- The paper introduces the VaSE framework, a training-free method that integrates value-state magnitude reservation and stochastic eviction to preserve critical reasoning information.
- It employs two variants, VaSE-AttnV and VaSE-DKV, to dynamically balance cache efficiency and accuracy, ensuring robust long-form reasoning under memory constraints.
- Experimental results show that VaSE improves pass@1 accuracy by up to 9.2%, reduces memory usage, and enhances throughput compared to baseline eviction strategies.
Value-Aware Stochastic KV Cache Eviction for Reasoning Models: Technical Analysis
Introduction and Motivation
Efficient inference in LLM-based reasoning models is fundamentally constrained by memory and compute tied to the KV cache, especially during decode-phase generation of extended chains-of-thought. Standard approaches either use sparse selection methods (e.g., SeerAttention-R), which scale linearly in memory, or aggressive KV eviction strategies, which often suffer substantial accuracy degradation on long-form reasoning. This work systematically dissects the failure modes of KV cache eviction, identifying two previously under-explored factors: the criticality of value states with large vector magnitude and the positive role of stochasticity in cache retention. The proposed Value-aware Stochastic Eviction (VaSE) framework integrates these factors to define a training-free approach aligning eviction memory efficiency with selection-method accuracy.
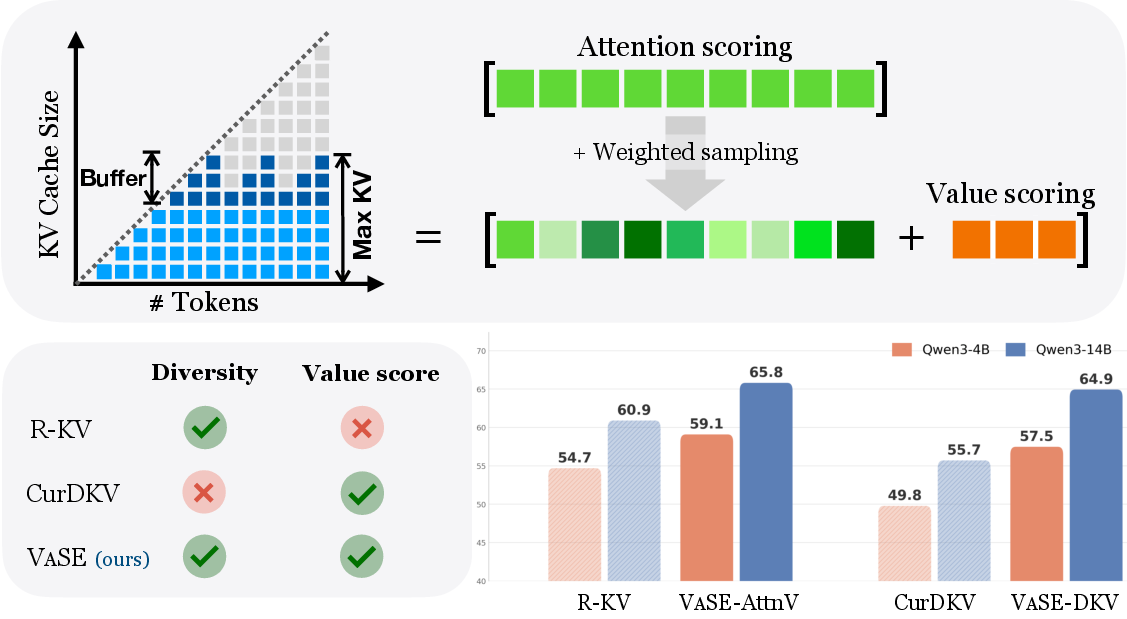
Figure 1: VaSE integrates magnitude-based value-state reservation and stochastic retention, outperforming baseline deterministic strategies and improving pass@1 accuracy under fixed cache budgets.
Technical Contributions
Analysis of Value-State Magnitude Importance
The empirical distribution of value-state magnitudes in Qwen3 architectures is highly skewed; a minority of cached value vectors exhibit extreme L2/Range outliers. Crucially, targeted eviction of these large-magnitude value states precipitates catastrophic model failures—repetitive reasoning loops and output degeneration, confirming the non-interchangeability of cache content.
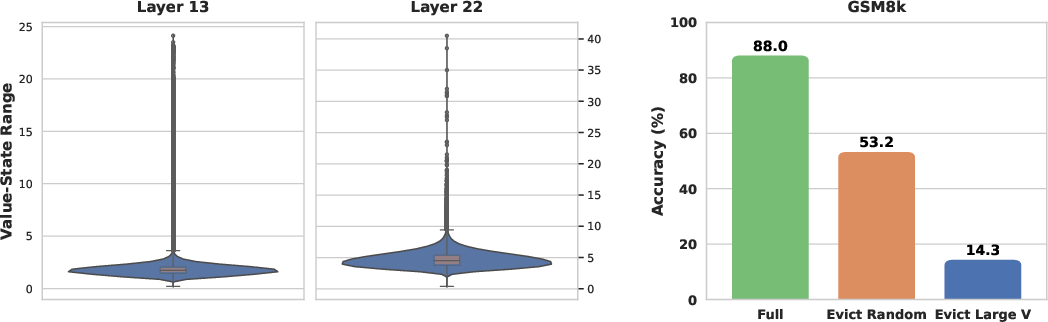
Figure 2: Value-state magnitude exhibits outliers; evicting high-magnitude states collapses accuracy below random eviction performance, confirming their essentiality to correct reasoning.
