LLM Explainability with Counterfactual Chains and Causal Graphs
Abstract: Causal graphs provide a high-level language for making mechanisms transparent. Recent work uses LLMs to recover causal graphs of external-world processes. Instead, in this paper, we use causal graphs to model LLM inference itself, providing stakeholders with a transparent view of how the model perceives and organizes high-level concepts to produce a prediction. We propose a four-phase method for constructing such graphs. Given a target LLM and a set of textual examples, our method discovers class-discriminative, human-interpretable concepts and maps each input to LLM-perceived concept states. We then introduce an MCMC-inspired counterfactual augmentation procedure that expands the sparse observational data through chains of counterfactuals. This enables stable causal discovery with $σ$-CG, yielding informative, interpretable graphs. We apply our method to three LLMs across disease diagnosis, sentiment analysis, and LLM-as-a-judge classification tasks. We evaluate the learned graphs for predictive fidelity and structural stability, and the MCMC-inspired augmentation for convergence and downstream utility. Our results show that the discovered causal graphs capture meaningful dependencies consistent with LLMs' reasoning. Together, this paper provides a foundation for concept-level explainability of LLMs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “LLM Explainability with Counterfactual Chains and Causal Graphs”
What is this paper about?
This paper tries to open up the “black box” of LLMs by showing, in a human-friendly way, how they make decisions. Instead of guessing what clues in the text a model uses, the authors build a cause-and-effect map—like a flowchart with arrows—that shows which high-level ideas (called “concepts”) the model notices and how those ideas lead to its final answer.
What questions were the researchers asking?
- Can we build a cause-and-effect map of how an LLM thinks, not about the real world, but about its own reasoning?
- Can we automatically find human-understandable concepts (like “headache” or “happy tone”) that the model relies on?
- Can we create good “what-if” examples to fill in gaps in the data so the map we learn is stable and reliable?
- Do the maps we learn really match how the model behaves (that is, do they predict the model’s outputs well)?
How did they do it? (In everyday terms)
Think of the model’s decision process like a recipe. The “ingredients” are concepts (e.g., “softness,” “headache,” “sarcasm”). The final “dish” is the model’s answer (e.g., diagnosis, positive/negative review, preferred response). The researchers built the recipe in four steps:
- Step 1: Use the model’s own answers They first ask the model to label the texts (e.g., positive/negative), then treat these labels as the “truth” for understanding how the model itself reasons.
- Step 2: Discover the model’s concepts They ask the model to list concepts that help tell the classes apart (for example, “headache supports migraine,” “fever supports influenza,” or “sarcastic tone supports negative sentiment”). Then, for each text, they record which concepts show up and which class each concept seems to support, including “absent” if the concept doesn’t appear.
- Step 3: Create “what-if” chains to fill gaps Real data doesn’t cover every combination of concepts. So they generate counterfactuals—new, slightly edited texts that change one concept at a time (like making the “papaya” firmer or removing “sensitivity to light”) while keeping the rest as steady as possible. They only accept a new example if: 1) the targeted concept really changed in the intended direction, and 2) other concepts didn’t drift too much. This is like carefully tweaking one ingredient in a recipe to see its effect, without changing the whole dish.
- Step 4: Build the cause-and-effect map With the expanded dataset (original + “what-if” examples), they use a graph-finding tool to draw arrows from concepts to other concepts and to the final prediction. The result is a “causal graph”—a map of how the model links ideas to make its decision.
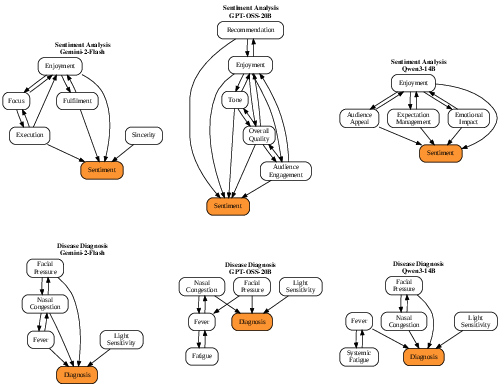
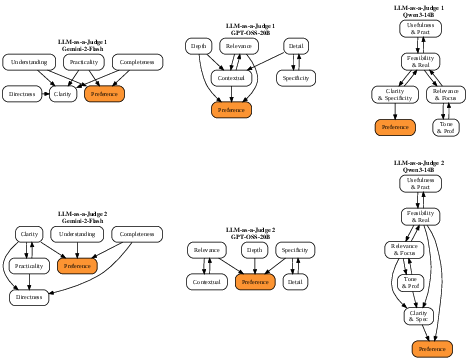
Example: In a medical text, “headache” and “sensitivity to light” might point toward “migraine,” while “nasal congestion” might point toward “sinusitis.” The graph shows these arrows so you can see the model’s reasoning at a glance.
