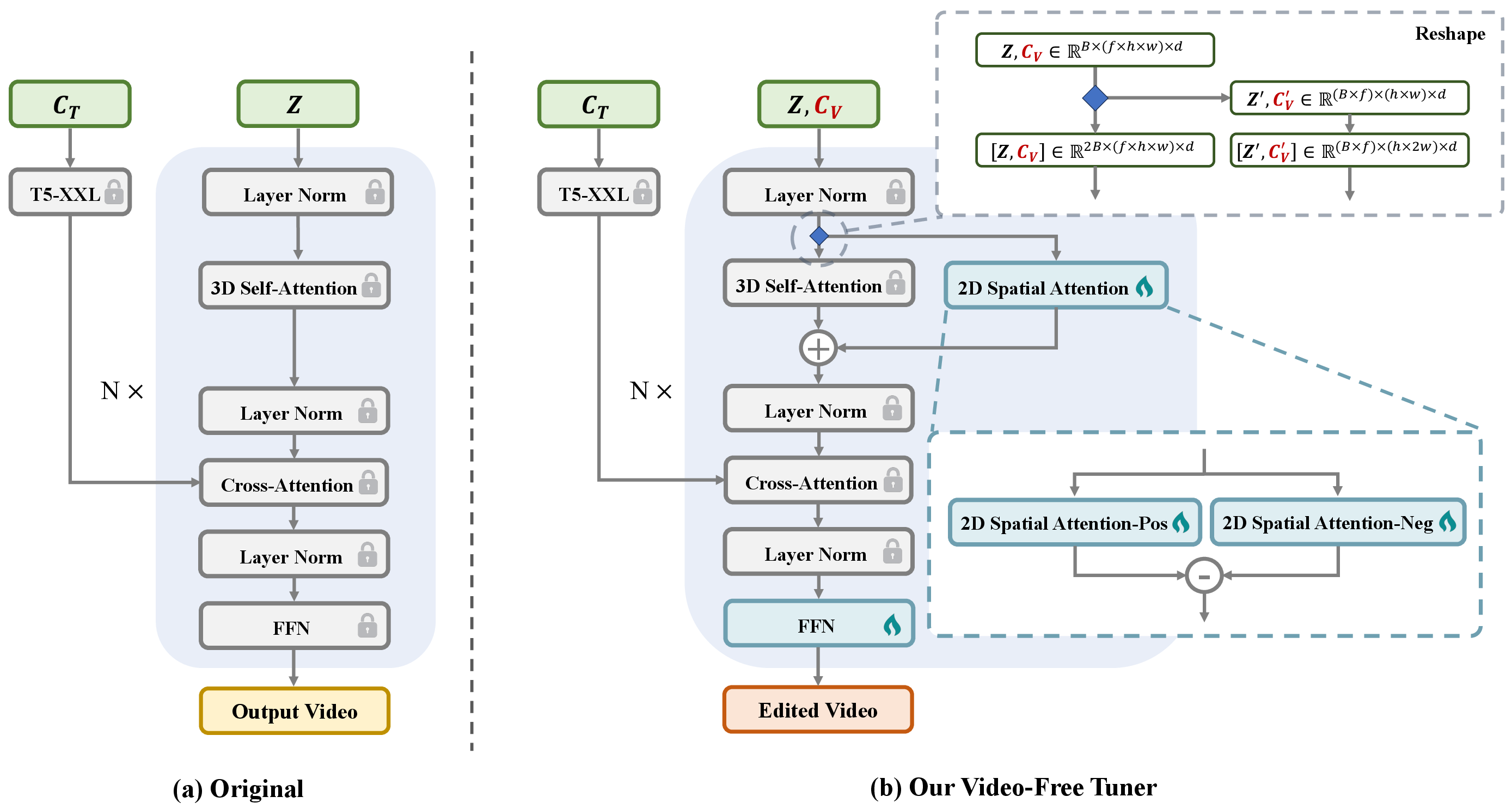
- Spatial vs. temporal “decoupling”
- Spatial = what each frame looks like (colors, shapes, objects).
- Temporal = how frames change over time (motion, smoothness).
- They keep the model’s “time brain” frozen (so it keeps good motion), and only adjust the “space brain” using images.
