- The paper introduces TheoremExtr, which integrates parser and runtime extraction to capture detailed theorem dependencies in Rocq.
- The paper demonstrates scalability by processing 32 projects and extracting nearly 100,000 formal artifacts for enhanced corpus-level search.
- The paper’s method bridges gaps in traditional Rocq tools, empowering automated theorem retrieval and LLM training with unified semantic data.
Comprehensive Extraction and Search for Rocq Theorems and Definitions
Introduction
The landscape of interactive theorem proving in Rocq (Coq) exposes acute limitations in both the extraction and discoverability of formalized knowledge, particularly as the body of verified mathematics and software artifacts proliferates. While large-scale theorem repositories for other proof assistants (e.g., Lean's mathlib) provide essential infrastructure for downstream tasks (proof automation, LLM training, and advanced program analysis), Rocq has so far lacked tooling that enables unified, cross-project theorem search and dependency analysis. The paper "Extraction and Search in Rocq: Theorems, Definitions and Their dependencies" (2606.04704) addresses these deficits with TheoremExtr, a toolset that systematically extracts theorems, their dependencies, and definitions from Rocq projects and exposes them through a web-based semantic search interface. This essay provides an in-depth review of TheoremExtr’s design, implementation, evaluation, and implications.
Motivation and Challenges
Rocq’s native theorem search facilities are tightly scoped to the currently imported modules; they do not support corpus-level retrieval across disparate libraries, nor do they expose low-level dependency graphs or allow corpus mining without manual protocol engineering. The lack of machine-actionable theorem metadata impedes both expert users and researchers, especially in LLM-driven formal methods, automated prover development, and project maintenance. A key technical challenge is that reliable extraction of theorem metadata, including their precise dependencies, is nontrivial due to the distributed nature of definitions, the possibility of implicit arguments, and the distinctions between syntactic and semantic entities in Rocq’s compilation and runtime environments.
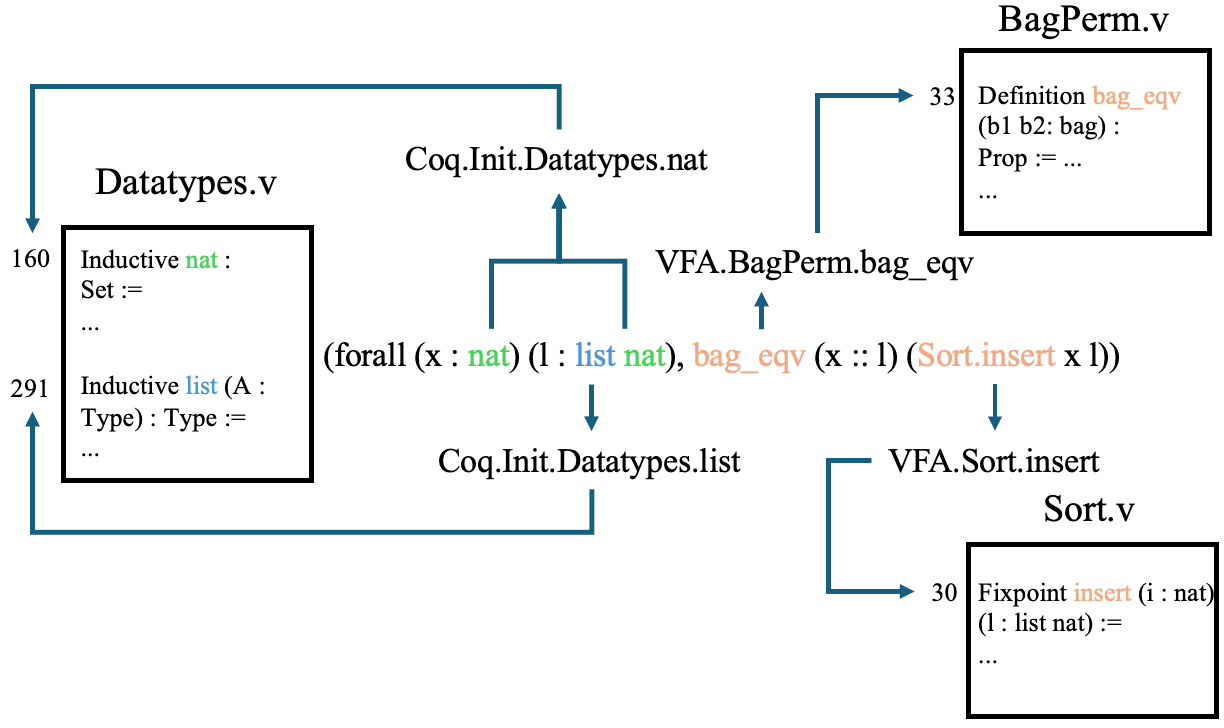
Figure 1: Visualization of a theorem and its fine-grained dependencies across project files.
