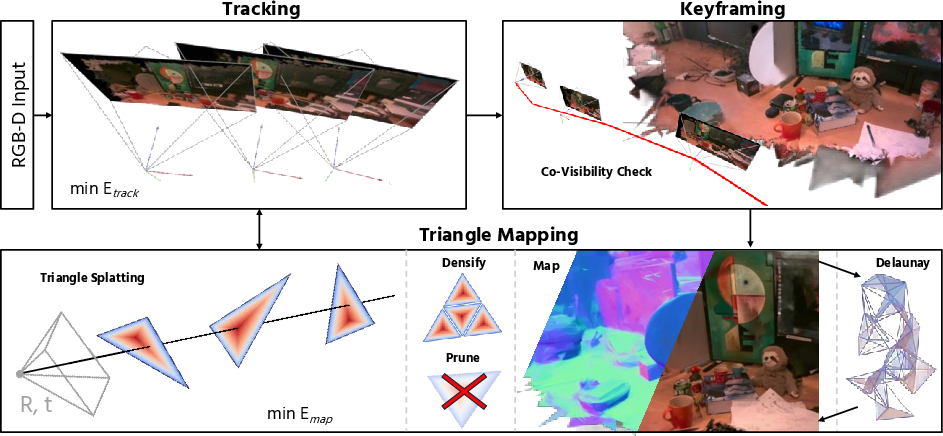
Triangle Splatting SLAM
Abstract: We present a dense RGB-D SLAM system using differentiable triangles as the 3D map representation. While 3D Gaussian Splatting has emerged as the leading method for novel-view synthesis, triangles remain the standard primitive for traditional rendering hardware, game engines, and downstream tasks requiring explicit geometry such as simulation, collision, and editing. Recent offline methods have demonstrated that an unstructured 'triangle soup' can be optimised into a photorealistic mesh via Delaunay triangulation across a set of posed images. Building upon this insight, we present the first dense SLAM system to employ Triangle Splatting to perform both tracking and mapping through online differentiable rendering of a triangle soup. The map can be converted into a connected mesh on-the-fly via restricted Delaunay triangulation, enabling new online capabilities such as mesh deformation and collision checking. On Replica and TUM-RGBD, our system outperforms baselines on 3D geometry, matches the camera-tracking accuracy, and enables online mesh-based scene editing.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way for a computer to build a detailed 3D map of a place while moving through it with a camera. The method is called Triangle Splatting SLAM. It represents the world using many tiny triangles (like in video games), so the system can both look realistic and create a clean, connected 3D mesh that other tools (like physics engines or game editors) can use right away.
The big questions the authors asked
- Can we use triangles—the standard building blocks in computer graphics—as the main 3D map for SLAM, not just as an extra step at the end?
- Can this triangle-based map be updated live as the camera moves, staying photorealistic and geometrically accurate?
- Can we turn the triangle map into a connected mesh on the fly (in real time) for tasks like editing and collision checking?
- How does this approach compare to popular alternatives (like “Gaussian Splatting”) in terms of camera accuracy and 3D quality?
How does their system work?
SLAM in simple terms
SLAM stands for Simultaneous Localization and Mapping:
- Localization: figuring out where the camera is and which way it’s pointing.
- Mapping: building a 3D model of the world.
This paper uses an RGB-D camera, which gives both color (RGB) and depth (D). Think of depth as how far away each pixel is.
Why triangles?
Triangles are the standard in graphics (games, animation) because:
- They render very fast on GPUs.
- They describe surfaces explicitly (great for measuring, collisions, and editing).
- They connect into meshes that are easy to edit and simulate.
Many recent SLAM methods use “blobs” or volumes that look good but don’t directly give a clean, connected surface. This work uses triangles from the start, so the system always knows the actual surface.
From pictures to triangles: “differentiable rendering”
Imagine the system has a big pile of tiny, semi-transparent triangles. If you look at them from the camera’s point of view, you can “render” what the camera should see. Differentiable rendering means the computer can gently tweak triangle positions, colors, and opacities to make the rendered image match the real photo better—like adjusting puzzle pieces until the picture lines up.
Key ideas they use:
- Each triangle inherits color and transparency from its three corner points (vertices), and these blend smoothly across the triangle.
- They make the rendering process “smooth” so the computer can compute how to nudge triangles in the right direction.
- They sort triangles by depth and blend them, a bit like stacking lightly transparent stickers to build the final image.
Tracking the camera
To know where the camera is, they:
- Render the scene from a guessed camera pose.
- Compare the rendered image to the real photo (using simple differences and a visual similarity score called SSIM).
- Also compare the rendered depth to the camera’s depth image.
