- The paper presents a novel instance-level structured defect grounding method that represents text-to-image failures as precise quartets of location, type, reason, and importance.
- It introduces the SDG-30K dataset and a dedicated evaluation protocol, achieving competitive performance in defect localization and semantic alignment compared to traditional heatmap methods.
- The framework enhances downstream applications by enabling refined reward shaping in diffusion models and guiding defect-specific image improvements.
Structured Defect Grounding for Text-to-Image Feedback: Technical Overview and Implications
Motivation and Context
Text-to-image (T2I) models have advanced in photorealism yet continue to manifest localized, subtle, and semantically entangled defects that global or pixel-wise supervision cannot adequately characterize. Prevailing scalar or dense heatmap feedback paradigms—such as those in RichHF and ImageDoctor—reduce complex defects to coarse spatial or aggregate signals, failing to connect specific error types to their semantic context and precise location. This disconnect impedes principled model alignment, granular evaluation, and actionable refinement of generative systems.
The "Where, What, Why, and Importance: Structured Defect Grounding for Text-to-Image Feedback" paper (SDG) (2606.06113) addresses this representational bottleneck by reframing T2I defect diagnosis as instance-level structured set prediction, whereby each defect is expressed as a quadruple: location (bounding box), type (artifact or misalignment), natural-language reason, and importance score.
SDG introduces a unified representation for T2I failures, encoding each as a tuple (bi,ti,ri,si), with b as a quantized bounding box, t as a categorical defect type (artifact, misalignment), r as a free-form reason, and s as an integer importance reflecting perceptual and semantic impact. This structured approach enables both fine-grained attribution of failures and prioritized, context-aware evaluation essential for complex generative errors.

Figure 1: Qualitative comparison between heatmap-based and SDG-style structured feedback, contrasting coarse artifact/misalignment maps with instance-level bounding boxes, explicit types, chain-of-thought traces, and importance scores.
SDG-30K Dataset and Evaluation Protocol
To enable systematic training and evaluation, SDG-30K, a 30k-image dataset, is constructed with human box-level defect annotations across four modern T2I generators. Each instance is labeled with bounding box, type, concise description (post-processed via Gemini 3 Pro for detailed English reasons and importance), covering both artifact and misalignment failures.
A dedicated evaluation protocol (SDG-Eval) is established:
- Image-level metrics: Detection F1 for presence of each defect type, clean-image accuracy.
- Defect-level metrics: Class-aware Hungarian matching between predicted and ground-truth instances yields [email protected]/0.5 (localization), DescCos (description similarity via Qwen embeddings), and ImpAcc (importance score accuracy).
The dataset reveals nontrivial rates of both artifact and misalignment defects—underscoring the insufficiency of scalar feedback in characterizing present-day T2I failures.
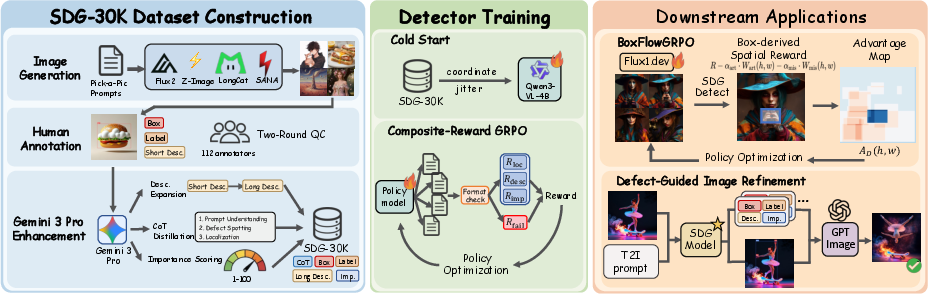
Figure 2: SDG framework: dataset construction pipeline, two-stage detector training (SFT + GRPO), and downstream applications including diffusion reward shaping and defect-guided image refinement.
SDG Detector: Model Architecture and Optimization
The SDG detector operationalizes the framework by treating T2I defect localization as structured vision-language generation. The base model (Qwen3-VL-4B-Instruct) is fine-tuned in two stages:
Crucially, the detector outputs both a reasoning trace (chain-of-thought for interpretability) and a defect set in JSON, natively compatible with autoregressive VLM decoders.
Quantitative and Qualitative Results
Numerical Performance: On SDG-30K, the SDG detector with GRPO achieves artifact/misalignment [email protected] scores of 0.263/0.387—significantly close to human upper bounds (0.278/0.409). Description cosine and importance metrics are consistently high (>0.88). Notably, zero-shot GPT-5.4 and Gemini 3 Pro fall short by large margins in localization and misalignment recall, substantiating the necessity for in-domain, structured supervision and optimization.
Cross-Dataset Generalization: When evaluated zero-shot on RichHF-18K, SDG yields misalignment F1 nearly 3x that of ImageDoctor, demonstrating superior transferability in capturing prompt-conditioned failures versus architectures centered on heatmap regression.