- Adding two special 2D “attention” modules
- Attention is how the model decides what to focus on.
- The authors add two new 2D attention blocks that look only within each frame (not across time): one acts like a highlighter (enhances what you want), and the other acts like an eraser (suppresses what you don’t).
- These two blocks start out balancing each other, so the model behaves the same as before at the beginning, then gradually learns to edit.
- Dual-path pipeline (two lanes that meet at the right time)
- Instead of mixing the noisy video the model is trying to generate with the input reference (like the source video or image) too early, they process them in separate lanes.
- These lanes only interact inside the new 2D attention blocks, so the original “time” parts of the model stay untouched and motion stays stable.
- Separate “noise levels” for different inputs
- During training, the model learns to turn noisy stuff into clean images/videos. The authors tell the model: “The thing you’re generating is noisy right now, but the reference you’re copying from is clean.”
- This clear signal makes training more stable and faster.
- Optional “head start” from the input video
- They can start the generation from a lightly noised version of the source video (like tracing over a faint sketch), to help preserve structure.
- Tiny, efficient training
- They only update a small number of added parameters (think “clip-on modules” rather than retraining the whole model).
- They train on small sets of image pairs (about 100–250), not giant video datasets.
What did they find?
ViFeEdit can adapt a text-to-video model to do many video edits—using only images for training—while keeping motion smooth and the background stable. In tests, it:
- Handled six fine-grained editing tasks: style transfer, rigid object replacement (e.g., swapping a car), non-rigid replacement (e.g., changing an animal or clothing), color changes, object addition, and object removal.
- Preserved temporal consistency (no “frozen frames” or flickering) better than methods that trained the whole model with images.
- Produced more faithful edits than training-free tricks that only tweak attention during generation.
- Learned faster and more stably thanks to the dual-path design and separate noise settings.
- Worked well with small amounts of image data and minimal compute.
- Could handle multiple tasks within a single fine-tuned add-on (not just one task per add-on).
Why this matters: most competing video editing systems need lots of paired video data or heavy training. ViFeEdit avoids that by learning edits from images while reusing a strong, pre-trained video model’s motion abilities.
Why does this matter?
- Lower cost and easier training: You don’t need massive video datasets (which are hard to collect and label). A small image set is enough.
- Consistent, better-looking results: Edits look right in each frame and stay stable across the whole video.
- Flexible and practical: The same approach can handle many editing tasks, and can be expanded to new ones quickly.
- Wider access: Creators, smaller labs, and developers can get high-quality video editing without huge computing resources.
In short, ViFeEdit is like teaching a skilled animator new drawing styles and edit tricks using only still images—while letting their sense of timing and motion remain as good as ever.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Scope of temporal edits: Because 3D attention is frozen, the method likely cannot modify motion semantics (e.g., retiming, trajectory changes, camera path edits, viewpoint transitions). How to extend ViFeEdit to edits that require changing temporal dynamics, not only spatial appearance?
- Generalization beyond the Wan2.1 backbone: The approach is only demonstrated on Wan2.1-T2V-1.3B. Does the reparameterization transfer to other video DiTs (e.g., CogVideoX, HunyuanVideo), factorized attention designs, or U-Net–style video models? Provide cross-backbone validation and any required adaptation steps.
- Long-form and high-resolution scalability: Experiments are limited to ~81 frames at 480p. What are memory/latency trade-offs and failure modes at 720p/1080p and multi-minute durations? Quantify VRAM, throughput (fps), and quality (e.g., FVD) under scaling.
- Token doubling overhead: The dual-path design effectively doubles tokens (by concatenation along batch/spatial dimensions). What is the exact compute/memory overhead per block and how does it scale with sequence length and resolution? Are there efficient variants (e.g., sparse or cross-attention-only coupling)?
- Breadth and robustness of evaluation: The study relies primarily on VBench and VLM-based metrics (FiVE-Acc via Qwen-VL). Include human studies and standard video metrics (FVD, VFID, tLPIPS, warping error) and stress tests (fast motion, motion blur, rolling shutter, dynamic lighting, rapid occlusions).
- Identity preservation and human-centric evaluation: No explicit tests on identity fidelity (faces, hands). Evaluate identity metrics (e.g., face-ID similarity) under style transfer and edits, and quantify trade-offs against edit strength.