- Use math to quickly adjust the camera pose so the render and the real image line up. They speed this up with a custom, exact gradient (an “analytic Jacobian”), which saves time.
Building and cleaning the map
When the system decides a frame is important (a “keyframe”), it:
- Adds new triangles based on the RGB-D data. Each new triangle starts near a measured 3D point and faces the right way using surface normals (directions estimated from depth).
- Regularizes triangle shape so they don’t become skinny or weirdly stretched (it nudges angles toward an even 60°—roughly equilateral).
- Splits triangles that look blurry in the image into smaller ones to add detail (like zooming in where needed).
- Prunes triangles that are too big, too uncertain, or nearly invisible.
During mapping, it keeps re-rendering from recent keyframes and adjusts both the map and those keyframe camera poses to fit the images and depth better.
Making a connected mesh on the fly
At any time, the triangle “soup” (a set of triangles without guaranteed clean connections) can be turned into a connected, well-formed mesh using a technique called Delaunay triangulation. You can think of it as a smart way to connect nearby points into a tidy triangle network. This lets the system:
- Check collisions (e.g., “does a robot hit this wall?”)
- Deform or edit surfaces live (move a handle, bend a surface)
- Export to tools and engines that expect standard meshes
What did they find?
- Camera tracking accuracy: Their method matches strong baselines on two well-known datasets (TUM RGB-D and Replica). In plain terms, it locates the camera about as accurately as leading systems.
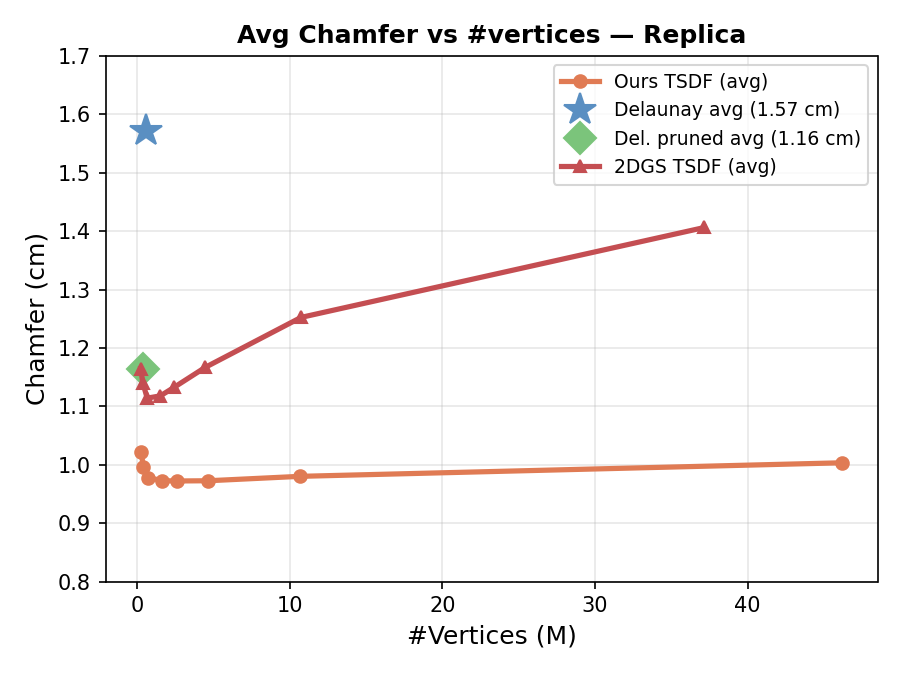
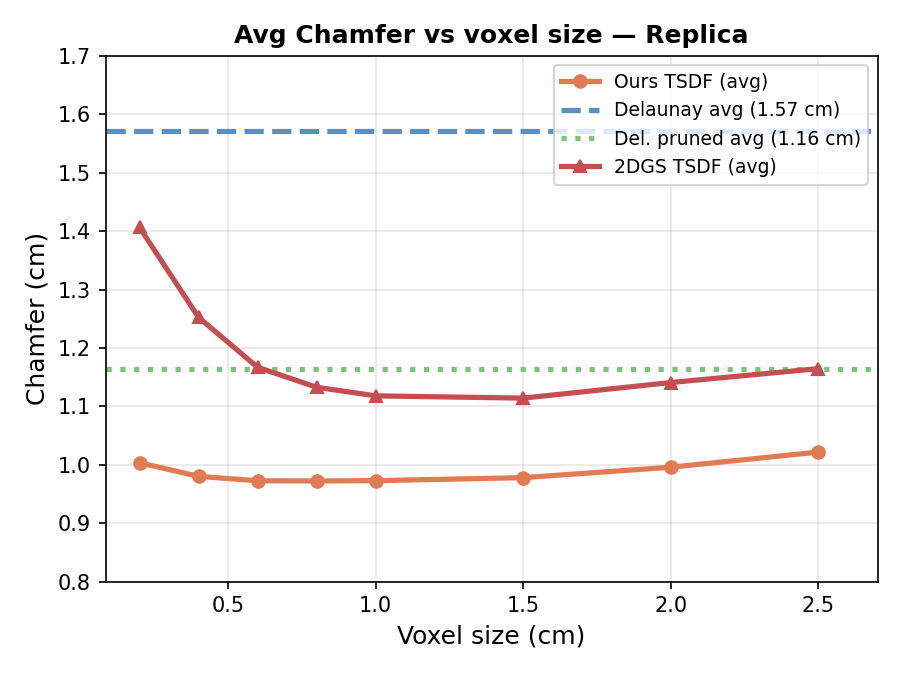
- 3D geometry quality: Their triangles produce more accurate surfaces than popular alternatives that need extra post-processing. Measured by how close the reconstructed surface is to ground truth (Chamfer distance), their approach is better.
