- The paper introduces a compiler-driven affine scan lowering technique that converts sequential affine recurrences into parallel Blelloch scan schedules.
- It leverages MLIR for systematic IR transformation and demonstrates latency reduction from 51.7 ms to 0.032 ms at a sequence length of 1024.
- The approach generalizes to diverse recurrence-based computations while highlighting numerical stability challenges with aggressive exponential parameterizations.
ScanWeaver: Compiler-Driven Parallelization of Affine Recurrences via Associative Scan Lowering
Motivation and Affine Scan Abstraction
Sequential recurrences, pervasive in state-space models (SSMs), dynamic programming, and recurrent neural networks (RNNs), significantly impede parallel execution on modern accelerators due to their inherent step-wise dependencies. Recent advances like Mamba foreground input-dependent selective scan recurrences (ht=atht−1+btxt), retaining linear-time traversal but imposing strict sequential constraints.
ScanWeaver addresses this by reframing recurrence computation as an associative affine scan, which decomposes sequential recurrences into compositions of affine transition pairs: (At,Ut)=(at,btxt). Associative composition, (A2,U2)⊕(A1,U1)=(A2A1,A2U1+U2), facilitates prefix scan evaluation and exposes parallel structure amenable to scan algorithms.
(Figure 1)
Figure 1: Affine scan reformulates sequential recurrence traversal into a parallel prefix schedule over sequence dimension L.
This conversion enables systematic compiler-driven lowering, turning what is nominally O(L) dependency depth into O(logL) via Blelloch scan schedules, radically increasing parallel execution throughput on GPU architectures.
MLIR-Based Lowering Pipeline
ScanWeaver leverages MLIR's flexible IR stacking to instantiate affine scan as a compiler abstraction, supporting decomposition, scan lowering, and explicit execution mapping. The pipeline progresses from high-level recurrence IR through:
- Affine normalization
- Associative scan decomposition
- Explicit Blelloch scan schedule materialization (upsweep, root init, downsweep)
- MLIR GPU lowering
- Artifact generation and execution on CUDA GPU
The affine scan abstraction decouples recurrence logic from realization schedules, enabling principled reuse across operator classes and generalization beyond selective scan, such as weighted prefix recurrences.
Implementation and Execution Strategies
ScanWeaver supports multiple execution paths:
- PyTorch sequential reference
- Naive CUDA recurrence traversal
- Compiler-generated MLIR GPU Blelloch scan
- Parallel CUDA Blelloch scan backend
By staging affine transition pairs in shared memory and mapping sequence dimension L across scan trees, ScanWeaver achieves substantial reduction in sequential bottlenecks. The Blelloch scan reflects a logarithmic dependency structure, supplanting strictly sequential traversal with hierarchical parallel composition.
Numerical Results and Latency Scaling
ScanWeaver’s compiled Blelloch scan backend demonstrates markedly superior latency profile compared to both PyTorch sequential reference and naive CUDA implementations across increasing sequence lengths. At L=1024, measured latency is $0.032$ ms for ScanWeaver Blelloch, in stark contrast to $0.469$ ms (naive CUDA) and (At,Ut)=(at,btxt)0 ms (PyTorch).
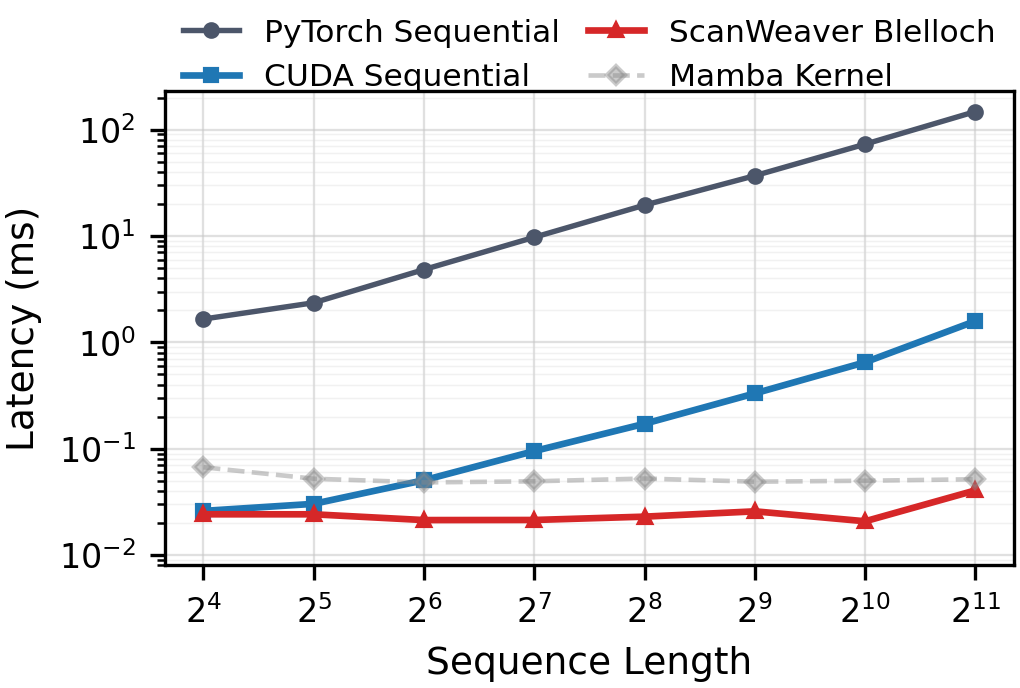
Figure 2: Latency scaling across sequence lengths; ScanWeaver Blelloch backend exhibits flatter scaling than sequential traversal due to logarithmic-depth parallel prefix scheduling.
This demonstrates concrete improvement in realized parallelism, with overhead attributable primarily to GPU synchronization and launch costs rather than arithmetic computation.
Generalization, Numerical Stability, and Systems Implications
ScanWeaver’s affine scan transformation is not limited to Mamba-like selective scan but generalizes to any affine recurrence that admits prefix composition. This abstraction enables compiler systematically to recover parallel execution for a broad set of recurrent ML workloads.
Implementation correctness holds across tested ranges of parameters, but aggressive exponential parameterization induces numerical instability—magnifying floating-point discrepancies and warranting separate characterization.
The compiler-centric approach of ScanWeaver challenges the necessity of bespoke kernel engineering for every operator, offering the potential for unified recurrence parallelization in future ML stacks, with further extensibility toward alternative scan schedules and distributed execution.
Comparison with Production Kernels and Limitations
While operator-specialized kernels (e.g., Mamba’s fused CUDA kernel) deliver high performance via hand-tuned memory access and fusion, ScanWeaver focuses on generalized compiler lowering and structural parallelization. The primary aim is not strict outperformance but rather to demonstrate that compilation-driven affine scan abstraction is viable and portable.
Notable limitations include instability under exponential parameters, restriction to Blelloch schedules, exclusion of gating/reset mechanisms, and absence of distributed/multi-GPU execution strategies.
Conclusion
ScanWeaver elevates affine scan to a compiler primitive, enabling systematic transformation and parallelization of recurrence-based computations via associative scan lowering and MLIR-driven GPU execution. The numerical results validate substantial reductions in latency, especially for long sequence traversals. This lays groundwork for universal recurrence parallelization schemes in ML compiler stacks, with implications for advancing both performance portability and structured IR lowering in accelerator-centric workloads.