- The paper demonstrates that sparse latent representations enable near-maximal discrimination of hallucinations with high AUC scores.
- The authors develop two steering methods—activation-space and SAE latent steering—that suppress non-speech hallucinations without modifying Whisper’s weights.
- Empirical results reveal significant reductions in hallucination rates with minimal increases in word error rates, proving the method’s practical utility.
Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders
Introduction and Problem Statement
This work rigorously addresses a key failure mode in modern ASR: hallucinations in Whisper, where the system produces coherent, plausible transcriptions for non-speech input, such as silence or background noise, which are semantically decoupled from the actual audio. The authors hypothesize that internal encoder representations of Whisper contain sufficient information for both hallucination detection and targeted mitigation. Central to their framework are two internal feature spaces: raw Whisper encoder activations and sparse latent representations derived from Sparse AutoEncoders (SAEs). The study systematically investigates linear separability of hallucination-related information in these spaces and proposes two fine-tuning-free steering schemes—activation-space and SAE-space steering—to suppress hallucinations without degrading ASR performance on genuine speech.
Representational Structure and Hallucination Detection
The empirical analysis reveals that hallucination-discriminative signal concentrates in a subset of encoder hidden units, with linear separability increasing toward deeper layers. Logistic regression classifiers trained on raw activations and SAE latents achieve high AUC scores (e.g., exceeding 0.8 on several splits) for hallucination detection. Notably, a sparse subset (top 10–25) of SAE latents suffices for near-maximal discrimination, indicating that the hallucination correlate is not diffuse but sharply delineated in internal feature space.
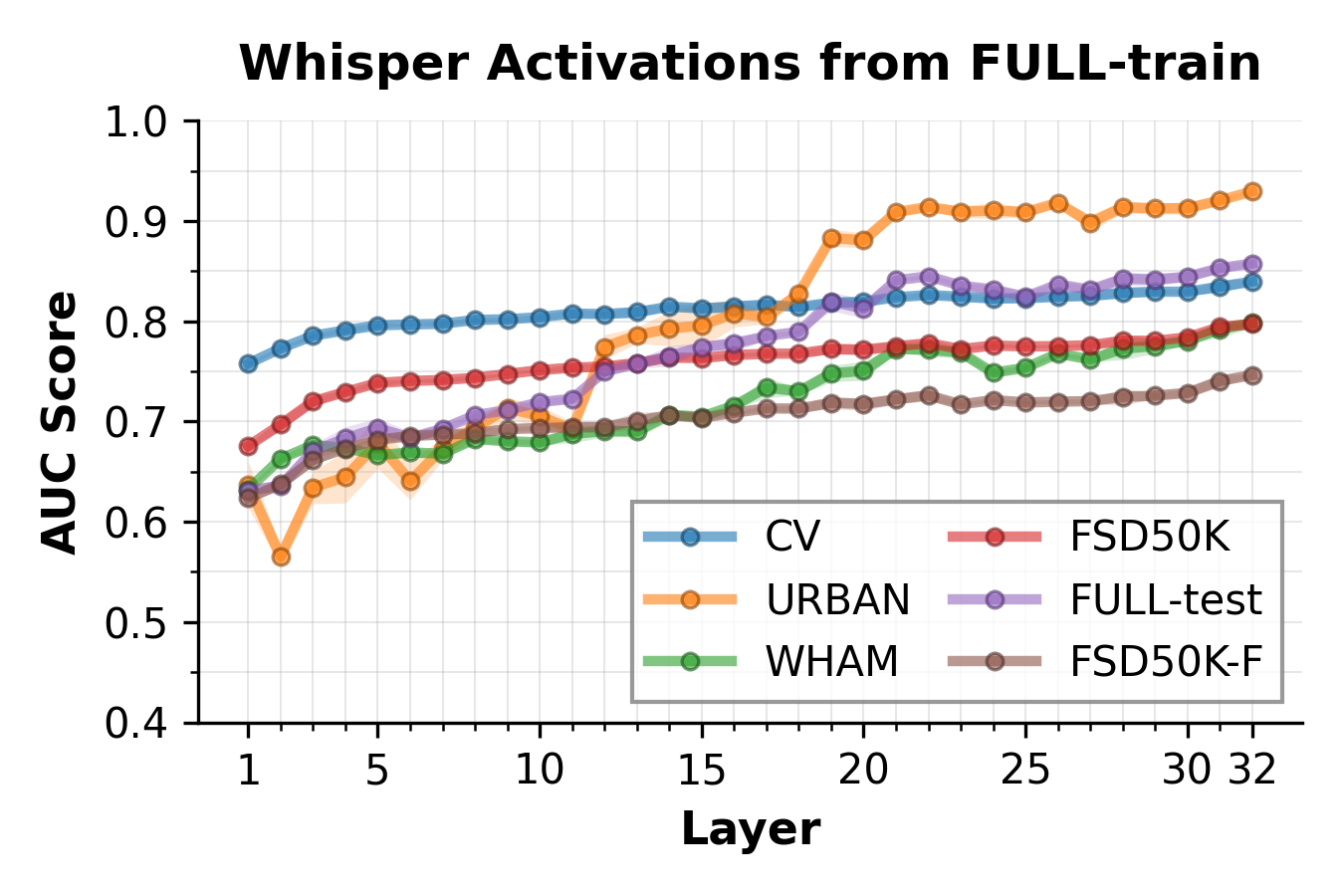
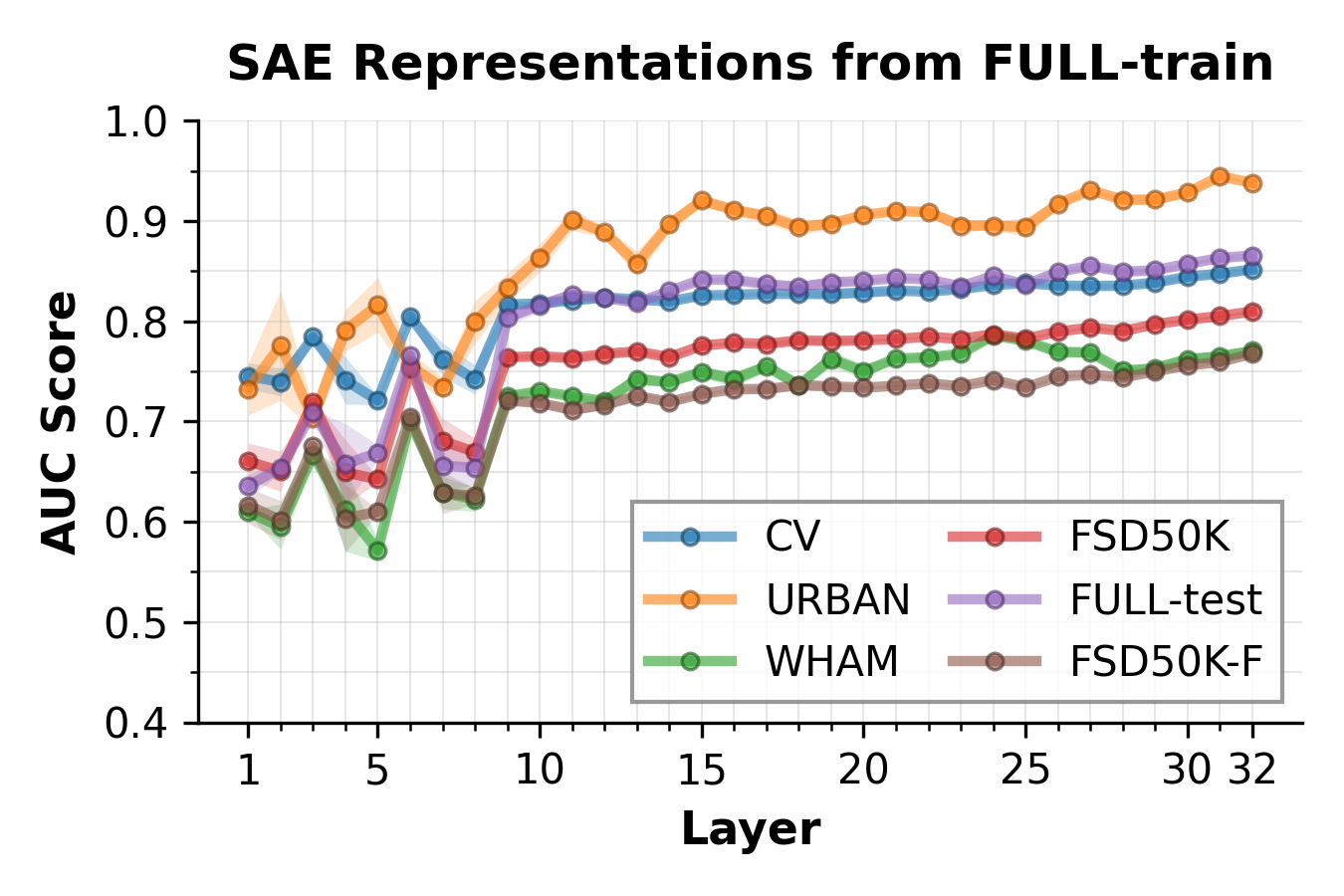
Figure 1: Layer-wise AUC for hallucination versus non-hallucination classification on both raw Whisper activations and SAE latents; separability improves in deeper layers and is generally higher for SAE representations.