- Mesh generation speed and quality:
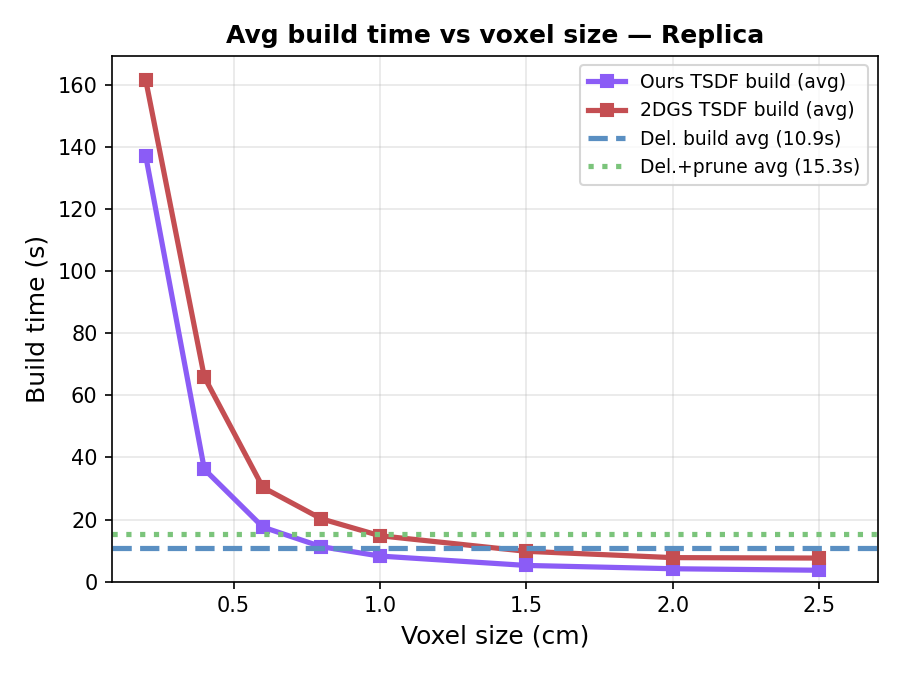
- Turning their depth maps into a mesh with TSDF fusion gives the best geometric accuracy, but takes longer.
- Using Delaunay triangulation directly on their triangles is about 2–3× faster while still very accurate—good for quick, on-the-fly mesh creation.
- Live editing: Because they’re already using triangles, they can enable online mesh editing and collision checking during mapping—something that’s hard with volumetric or blob-like methods.
In short: similar camera accuracy, better 3D surfaces, and meshes that are ready to use immediately.
Why this matters
- For robots and AR/VR, you don’t just want pretty pictures—you need a trustworthy, connected surface to plan paths, detect collisions, and edit scenes. This method provides that directly.
- It blends the best of both worlds: fast, photorealistic rendering and practical, editable geometry.
- It opens the door to interactive applications like live scene editing, simulation, and “digital twins” where a live 3D model is kept up to date as you move around.
A few simple definitions
- SLAM: Build a map while figuring out where you are in it.
- RGB-D camera: Captures color and distance for each pixel.
- Differentiable rendering: Rendering that tells you how to adjust the 3D model to better match a photo.
- Mesh: A connected set of triangles forming a surface.
- Delaunay triangulation: A method to connect points into triangles that avoids skinny, unstable shapes.
- TSDF fusion: A way to merge many depth images into a smooth 3D surface.
- Chamfer distance: A score of how close two 3D shapes are (lower is better).