What did they find, and why does it matter?
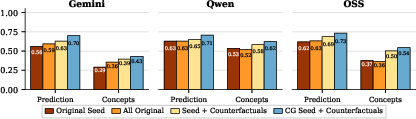
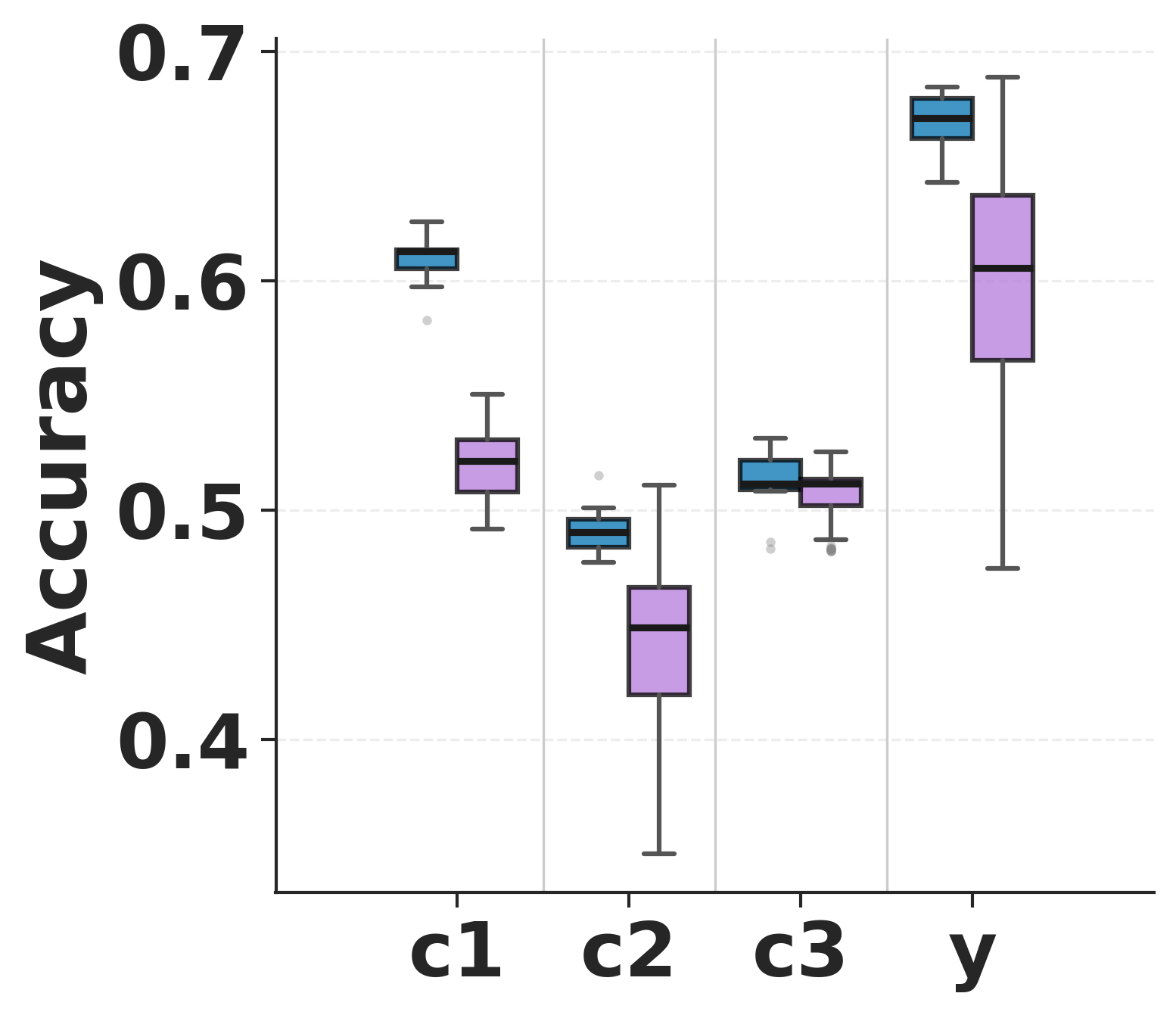
- The maps predicted the model’s behavior well When they used the immediate “parent” concepts (the ones with arrows pointing into a node) to predict that node (either a concept or the final answer), they did better than using other random sets of concepts. This suggests the discovered graphs capture meaningful cause-and-effect links in the model’s reasoning.
