- The paper introduces DD-GEPA, a modular framework that automatically optimizes dialogue disentanglement prompts through evolutionary search.
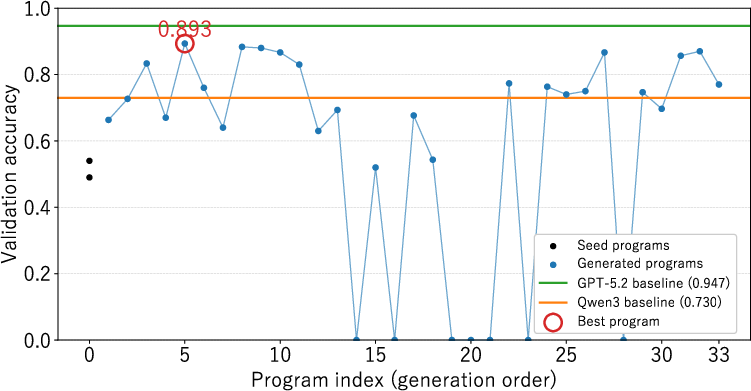
- The paper demonstrates that the optimized prompt boosts key metrics (e.g., VI=94.12, ARI=75.87, Dialogue F1=42.52) compared to manual baselines.
- The paper highlights limitations in trace diversity and signal bottlenecks, suggesting hybrid approaches for further advancements.
DD-GEPA: Automatic Prompt Optimization for Dialogue Disentanglement
Problem Setting and Motivation
Dialogue disentanglement refers to the task of partitioning entangled utterances from multi-party chat streams into coherent dialogue clusters, where clusters are defined by reply-to relations among utterances. This is a foundational preprocessing step for downstream applications such as dialogue state tracking and conversational response modeling, particularly in settings with high message concurrency (e.g., IRC, Slack). LLMs exhibit strong contextual reasoning, suggesting potential for state-of-the-art performance in disentanglement. However, prior studies have shown that LLM-based approaches are highly sensitive to prompt design and may underperform compared to specialized neural models and handcrafted features, especially for open-weight models with ≤30B parameters.
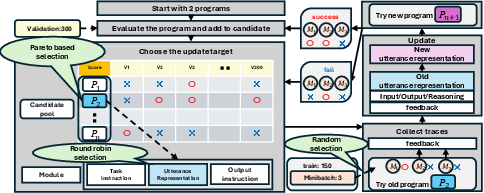
Manual prompt engineering is infeasible at scale due to the lack of comprehensive annotation guidelines, notable human disagreement over gold standards, and the fine-grained dependence of LLM performance on prompt formatting and structure. Therefore, this work introduces DD-GEPA: an automatic, modular prompt optimization framework that decomposes complex dialogue disentanglement prompts into three independently optimizable modules—task instruction, utterance representation, and output instruction—and uses an extension of GEPA (Reflective Prompt Evolution; [agrawal2026gepa]) to optimize these components through evolutionary search and natural language reflection.
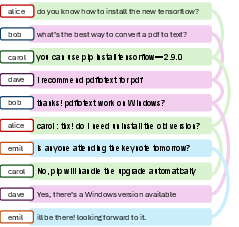
Figure 1: Illustration of the dialogue disentanglement task, visualizing the partitioning of interleaved chat utterances into color-coded dialogue clusters.
DD-GEPA Framework
DD-GEPA adapts the GEPA optimization paradigm for the multi-faceted prompt structure of dialogue disentanglement. A "program" in DD-GEPA consists of the three prompt modules (instruction, representation, output), and a population of such programs is iteratively optimized in a Pareto-based evolutionary loop.
This approach enables joint search over semantics and formatting, tailored for disentanglement tasks with complex, compositional prompt requirements.
Experimental Evaluation
Dataset and Baselines
Experiments are conducted on the Ubuntu IRC dataset ([kummerfeld2019large]), with standard development/test splits. The study benchmarks four prompt settings:
- Seed 1: Minimal instruction and whitespace-separated representation; single-value output.
- Seed 2: As above, with a two-key output scheme ("is_new_dialogue", "utterance_id").
- Baseline: Manually engineered prompt with JSON utterance representation and two-key output, as in [TakadaMori2026Rethinking].
- Optimum: The program produced by DD-GEPA after three update rounds (one per module).
All experiments use Qwen3-30B-A3B-Thinking-2507 ([yang2025qwen3]) for reply-to prediction; GPT-5.2 ([openai2025gpt52]) is used for comparative evaluation. Metrics include variation of information (VI), ARI, NMI, 1-1, S-F1, local accuracy, and dialogue-level (cluster) precision/recall/F1.
Main Results
Analysis and Implications
Error Taxonomy: Predominant residual errors under Optimum are associated with ambiguities in phatic expressions, system messages, technical jargon, ambiguous addressee contexts, and cases with insufficient preceding context. These align with known annotator ambiguities in gold data and indicate fundamental challenges in both LLM and traditional models.
Optimization Limits: DD-GEPA's convergence correlates with both the representational expressiveness of the best prompt and limits in trace diversity (large token context requirements preclude larger trace sets during update). The prompt optimization dataset, although curated for difficulty, may be insufficiently challenging or diverse to drive breakthrough improvements.
Implications for Disentanglement and Prompt Engineering:
- Modular, automatically optimized prompts can yield measurable accuracy gains in LLM-based dialogue disentanglement, demonstrating their value over manual engineering even for strong, large models.
- Despite clear advances, prompt optimization alone does not bridge the gap with best-in-class non-LLM and scaled proprietary LLM systems—suggesting limitations inherent to both open-weight model capacity and the information bottleneck of prompts.
- Extending beyond prompt search—possibly leveraging hybrid retrieval, in-context exemplars, or dynamic prompt adaptation—may be necessary for further advances.
Theoretical and Practical Impact
From a theoretical perspective, this work formalizes a modular, compositional approach to prompt optimization for structured NLP tasks, providing a blueprint for decomposable, high-dimensional prompt search in compound LLM systems. Practically, the findings highlight both the strengths and constraints of reflective evolutionary prompt search for real-world dialogue tasks—especially under privacy restrictions limiting LLM fine-tuning or data sharing.
Future developments may pursue:
- Scalable trace-based optimization that circumvents token constraints (e.g., sampling, abstraction, or filter techniques for trace selection).
- Integration with instruction tuning or demonstration-based prompt composition.
- Expanding to domains with more complex interaction structures, beyond programming-related or publicly available data.
Conclusion
DD-GEPA demonstrates that automatic, modular prompt optimization provides tangible improvements for LLM-based dialogue disentanglement, surpassing manual prompt baselines but not yet matching specialized neural architectures or scaled commercial LLMs. This establishes a robust foundation for systematic, data-driven prompt design in compositional LLM programs and sets the stage for further research on context-efficient, high-fidelity disentanglement in multi-party chat environments.