Final takeaway
Triangle Splatting SLAM shows that you can use triangles—the language of modern graphics cards and game engines—as the main map in a live SLAM system. It keeps camera tracking accurate, improves 3D surface quality, lets you create connected meshes on demand, and supports real-time editing. This makes it especially useful for robotics, AR, and any application where you need both a good-looking scene and a reliable, editable 3D model.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored in the paper, framed as concrete and actionable directions for future research:
- No loop closure or global consistency: the system operates “w/o” loop closure in evaluations; investigate mesh-aware loop-closure, global pose graph optimization, and map deformation (e.g., deformation graphs) to prevent long-term drift and accumulated topological errors.
- Limited real-time performance: current throughput is 0.55–2.33 FPS with high latencies (up to ~1.8 s per frame); identify and eliminate bottlenecks (e.g., per-frame depth sorting of faces, Python overhead, sequential tracking/mapping), introduce multi-threaded pipelines and CUDA kernel fusion to approach 30 FPS hard real-time.
- Scalability to large scenes is untested: largest reported map is ~152k triangles; evaluate performance and memory when scaling to millions of triangles and longer trajectories, including spatial partitioning (BVH, k-d trees, grids), frustum culling, and out-of-core data management.
- No dynamic-scene handling: the method assumes static scenes; extend to detect, segment, and handle moving objects (e.g., dynamic triangle soups, object-level tracking, or layered maps) while maintaining mesh integrity.
- Reliance on RGB-D depth supervision: performance without depth (monocular RGB) is not assessed; experimentally evaluate monocular-only operation with priors (depth/normal priors, learned geometry) and quantify scale consistency and failure modes.
- Appearance model is simplistic: per-vertex RGB and global σ omit view-dependent appearance, shading, exposure/white-balance, and lighting changes; explore per-face/vertex SH, learned appearance features, photometric calibration, and robustness to illumination variability.
- Depth/occlusion rendering assumptions: alpha compositing with depth-sorted faces may be brittle for intersecting geometry and transparency ordering; assess differentiable z-buffering, order-independent transparency, or soft visibility to improve occlusion correctness and gradient stability.
- Mesh quality/topology not characterized: beyond Chamfer, there is no quantitative evaluation of manifoldness, self-intersections, watertightness, or non-manifold edge counts; add topology metrics and collision-safety checks, and incorporate constraints to enforce manifoldness online.
- Online Delaunay meshing overhead and robustness: on-the-fly restricted Delaunay costs 9–16 s per scene; study incremental/streaming triangulation algorithms, parallelization, and failure cases (sliver tetrahedra, cross-surface connections) for frequent updates and larger scenes.
- Triangle initialization strategy may bias geometry: equilateral triangles around back-projected points with radius from nearest neighbors is heuristic; compare against uncertainty/texture-driven sampling, anisotropic triangle seeds aligned with local curvature, and multi-scale initialization.
- Equilateral regularization trade-offs unquantified: penalizing non-equilateral angles could oversmooth fine features; perform ablations on λ_equi and shape statistics to quantify impact on thin structures and high-curvature surfaces.
- Vertex sharing vs. independence not studied: the choice to avoid shared vertices during the triangle soup phase is motivated qualitatively; run controlled ablations comparing shared-vertex soups vs. independent vertices for convergence speed, stability, and final mesh quality.
- Parameter sensitivity not explored: key thresholds (opacity ε_o, projected area ε_a, blur threshold θ_blur, σ in the window function) lack sensitivity analyses; map performance across ranges and propose adaptive/learned schedules per-scene or per-region.
- Analytic gradients limited to pose: only pose Jacobians are derived analytically; investigate analytic or fused-kernel gradients for vertex positions, colors, and opacities to accelerate mapping and reduce autodiff overhead.
- Depth computation definition and consistency: the paper does not detail how depth is derived under alpha blending and multi-triangle intersections; formalize the depth estimator, its gradients, and test consistency with the mesh extracted by Delaunay to avoid rendering–geometry mismatches.
- Normal supervision from raw depth may be noisy: normals from finite differences on depth can be unreliable; evaluate robust normal estimation (confidence-weighted normals, joint bilateral filtering, learned normal predictors), and down-weight uncertain normals during optimization.
- Keyframe selection via triangle IoU needs validation: IoU of rendered triangles may be sensitive to transient geometry or pruning; compare against coverage- and information-gain-based criteria and analyze the impact on convergence and tracking stability.
- Editing–mapping interplay is unclear: online mesh edits are demonstrated, but it is not shown how edits feed back into the triangle soup optimization and tracking without destabilization; design and evaluate a consistent edit–optimize loop with topology/appearance constraints.