- The “what-if” chains made the maps better and more stable By generating targeted counterfactuals, they filled in missing combinations of concepts. This led to more accurate and more consistent graphs. Over time, the graphs stabilized—adding more counterfactuals stopped changing the structure, which is a good sign.
- Different tasks and models use different reasoning styles On a structured, synthetic medical task, different LLMs found similar concepts (like key symptoms) and reasoning patterns. But on messy, real-world tasks (movie review sentiment and “LLM-as-a-judge” preferences), models sometimes used different concepts and different graph structures. This tells us that models may perform similarly but “think” differently—a big deal if you care about fairness, safety, or alignment with expert expectations.
Why it matters: These concept-level maps help people see not just what the model decided, but why. That’s useful for doctors, judges, teachers, or anyone who needs transparent AI. It can reveal hidden shortcuts, biases, or misunderstandings, and help users choose and trust the right model.
What’s the potential impact?
- More trustworthy AI decisions Clear maps of cause-and-effect can help catch biases and errors before they cause harm, especially in high-stakes areas like health or law.
- Easier model comparison and auditing If two models both score well but for different reasons, these graphs show which one aligns better with your values or rules.
- A foundation for better explanations Instead of one-off explanations for single cases, this approach gives a global picture of how the model reasons across many cases.
The authors also note challenges: the method relies on the model to describe its own concepts and to write good “what-if” texts, and some parts of the evaluation focus on the most direct links rather than very long chains. Still, this is a strong step toward making AI reasoning more visible and understandable.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and open questions that remain after this work, framed to inform follow‑up research.
- Faithfulness of concept annotations: How well do LLM-elicited concept states reflect the model’s true internal computation? Validate with mechanistic probes, activation-patching, or external annotators rather than relying solely on self-reports.
- Self-referential pipeline risk: The same LLM proposes concepts, annotates, generates counterfactuals, and is the target of explanation. Quantify and mitigate circularity (e.g., cross-model triangulation, human audits, or using separate models for different phases).
- Concept representation adequacy: Concepts are encoded as categorical subsets of labels, collapsing intensity/polarity and multi-dimensional nuance. Compare against richer representations (e.g., graded strengths, continuous scores, multi-attribute vectors).
- Completeness/minimality of the concept set: No test verifies that the selected concepts are sufficient mediators of X→Y. Measure residual dependency of Y on X given C (e.g., test whether P(Y|X,C) ≈ P(Y|C)) and develop methods to add/drop concepts until mediation is achieved.
- Sensitivity to batching and randomness: Concept discovery depends on batch grouping, prompt phrasing, temperature, and random seeds. Perform repeated runs with shuffled batches and report stability measures and confidence intervals.
- Use of predicted vs. ground-truth labels: Replacing labels with model predictions may bias concept discovery. Systematically compare graphs learned from predictions, ground truth, and mixtures, and assess downstream differences.
- Structural constraints correctness: The framework disallows direct X→Y edges and forces mediation via concepts. Test sensitivity to relaxing this assumption and quantify how often a direct text-to-prediction path is still needed.
- Identifiability under cycles and discreteness: With sigma-CG on discrete multi-valued variables and possible cycles, when are directions identifiable? Provide theoretical conditions or synthetic studies quantifying recoverability and error modes.
- Edge orientation and spurious cycles: Cycles may be artifacts of sparse coverage or algorithmic bias. Validate edges with targeted interventions on concepts and assess whether induced changes align with predicted directions.
- Lack of path-level validation: Evaluation focuses on local parents. Devise tests for multi-hop causal influence and path-specific effects (e.g., compute mediated effects along identified paths using interventional counterfactuals).
