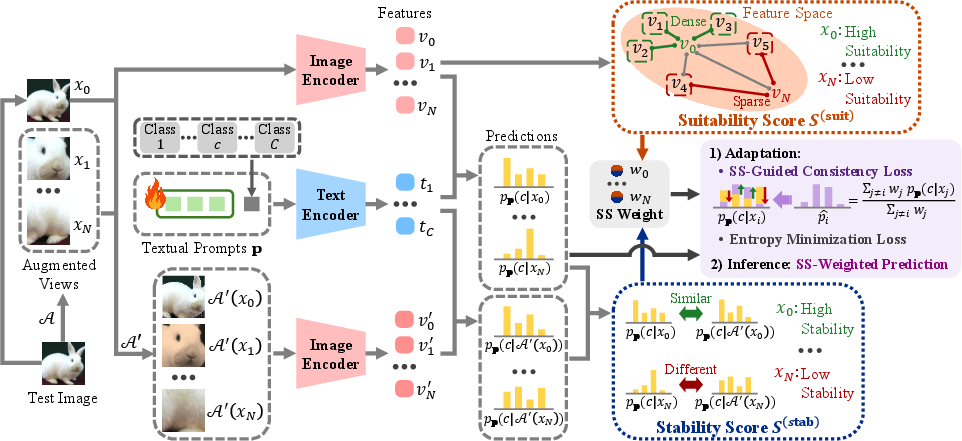
- The paper introduces a novel SS-TPT method that computes stability and suitability scores to assess the trustworthiness of augmented views in vision-language models.
- It leverages an SS-guided consistency loss and SS-weighted prediction aggregation to mitigate adversarial perturbations while reducing computational overhead.
- Empirical results demonstrate that SS-TPT outperforms existing defenses across diverse datasets and attack scenarios, even when using limited augmentation views.
Stability and Suitability-Guided Test-Time Prompt Tuning for Adversarially Robust Vision-LLMs
Introduction and Motivation
Recent advances in vision-LLMs (VLMs) such as CLIP have enabled strong zero-shot recognition by aligning visual and linguistic modalities in a joint embedding space. However, the vulnerability of these pre-trained systems to distribution shifts and adversarial perturbations remains a critical barrier to deployment in real-world, safety-critical contexts. Existing test-time adaptation defenses bolster robustness by leveraging large ensembles of augmented image views, but this approach incurs significant computational overhead and exposes a trade-off between robustness and throughput. In low-view regimes, naively aggregating predictions can be dominated by adversarially corrupted or low-quality augmentations, resulting in substantial drops in robustness and efficiency.
To address this, the paper introduces SS-TPT (Stability and Suitability-guided Test-Time Prompt Tuning), which introduces a principled approach to assessing and leveraging the quality of augmented views at test time. Rather than treating all augmentations as equally trustworthy, SS-TPT computes two orthogonal per-view metrics—stability (prediction invariance under mild augmentations) and suitability (feature-space density among views)—that guide both adaptation and inference. The goal is to select and amplify the influence of trustworthy, reliable views while mitigating the impact of adversarial or degenerate augmentations.
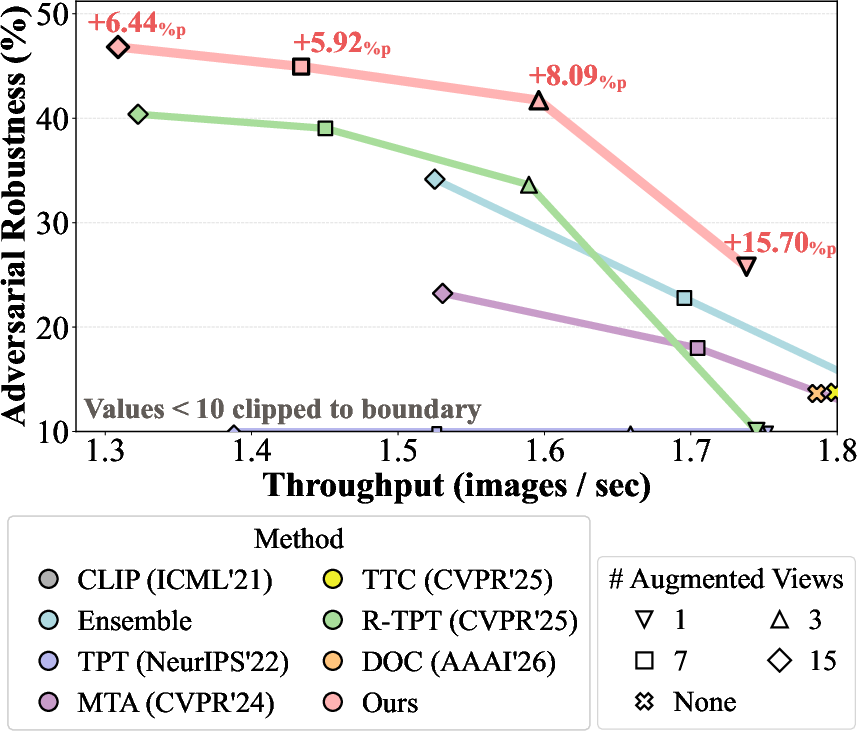
Figure 1: Robustness-throughput trade-off across test-time defenses, averaged over 10 fine-grained classification datasets. SS-TPT consistently surpasses prior methods, achieving higher robustness with faster inference even when using fewer augmented views.