Ablations confirm that simply reserving entries with top-v magnitude (Range(v) or L2(v)) consistently boosts accuracy versus naïve or attention-only strategies, while stochastic eviction of borderline tokens delays irreversible loss of relevant context.
VaSE Framework and Implementation
VaSE instantiates two axes:
- Value-awareness via explicit reservation of high-magnitude (Range) value states in the persistent cache segment, preventing their accidental eviction. This mechanism generalizes across different norm and statistic choices (see appendix).
- Stochasticity via random sampling (attention-weighted or Gaussian-projection sampling) for selection among non-reserved tokens, which increases diversity and avoids cache homogenization observed in top-k selection-only baselines.
This methodology is realized in two variants:
- VaSE-AttnV: Combines attention-based scoring with stochastic sampling for non-reserved slots.
- VaSE-DKV: Employs stochastic re-sampling of projection matrices in CUR-style scoring, dynamically changing the induced ranking at each eviction step to ameliorate hard-to-recover scoring errors.
VaSE slots naturally into the periodic eviction framework with a fixed-size buffer (B) and persistent budget (K), providing sublinear and bounded memory footprint independent of sequence length.
Experimental Results
Reasoning Task Benchmarks
Comprehensive benchmarks on Qwen3-4B/14B are conducted on six long-form reasoning tasks (AIME, HMMT, GPQA, MATH, LiveCodeBench). At a standard 4× compression ratio (e.g., 2048-token budget for 8K+ output sequences), both VaSE variants outperform prior eviction methods—R-KV, SnapKV, CurDKV—by margins ranging from 4.4% to 9.2% in average pass@1 accuracy. VaSE matches or modestly surpasses SOTA selection method SeerAttention-R, notably with fixed (non-linear) memory cost.
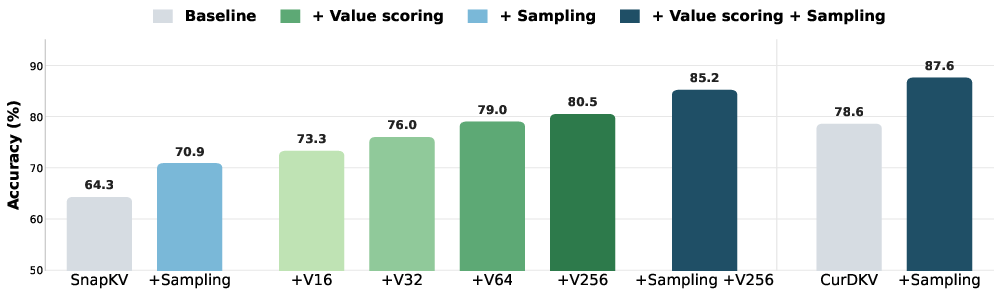
Figure 3: GSM8K case study showing accuracy margin gained via value reservation and stochastic selection.
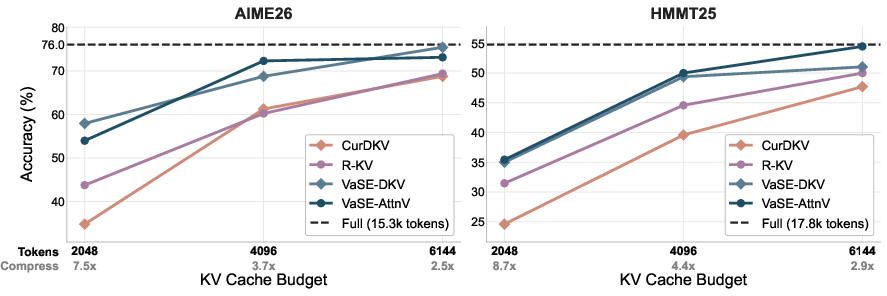
Figure 4: Accuracy across varying KV cache budgets; VaSE outperforms R-KV and deterministic variants, especially under aggressive compression.