- Absence of ground-truth benchmarks: There is no standard to score graph correctness. Build controlled simulators or modular “toy” LLMs with known concept-graphs to quantitatively evaluate recovery accuracy.
- Limited algorithmic comparisons: Only sigma-CG is used. Compare with alternative causal discovery methods (e.g., NOTEARS, FCI/FCI+ variants, GES, DAG-GNN, ICA-based methods, hybrid approaches) and ensembles for robustness.
- Handling latent confounders in practice: Although sigma-CG can theoretically cope with latents, the practical impact of unmodeled confounders between concepts is unassessed. Develop diagnostics and tests for latent confounding in discovered graphs.
- Quantifying edge strengths and uncertainty: The graphs are topological only. Estimate causal effect sizes with uncertainty (e.g., bootstrapping, Bayesian structure learning) and report confidence in edges.
- MCMC-inspired expansion lacks target distribution: The chain has no formal stationary distribution or mixing guarantees. Define a target over concept states, develop acceptance rules consistent with it, and provide mixing diagnostics.
- Coverage of the concept manifold: KL-based convergence is heuristic and may underdetect underexplored regions. Augment with multiple chains, diverse seeds, effective sample size, and coverage metrics over stratified concept partitions.
- Acceptance criteria hyperparameters: The choices of ε (concept drift tolerance), K (steps), and R (regenerations) are not justified. Run sensitivity analyses and propose adaptive tuning or validation-driven stopping rules.
- Side-effect control via concept-count drift is crude: Counting changed concepts ignores semantic closeness. Incorporate semantic similarity or entailment constraints (e.g., embedding distances, textual entailment tests) to better preserve non-target content.
- Faithfulness of counterfactuals: Generated edits may not be minimal or may introduce hidden shifts. Add human or multi-model verification, lexical edit-distance checks, and entailment consistency tests to audit counterfactual faithfulness.
- Data efficiency and sample complexity: How many counterfactuals are needed to achieve stable structure? Develop stopping criteria, active selection of interventions, and sample-complexity estimates for reliable discovery.
- Scalability: Concept count and value arity lead to combinatorial explosion; sigma-CG and exhaustive evaluations may not scale. Explore sparsity assumptions, structure priors, constraint pruning, and scalable score-based search.
- Generalization beyond classification: The framework is tailored to single-label classification; extension to generation, multi-label outputs, or structured prediction is open. Define concepts and causal targets for generative settings.
- LAJ per-query fragmentation: One graph per query does not reveal cross-query regularities. Develop methods to cluster queries, learn shared meta-graphs, and infer reusable criteria across topics.
- Robustness to domain shift and adversarial edits: Test whether learned graphs remain stable under domain shifts, synonyms/paraphrases, and adversarial perturbations of inputs and prompts.
- Cross-lingual and multimodal extension: The method is English-text centric. How to define and align concepts across languages and modalities (e.g., vision-language) remains open.
- Human-centered evaluation: No user study measures interpretability, usefulness, or actionability. Conduct expert and end-user evaluations to assess whether graphs improve trust, debugging, and decision-making.
- Fairness and bias auditing: Use graphs to detect biased heuristics (e.g., protected-attribute proxies) and evaluate fairness constraints or debiasing interventions at the concept level.
- Reproducibility under model updates: Quantify how graphs change with LLM version updates, decoding parameters, and hardware/software differences; provide protocols for longitudinal tracking.
- Inter-model comparability: Different LLMs yield different concept sets and topologies. Formalize alignment methods to compare, map, or merge concepts across models.
- Post-hoc vs mechanistic validity: Bridge to mechanistic interpretability by correlating concept nodes with neurons, circuits, or representation directions; test whether editing those components changes concept states as predicted.
- Residual unexplained variance: Report how much of Y can be predicted from C vs. X, and investigate unexplained components (missing concepts, noise, or direct text effects).
- Ethical safeguards for counterfactual generation: Especially in clinical domains, generated counterfactuals may contain unsafe content. Incorporate safety filters, red-teaming, and review processes.
- Prompt engineering dependence: The pipeline’s outputs may be prompt-sensitive. Establish prompt-robust procedures (e.g., instruction ensembles, paraphrase-averaging, or prompt-tuning).