- Occlusion-aware consistency: How robust is per-frame spatial editing to occlusions and disocclusions over time without masks? Test on occlusion-rich benchmarks and analyze failure cases at occlusion boundaries.
- Region-controlled editing: The framework does not natively support masks or spatial constraints. How to incorporate optional masks/soft attention maps while retaining temporal consistency without video supervision?
- Multi-condition generality: Claims of adaptability to “diverse conditioning signals” are not systematically demonstrated. Provide controlled studies with depth, pose, sketches, optical flow, and multi-modal combinations; report when conflicts arise.
- Compositional and multi-task editing: While a small multi-task LoRA is shown, the extent of task interference, catastrophic forgetting, and compositionality (e.g., simultaneous color change + object replacement + style) remains unquantified. Evaluate continual learning and task mixing at scale.
- Sensitivity to LoRA configuration: Only rank-32 LoRA is reported. How do rank, target layers, and learning rates affect quality, temporal stability, and convergence? Provide ablations and guidelines.
- Positive–negative spatial attention analysis: Theoretical and empirical understanding is limited. What is the contribution of the sign-aware design beyond zero-initialization? Analyze gradient flow, stability, and alternatives (e.g., gated residuals, contrastive objectives).
- Initialization and reusability of spatial priors: The claim that initializing 2D attention from 3D attention reuses “rich spatial priors” is not quantified. Compare different initializations (random, zero-conv, layer-wise copy) with controlled training budgets.
- Separate timestep embeddings: The benefit is shown qualitatively. Provide quantitative convergence curves, ablations over schedules and embedding parametrizations, and compatibility with other noise schedulers (e.g., EDM, VP/VE SDEs, different rectified-flow variants).
- Optional SDEdit-style noise prior: The effect of the hyperparameter α is not analyzed. Provide sensitivity plots of α vs. edit strength, fidelity, and temporal stability, and recommendations per task.
- Failure mode characterization: Frozen frames were mentioned as a risk for naïve tuning, but failure analysis for ViFeEdit itself (e.g., over-smoothing, ghosting, texture drift, temporal lag in edits) is missing. Include systematic failure categorization and mitigation tips.
- Motion–content trade-off controls: How can users control edit strength vs. content preservation at inference (e.g., scaling of positive/negative branches, guidance weights)? Provide inference-time knobs and their effects.
- Dependence on synthetic image pairs: Training sets are small (100–250 pairs) and largely synthetic (LLM-prompted and model-edited images). Assess domain shift to real-world edits and real paired video, and report performance under real, noisy, or imperfect image supervision.
- Editing tasks changing 3D structure: Per-frame spatial editing may struggle with 3D geometry-consistent changes (e.g., adding limbs/parts that obey parallax and articulation). Evaluate on 3D-consistency benchmarks or integrate lightweight temporal/3D priors.
- Preservation of base model capabilities: Does attaching LoRA adapters for editing degrade the base T2V model on unrelated prompts? Report zero-shot generation quality before/after loading adapters and investigate adapter composition/merging.
- Integration with tracking and correspondence: No use of cross-frame correspondences or optical flow to guide consistent edits. Explore plug-in trackers or token correspondences to improve identity and part-level stability.
- Ethical and safety considerations: The method enables strong video edits without video training. Consider misuse risks (deepfakes, misinformation), watermark preservation, and safety mitigations.
- Reproducibility details: Training budgets, exact hyperparameters (optimizer, LR schedules, batch sizes), and dataset generation procedures (prompts, seeds, filtering) are not fully specified. Provide full training cards and scripts for deterministic reproduction.
- Licensing and data provenance: The paper relies on outputs of FLUX and Qwen-Image-Edit to build training pairs. Clarify licensing, redistribution rights, and whether datasets can be released for community benchmarking.
- Extending to audio-visual or multi-view video: The approach is not evaluated with audio-synchronized video edits or multi-view/4D consistency. Can the spatial branch be extended to handle audio features or multi-camera constraints?