- Dependence on TSDF for best Chamfer: the lowest Chamfer is achieved after TSDF fusion of the method’s depth, implying the soup/mesh pipeline alone underperforms; investigate training objectives and visibility losses to close the gap without resorting to a secondary volumetric representation.
- Robustness to sensor imperfections is not assessed: evaluate sensitivity to depth noise, missing depth frames, rolling shutter, miscalibration (intrinsic/extrinsic), and auto-exposure; add online calibration and robust losses (e.g., Tukey, Charbonnier) and depth-confidence weighting.
- Backface handling and normal orientation unspecified: the rasterizer setup (backface culling, two-sided rendering) and triangle orientation consistency are not detailed; study their effects on stability and introduce orientation regularizers or visibility-aware normal constraints.
- Limited benchmarks and metrics: experiments are confined to TUM and Replica (indoor, mostly static); test on larger, more diverse, and dynamic datasets, and add metrics like normal error, completeness, F-score, topological validity, and per-region error (thin structures, specular/transparent surfaces).
- No ablation studies: the paper lacks ablations for the proposed design choices (average vs. min opacity, equilateral loss, densification policy, pruning thresholds, analytic pose Jacobians); provide systematic ablations to isolate contributions and guide hyperparameter selection.
- Spatial data structures absent: per-frame face sorting and naive visibility tests may not scale; investigate GPU-accelerated spatial indices (tiled rasterization, per-tile bins, BVHs) to reduce sorting, overdraw, and memory bandwidth.
- Integration with learned priors: while suggested in future work, the paper does not test depth/normal priors or transformer-based geometric priors; quantify gains from integrating learned priors in low-texture or reflective regions under real-time constraints.
- Evaluation of collision fidelity and physics readiness: the claimed benefit for simulation and collision is qualitatively shown; add quantitative tests (contact accuracy, penetration depth errors, collision response stability) compared to ground-truth meshes.
- Relocalization after tracking loss is unspecified: handling of tracking failure or global relocalization is not addressed; integrate and benchmark relocalization (e.g., retrieval-based, PnP with soup features) under viewpoint and illumination changes.
- Multi-sensor extensions unaddressed: fusion with LiDAR, stereo, or event cameras is not explored; define differentiable fusion strategies at the triangle level and measure improvements in textureless areas and at depth discontinuities.
- Memory growth control and compression: while model size is low in reported cases, long sessions will grow; implement online decimation, edge collapses, and triangle-soup compression (e.g., diffsoup-style pruning) with guarantees on photometric and geometric error.
Practical Applications
Practical Applications of Triangle Splatting SLAM
Triangle Splatting SLAM introduces a unified, triangle-based 3D map for RGB-D SLAM that supports differentiable rendering, online Delaunay meshing, and mesh-based editing/collision in the loop. It achieves competitive pose tracking with superior 3D geometry versus 3D/2D Gaussian SLAM, while outputting connected meshes in seconds. Below are actionable applications and workflows that build on these capabilities.
Immediate Applications
The following can be deployed today on RGB-D sensors (e.g., Intel RealSense, Azure Kinect) with a CUDA-capable GPU, mainly in static, indoor environments.
- Bold AR occlusion and physics in game engines
- Sectors: software, gaming/AR, education
- What: Stream on-the-fly connected meshes into Unity/Unreal for correct occlusion, lighting, and real-time collision during AR experiences or mixed-reality demos.
- Tools/workflows: “Triangle-SLAM Live Mesh” plugin (Unity/Unreal); live Delaunay meshing for occlusion + collision; TSDF-based mesh for high-fidelity offline renders.
- Assumptions/dependencies: RGB-D input; CUDA GPU; mostly static scenes; current framerate ~0.5–2.3 FPS; no loop closure in the provided system.
- Robot motion planning and collision checking from live geometry
- Sectors: robotics, manufacturing, logistics
- What: Use the connected mesh for online collision checking, local path planning, and manipulation planning in labs/cells.
- Tools/workflows: ROS2 node publishing /mesh and /tf; mesh → FCL/Bullet/PhysX collision backends; “no-go” zones created by online mesh editing.
- Assumptions/dependencies: Static or slowly changing scenes; low-latency planning requires downsampled meshes or planning at lower cadence; accurate camera calibration; RGB-D reliability.
- Rapid digital twin bootstrapping with adjustable quality–speed trade-offs
- Sectors: AEC (architecture, engineering, construction), facilities, digital twins, real estate
- What: Produce meshes within 10–16 s via (pruned) restricted Delaunay for quick turnarounds; optionally refine via TSDF fusion (~33 s) for highest geometric accuracy.
- Tools/workflows: Two-stage extraction: Delaunay for fast iterations → TSDF for final delivery; exporters to glTF/OBJ/PLY.