- Duplicate and near-duplicate management: Expansion may generate redundant samples that skew estimates. Implement deduplication and weighting schemes to avoid bias.
- Output calibration and uncertainty in annotations: Concept annotations are point estimates. Elicit and leverage calibrated probabilities (e.g., temperature scaling, Bayesian decoding) and propagate uncertainty into discovery.
- Integration of expert priors: For specialized domains, allow experts to supply concept constraints or priors and study how they improve structure accuracy and stability.
- Failure mode analysis: In settings where parent sets are not Top‑3 or accuracy gains are small, characterize why (e.g., noisy concepts, poor coverage, spurious edges) and design targeted fixes.
Practical Applications
Below is an overview of practical applications derived from the paper’s method for building concept-level causal graphs of LLM inference and its MCMC-inspired counterfactual augmentation. Each application highlights sectors, potential tools/workflows, and feasibility assumptions.
Immediate Applications
These are deployable now with current LLMs, prompt engineering, and standard MLOps stacks.
- Concept-level model audit dashboards — sectors: software/MLOps, healthcare, finance, legal, public sector
- What: Build a “Concept Causal Graph Explorer” that extracts discriminative concepts, maps input texts to concept states, and displays the discovered concept→prediction graph as evidence of how the LLM reasons.
- Tools/workflows: Batch concept discovery and annotation; σ-CG graph discovery; per-input concept vectors; export to model cards and audit logs.
- Assumptions/dependencies: Access to the target LLM for deterministic classification (τ=0) and generative prompting (τ≈0.5); data governance to handle sensitive text; stakeholder acceptance that explanations reflect the model’s perspective, not necessarily ground truth.
- Pre-deployment model selection and validation via reasoning comparisons — sectors: healthcare, finance, enterprise AI
- What: Compare competing LLMs by their concept sets and causal topologies to pick the model whose reasoning aligns with domain expectations (e.g., clinical features for triage).
- Tools/workflows: “Reasoning Comparator” that reports concept overlap, edge similarity, and parent-set predictive fidelity; run on representative datasets.
- Assumptions/dependencies: Sufficient coverage of domain-specific examples; domain experts to interpret plausibility of discovered concepts.
- Counterfactual red-teaming and bias probing — sectors: policy/compliance, HR, finance, content moderation
- What: Use the MCMC-inspired counterfactual chains to stress-test decision boundaries and reveal reliance on sensitive or spurious concepts (e.g., lexical markers, identity terms).
- Tools/workflows: “Counterfactual Chain Probe” that targets concepts for More/Less interventions, logs acceptance tests (target alignment, minimal side effects), and summarizes causal effects.
- Assumptions/dependencies: Clear policies on sensitive attributes; human oversight to review adversarial perturbations; careful prompt design to avoid harmful content generation.
- Training data augmentation for robustness (with caution) — sectors: NLP product teams, data ops
- What: Use accepted counterfactuals to densify underrepresented concept configurations and reduce spurious correlations in fine-tuning datasets.
- Tools/workflows: Integrate the counterfactual generator as a data pipeline step; filter with acceptance tests; retrain or fine-tune classifiers or LLMs.
- Assumptions/dependencies: For training, labels should be tied to domain ground truth rather than LLM-predicted labels; quality control to avoid label noise; licensing for data reuse.
- Compliance-ready documentation and evidence trails — sectors: regulated industries (EU AI Act, healthcare, finance)
- What: Add concept-level causal graphs and parent-set predictive metrics to model cards and audit packages as “process evidence” of model behavior.
- Tools/workflows: Automated export of graphs, convergence plots (KL, structural stability), and per-node parent predictive metrics.
- Assumptions/dependencies: Regulator acceptance that model-internal, concept-level graphs are an admissible form of explainability; periodic regeneration when models or data change.
- Query-scoped LLM-as-a-judge rubric discovery — sectors: benchmarking, content platforms, evaluation vendors
- What: For each prompt/query, construct a per-query causal graph over evaluation criteria to show why a judge prefers one answer over another.
- Tools/workflows: Generate diversified answer pairs for a given query; extract concepts and run σ-CG; present the per-query reasoning graph to developers and evaluators.
- Assumptions/dependencies: Compute budget for per-query datasets; careful de-biasing of generated pairs; governance for potential exposure to sensitive content.
