- The paper shows that limited cortical memory forces the model-based learner to adopt distinct strategies (MAXREWARD and MAXREACH) to optimize learning outcomes.
- The study employs simulations in a tree MDP to reveal trade-offs between rapid reward exploitation and quicker adaptation following reward shifts.
- The findings have implications for cognitive neuroscience and AI, suggesting resource-efficient designs that emulate the division of labor between cortex and subcortex.
Distinct Computational Roles of Cortex and Subcortex Under Memory Constraints
Theoretical Framework and Model Design
The paper proposes an explicit computational model that dissects the interaction between cortical (model-based, MB) and subcortical (model-free, MF) learning modules when the memory resources allocated to the cortical system are severely limited. The environment is structured as a tree Markov Decision Process (MDP) with stochastic transitions, where reward is available only at the leaf nodes. Each episode begins at the root, and the agent acts until reaching a terminal state. Critically, the MB learner can only track a fixed number m of transition probabilities P(s′∣s,a), leading to selective memory strategies.
Two distinct strategies are formalized for allocating MB memory:
- MAXREWARD: Prioritizes tracking transitions directly associated with reward, leveraging reward-based learning to maximize immediate exploitation.
- MAXREACH: Allocates memory slots to transitions closest to the root, optimizing reachability of arbitrary goal states and facilitating flexibility when reward locations vary.
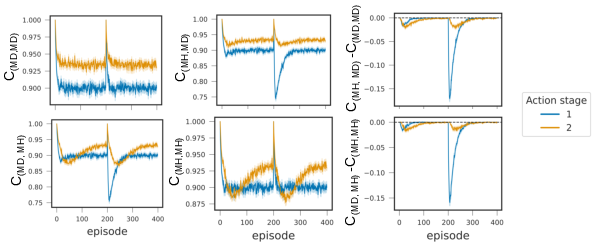
Both MB and MF learners propagate reward signals backward efficiently via SARSA(0)-style updates and policy-evaluation dynamic programming, but MB capacity limits induce fundamentally different behaviors compared to traditional approaches where the MB learner has unconstrained memory.
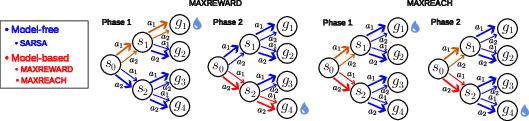
Figure 1: Visualization of a depth-2 tree environment and tracked edges for MAXREWARD and MAXREACH strategies; red arrows represent MB-tracked edges, stroke width encodes estimated probabilities.
Comparative Strategy Analysis and Experimental Results
Through extensive simulation, the study compares learning dynamics of MAXREWARD and MAXREACH under various memory capacities m and tree depths d. The results illustrate that:
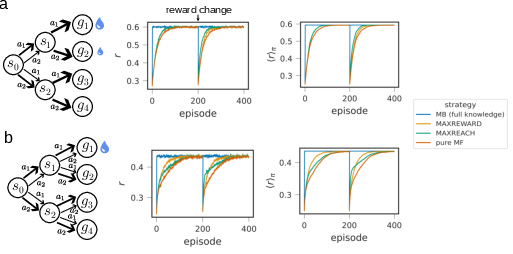
- When m is sufficiently large, both strategies converge and achieve equivalent performance, akin to MB methods with full knowledge.
- With limited m, MAXREWARD excels when reward associations remain stationary, rapidly exploiting known reward branches but performing poorly immediately following reward relocation.
- MAXREACH, by tracking root-near transitions, achieves superior adaptation and initial performance after reward locations change, as the agent can efficiently redirect its policy using pre-learned structural knowledge despite the lack of direct reward associations.
Numerical results are provided for two illustrative cases:
A broader sweep across m and d parameters corroborates the finding that the choice of memory allocation strategy critically depends on environmental reward volatility and structural complexity.
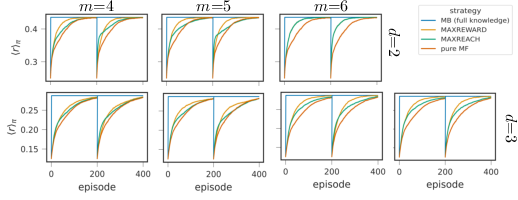
Figure 3: Policy-averaged reward trajectories for MAXREWARD and MAXREACH across varying memory capacities and tree depths, highlighting trade-offs in performance.
Implications for Cognitive Neuroscience and Artificial Intelligence
The computational dissociation observed aligns with neuroanatomical and neurophysiological findings: cortex (MB) exhibits sparse dopaminergic innervation and is theorized to construct generalized environmental models independent of immediate reward, while subcortical structures (striatum/MF) rely heavily on reward signals for learning. This model provides a mechanistic explanation for why cortex is responsible for structural learning, enabling rapid adaptation in nonstationary environments, whereas subcortex specializes in incremental reward-based learning.
Such a division of labor has practical implications for reinforcement learning in AI:
Theoretical Extensions and Limitations
The model opens several avenues for extension:
- Parametric models and compression (e.g., Successor Representation, low-dimensional embeddings) may scale these findings to complex environments, but require careful treatment of MF–MB coupling.
- More nuanced hybrid strategies (e.g., a transient "hot cache" combining exploitation and structure) may better reflect biological and practical learning systems.
- Explicit costs for MB computation could model habitual handover from cortex to subcortex (as seen in motor skill acquisition).
The paper acknowledges limitations, notably simplified environments, tabular algorithmic approaches, and the assumption that untracked transition probabilities are assigned to zero-reward states.
Conclusion
This study formalizes and analyzes how limited cortical (model-based) memory induces distinct strategies for information allocation, leading to practical and theoretical dissociations between cortical and subcortical learning. By demonstrating strong numerical trade-offs between exploitation and flexibility under memory constraints, the work provides a foundation for modeling animal and human learning, and inspires future designs of efficient, adaptive AI systems that mirror the division of labor observed in biological brains.