- Assumptions/dependencies: Indoor, static; sufficient texture/depth quality; small-to-medium spaces (tens to hundreds of thousands of triangles).
- Collaborative design and layout via live mesh-based scene editing
- Sectors: AEC, industrial design, retail staging
- What: Deform or edit the connected mesh during capture to test layouts (e.g., furniture repositioning), check clearances, and simulate line-of-sight.
- Tools/workflows: Live “edit-in-the-loop” UI; export edited meshes to CAD/BIM; mesh-based distance and clearance checks.
- Assumptions/dependencies: Edits reflect geometry, not semantics; mesh manifoldness not guaranteed; accuracy depends on sensor depth and coverage.
- Fast physics-ready scene initialization for simulation
- Sectors: robotics simulation, digital content creation
- What: Use pruned Delaunay meshes to quickly initialize physically interactive environments for Gazebo, Isaac Sim, or game engines; refine later if needed.
- Tools/workflows: Automated mesh collider generation; per-room segmentation from frame covisibility.
- Assumptions/dependencies: May require watertightness or cleanup for certain engines; dynamic objects not explicitly modeled.
- Asset digitization for e-commerce and virtual staging
- Sectors: e-commerce, media/entertainment, real estate
- What: Capture small objects or room-scale assets with photorealistic textures and consistent geometry suitable for rapid turnarounds.
- Tools/workflows: RGB-D turntable capture or walk-through; pruned Delaunay for speed; TSDF for final catalogue quality.
- Assumptions/dependencies: Limited specular/transparent materials; thin structures are handled better than many TSDF-only methods but still benefit from careful scanning.
- Education and research baseline for differentiable rendering and SLAM
- Sectors: academia, training
- What: Use the open-source pipeline to teach/benchmark differentiable rasterization, analytic pose Jacobians, and SLAM front/back-ends.
- Tools/workflows: Course labs with Replica/TUM RGB-D; ablation on equilateral regularization, densification, and pruning; benchmarking geometry vs. ATE.
- Assumptions/dependencies: GPU-equipped lab machines; familiarity with CUDA/PyTorch.
- Facility mapping and AR wayfinding pilots
- Sectors: healthcare, corporate campuses, museums
- What: Build geometry-accurate indoor maps to support occlusion-aware AR wayfinding and safety-awareness demos (e.g., avoiding obstacles).
- Tools/workflows: Pre-scan building segments to generate meshes; deploy AR overlays using engine plugins; periodic re-scans to update geometry.
- Assumptions/dependencies: Static layouts; privacy-safe capture policies; device–server synchronization for mesh streaming.
Long-Term Applications
These require further research, scaling, or engineering (e.g., 30 FPS, monocular support, dynamic scenes, manifold guarantees).
- Real-time mobile AR mapping (30+ FPS) on edge devices
- Sectors: consumer AR, wearables
- What: On-device triangle-based mapping for AR glasses/phones to enable persistent occlusion, physics, and scene editing in real time.
- Tools/workflows: Vulkan/Metal GPU backends; multiprocessing; conjugate-gradient solvers; CUDA/Vulkan optimizations; streaming triangle soups.
- Assumptions/dependencies: Significant performance engineering; power/thermal constraints; platform GPU API support.
- Monocular, outdoor, and dynamic-scene SLAM with learned priors
- Sectors: robotics, autonomous systems, AR
- What: Extend to RGB-only and outdoor conditions with priors for depth/pose; handle moving objects with motion segmentation and topology updates.
- Tools/workflows: Depth/normal priors (e.g., monocular networks), learned regularizers; dynamic object masks; robust photometric losses.
- Assumptions/dependencies: Model generalization; increased compute; robustness to lighting/weather; regulatory constraints for outdoor capture.
- Manifold, watertight meshes ready for CAD/BIM and fabrication
- Sectors: AEC, manufacturing, 3D printing
- What: Enforce manifoldness/self-intersection constraints during optimization to output CAD-grade geometry suitable for rigging and fabrication.
- Tools/workflows: Differentiable manifold constraints; post-process repair integrated in the loop; mesh→BIM alignment tools.
- Assumptions/dependencies: New losses/constraints; potential trade-off with photorealism; tactile tolerances for fabrication.
- Semantic–geometric scene understanding for task planning
- Sectors: robotics, smart buildings, retail analytics
- What: Fuse per-vertex semantic labels with the connected mesh for higher-level reasoning (e.g., “plan around tables,” “inspect shelves”).
- Tools/workflows: Semantic segmentation heads; per-vertex/face features; planners using semantic collision layers.
