- The paper proposes a single-stage audio frontend, MelT, that reformulates Mel-frequency extraction as dense matrix multiplications, achieving significant latency and energy reductions.
- It replaces the conventional STFT+Mel pipeline with a GEMM-native NDFT, aligning computation with modern accelerator capabilities and optimizing performance across diverse hardware.
- Empirical evaluations confirm that MelT maintains competitive classification accuracy while delivering faster inference and lower energy consumption on both edge and datacenter platforms.
MelT: GEMM-Native NDFT for Efficient Single-Stage Audio Frontends on Modern Accelerators
Overview
The paper presents MelT, a single-stage audio frontend framework that leverages dense General Matrix Multiplication (GEMM)-based Non-Uniform Discrete Fourier Transform (NDFT) to directly project acoustic frames into Mel-spaced frequency coordinates. By encoding the Mel-spaced NDFT as dense matrix operations, MelT exploits the architectural strengths of modern deep learning accelerators, such as GPUs and specialized matrix coprocessors, in contrast to the conventional STFT+Mel frontend which aligns computation with FFT rather than GEMM engines. The study empirically demonstrates substantial reductions in inference latency and energy consumption across edge and datacenter hardware, while maintaining practical classification accuracy on benchmark tasks.
Motivation and Methodological Innovations
Contemporary audio models, including for speech recognition and audio event classification, are increasingly deployed on hardware optimized for dense linear algebra. However, the prevailing STFT+Mel frontend pipeline was engineered for computational efficiency on classical CPUs and now creates execution inefficiencies on modern accelerators because it is multi-staged, incurs significant memory movement, and underutilizes matrix multiplication engines.
MelT addresses this by recasting the Mel-frequency spectral projection as a direct NDFT at Mel-spaced frequencies, structured for accelerator execution via GEMM. The proposed pipeline computes the Mel projection for each frame by applying a precomputed basis of sinusoidal functions at nonuniform (Mel) frequencies via matrix multiplication. The representation is extended to cepstral domains (MFCCT) by appending log compression and an orthonormal DCT-II transform, mirroring the MFCC pipeline but with all major operations expressible as dense matrix products.
The established MelT pipeline operates as follows: after standard frame blocking and windowing, each signal frame is projected via explicit dense matmuls to compute, for each of M Mel bins, real and imaginary projections,
Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)
where fm are the Mel-spaced target frequencies obtained through the inverse Mel mapping. The resulting energy matrix S is constructed as St,m=Rt,m2+It,m2. The log-compressed S constitutes the MelT spectrogram, and its DCT-II transform yields the MFCCT cepstral representation. Critically, all major frontend steps are designed as dense GEMM operations, well-suited for high-throughput execution on modern accelerators.
The pipeline design is not an algebraic rearrangement of STFT followed by Mel aggregation, but a distinct projection sequence that omits intermediate linear-frequency spectra and sparse filterbank aggregation, yielding coherent Mel-space projections.
Empirical Evaluation and Results
Latency and Throughput
Comprehensive benchmarking was performed on Apple A18 Pro (edge), Apple M4 Pro (workstation), NVIDIA V100 (legacy datacenter), and NVIDIA H100 (modern datacenter). MelT attains significant reduction in inference latency compared to STFT+Mel, scalable with input duration and maximal for longer contexts. On the Apple A18 Pro, MelT achieves up to 3.75× latency speedup for 160-second utterances. Datacenter GPUs, such as the H100, observe a 1.92× reduction, reflecting backend-specific dispatch and memory dynamics.
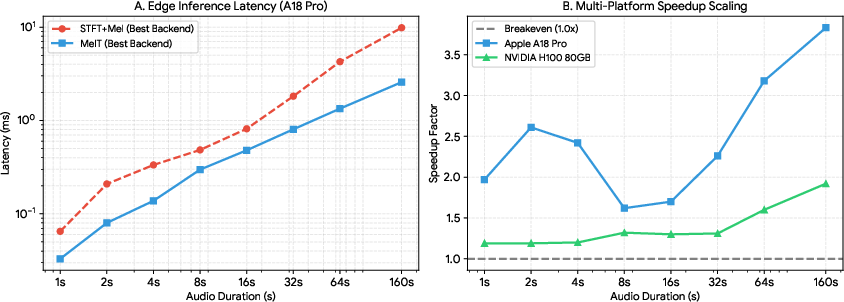
Figure 1: Latency scaling (Panel A) and corresponding speedup (Panel B) for MelT versus the conventional STFT+Mel pipeline, exhibiting consistent acceleration as input duration increases.