Practical Applications
Summary
ViFeEdit introduces a video-free tuning framework that adapts text-to-video diffusion transformers (DiTs) for diverse video editing tasks (style transfer, object replacement/addition/removal, color alteration) using only small 2D image datasets. The core innovations—architectural reparameterization that decouples spatial modeling from frozen 3D temporal attention, a dual-path conditioning pipeline, and separate timestep embeddings—enable efficient, low-compute training (LoRA rank 32, 100–250 image pairs) while preserving temporal coherence. Below are practical applications across industry, academia, policy, and daily life.
Immediate Applications
The following can be deployed now with a modern text-to-video DiT (e.g., Wan2.1), minimal image data, and commodity GPUs.
- Consistent video style transfer for post-production and advertising — media/entertainment, marketing
- Use case: Batch stylize entire clips (e.g., Ghibli/Chibi/cartoon styles) with high temporal consistency for ads, trailers, social campaigns.
- Tools/products/workflows: NLE/After Effects/Premiere plugin; “Style LoRA” adapters trained on 100–200 paired images; batch render pipeline with optional SDEdit prior for reference preservation.
- Assumptions/dependencies: Access to a compatible T2V DiT with 3D attention; style reference image pairs; GPU (e.g., single 4090/A100); licensing for base model and training data.
- Brand localization and variant generation — retail, e-commerce, marketing
- Use case: Replace logos/packaging or adjust product colors for different regions, seasons, or campaigns while keeping video motion and backgrounds consistent.
- Tools/products/workflows: “Replacement” and “Color LoRA” adapters; template prompts and QA scripts; adapter registry per brand/style guide.
- Assumptions/dependencies: High-quality reference images of the new branding; legal approval and brand governance; robust prompts for specific targets.
- Targeted object removal and cleanup — social platforms, safety, media archiving
- Use case: Remove sensitive items, watermarks, or PII (e.g., license plates) across frames without flicker.
- Tools/products/workflows: “Removal LoRA” adapters; simple selector UI or keyword prompts; optional detector to propose candidates.
- Assumptions/dependencies: Reliable detection or prompt targeting; content policy compliance and disclosure; failure modes under heavy occlusion.
- Object addition and product placement in existing footage — e-commerce, media production
- Use case: Insert new SKUs/props consistently across scenes for late-stage product changes or dynamic placement.
- Tools/products/workflows: “Addition LoRA” adapters; reference image bank; confidence-based review; render-on-cloud API.
- Assumptions/dependencies: Sufficient reference images (angles, textures); legal clearance; scene occlusion handling.
- Color correction and recoloring at clip level — broadcast, sports, film
- Use case: Recolor uniforms, cars, or props globally/locally with temporal stability (e.g., team color swaps, night-to-day palette adjustments).
- Tools/products/workflows: “Color LoRA” with palette control; NLE integration; LUT-friendly exports.
- Assumptions/dependencies: Accurate prompts or masks for localized changes; base model color fidelity; QA for spillover.
- Cost-efficient research prototyping of video editing — academia, corporate R&D
- Use case: Prototype new video editing controls (replacement, addition, color/style) without curating video datasets.
- Tools/products/workflows: Open-source ViFeEdit code; LoRA fine-tuning notebooks; VBench/FiVE-Bench evaluation scripts.
- Assumptions/dependencies: Compatible backbone and compute; small paired image datasets; reproducible evaluation.
- Synthetic domain augmentation while preserving motion — robotics, autonomous driving, vision analytics
- Use case: Stylize or recolor training videos (e.g., weather/time-of-day) to expand datasets without corrupting motion cues.
- Tools/products/workflows: Task-specific Style/Color LoRA; automatic batch pipelines with metadata propagation; dataset versioning.
- Assumptions/dependencies: Label preservation strategy; closed-loop validation to avoid sim-to-real drift.
- Localized educational content creation — education, public sector communications
- Use case: Replace objects or stylize footage to align with local culture/language while maintaining temporal coherence.
- Tools/products/workflows: Lightweight LoRA training per locale; adapter catalog; reviewer-in-the-loop workflow.
- Assumptions/dependencies: Rights for source and training images; pedagogical and cultural review; provenance disclosures.
- Edit-as-a-service APIs with adapter hub — software/SaaS
- Use case: Cloud endpoints for video style transfer, object edits, and recolor tasks; adapter marketplace per brand/use-case.
