- The paper introduces the LPCD framework that disentangles invariant malicious intent from volatile tactical packaging in live streaming data for improved OOD detection.
- It employs dual-level counterfactual consistency decoupling and post-hoc calibration, achieving up to a +6% OOD PR-AUC gain on large-scale industrial datasets.
- The approach offers a scalable, plug-and-play solution that outperforms state-of-the-art models while significantly reducing false positive rates under adversarial conditions.
Latent-Predictive Counterfactual Decoupling for Tactical OOD in Live Streaming Risk Assessment
Introduction and Problem Setting
Modern live streaming platforms encounter highly sophisticated adversarial behaviors, where malicious actors—such as fraudsters and promoters of illicit content—perpetually adapt their tactics. Core malicious objectives (e.g., off-platform scam redirection, fraudulent in-platform sales) remain invariant, but adversaries continuously repackage their narratives to evade detection systems. This results in tactical out-of-distribution (OOD) shifts, whereby the observable data distribution is altered in a deliberate, adversarial fashion, while the underlying risk-generating mechanism remains stable.
Traditional OOD generalization frameworks, which often assume exogenous or environment-labeled distribution shifts, struggle in this setting. The crux is a deep semantic entanglement between intent and tactical narrative—a tightly coupled evolution between invariant causal intent and volatile packaging. Raw-level counterfactual interventions are ill-defined due to the multimodal and high-dimensional nature of live sessions. Consequently, there has been little success in deploying robust, intent-focused risk detection at scale.
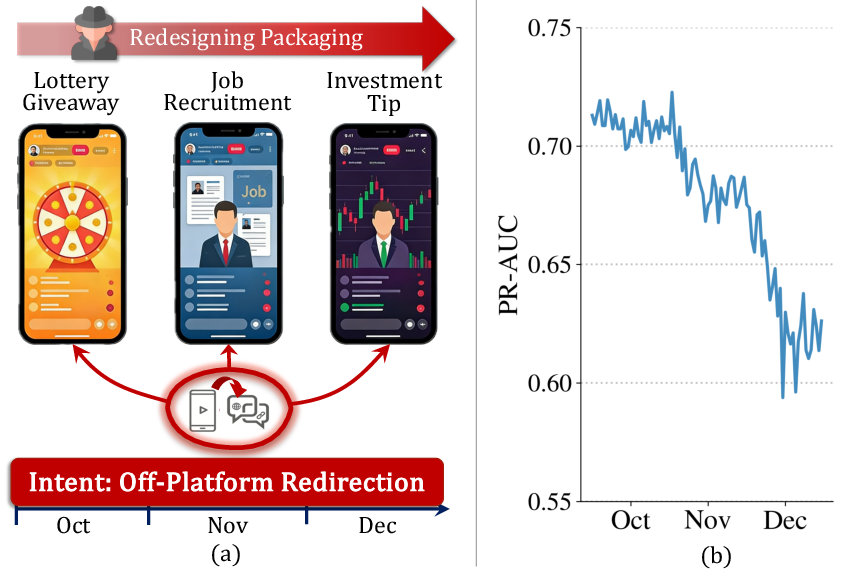
Figure 1: (a) Malicious adversaries maintain invariant intent while continually redesigning tactical narrative packaging. (b) Longitudinal PR-AUC degradation in a production detector due to evolving adversarial tactics.
Methodology: Latent-Predictive Counterfactual Decoupling (LPCD)
Framework Overview
LPCD is a plug-in framework architected for tactical OOD robustness in live streaming risk detection. It enables latent space counterfactual reasoning by disentangling invariant malicious intent from highly volatile tactical packaging. Its training pipeline consists of three stages—latent representation disentanglement, counterfactual consistency decoupling (CCD) at both representation and prediction levels—and a test-time post-hoc magnitude calibration.
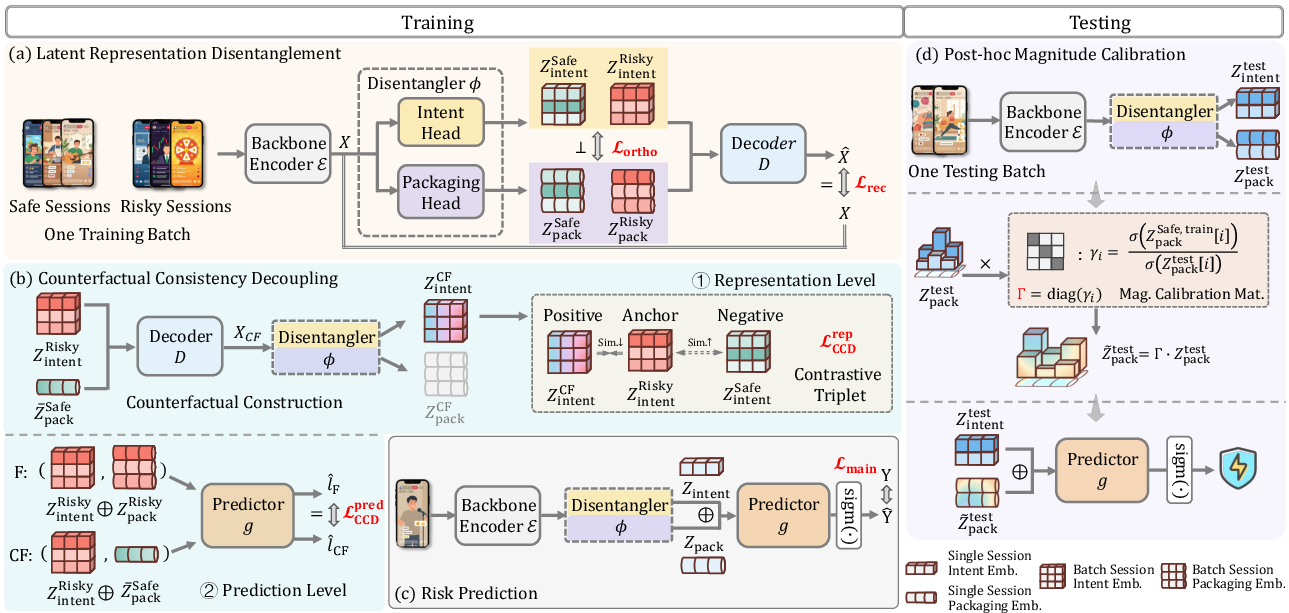
Figure 2: LPCD decomposes session representations into intent and packaging components, enforces intent invariance through counterfactual packaging interventions (CCD), and applies test-time calibration for robust deployment.