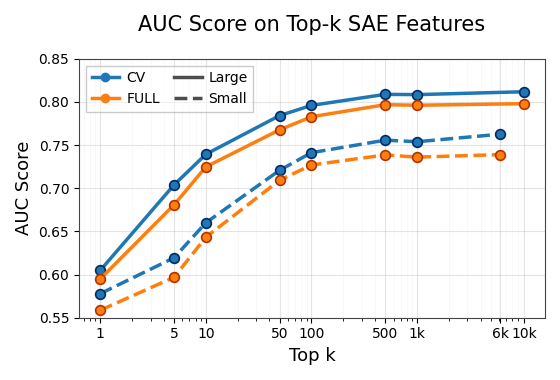
Figure 2: Classification AUC as a function of the number of top-k SAE features; strong performance is attained with only tens of latents, supporting the steering approach's sparsity assumption.
These findings validate the premise for linear steering and support the subsequent construction of targeted interventions derived from the contrast between hallucination-prone and genuine-activation means.
Steering Strategies: Mechanisms and Implementation
The authors formalize two inference-time steering paradigms:
- Activation-Space Steering: Compute the mean activation difference (steering vector) between hallucinating and non-hallucinating non-speech samples at the final encoder layer. During inference, this vector (scaled by coefficient α) is injected into the residual stream, nudging the input representation toward the non-hallucinating manifold.