- Assumptions/dependencies: Training data; robust semantics under occlusion; domain adaptation.
- Multi-agent collaborative mapping and shared digital twins
- Sectors: industry 4.0, construction monitoring, events/venues
- What: Multiple RGB-D agents stream triangle soups; server-side restricted Delaunay merges and reconciles connectivity for a unified mesh.
- Tools/workflows: Shared coordinate frames; mesh merge/conflict resolution; bandwidth-aware streaming (triangle soup compression).
- Assumptions/dependencies: Networking and synchronization; privacy and access control; loop-closure and drift correction at scale.
- Continuous, editable digital twins for operations and maintenance
- Sectors: energy, utilities, facility management
- What: Keep a live, editable twin that supports deformation-based “what-if” analyses (e.g., retrofits), collision-aware robot deployments, and safety checks.
- Tools/workflows: Scheduled re-scans; change detection; mesh versioning; integration with CMMS/BIM systems.
- Assumptions/dependencies: Governance over updates; persistent IDs for elements; acceptance of geometric uncertainty bounds.
- Compression and streaming for web-scale 3D experiences
- Sectors: content delivery, metaverse/web3D
- What: Extreme triangle soup simplification (as hinted by recent differentiable triangle work) to stream photorealistic scenes to browsers/clients.
- Tools/workflows: Progressive refinement; adaptive densification on client; web GPU pipelines (WebGPU).
- Assumptions/dependencies: Standardized formats; client GPU capabilities; balance between compression and fidelity.
- Policy and standards for privacy-preserving spatial computing
- Sectors: policy/regulation, public sector, healthcare
- What: Inform standards for on-device processing, selective redaction (e.g., faces/screens), and safe sharing of meshes rather than raw RGB-D.
- Tools/workflows: On-device meshing; redact-sensitive geometry/textures; usage guidelines for indoor mapping in public spaces.
- Assumptions/dependencies: Stakeholder consensus; interoperability standards (glTF/BIM); compliance frameworks.
Notes on feasibility across applications:
- Current system assumes RGB-D input, static indoor scenes, and a CUDA GPU; monocular/outdoor/dynamic support is future work.
- Latency is scene-dependent (0.55–2.33 FPS in paper), sufficient for interactive demos, background mapping, and slow-cadence robotics; hard real-time requires additional engineering.
- Mesh quality is high but not guaranteed manifold; TSDF fusion offers a higher-accuracy upper bound at greater compute cost.
- Accurate calibration and reliable depth are critical; performance and fidelity degrade with poor sensors or challenging materials (e.g., transparent/reflective surfaces).
Glossary
- Absolute Trajectory Error (ATE): A metric for camera tracking accuracy that measures the deviation between estimated and ground-truth trajectories; "Absolute Tracking Error (ATE)".
- Alpha compositing: A blending technique combining overlapping layers using opacity (alpha) to produce the final pixel color; "rendered via differentiable alpha compositing".
- Alpha-blended triangle soup: A set of unconnected triangles rendered with alpha blending to model appearance before establishing mesh connectivity; "optimising an alpha-blended triangle soup".
- Analytical pose Jacobian: A closed-form derivative of the rendering loss with respect to camera pose, used to speed up optimisation; "derive analytical pose Jacobians".
- Anisotropic Gaussian: A Gaussian with direction-dependent variance used as a volumetric primitive in splatting methods; "uses anisotropic Gaussian primitives".
- Back-projection: Mapping image measurements (e.g., depth pixels) back into 3D space using camera intrinsics and pose; "by back-projecting RGB-D measurements".
- Barycentric coordinates: Coordinates expressing a point inside a triangle as a convex combination of the triangle’s vertices, enabling attribute interpolation; "interpolating the vertex colours using barycentric coordinates".
- Bundle adjustment: Joint optimisation of camera poses and 3D structure to minimise reprojection or photometric error across frames; "performing a learned dense bundle adjustment over depth maps."
- Chamfer distance: A symmetric distance between two point sets commonly used to evaluate geometric reconstruction accuracy; "Chamfer distance degrades in these areas."
- Co-visibility: The extent to which two views observe the same scene content, used for selecting keyframes or frames for mapping; "Frames with high co-visibility are selected as keyframes."
- CUDA: NVIDIA’s parallel computing platform and programming model used for GPU-accelerated kernels; "the backward pass of the CUDA kernel".
- D-SSIM: A differentiable or loss-adapted variant of Structural Similarity used as a photometric term in optimisation; "the D-SSIM term".
- Deep Marching Tetrahedra (DMTet): A neural approach to mesh extraction using marching tetrahedra within a differentiable framework; "Deep Marching Tetrahedra (DMTet)".