Energy Consumption
Energy profiling shows that frontend computation energy reductions can exceed latency gains, primarily when the accelerator's power draw also decreases under MelT. On the NVIDIA H100, MelT reduces median chip-level power demand from 438.1 W (STFT+Mel) to 309.0 W, combining with latency reduction for a 2.74× minimum energy cut. On the A18 Pro, MelT reduces the energy per forward pass by 3.52× due almost entirely to shorter execution time, as power draw remains constant across pipelines.
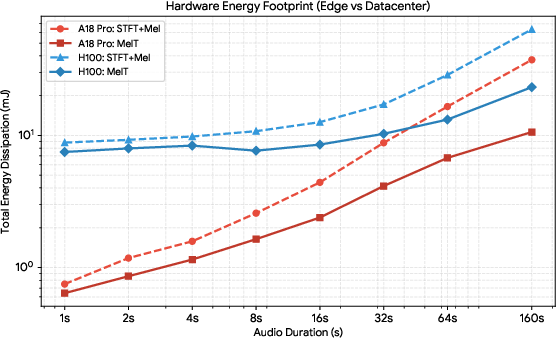
Figure 2: Hardware energy consumption in millijoules over input size, illustrating substantial reductions with MelT compared to the traditional frontend.
The coherence discrepancy between MelT and STFT+Mel (non-equivalence due to ordering of projection and energy computation) does not induce meaningful representation drift in practice: frame-level feature similarity (cosine) remains within Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)0.
On standard downstream tasks:
- VoxCeleb1 gender classification: MFCCT matches standard MFCC accuracy within 0.2% (97.84% vs. 97.95%). Cross-evaluation demonstrates only minor degradation when training on STFT+Mel and evaluating on MelT-based features (88.91% vs. 88.81%).
- SPIRA COVID-19 respiratory classification: MFCCT produces an F1 of 0.9860 vs. MFCC’s 0.9737.
Scaling with Mel Bin Count
Performance gain from MelT is sensitive to Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)1, the number of Mel bins, due to the Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)2 arithmetic pattern. As Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)3 grows large, the speedup diminishes—approaching parity with STFT+Mel at Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)4—but practical configurations (e.g., Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)5 for ASR) retain Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)6 acceleration.
Implications for Hardware-Software Co-Design
A central implication highlighted by this work is that the dominant factor in realized latency and energy efficiency for audio frontends on modern accelerators is shifting from algorithmic FLOP counts to hardware-execution path alignment. By recasting frontend computation as a unified dense matmul (GEMM), MelT aligns processing with accelerator strengths—kernel launch reduction, regular compute patterns, improved cache and memory throughput—enabling substantial practical gains often obscured by asymptotic complexity analysis.
The benefits extend to cepstral representations (MFCCT), indicating that the gains stem from the execution structure, not from specific frontend invariants.
The observed platform- and configuration-dependence of performance gains underscores the necessity for hardware-software co-design when engineering inference-critical frontend pipelines, especially in the context of proliferating matrix-native accelerators in mobile and server environments.
Future Research Directions
Several avenues arise from this work:
- Learnable Mel-Space Projections: While MelT uses fixed Mel spacing, parameterizing the NDFT bases or incorporating learnable frequency positions could be explored for task-specific supervision.
- Generalization to Other Spectral Representations: Extending the GEMM-NDFT pipeline to non-Mel and non-audio domains, including music and non-speech signals, could validate hardware-native benefits universally.
- Hardware-Aware Parameter Optimization: Characterizing the Rt,m=n∑x~t[n]cos(2πfmn/fs),It,m=n∑x~t[n]sin(2πfmn/fs)7-scaling crossover analytically and empirically to aid in frontend parameter selection co-optimized for both accuracy and efficiency.
- Incorporation into End-to-End Systems: Integrating MelT and variants in trainable frontend layers for speech recognition, event detection, or audio self-supervised pretraining for system-level impact quantification.
Conclusion
This study demonstrates that MelT, by reframing Mel-spaced spectral feature extraction as a dense matmul operation, achieves marked reductions in latency and energy consumption relative to conventional pipelines, especially on accelerators where dense linear algebra is preferentially optimized. These advantages persist for common frontend configurations and do not sacrifice downstream classification performance, as evidenced on both speech and clinical tasks. The findings advocate for continued re-examination and redesign of classical signal-processing modules from a hardware-centric standpoint, with clear practical benefits for deep learning inference at scale.