- SAE Latent Steering: Leverage logistic regression weights from SAE-latent classifiers to identify and steer only the most discriminative latent dimensions. Both additive (offsetting latent values by average activation) and multiplicative (scaling latents) strategies are considered, with hyperparameters (α, k) tuned on held-out non-speech validation data. Decoded, steered activations are re-inserted in Whisper's encoder stream.
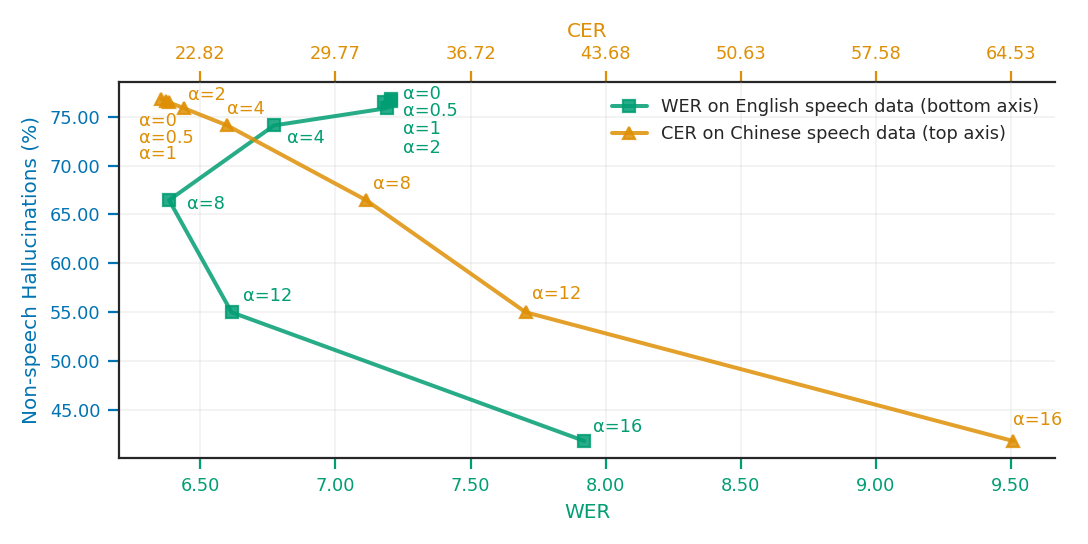
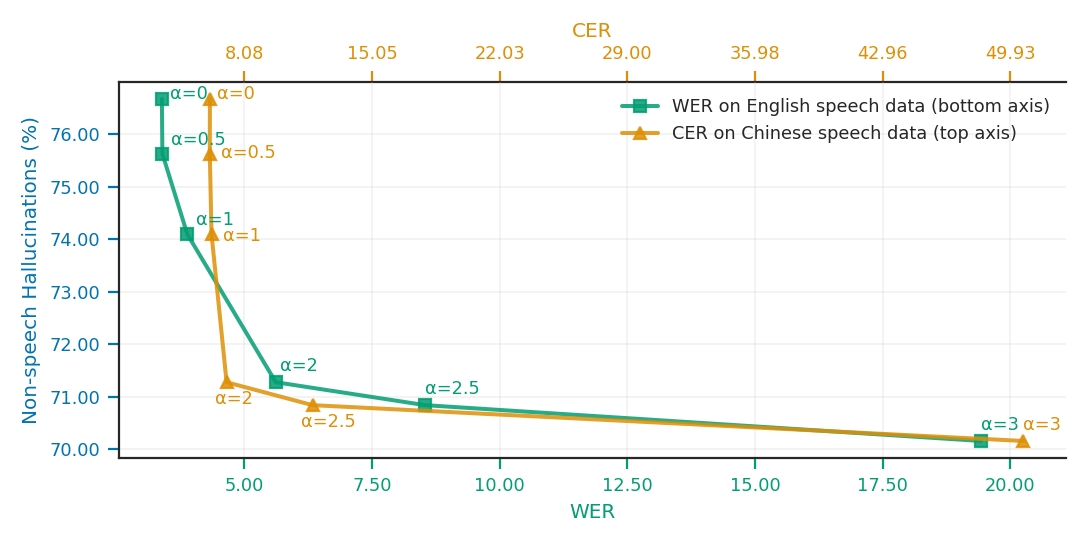
Figure 3: Pareto trade-off between hallucination rate (HR) and ASR quality (WER/CER) for activation-space steering across α values on Whisper small and large-v3.
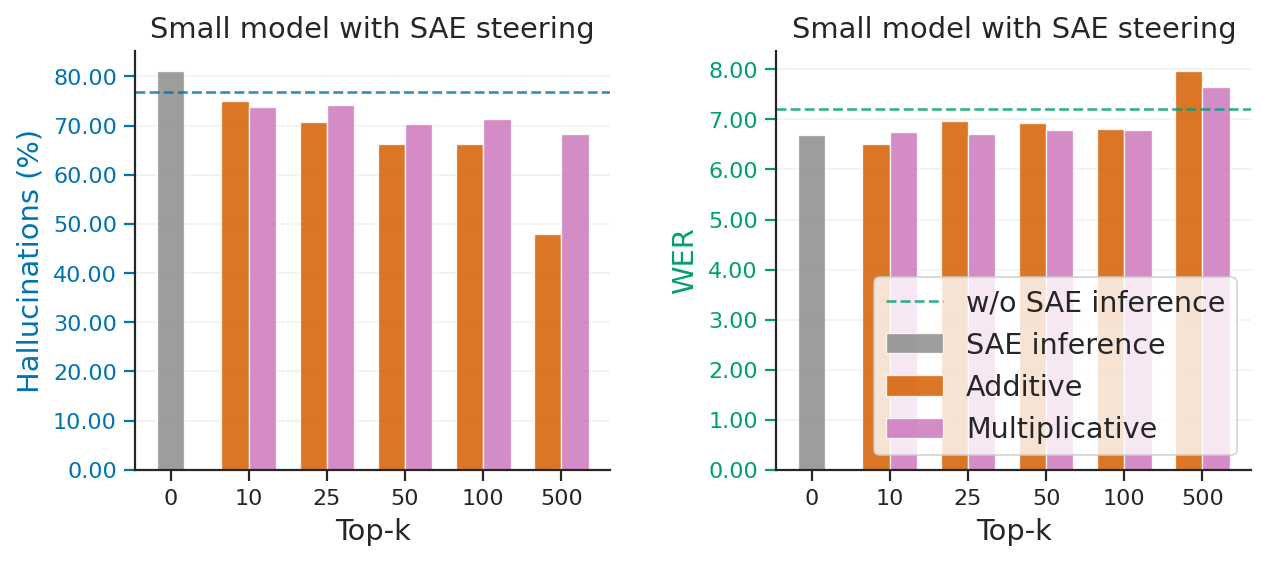
Figure 4: Comparative effectiveness of additive and multiplicative SAE steering as a function of top-k latents; additive interventions typically yield superior HR reductions for lower k.