- Human-in-the-loop decision support — sectors: clinical triage, customer support, legal triage
- What: Surface per-input concept states and their directed links to predictions so operators can validate whether the LLM considered appropriate factors before acting.
- Tools/workflows: UI plugin that shows (X → concepts → prediction) with parent contributions; operator can accept/reject or request counterfactuals.
- Assumptions/dependencies: Clear handoff policies to avoid automation bias; alignment between extracted concepts and domain ontologies.
- Production monitoring for reasoning drift — sectors: MLOps/SRE for AI systems
- What: Track changes in discovered concept sets and edges over time to detect shifts in model reasoning that may precede performance or fairness degradation.
- Tools/workflows: “Causal Graph Monitor” that recomputes graphs on periodic samples; alarms on edge changes, parent-set predictive drops, KL/structural stability deviations.
- Assumptions/dependencies: Scheduled sampling from live traffic or shadow data; thresholds tuned to avoid alert fatigue.
Long-Term Applications
These require further research, scaling, or integration into training loops and broader standards.
- Training-time causal alignment and regularization — sectors: safety-critical AI, healthcare, finance
- What: Incorporate losses/constraints that steer models toward human-approved concept→prediction graphs (e.g., penalize reliance on banned parents).
- Tools/workflows: “Causal Regularizer” that compares current graph vs. policy graph; RLHF or supervised fine-tuning guided by concept-level feedback.
- Assumptions/dependencies: Stable concept extraction across epochs; methods to enforce graph constraints without harming utility.
- Standardized reasoning-benchmarks with ground-truth graphs — sectors: academia, evaluation consortia
- What: Create benchmarks where concept variables and canonical causal structures are known, enabling objective scoring of reasoning fidelity.
- Tools/workflows: Public datasets with controlled concept distributions; baseline toolkits for concept discovery, augmentation, and σ-CG.
- Assumptions/dependencies: Community consensus on gold graphs; careful dataset design to avoid shortcut learning.
- Cross-model Reasoning Alignment Score for procurement — sectors: public sector, large enterprises
- What: Define metrics quantifying how well a model’s discovered graph aligns with domain policies or expert graphs; use in vendor selection and model approval.
- Tools/workflows: Similarity metrics over nodes/edges/parents; acceptance thresholds; automated reports for RFPs.
- Assumptions/dependencies: Policy-defined “approved” concept graphs; legal clarity on how such scores inform procurement.
- Bridging to mechanistic interpretability — sectors: safety research, foundational model labs
- What: Map discovered high-level concepts and causal edges to neurons/heads/circuits for end-to-end interpretability from tokens to circuits.
- Tools/workflows: Joint probes: (concept states) ↔ (mechanistic features); causal tracing; interventions aligned with concept shifts.
- Assumptions/dependencies: Stable, localizable representations; scalable tools for large models; careful validation to avoid cherry-picking.
- Extension to open-ended generation and multimodal reasoning — sectors: robotics, VLMs, creative tools
- What: Generalize from classification to generation by modeling concept-level pathways that mediate generation criteria; extend to text+image/audio tasks.
- Tools/workflows: Sequence- or step-wise concept tracking; concept-aware decoding constraints; multimodal concept libraries.
- Assumptions/dependencies: Robust concept extraction for non-classification outputs; handling temporal and hierarchical dependencies.
- Automated causal fairness enforcement — sectors: lending, hiring, insurance
- What: Use discovered graphs to detect and prevent protected attributes (or proxies) from being parents of predictions; enforce counterfactual fairness.
- Tools/workflows: “Causal Fairness Enforcer” to audit and constrain edges; MCMC counterfactuals for sensitive attribute interventions.
- Assumptions/dependencies: Reliable identification of protected/proxy concepts; legal and ethical oversight; mitigation strategies that preserve utility.
- Active data collection and labeling guided by concept coverage — sectors: data operations, annotation platforms
- What: Use coverage gaps in the concept-state space to drive targeted data acquisition and labeling, reducing sample complexity.
- Tools/workflows: Acquisition functions over uncovered concept combinations; integrated counterfactual generation for targeted sampling.
- Assumptions/dependencies: Budget for curated data; human-in-the-loop validation of concept states.
