- The paper presents an automated synthesis workflow that uses an interactive theorem prover (Rocq) to generate a fully verified RISC-V RV32I interpreter from natural language requirements.
- It details a repair loop leveraging explicit proof states for precise error correction, outperforming SMT-based backends like Dafny in project-scale verification.
- Empirical results validate the approach with extensive testing, including 98.2 million fuzzing inputs and complete interpreter synthesis, demonstrating practical viability for industrial applications.
Interactive Theorem Provers as LLM-Agent Backends for Verified Software Project Generation
Motivation and Problem Statement
The increasing reliability demands of LLM-generated software projects, especially those mapped from natural language requirements, necessitate rigorous guarantees that go beyond unit testing and type checking. Traditional code generation by LLMs often results in syntactic correctness but leaves latent semantic errors unaddressed. Verified programming, in which implementations are required to satisfy machine-checked formal specifications, offers a solution. Prior work with verification-oriented languages (e.g., Dafny, Frama-C) exposes limitations: LLMs struggle to generate project-scale verified solutions, and automated solvers frequently fail with opaque feedback, stalling the synthesis-repair loop. This paper investigates whether interactive theorem provers (ITPs), exemplified by Rocq (formerly Coq), provide a viable backend for fully automatic, project-scale software generation and verification by LLM coding agents (2605.26017).
SPDDwL Workflow Architecture and Instantiation
The SPDDwL workflow targets the transformation of natural-language requirements into projects with a formally verified functional core, supported by an ITP backend and extraction mechanism. It systematically separates effectful host components (e.g., I/O) from pure logic, ensuring that only deterministic data transformations are proved within the ITP. The practical instantiation uses Rocq and extracts the pure core to C++, linking it with a thin host layer responsible for runtime integration.
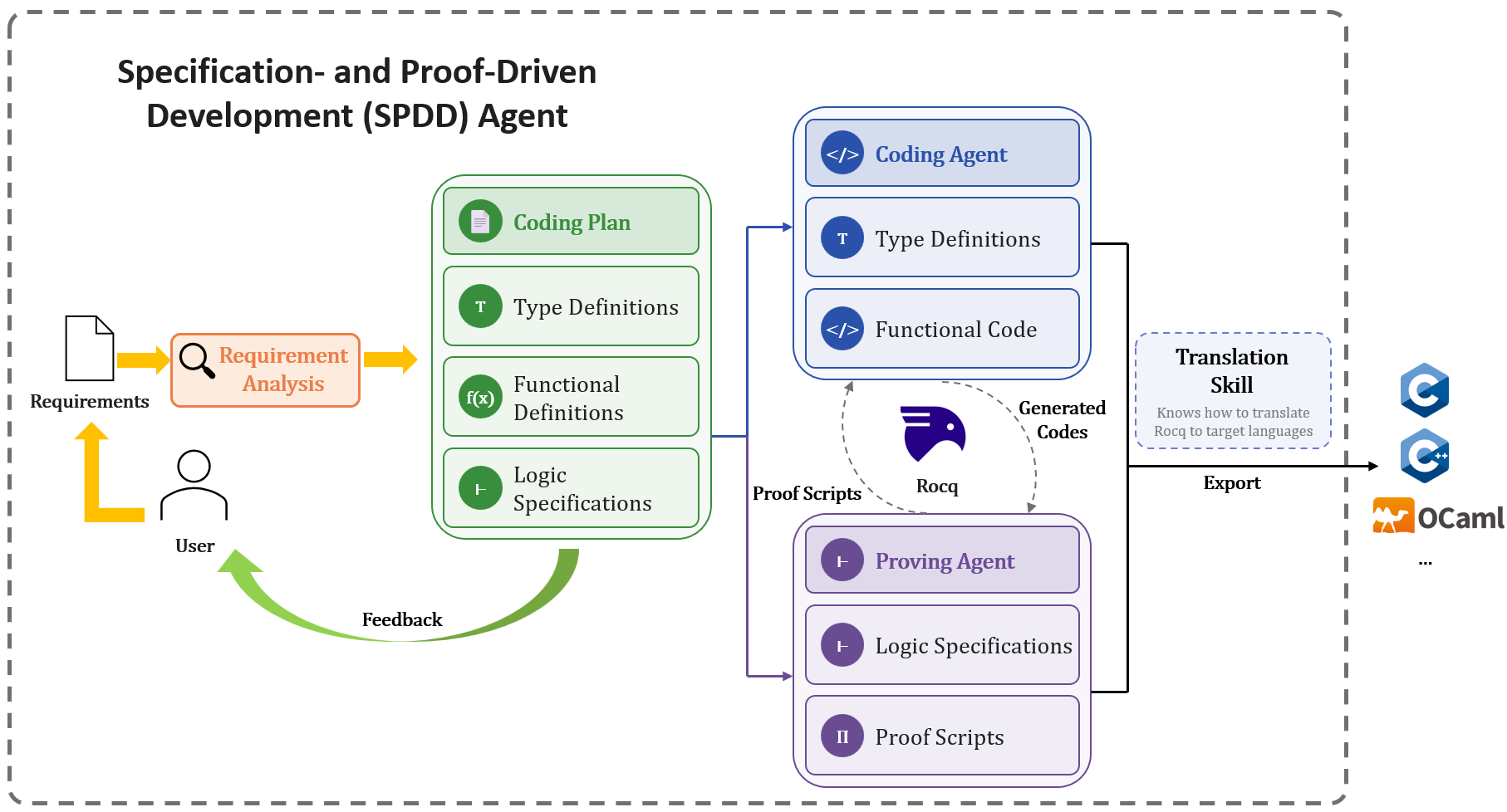
Figure 1: The SPDDwL workflow instantiated with Rocq, illustrating the pipeline from requirements analysis to verified code extraction and integration.