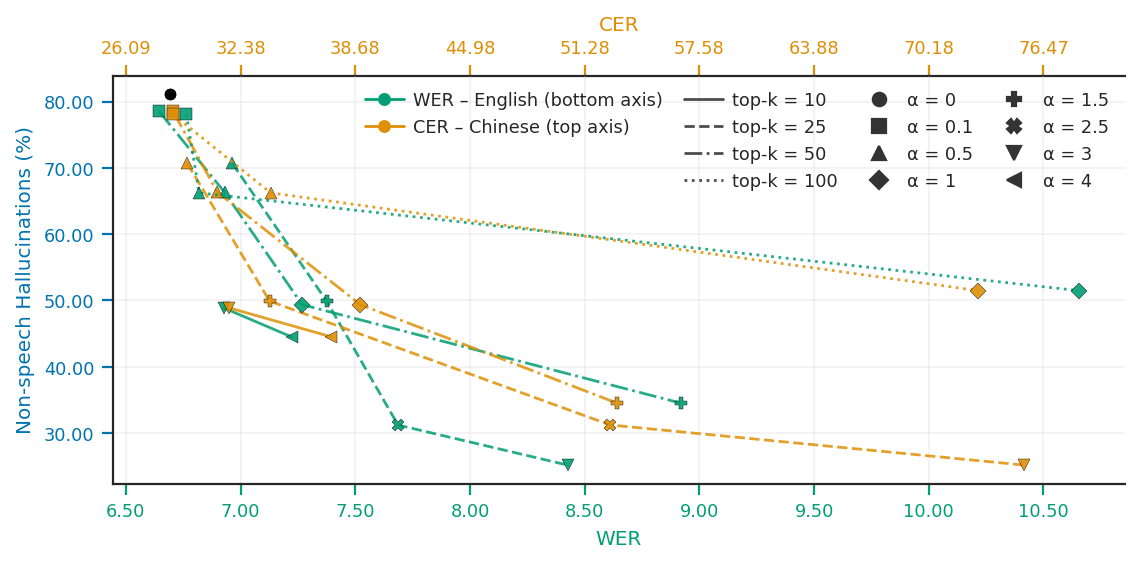
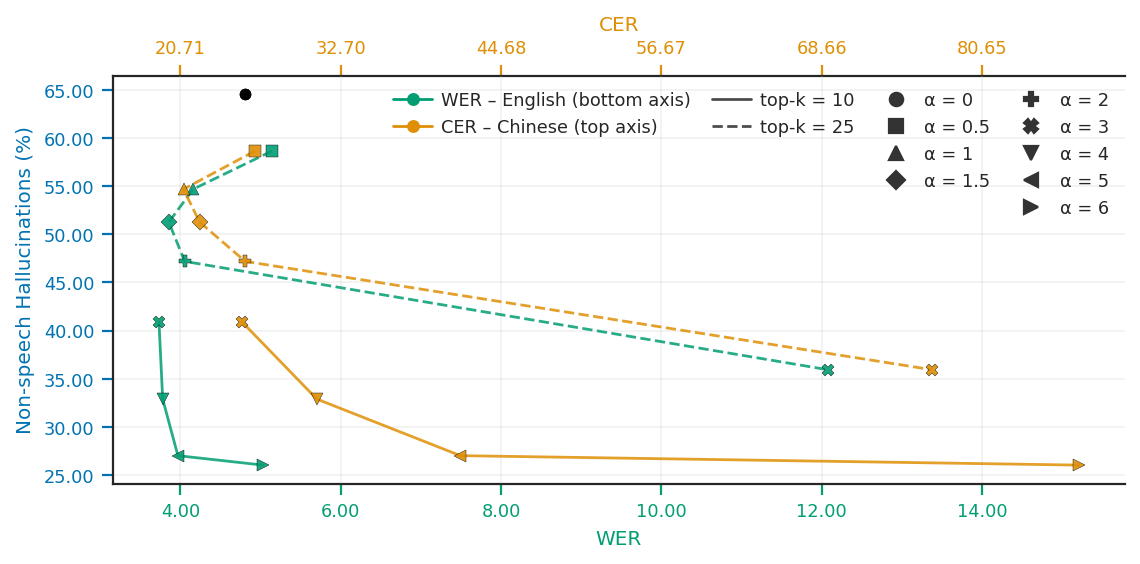
Figure 5: Multi-objective trade-off between HR, WER, and CER for additive SAE-based steering as α and top-k are varied.