- Synthetic dataset generation with controlled concept distributions — sectors: model training, stress testing
- What: Leverage the MCMC-inspired procedure to synthesize corpora covering hard-to-observe concept configurations, for training or stress testing.
- Tools/workflows: “Concept-conditioned Text Synthesizer” with acceptance checks; curriculum generation focused on underrepresented states.
- Assumptions/dependencies: Faithfulness of generated texts; avoidance of training signal leakage; alignment with downstream label definitions.
- Real-time decision-time explanations — sectors: contact centers, clinical decision support
- What: Produce a per-decision concept graph on the fly with minimal latency for live explanations and operator guidance.
- Tools/workflows: Cached concept extractors; fast approximations of parent sets; on-device or edge inference for privacy.
- Assumptions/dependencies: Latency budgets; compute footprint; robust caching to reduce cost.
- Legal-grade audit trails and evidence management — sectors: compliance, insurance, legal tech
- What: Preserve chains of counterfactuals, acceptance decisions, and final graphs as auditable artifacts supporting incident reviews and regulatory inquiries.
- Tools/workflows: Immutable logging; evidence serialization formats; retention policies aligned with privacy regulations.
- Assumptions/dependencies: Storage and governance; clarity on evidentiary standards and privacy constraints.
These applications leverage the paper’s core innovations: (i) model-driven discovery of human-interpretable concepts and their causal organization; (ii) MCMC-inspired counterfactual augmentation for dense, realizable coverage of the concept space; and (iii) causal discovery (σ-CG) that tolerates cycles and discrete variables. Collectively, they enable more actionable, process-level explainability for LLMs across product development, governance, and education.
Glossary
- Acyclicity: The property of a graph having no directed cycles, often assumed to make causal discovery identifiable. "requiring assumptions such as acyclicity, temporal ordering, or restricted functional forms"
- Adjustment: A causal inference technique that controls for confounding by conditioning on covariates when estimating causal effects. "typically via causal inference methods such as counterfactuals \citep{toker2026libertycausalframeworkbenchmarking}, matching \citep{GatCFCSR24}, or adjustment \citep{DBLP:journals/coling/FederOSR21}."
- Attention heads: Transformer components that compute attention distributions, sometimes analyzed as causal mediators in mechanistic interpretability. "such as attention heads, neurons, residual-stream directions, or higher-level representations"
- Chain-of-thought rationales: Sequences of intermediate reasoning steps generated by an LLM to justify an answer. "chain-of-thought rationales \citep{DBLP:journals/corr/abs-2501-18645}"
- Causal discovery: The process of inferring causal structure (graph edges and directions) from data under assumptions. "Causal discovery aims to recover causal structure from data"
- Causal effect: The change in a model prediction or outcome attributable to intervening on a variable or concept. "enable estimation of the causal effects of high-level concepts on model predictions"
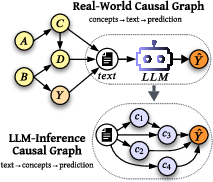
- Causal graph: A directed graph where edges represent direct cause-and-effect relationships among variables. "A causal graph is a directed graph whose edges encode direct cause-and-effect relationships among variables"
- Causal inference: A framework for estimating cause–effect relationships, often using tools like counterfactuals, matching, and adjustment. "typically via causal inference methods such as counterfactuals \citep{toker2026libertycausalframeworkbenchmarking}, matching \citep{GatCFCSR24}, or adjustment \citep{DBLP:journals/coling/FederOSR21}."