Methodology
SS-TPT Framework Overview
The SS-TPT procedure can be summarized as follows:
Stability and Suitability Computation
Let pp(⋅∣xi) denote the predictive distribution for view xi with current prompt parameters p.
- Stability (Sistab): Inverse of the Jensen-Shannon divergence between pp(⋅∣xi) and pp(⋅∣x~i), where x~i is a weak augmentation of xi. High stability indicates that the model's prediction is resistant to small, label-preserving perturbations.
- Suitability (Sisuit): Inverse mean squared cosine distance between xi and other views xi0 in the feature space. High suitability indicates the view resides in a dense, consistent local region amongst the augmentations.
- SS Score: xi1, with xi2 denoting min-max normalized scores and xi3 a trade-off parameter.
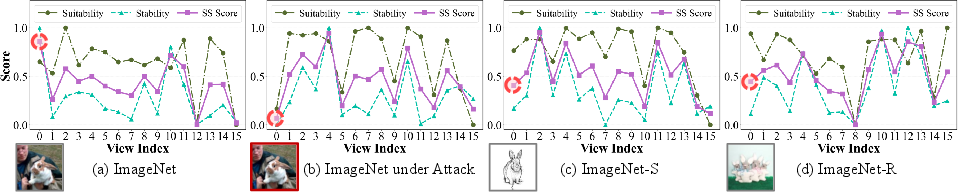
Figure 2: Stability, suitability, and combined SS scores for each view under varying conditions. High SS scores reliably indicate trustworthy (clean or natural) views, while adversarially perturbed or OOD views receive low SS scores.
Adaptation and Inference
- SS-Guided Consistency Loss: For adaptation, each view is aligned to a leave-one-out SS-weighted reference (i.e., an aggregation of all other views weighted by SS scores), using KL divergence. The total adaptation objective combines per-view entropy minimization with this SS-guided consistency, balanced by xi4.
- SS-Weighted Prediction: At inference, the final prediction is the SS-weighted sum of all per-view predictions, suppressing unreliable or adversarial augmentations.
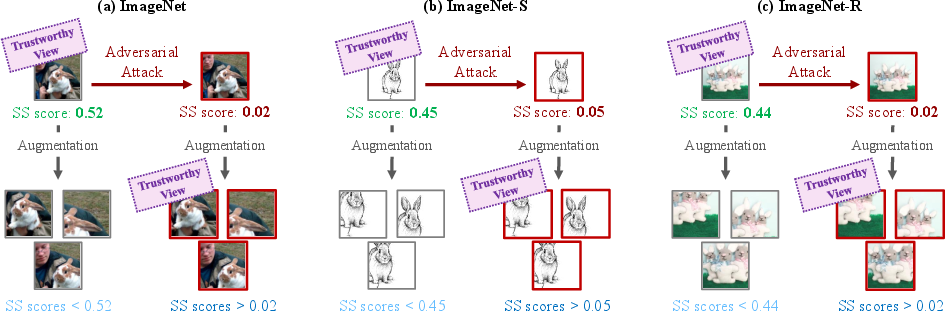
Figure 4: Average SS scores on clean and adversarially attacked images for several ImageNet-derived datasets, demonstrating that adversarial perturbations sharply reduce the SS score of the original view, shifting the model’s trust toward less-corrupted augmentations.
Evaluation and Results
Experimental Setup
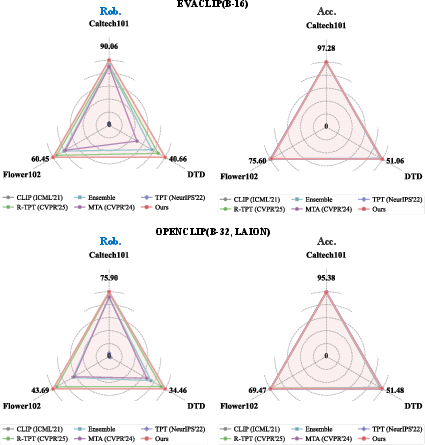
Experiments are conducted on 10 fine-grained classification datasets and several challenging distribution-shifted benchmarks (ImageNet-A, -V2, -R, -S). Robustness is evaluated using clean accuracy and adversarial accuracy (PGD, white-box, AutoAttack, CW, and DI-FGSM attacks). Competing baselines include CLIP zero-shot, TPT, TTC, DOC, R-TPT, and multi-view ensemble.