Figure 3: Qualitative comparison on SDG-30K between SDG, ImageDoctor, and ground-truth, illustrating precise instance-level grounding and type attribution.

Figure 4: Extended evaluation showing the fidelity of SDG in complex, heterogeneous defect scenarios.
Downstream Applications
Diffusion Model Alignment via BoxFlow-GRPO
SDG outputs serve as structured, importance-weighted spatial penalization maps within the BoxFlow-GRPO framework for diffusion model RL. Unlike previous approaches that modulate scalar rewards by predicted defect heatmaps, BoxFlow-GRPO constructs, for each latent location, reward signals proportional to the detected importance of artifact/misalignment boxes.
Empirical Results: BoxFlow-GRPO achieves the highest average relative improvement (+2.4%) across preference and quality benchmarks while uniquely increasing the real-image likelihood, a dimension where scalar-masked and heatmap-driven baselines regress—quantitatively mitigating reward hacking and preserving photographic realism.


Figure 5: Visual comparison illustrating the benefit of structured spatial reward on output fidelity and prompt alignment.

Figure 6: Extended evaluation of BoxFlow-GRPO on challenging prompts, demonstrating robust compositional and attribute faithfulness.
Defect-Guided Refinement
SDG also enables semantically meaningful, localized correction through structured feedback fed into GPT-Image-1.5, surpassing both caption-only and heatmap/text-based editing in human GSB (Good/Same/Bad) preference rates.

Figure 7: Attribute-corrective and artifact-removal effectiveness of SDG-guided image editing, particularly in semantically subtle prompt-conditioned mismatches.
Theoretical and Practical Implications
This work establishes structure-aware, instance-level feedback as a general interface for evaluating and aligning generative models beyond the reach of global metrics or coarse pixel-wise feedback. The SDG formalism allows fine-grained reward shaping in diffusion model RL, exposing reward hacking that escapes scalar detectors and providing actionable signals for downstream editing.
Practically, this advances interpretability and failure diagnosis in T2I, supports modular system design (decoupling detector and generator), and serves as a foundation for extensible feedback taxonomies (future additions: safety, aesthetics, etc.). Theoretically, SDG highlights the unique alignment leverage of structured, compositional error representation and advances the interface between vision-language modeling and RL in generative alignment.
Future Directions
Subsequent work is expected to exploit the modularity of SDG tuples, expanding the set of defect types, introducing richer spatial primitives (e.g., masks, relation graphs), or incorporating subjective attributes (aesthetic, safety) into structured feedback. Integration with active learning and adversarial detection frameworks appears promising for bootstrapping the annotation of failure cases. Additionally, leveraging synthetic or web-scale sources for scalable structured feedback remains an open research area for adapting SDG to further diverse domains.
Conclusion
Structured Defect Grounding furnishes a unified, extensible instance-level protocol for T2I diagnosis, evaluation, and alignment. Through both rigorous empirical validation and modular downstream application, it advances the granularity, generalizability, and interpretability of feedback in modern generative modeling (2606.06113).