- Causal topology: The structural arrangement of causal relations in a graph, including which concepts influence others. "their causal topologies differ"
- Concept-level causal graph: A causal graph defined over human-interpretable concepts that mediate from text to prediction. "construct concept-level causal graphs of LLM inference for classification tasks"
- Concept manifold: The subset of the combinatorial concept space corresponding to realizable, coherent configurations in natural text. "stochastically explores the valid concept manifold"
- Concept vector: A vector representation assigning each interpretable concept a state aligned with task classes for a given input. "representing each example as a concept vector"
- Constraint-based (causal discovery): A family of methods that use conditional independence tests to infer edges and orientations in causal graphs. "Classical methods include constraint-based, score-based, and hybrid approaches"
- Counterfactual: A hypothetical version of an input with targeted changes to assess causal influence on predictions. "Counterfactual methods provide stronger causal evidence"
- Counterfactual augmentation: Expanding a dataset by generating counterfactual examples to improve coverage of the concept space. "We then introduce an MCMC-inspired counterfactual augmentation procedure"
- Cyclic causal structures: Causal graphs that allow feedback loops among variables, violating acyclicity. "accommodates cyclic causal structures"
- Edge orientation: The process of directing edges in a causal graph consistent with constraints and background knowledge. "and enforce this constraint during edge orientation"
- Feature attribution: Methods that assign importance scores to input features for explaining model predictions. "LLM interpretability methods include feature attribution \citep{DBLP:journals/corr/abs-2107-14000,DBLP:conf/emnlp/LanXHHL25}"
- Gelman–Rubin statistic: A convergence diagnostic for multiple MCMC chains comparing within- and between-chain variance. "Multi-chain diagnostics such as the Gelman-Rubin statistic are not directly applicable"
- Hamming distance: A metric counting the number of differing entries between two binary vectors; used here to compare edge sets. "the Hamming distance between causal edge sets recovered across successive iterations drops to zero"
- Kullback–Leibler (KL) divergence: An information-theoretic measure of divergence between probability distributions. "we calculate the Kullback-Leibler (KL) divergence"
- Markov blanket: The minimal set of variables (parents, children, and co-parents) that renders a node conditionally independent of all others. "local Markov blankets for causal effect estimation"
- Markov Chain Monte Carlo (MCMC): A class of sampling algorithms that use Markov chains to explore complex distributions. "Markov Chain Monte Carlo (MCMC) methods provide a principled way to explore complex, high-dimensional spaces"
- Matching (causal inference): A method that pairs units with similar covariates across treatment conditions to estimate causal effects. "matching \citep{GatCFCSR24}"
- Mechanistic interpretability: The study of what internal components (e.g., neurons, heads, directions) compute and how they causally mediate behaviors. "First, in mechanistic interpretability, causal graphs are defined over model-internal components"
- Metropolis–Hastings test: An acceptance rule in MCMC that probabilistically decides whether to accept a proposed sample. "akin to a Metropolis--Hastings test"
- Orthogonal expansion: An idealized scenario where new samples occupy previously unseen regions of the state space. "an orthogonal expansion upper bound"
- Perfect overlap (lower bound): A limiting case where new samples duplicate existing ones, producing minimal distributional change. "a perfect overlap lower bound"
- Positional bias: A systematic preference influenced by the order in which options are presented. "To mitigate positional bias, each pair is presented twice with the response order swapped."
- Probing (NLP): Training auxiliary classifiers on model representations to test whether specific information is encoded. "probing \citep{DBLP:journals/corr/abs-2502-04789, DBLP:journals/corr/abs-2506-01042,DBLP:journals/corr/abs-2508-06030}"
- Residual-stream directions: Directions in the transformer residual stream associated with specific features or functions, analyzed as internal mediators. "such as attention heads, neurons, residual-stream directions, or higher-level representations"
- Score-based (causal discovery): Methods that search over graph structures to optimize a scoring criterion like likelihood or penalized fit. "Classical methods include constraint-based, score-based, and hybrid approaches"
- Screening off: The property that conditioning on a node’s direct parents renders other variables irrelevant for predicting it. "the direct causal parents should screen off indirect variables"
- Sigma-CG algorithm (σ-CG): A constraint-based causal discovery algorithm that supports discrete variables and cycles. "We employ the -CG algorithm"
- Sink node: A node with only incoming edges (no outgoing edges) in a directed graph. "we impose that is the unique sink node"
- Structural stability: The robustness of a learned causal graph’s edge structure under data augmentation or perturbations. "predictive fidelity and structural stability"
- Temporal ordering: An assumption that variables can be ordered in time so that causes precede effects. "requiring assumptions such as acyclicity, temporal ordering, or restricted functional forms"
- Topological convergence: Stabilization of the learned graph’s structure (topology) as more samples are added or iterations proceed. "distributional and topological convergence"
- vLLM framework: A high-throughput inference engine for serving LLMs efficiently. "For the open-weights models (Qwen3-14B and gpt-OSS-20b) we use the vLLM framework~\cite{kwon2023efficientmemorymanagementlarge}"
Collections
Sign up for free to add this paper to one or more collections.