TheoremExtr: Architecture and Methodology
TheoremExtr achieves comprehensive extraction by synthesizing data gleaned from Rocq’s parsing (compile-time) and runtime environments, thus enabling both accurate syntactic indexing and deep semantic dependency analysis.
The approach consists of three synergistic components:
- Parser-stage Extraction: By instrumenting the Rocq compiler, TheoremExtr captures abstract syntax data for theorems and definitions, including names, full paths, line numbers, and scope information (module context). This ensures precise localization and pre-disambiguation of entities, with negligible overhead.
- Runtime Extraction: A custom Rocq plugin operates at runtime, interrogating the loaded environment to discover actual dependencies—including those not statically enumerable—by resolving implicit arguments and function applications, and associating concrete type information to each theorem and definition as encountered during execution.
- Data Merging: Leveraging absolute naming conventions, TheoremExtr robustly merges compile-time and runtime datasets, providing a unified JSON corpus where every theorem and definition is annotated with its context, dependencies, type signatures, and cross-references.
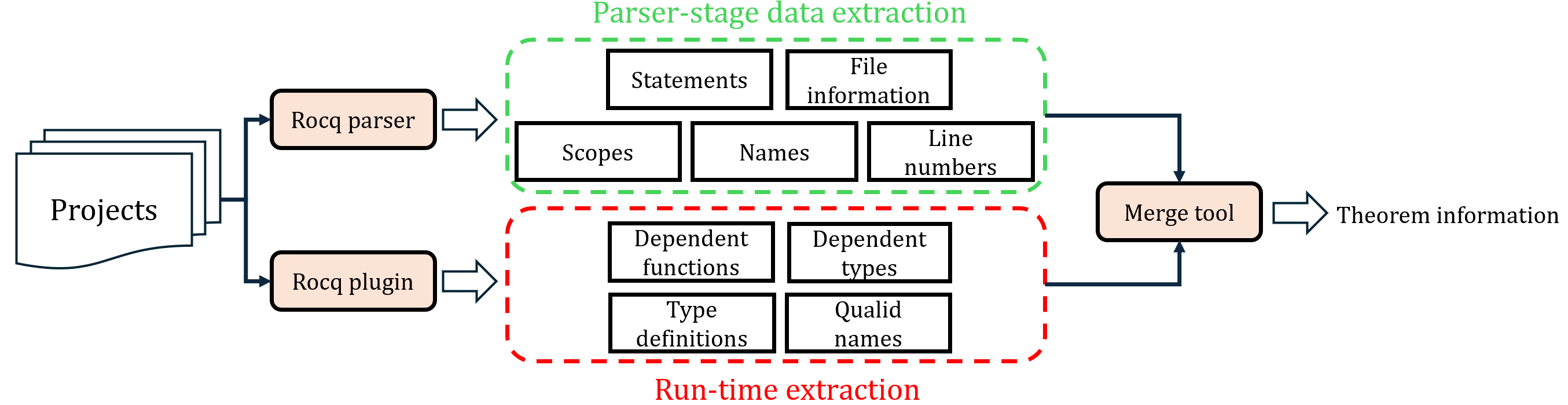
Figure 2: System-level overview of TheoremExtr's dual-phase extraction and data consolidation processes.
This dual-extraction methodology overcomes limitations of previous approaches that sample only at the syntactic or runtime level. Notably, runtime extraction captures dependencies that are otherwise semantically invisible at parsing due to deferred evaluation, while parser-stage data affords precise source mapping and project-level attribution.