- Delaunay tetrahedralisation: Partitioning 3D space into tetrahedra so that no point lies inside the circumsphere of any tetrahedron; "3D Delaunay tetrehedralisation".
- Delaunay triangulation: A triangulation maximizing the minimum angle of all triangles, widely used for mesh generation and connectivity; "Delaunay triangulation maintains the existing geometry".
- Differentiable rasterisation: A rendering process that provides gradients with respect to geometry and appearance, enabling optimisation from images; "using differentiable rasterisation on the Delaunay triangulation".
- Differentiable rendering: Rendering with gradients that allow back-propagation to update scene parameters (e.g., poses, geometry, appearance); "differentiable rendering enabling joint optimisation of camera poses and scene geometry."
- Egocentric TSDF: A TSDF reconstruction centered on and moving with the camera to bound memory usage; "egocentric TSDF reconstruction".
- Equilateral regularisation: A geometric penalty encouraging triangles to be close to equilateral to avoid degenerate, elongated faces; "equilateral regularisation".
- Incentre: The center of the inscribed circle of a triangle, used here as a reference point for smooth influence functions; "the face's incentre".
- Instant-NGP: A fast neural graphics primitive approach (e.g., hash-grid MLPs) for efficient view-dependent appearance modeling; "Instant-NGP".
- Intersection-over-Union (IoU): A set overlap metric defined as intersection divided by union, used to decide keyframe selection; "intersection-over-union of triangles".
- Keyframing: Selecting representative frames to anchor mapping and optimisation for efficiency and stability; "Keyframing is based on co-visibility checks".
- Lie algebra se(3): The tangent space of the SE(3) pose group, used to parametrise small camera pose updates; "elements of \mathfrak{se}(3)".
- Manifoldness: A topological property of meshes where each edge and vertex has a consistent neighborhood, avoiding non-manifold artifacts; "enforce manifoldness".
- Marching cubes: A classic algorithm that extracts polygonal meshes from volumetric scalar fields; "the marching cubes algorithm".
- Mesh Splatting: A rendering approach that splats triangles with shared per-vertex attributes for differentiable mesh-like rendering; "builds upon Mesh Splatting".
- Photometric error: The pixel-wise difference between rendered and observed images used to supervise rendering-based optimisation; "comprising both photometric and geometric error."
- Rasterisation: Converting geometric primitives into pixel samples for image formation; "the rasterisation process is differentiable".
- Rasteriser: The component performing rasterisation and providing outputs like colors, depths, and normals; "returned by the rasteriser".
- Ray-marching: Sampling along rays through a volume or field to compute color and depth, common in neural rendering; "expensive ray-marching".
- Restricted Delaunay triangulation: A variant of Delaunay triangulation constrained to a surface or subset, used to recover mesh connectivity; "Restricted Delaunay triangulation".
- SE(3): The Special Euclidean group of 3D rotations and translations representing rigid body poses; "\mathbf{SE}(3)".
- Signed distance field (SDF): A scalar field giving the signed distance to a surface, used here for smooth triangle coverage in image space; "2D signed distance field".
- Skew-symmetric matrix: A matrix representing the cross product as a linear map, used in pose Jacobians; "skew symmetric matrix".
- Structural Similarity (SSIM): A perceptual image similarity metric often used in photometric losses; "Structural Similarity (SSIM) loss".
- Surfel: A surface element (or oriented disk) used as a point-based model in dense SLAM; "optimises poses and surfels".
- Tetrahedra: 3D simplices used to tessellate space in triangulations or meshing; "form tetrahedra with triangular faces."
- Truncated Signed Distance Field (TSDF): A clipped SDF for robust fusion of depth maps into volumetric grids; "truncated signed distance field (TSDF) integrates depth maps".
- TSDF Fusion: Integrating depth frames into a TSDF volume to extract a mesh; "TSDF Fusion".
- Triangle soup: An unconnected collection of triangles without explicit mesh connectivity; "a `triangle soup' can be optimised".
- Voxel hashing: A sparse volumetric data structure indexing active voxels via a hash table for scalable mapping; "voxel hashing".
- Voronoi cells: Regions partitioning space by nearest points, dual to Delaunay triangulation, used here for ray tracing; "Voronoi cells".
- Watertight mesh: A mesh without holes where every edge is consistently shared, suitable for robust physical operations; "achieve a watertight, smooth, and photorealistic result."
- Window-based densification: Adding detail by subdividing primitives based on their visibility within a sliding keyframe window; "window-based densification."
- Window function: A smooth per-pixel influence function that decays from the triangle’s incentre to its edges; "defined as a window function".
Collections
Sign up for free to add this paper to one or more collections.