- Tools/products/workflows: Containerized inference with dual-path conditioning; adapter registry (versioned LoRAs); usage metering.
- Assumptions/dependencies: GPU capacity and cost control; content safety tooling; base model usage rights.
- Attention analysis and spatiotemporal research probes — academia
- Use case: Study how freezing 3D attention and editing only spatial branches affects temporal coherence and semantics.
- Tools/products/workflows: Instrumentation for attention head visualization; ablation switches (positive/negative 2D branches on/off); shared benchmarks.
- Assumptions/dependencies: Access to internals of the backbone; consistent logging and seed control.
Long-Term Applications
These require further research, scaling, integration, or productization beyond the current paper.
- Real-time or near-real-time live video editing — broadcast, streaming, XR
- Use case: Live stylization/recoloring/object overlays during events or AR telepresence with temporal stability.
- Tools/products/workflows: Model distillation/quantization, caching for dual-path attention, low-latency engines.
- Assumptions/dependencies: Significant inference optimization; hardware acceleration; robust failure handling under rapid motion.
- On-device consumer apps for cohesive edits — mobile, creator tools
- Use case: Smartphone apps enabling consistent multi-frame edits (addition/removal/style) offline.
- Tools/products/workflows: Tiny-DiT variants; LoRA merging and adapter compression; UI for prompt + region control.
- Assumptions/dependencies: Memory/compute constraints; energy budgets; privacy-safe model updates.
- Multi-condition controls from image-only supervision — VFX, creative tooling
- Use case: Add depth/segmentation/pose control branches trained via images or pseudo-labels while preserving temporal modules.
- Tools/products/workflows: Extended dual-path for multimodal conditioning; pseudo-label generation at scale.
- Assumptions/dependencies: Reliable pseudo-label quality; architectural compatibility; training stability with multi-conditions.
- Unified multi-task adapter composition and marketplace — software
- Use case: Compose “Style+Color+Addition” adapters on the fly; share/sell verified adapters with metadata.
- Tools/products/workflows: Adapter composition rules; compatibility tests; governance and content safety checks.
- Assumptions/dependencies: Standards for adapter formats; IP and licensing frameworks; mitigation for harmful combinations.
- Interactive, fine-grained editing UIs — creative suites
- Use case: Scribbles/masks/region prompts to direct object-level edits with temporal propagation.
- Tools/products/workflows: Front-end temporal propagation; mask-aware positive/negative spatial attention guidance.
- Assumptions/dependencies: Robust region tracking; user experience for preview/undo; tight NLE integration.
- Studio-grade pipelines replacing parts of CGI and rotoscoping — film/TV
- Use case: Shot-specific adapters to handle prop swaps, background cleanup, or stylized sequences at production quality.
- Tools/products/workflows: Shot QC automation, color pipeline interoperability, versioned adapters per shot/sequence.
- Assumptions/dependencies: Meeting cinematic quality bar; union/workflow considerations; provenance and crediting.
- Medical and surgical training content generation (non-diagnostic) — healthcare education
- Use case: Animate procedural steps or instrument replacements for training while maintaining temporal realism.
- Tools/products/workflows: Domain adapters trained on curated synthetic/approved images; scenario scripts; expert review.
- Assumptions/dependencies: Strict ethical and regulatory review; no diagnostic claims; data anonymization.
- Provenance, watermarking, and policy alignment — policy, media platforms
- Use case: Embed robust watermarks and C2PA manifests in edited outputs; auto-attach edit metadata (adapter IDs).
- Tools/products/workflows: Watermarking integrated into decoding; provenance pipelines; compliance dashboards.
- Assumptions/dependencies: Industry standardization; balance between robustness and visual quality.
- Forensics and misuse mitigation specific to decoupled editing — security/policy
- Use case: Detectors tailored to artifacts of spatial-only tuning with frozen temporal modules; dataset releases of edited vs original.
- Tools/products/workflows: Benchmark suites; API hooks for attestation; cross-platform detection libraries.
- Assumptions/dependencies: Access to edited corpora; collaboration across platforms; evolving adversarial threats.
- Edge privacy-preserving redaction — security, public sector, IoT
- Use case: On-drone/bodycam removal of PII objects consistently across frames before upload.