The workflow proceeds through:
- Requirement analysis by an LLM agent, decomposing requirements into explicit coding plans containing type definitions, function signatures, effect separation, and formal properties.
- Pure functional code and specifications generated by a coding agent and proved by a proving agent, relying on Rocq's interactive goal state for repairable feedback.
- Extraction of verified computational components to the target language (C++), where proof terms are erased but function invariants are preserved.
- Host-side glue code implementation.
Case Study: Automatic Synthesis of a RISC-V RV32I Interpreter
The primary evaluation is a complete, fully automated synthesis of an unprivileged RISC-V RV32I interpreter encompassing all 47 instructions. Following requirements provided in natural language (directly excerpted from the ISA manual), the system generates:
- A coding plan for each instruction (e.g., JALR), specifying data representations (32-bit words, register file, architectural state), handler functions, and logical properties such as state invariants and frame conditions.
- Verified Rocq code: 1,859 lines encompassing type definitions, function bodies, and proof scripts.
- Extracted C++ code: 2,848 lines for integration.
- Test harness: 265 LLM-generated instruction tests, all passing post-integration.
- Robustness validation: 12-hour AFL++ fuzzing campaign, covering 98.2 million inputs, reporting zero crashes and zero hangs.
Bold claim: This is the largest reported realistic software project with a fully machine-checked core generated without human intervention by an LLM agent; under identical configuration, automated-verification-oriented backends (Dafny) do not complete verification.
Feedback Loop: Interactive Proof Repair
The repair loop is a significant differentiator. When proof attempts fail, Rocq exposes an explicit proof state containing open goals and local context, which is leveraged by the LLM agent to generate actionable repairs—contrasting sharply with automated verifiers (e.g., Dafny) where solver timeouts offer minimal diagnostic value, leading to repair deadlocks.
A hallucinated implementation cannot pass verification, as every property is checked via formal proofs rather than relying on testing or post-hoc analysis. The model must generate both function implementation and proof; any discrepancy results in rejection by the Rocq kernel.
Comparative Evaluation: Rocq vs. Dafny Backends
Under the same 30-minute synthesis budget, the Rocq backend completes the interpreter. The Dafny backend, relying on SMT-based automated verification, fails to produce a verified implementation. The root cause is feedback granularity—Rocq's proof states allow targeted repair, whereas Dafny's solver timeouts do not. The empirical result highlights the importance of interactive, granular feedback for LLM-driven project-scale verification.
Robustness and Testing
The extracted interpreter demonstrates strong dynamic correctness under both generated test cases and aggressive fuzzing. Despite only the pure core being verified, integration with an unverified host layer (effects, runtime logic) introduces no detectable weaknesses over extended validation. These empirical results support the practical viability of mixing verified and effectful code in LLM-generated projects.
Implications and Directions for AI-Driven Verified Programming
This study substantiates that ITPs furnish not only logical rigor but also actionable, high-quality feedback for automated agents, enabling end-to-end project generation with nontrivial verification tasks. It positions ITPs like Rocq as the preferred infrastructure for agentic code synthesis, especially when semantic correctness is mandatory. The full pipeline—from requirement clarification to extraction—can be realized automatically, limited only by proof automation and interface extensibility.
The implications are significant for both practical and theoretical developments:
- Industrial safety-critical software: Trusted LLM-agent pipelines with ITP backends (e.g., Rocq, Lean, Isabelle) reduce human intervention, potentially accelerating adoption in certified systems (e.g., firmware, simulators, compilers).
- Theoretical scalability: Explicit proof-state feedback is essential for integrating LLM agents into verification-centric development, as opposed to opaque constraint-based solvers.
- Hybrid architectures: Combining pure-core extraction and effectful host layers enables flexible deployment targets (C++, Rust, OCaml), with formal guarantees preserved for verified fragments.
- Future research: Advances in proof-search, lemma retrieval, and agentic repair loops (e.g., RocqStar (Khramov et al., 28 May 2025), retrieval-augmented LLMs) will further increase scalability and reliability.
Conclusion
The paper rigorously demonstrates that interactive theorem provers, particularly Rocq, unlock a robust avenue for trustworthy, agent-driven generation of project-scale verified software from natural language requirements. The SPDDwL workflow enables precise effect separation, actionable proof repair, and reliable extraction. Strong results—complete interpreter synthesis, all tests passing, no fuzzing failures—establish ITP-backed workflows as the preferred paradigm for LLM-agent software generation where correctness guarantees are required. Theoretical and practical implications will inform future AI developments as verification-centric agentic programming continues to scale (2605.26017).