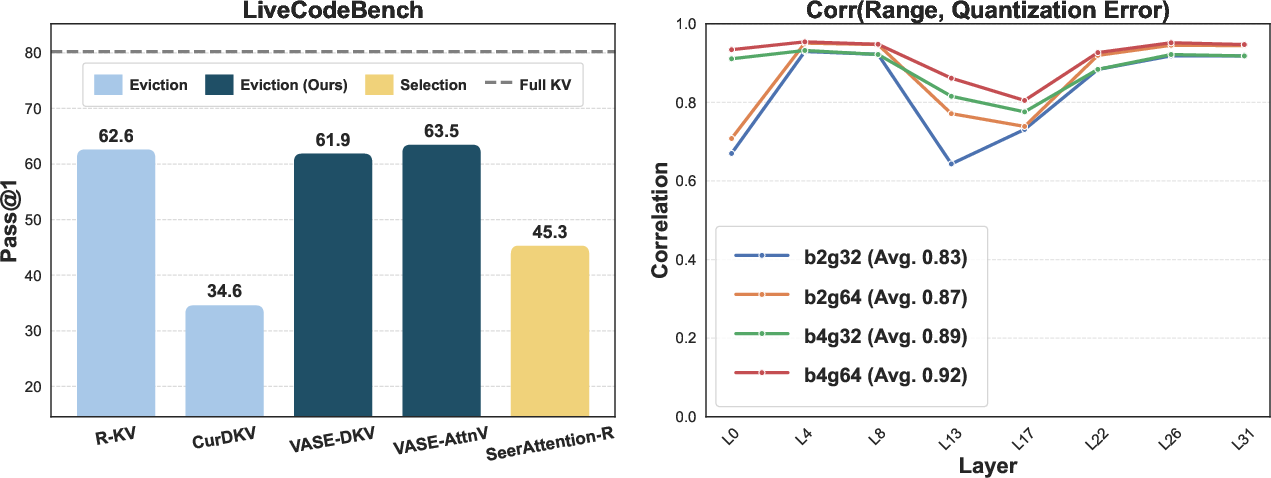
Figure 5: On code generation (LiveCodeBench), VaSE remains competitive and stable, even outperforming selection in domain-shifted settings.
Cache Quantization and Outlier Effects
A direct consequence of the value-magnitude distribution is observed in per-token quantization error: largest-Range value vectors induce disproportionately larger reconstruction errors under fixed-bit quantization, being a critical source of information loss in quantized KV designs.
System Throughput and Memory Profiling
All eviction-based methods, with VaSE being the most efficient, present v0 throughput gains and v1 reduction in memory compared to full KV cache on Qwen3-14B at 16K-32K output length regimes. This enables practical deployment under GPU memory constraints where dense cache is infeasible.
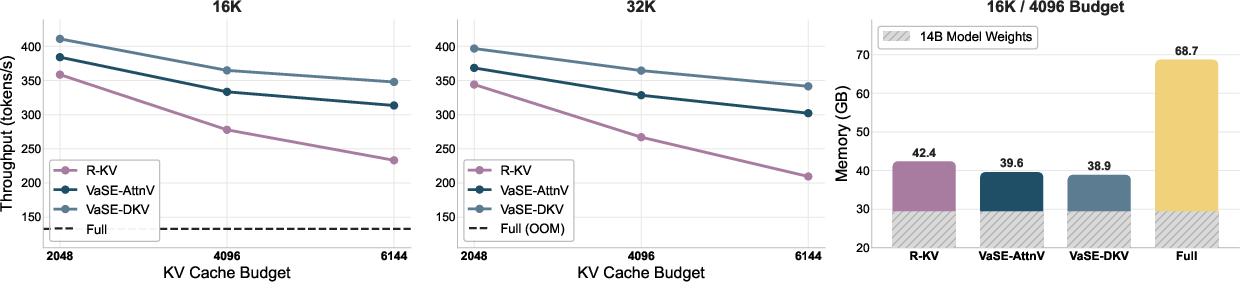
Figure 6: VaSE delivers superior decode throughput and lowest peak memory usage among all techniques, matching theoretical scaling ratios.
Failure Mode and Dynamics Analysis
Evicting outlier value states leads to persistent reasoning failures: models loop on partial thoughts, or sink into degenerate behaviors, never concluding the original task. This suggests large-magnitude values support critical latent-state transitions in multi-step reasoning.

Figure 7: Eviction of large-Range value states induces catastrophic failure: reasoning degenerates into infinite loops or incoherent output.
Distributions of value-state magnitude are stable across sequence length and position (Figure 8), confirming the consistency of the proposed reservation criterion throughout generation.
Broader Implications and Future Directions
VaSE's central insight—that small fractions of high-magnitude value states carry non-redundant, essential reasoning information—motivates future architectures for compressive/incremental reasoning. It also positions mixed-precision quantization plus magnitude-aware cache partitioning as promising lines of investigation for maximizing both efficiency and accuracy in LLM inference.
The use of stochastic retention to promote diversity in retained context elements can generalize to other forms of memory-limited computation or attention selection in LMs. Additionally, the framework highlights avenues for analyzing the interpretability of value-state outliers and their connection to in-context reasoning mechanisms.
Conclusion
VaSE furnishes a statistically-principled, training-free method for KV cache eviction that closes the accuracy-efficiency gap in decode-phase cache management for reasoning models. By integrating value-state magnitude awareness and stochastic diversity promotion, it realizes bounded-memory inference without the accuracy tradeoffs of prior methods. Its general applicability, strong empirical performance, and synergy with further quantization-based compression techniques underscore its value as a foundation for future memory-efficient LM research.