- Tools/products/workflows: Lightweight adapters; hardware-accelerated inference; audit logs for redaction steps.
- Assumptions/dependencies: Reliable on-device detection; power/thermal constraints; legal mandates for disclosure.
- Sim-to-real and real-to-sim transfer for robot perception — robotics, digital twins
- Use case: Stylize sim videos to match real sensor domains (and vice versa) while preserving motion dynamics for training/evaluation.
- Tools/products/workflows: Domain adapters per environment; automatic re-labeling checks; closed-loop training pipelines.
- Assumptions/dependencies: Ensuring physics/motion fidelity remains intact; robust evaluation.
- Energy- and cost-aware AI operations — AI ops, sustainability
- Use case: Replace expensive video dataset curation/training with image-only pipelines to cut GPU days and emissions.
- Tools/products/workflows: Carbon and cost dashboards; compute budgeting; reproducibility reports tied to adapters.
- Assumptions/dependencies: Transparent reporting; acceptance by stakeholders; comparable quality to video-trained baselines.
Cross-Cutting Assumptions and Dependencies
- Base model: Requires a high-quality text-to-video DiT with 3D full attention and solid temporal priors (e.g., Wan2.1); results depend on backbone capability and license terms.
- Data quality: Small paired image datasets must match target domain; synthetic pairs (from T2I/LLMs) may introduce biases or artifacts.
- Compute: Although lightweight (LoRA rank 32, ≤20 epochs), a modern GPU is needed; real-time/edge scenarios require further optimization.
- Control fidelity: Object- and region-level control benefits from clear prompts or auxiliary detectors/masks; very heavy occlusions or long shots may require extra conditioning.
- Safety and compliance: Edited videos should carry provenance/watermarks; applications with privacy or public impact require policy alignment and disclosures.
- Generalization: Adapters trained on limited images may not cover all poses/lighting; multi-task adapters help but need compatibility management.
- Integration: Some backbones may need code adaptation; API/NLE plugins require engineering effort for robust UX and batch workflows.
These applications leverage ViFeEdit’s core strengths: video-free training, parameter efficiency, temporal coherence preservation, and generality across editing tasks, enabling immediate deployment in production workflows and setting the stage for real-time, on-device, and policy-aligned future systems.
Glossary
- 2D spatial attention: Attention computed within individual frames (spatial domain) rather than across time, used to learn image-only edits. Example: "we ... introduce a pair of complementary 2D spatial attention modules."
- 3D attention: Attention operating jointly over space and time (spatiotemporal tokens) to capture video dynamics. Example: "modern DiT-based video generators adopt full 3D attention to jointly capture spatial and temporal dependencies"
- 3D position embeddings: Positional encodings that index both spatial dimensions and time for video tokens. Example: "assigning them separate 3D position embeddings as usual."
- Architectural reparameterization: A redesign of model components to change how functions are represented without altering initial behavior, enabling new training dynamics. Example: "we propose an architectural reparameterization technique"
- Attention heads: Parallel sub-operations in multi-head attention that specialize on different relationships (e.g., spatial vs. temporal). Example: "modern DiTs dynamically allocate spatial or temporal attention heads"
- Attention- and latent-modulation methods: Training-free techniques that alter attention maps or latent features at inference to control generation. Example: "training-free plug-and-play attention- and latent-modulation methods"
- Batch dimension: The tensor axis indexing separate samples processed together during model forward passes. Example: "concatenating them along the batch dimension"
- Conditional tokens: Tokenized inputs providing conditioning information (e.g., reference video or text) to guide generation. Example: "directly concatenate conditional tokens with noisy latent tokens"
- Conditioning signals: External inputs (text, images, videos) that guide the generative model toward desired outputs. Example: "adaptability to diverse conditioning signals."
- ControlNet-style zero-convolution: A conditioning mechanism initialized to zeros to avoid changing base behavior until trained. Example: "ControlNet-style zero-convolution approaches"
- Dual-path pipeline: Two separate processing streams (e.g., for latent states and conditions) that interact selectively to preserve base capabilities. Example: "we adopt a dual-path pipeline."