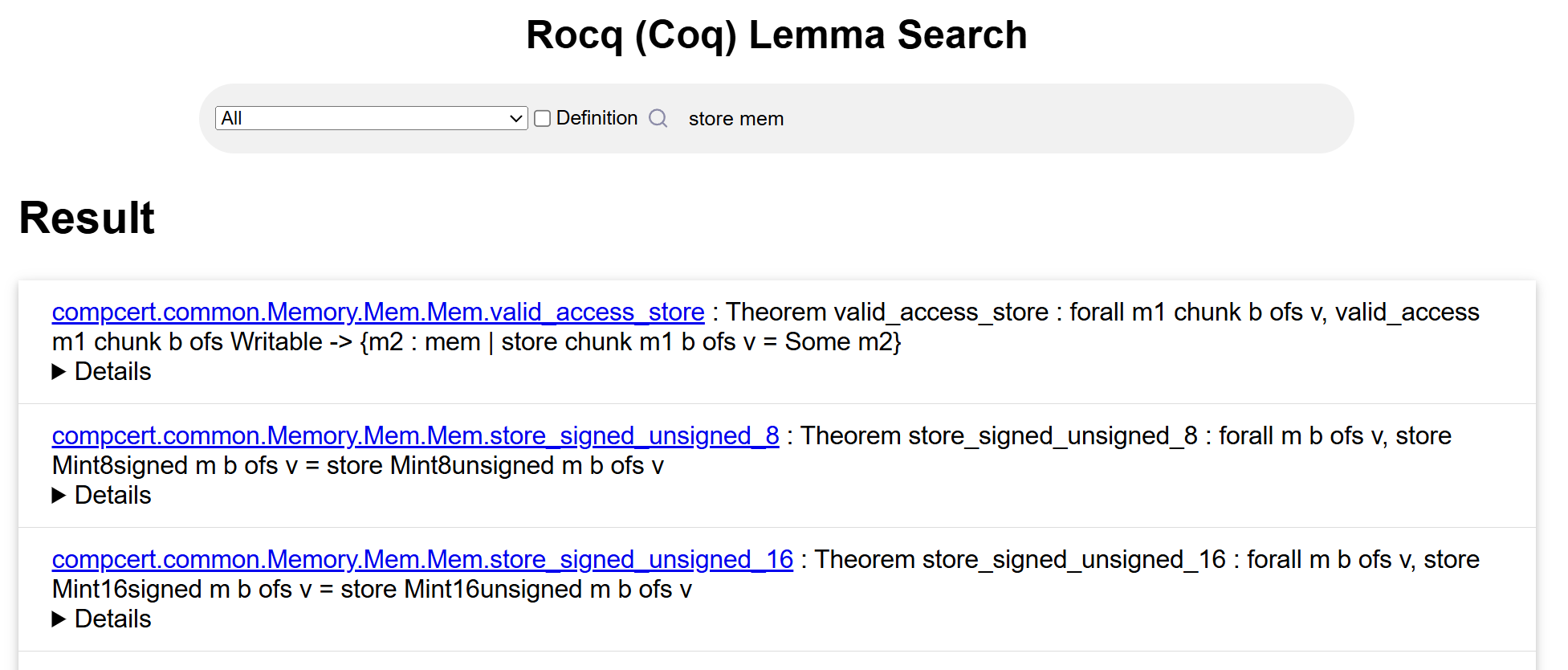
Large-Scale Extraction and Search Infrastructure
TheoremExtr was applied to 32 Rocq open-source projects, yielding a corpus of 71,795 theorems and 27,481 definitions. Extraction is scalable, with observed overheads being acceptable for large artifacts, e.g., end-to-end processing for compcert (a major verified C compiler) remains in the hundreds of seconds, and smaller projects complete within single-digit seconds.
The extracted corpus underpins a web-based search engine built on Flask with BM25-based similarity algorithms. Critically, the system supports:
Comparative Analysis
Prior tools such as CoqPyt and Coq SerAPI lack either the ability to capture deep dependency structure or require protocol-specific expertise (LSP, SerAPI command language), increasing the barrier for both end users and researchers. TheoremExtr combines operational simplicity—requiring only a single Rocq command invocation and a Python merge utility—with richer output and project version portability. Unlike pre-existing datasets such as Coqgym and CoqStoq, TheoremExtr’s corpus is up-to-date, scalable, and not restricted to a particular Rocq or plugin snapshot. Notably, extracted corpora are suitable for direct consumption in LLM training pipelines or proof agents, closing a critical gap between formal proof engineering and modern AI.
Implications, Limitations, and Future Prospects
Practical Implications: TheoremExtr enhances discoverability and reuse in Rocq, enabling researchers to execute corpus-scale mining, automated lemma invention, and similarity-based retrieval for proof engineering and program verification. The resulting dataset is machine-consumable and well-structured for large-scale downstream applications, including the construction of retrieval-augmented theorem provers and training/serving of Rocq-specific LLMs.
Theoretical Insights: The success of dual-phase extraction in Rocq sets a methodological precedent for other ITPs: comprehensive knowledge extraction requires integrating compiler-level introspection and runtime environment querying. This architecture advances the state-of-the-art for formal proof metadata curation and standardizes access patterns for theorem corpus providers.
Limitations: TheoremExtr is currently implemented against Rocq 8.20.0; adaptation to future versions requires ongoing synchronization with Rocq’s evolving API and internal representations. Implicit dependencies or unconventional scoping (e.g., via advanced module system extensions) may require additional instrumentation. The BM25 search may be suboptimal for certain advanced semantic queries—fine-tuning neural retrieval or incorporating premise selection techniques remains open.
Future Directions: Extension to broader Rocq versions, enrichment of the extracted corpus with automated lemma ranking, and integration with neural proof guidance systems are immediate priorities. There is also scope to enhance website UX, embed dependency visualization, and foster community contributions for repository coverage.
Conclusion
"Extraction and Search in Rocq: Theorems, Definitions and Their dependencies" (2606.04704) delivers a robust toolchain for comprehensive theorem and definition extraction in Rocq, establishing a scalable, semantically-rich corpus and enabling advanced search capabilities. By bridging gaps between source code, formal artifact, and search infrastructure, TheoremExtr provides a foundation for both immediate productivity improvements in the Rocq community and long-term advances in AI/ITP integration.