Latent Disentanglement
LPCD factorizes a session encoding x into two distinct subspaces:
- zintent: captures causally invariant malicious objectives.
- zpack: encodes variable tactical packaging.
A dual-branch MLP, regularized with a reconstruction loss and soft orthogonality, ensures that the two factors jointly encode sufficient session-level semantics with minimal leakage between them.
Counterfactual Consistency Decoupling
Representation-Level CCD
LPCD synthesizes counterfactual embeddings by maintaining zintent from a risky session while intervening on zpack with the centroid of benign packaging representations. It then enforces a contrastive consistency loss (triplet-style) that anchors the intent representation to its manifold, maintaining separation from benign session intents under packaging interventions.
Prediction-Level CCD
The classifier is regularized to produce invariant outputs when exposed to factual and packaging-counterfactual representations of the same intent. This eliminates the residual shortcut exploitation by the classifier, promoting a decision boundary strictly governed by causal intent.
Post-hoc Magnitude Calibration
At inference, tactical OOD shifts may manifest as magnitude perturbations in the packaging representation. LPCD performs lightweight, parameter-free normalization—aligning each dimension’s RMS to training statistics—ensuring stable operation regardless of adversarial paraphrasing.
Empirical Results
Quantitative Results and Superior OOD Robustness
LPCD was evaluated on two large-scale industrial datasets spanning millions of Douyin live streaming sessions, with both ID and OOD test splits in temporally distant intervals. Compared to state-of-the-art MIL and sequence backbones, as well as various OOD generalization plug-ins (IRM, VREx, GroupDRO, CORAL, EIIL, FOIL), LPCD consistently demonstrated:
- Substantial PR-AUC and F1-score gains (up to +6% OOD PR-AUC vs. best plug-in).
- Significantly reduced FPR at high recall targets—a critical metric for minimizing false alarms.
- Amplified improvements under severe tactical OOD shifts, confirming efficacy at the adversarial front.
Ablation Findings
Ablations established the necessity of both latent disentanglement and dual-level counterfactual intervention. The absence of either module degraded OOD robustness, and post-hoc calibration further provided strong gains (PR-AUC improved from 0.7053 to 0.7287 on June OOD).
Efficiency and Deployment
A fixed LPCD model, trained months prior, matched or outperformed a retraining oracle—at zero retraining cost and reduced inference latency (in part due to running only on disentangled representations). This efficiency is critical for settings constrained by label lag and high-throughput requirements.
Visual Validation
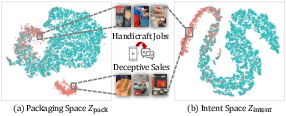
Figure 3: Decoupled representations via t-SNE—packaging space clusters sessions by surface tactic, while intent space collapses sessions sharing underlying malicious objectives.
Sessions with differing surface tactics but common malicious intent are well-separated in packaging space yet tightly clustered in intent space, verifying robust causal separation.
Generality and Online Test
LPCD yielded consistent 6–8% PR-AUC improvements across sequence and MIL families (Transformer, Reformer, TimeMIL, TAIL-MIL). In live A/B deployment, it outperformed incumbent baselines (Transformer, XGBoost) by a significant margin in both precision-recall and false-alarm control.
Implications and Future Directions
LPCD establishes that latent causal disentanglement, augmented by counterfactual reasoning, delivers practical and theoretical advances for OOD risk detection in adversarial, evolving settings. Its architecture is plug-and-play and model-agnostic, opening avenues for broader integration into moderation systems and anomaly detectors beyond live streaming. The approach invites further research in:
- Extending latent counterfactual interventions to additional modalities and interaction types.
- Refining decoupling via advanced disentanglement or better latent counterfactual construction.
- Real-time detection in adversarial domains with minimal or no retraining.
Conclusion
LPCD addresses the fundamental obstacle of tactical OOD in live streaming risk detection by leveraging latent disentanglement and counterfactual consistency. Its superior robustness, operational efficiency, and strong online validation demonstrate a compelling blueprint for deploying causal intent-focused models under adversarial dynamics. The methodology sets a precedent for broader adoption in OOD-mitigation across high-stakes machine learning pipelines.