- End-to-end video editing methods: Approaches that train a video model directly on paired supervision to output edited videos in one pass. Example: "end-to-end video editing methods"
- Feed-forward layers: Position-wise MLPs in transformer blocks that transform token features after attention. Example: "as well as the feed-forward layers to enhance performance."
- FiVE-Acc: A composite metric from the FiVE-Bench evaluating video editing accuracy across multiple criteria. Example: "we adopt the FiVE-Acc metrics"
- FiVE-Bench: A benchmark for evaluating fine-grained video editing performance across tasks. Example: "we adopt FiVE-Bench as our evaluation benchmark."
- Flow Matching mechanism: A training objective that learns a velocity field to transform noise into data via continuous-time flows. Example: "they apply the Flow Matching mechanism"
- Flow-matching schedule: The temporal progression of the flow-based generative process during inference or training. Example: "The flow-matching schedule then starts from ."
- Latent map: A compact representation (latent tensor) of images or videos on which diffusion operates. Example: "noisy video latent maps"
- LoRA fine-tuning: A parameter-efficient tuning approach that injects low-rank adapters into weight matrices. Example: "we employ LoRA fine-tuning"
- Noise prior: Using a reference (e.g., source video) blended with noise to initialize the diffusion process. Example: " can be used as a noise prior to initialize the noisy latent during inference"
- Noise scheduling: The policy controlling noise levels or timesteps for different branches during training/inference. Example: "separate timestep embeddings for noise scheduling"
- Positive–negative attention architecture: Paired spatial attention modules that explicitly enhance (positive) or suppress (negative) semantics for controllable edits. Example: "This positiveânegative attention architecture facilitates sign-aware semantic editing"
- Pretrained temporal modules: The parts of a video model responsible for time modeling that are kept fixed to preserve learned dynamics. Example: "the pretrained temporal modules of the base video generator remain intact"
- Residual manner: Combining module outputs by residual addition/subtraction to preserve initial behavior at initialization. Example: "designed to interact in a residual manner"
- SDEdit: A diffusion-based editing technique that initializes the process from a partially noised input for consistent edits. Example: "inspired by SDEdit"
- Sign-aware semantic editing: Editing strategy that treats additive and suppressive signals separately to control enhancement vs. inhibition of features. Example: "enables sign-aware semantic editing"
- Spatiotemporal coherence: Consistency across both space and time in edited videos (appearance and motion). Example: "achieving joint spatiotemporal coherence."
- Spatio-temporal decoupling: Separating spatial from temporal modeling so image-only training affects spatial edits without degrading temporal dynamics. Example: "The key to addressing this issue lies in a spatio-temporal decoupling mechanism"
- Temporal consistency: Stability of content across frames without flicker or drift. Example: "maintaining temporal consistency"
- Temporal modeling capability: A model’s ability to learn and generate coherent temporal dynamics. Example: "preserved its temporal modeling capability"
- Temporal position embedding: Positional encodings corresponding to frame indices used in temporal attention. Example: "a consistent frame index used for the temporal position embedding"
- Temporal positional indices: Index values assigned along the time axis to order tokens in a video sequence. Example: "setting the temporal positional indices to 0 for all tokens."
- Temporal-adaptation method: Techniques that add temporal modules to image models to enforce cross-frame consistency. Example: "temporal-adaptation method that explicitly incorporate temporal modules into image backbones"
- Timestep embeddings: Encodings of diffusion time/step that condition the network on current noise level. Example: "assign separate timestep embeddings to and "
- Video diffusion transformers: Transformer-based diffusion models designed for video generation and editing. Example: "a video-free tuning framework termed ViFeEdit for video diffusion transformers."
- Video-conditioned generative model: A generator that takes a video as input condition to produce an edited or controlled video. Example: "train a video-conditioned generative model on paired or synthetic supervision"
- Video-free tuner: An adaptation approach that tunes a video model using only images (no video training data). Example: "a video-free tuner for video diffusion transformers"
- VBench: A benchmark suite assessing various aspects of video quality and consistency. Example: "we follow the official VBench evaluation settings"
- VLM Score: A metric derived from a vision-LLM assessing structural/motion consistency and style fidelity. Example: "we evaluate VLM Score with Qwen2.5-VL-7B-Instruct"
Collections
Sign up for free to add this paper to one or more collections.