The results underscore that additive SAE steering delivers consistent hallucination suppression, while also affording strong control over WER degradation. Multiplicative approaches are less effective due to their inability to perturb inactive latents.
Experimental Results
The core empirical findings are as follows:
- Hallucination Prevalence: Baseline HR on challenging non-speech sets (e.g., UrbanSound8K) are high—up to 95.98% for Whisper large-v3 and 67.09% for Whisper small—highlighting the severity of unchecked hallucination.
- Steering Efficacy: Fine-tuning-free SAE-based additive steering reduces HR to 8.68% (UrbanSound8K) and 4.68% (WHAM!) for Whisper small and to 19.88% and 27.05% for Whisper large-v3, with minimal WER increases on English speech.
This approach, while not modifying Whisper's model weights, achieves HR reductions approaching those observed for dedicated fine-tuned decoder interventions (Calm-Whisper [24.10% masking; 15.51% fine-tuned]), but from encoder-side manipulations.
Additionally, activation steering (raw activation vector injection) does mitigate hallucinations, but to a much lesser degree (HR>60%). Intriguingly, steering sometimes yields minor WER improvement on Whisper small, possibly by regularizing encoder space toward a more speech-discriminative regime.
Analysis and Comparative Discussion
The study's principal advantage is leveraging sparse, interpretable latent decompositions to realize targeted, data-driven interventions that are weight-invariant and parameter-efficient—crucial for black-box or resource-constrained scenarios. The results contest the assumption that hallucination is strictly a decoder-centric problem. Encoder representations themselves encode sufficient information for both detection and non-parametric suppression of hallucinations. SAE-based steering, especially when sparsity is exploited, outperforms naive global manipulation of raw activation space.
However, transferability of the approach across languages is limited. For Mandarin, ASR metrics degrade under SAE steering, likely attributable to the out-of-domain nature of training data for the SAE—raising the prospect of future work on multilingual SAE pretraining and language/domain-adaptive steering masks.
Implications and Future Directions
The research establishes the practical utility of post hoc, fine-tuning-free intervention in modern ASR for mitigating hallucinations—a significant safety and reliability concern for deployed models in open environments. The latent-space steering paradigm is extensible, with clear implications for cross-modal generative models and interpretability research. Future investigations should consider:
- Multilingual, multi-domain SAE training to address CER/WER degradation outside English
- Layer-wise or progressive multi-point steering for robustness against distributed hallucination features
- Joint analysis with decoder-centric approaches for multi-stage mitigation
- Integration with LLMs for end-to-end audible-text pipelines
Conclusion
The study demonstrates that Whisper's internal encoder representations—especially when sparsely decomposed via SAE—concentrate hallucination cues in a small, tractable subset of features. Steering these via sparse, data-driven interventions yields substantial hallucination suppression with minimal ASR trade-off, supporting a generalizable, fine-tuning-free approach to ASR reliability. This opens new avenues for both analysis and control of neural ASR models and their pathological behaviors, situating feature-level steering as a central tool in future ASR system design.
Reference: "Whisper Hallucination Detection and Mitigation via Hidden Representation Steering and Sparse AutoEncoders" (2606.07473)

