- The paper's central contribution is the joint optimization of latent action models and diffusion-based VLA modules, which grounds visual dynamics directly to robot actions.
- It employs a composite loss with bidirectional cosine similarity to regularize inverse and forward dynamics, achieving improvements of ~10% in simulation and ~32% in real-world tasks.
- The method generalizes robustly across diverse robots and tasks, serving both as an end-to-end training framework and a post-training enhancement module.
Latent Action Representation Alignment for Robust Vision-Language-Action Models
The contemporary paradigm shift in generalist robotic control leverages Vision-Language-Action (VLA) models to directly map multimodal observations and language instructions to robot actions. However, these VLA models, especially large-scale architectures, remain fundamentally constrained by the scarcity, heterogeneity, and expense of labeled real-world robot datasets. While large corpora of internet-scale human video offer rich, semantically dense data, the chasm between observed visual dynamics and robot-executable actions—compounded by embodiment mismatch and unlabelled action trajectories—has limited direct exploitation of these unlabeled resources.
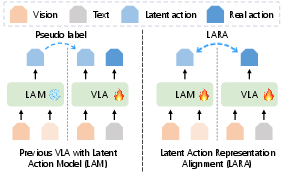
Latent Action Models (LAMs) address this challenge through learning abstracted, compressed action representations by modeling visual state transitions, offering a mechanism by which visual dynamics can inform VLA policy optimization. Conventional pipelines pre-train LAMs in a decoupled manner and leverage the learned representations as pseudo-labels or auxiliary losses for downstream VLA training. This isolation leaves LAMs unverified against robot-grounded action labels and restricts VLA models to operate within the action manifold defined by static, potentially suboptimal LAMs.
LARA: Joint Latent Action Representation Alignment
LARA (Latent Action Representation Alignment) proposes an integrated solution: the synchronous, end-to-end joint optimization of LAM and diffusion-based VLA modules via explicit alignment of their internal latent representations. This method establishes a bidirectional regularization mechanism:
- LAMs are grounded to action trajectories, suppressing spurious or non-causal visual dynamics that do not correspond to meaningful robot actions.
- VLA models are regularized via forward dynamics, as encoded by LAMs, mitigating hallucinated but functionally irrelevant or physically implausible trajectories.
The core technical embodiment of LARA is a representation alignment objective. Intermediate representations from the diffusion policy network (usually a Diffusion Transformer, DiT) are aligned, through a learnable projection, to the continuous latent outputs of the LAM's inverse dynamics model. Unlike prior works leveraging frozen pretrained representations, LARA treats both flows as dynamically trainable, enabling co-evolution of action abstractions and policy features.
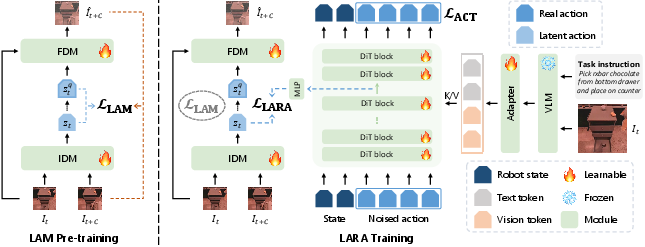
Figure 1: Method overview. Latent action features learned via LAM from visual state transitions are aligned with intermediate representations of the diffusion-based VLA policy, jointly optimizing both modules.
Methodological Contributions
The LARA objective augments the standard flow-matching loss for action prediction and the LAM’s VQ-VAE reconstruction loss with a bidirectional cosine similarity loss between policy and latent action features. This composite loss, balanced with tunable weighting parameters, is amenable to a variety of architectures and encapsulates the following:
LARA can be deployed as:
- A full end-to-end co-training framework from large-scale data.
- A post-training enhancement module on top of existing pretrained diffusion-based VLA models.
- A mechanism for latent action refiner, improving downstream utilization of LAM-generated pseudo-labels.
Experimental Evaluation
LARA's effectiveness is established through a wide battery of evaluations, spanning both simulation and real-world robotic manipulation contexts (e.g., LIBERO, SIMPLER-ENV, GR1-Sim-24, G1-Real). The experimental results demonstrate:
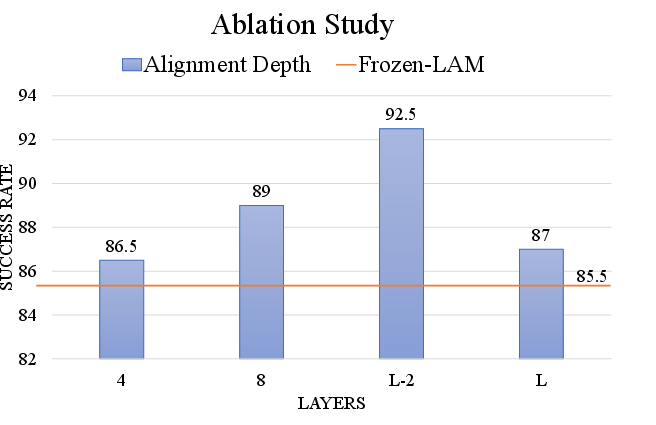
Figure 4: Qualitative attention map visualization. LARA-LAM focuses on task-relevant instruments (end-effectors, objects), whereas baseline LAMs distribute attention over distractors.
Ablation and Design Analysis
Comprehensive ablation studies reveal:
Implications and Future Perspectives
Theoretically, LARA provides a scalable, data-efficient paradigm for integrating unlabeled human video and labeled robot data in a single optimization loop, producing representations that bridge semantic understanding and executable policy. Practically, it enables increased sample efficiency for robotic system deployment, robustness to embodiment and domain shifts, and the possibility to exploit internet-scale multimodal corpora.
The method is compatible with contemporary diffusion-based policy architectures and LAM variants, indicating significant applicability as future policy models increase in scale and diversity. Potential next steps include scaling LARA to internet-scale datasets, combining with open-world generalization objectives, and extending the framework to hierarchical and closed-loop world models.
Conclusion
LARA formalizes a practical, theoretically motivated bridge between high-capacity policy networks and abstract action representations learned from unlabeled visual data. The explicit, bidirectional alignment substantially benefits both generalization and downstream task efficacy, fulfilling a core desideratum for generalist robot learning: leveraging abundant visual data while achieving action grounding and transferability.
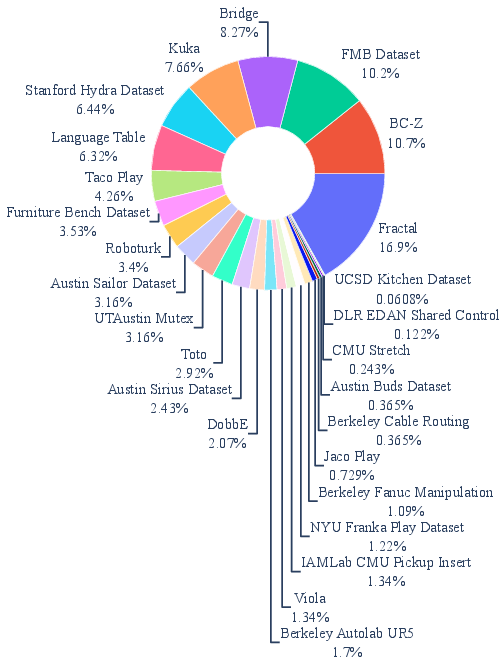
Figure 6: Distribution of data sources utilized in LAM pre-training and LARA joint training, demonstrating scalability across multimodal sources.
References
- "LARA: Latent Action Representation Alignment for Vision-Language-Action Models" (2606.07100)