Strong Empirical Results
Robustness-Throughput Trade-Off:
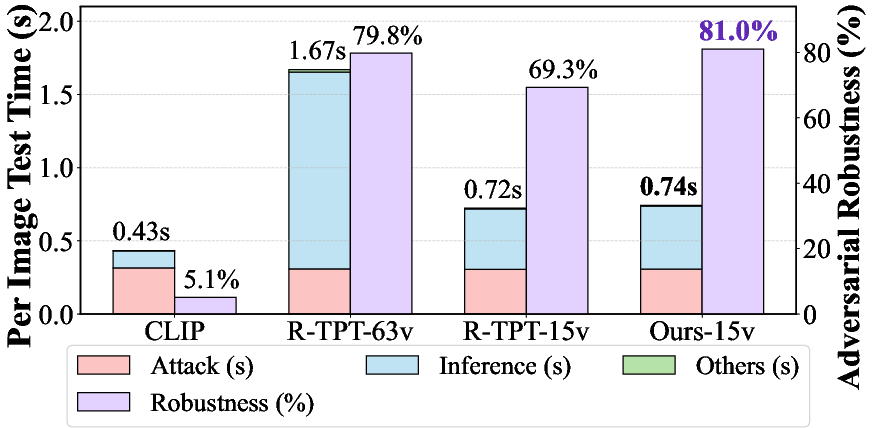
SS-TPT closes the robustness-efficiency gap in test-time defenses. With only 15 views, SS-TPT robustly outperforms R-TPT and other baselines that use many more (e.g., 63+) augmentations.
Single-View Regime:
Under severe augmentation constraints (only one view), SS-TPT still substantially outperforms prior adaptation methods. Adversarial robust accuracy on averaged datasets jumps from <14% (TTC, DOC, R-TPT) to 25.8% with SS-TPT, with clean accuracy preserved.
Attacks and Distribution Shifts:
SS-TPT achieves the highest clean and robust accuracy among all tested test-time adaptation defenses across all evaluated OOD variants of ImageNet, with similar trends under AutoAttack, CW, and DI-FGSM. On strong white-box, pipeline-aware attacks, robust performance is maintained, underscoring the approach’s resilience.
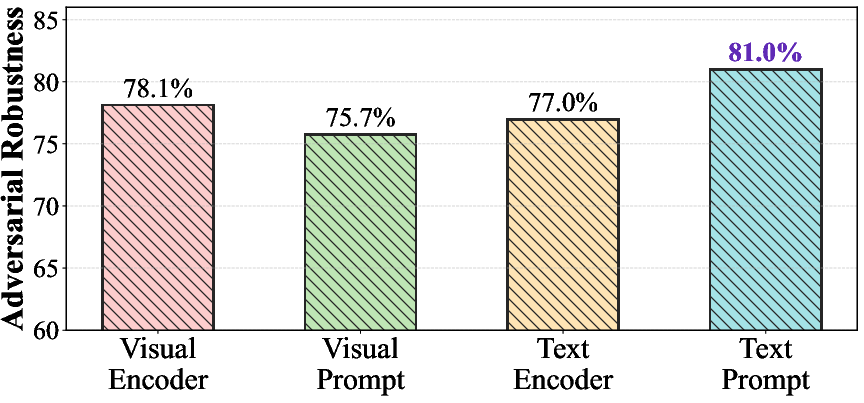
Figure 7: Robustness across different optimized parameter configurations. SS-TPT remains effective for text prompt tuning, encoder tuning, and visual prompt tuning.
Ablations and Analysis
Implications and Future Directions
SS-TPT establishes that direct assessment of per-view trustworthiness, via stability and suitability, is a dominant design principle for robust and efficient test-time adaptation in VLMs. This mechanism:
- Reduces computational burden by obviating the need for excessive augmentations to guarantee robustness.
- Provides a higher-level view selection paradigm, extendable beyond image-level invariances (e.g., to spatial, temporal, or modality consistency measures).
- Suggests that adaptive, instance-specific losses outperform rigid uniform consistency or entropy minimization under adversarial conditions.
Potential future work includes integrating localized spatial scoring, meta-learned trust estimators, or hybrid models combining prompt, encoder, and visual prompt adaptation with dynamic SS scoring.
Conclusion
SS-TPT advances test-time prompt tuning for VLM adversarial robustness by introducing stability and suitability-guided mechanisms for assessing and leveraging augmented view quality. By informing adaptation and inference with these principled metrics, SS-TPT achieves strong robustness-throughput trade-offs, excelling in both clean and adversarial performance across diverse datasets, architectures, and attack scenarios. The work substantiates the practical and theoretical merit of quality-aware adaptation, paving the way for more trustworthy and efficient deployment of vision-LLMs in adversarial and distribution-shifted environments.