- The paper presents a unified pipeline that leverages an alternating dual-hand vision transformer and diffusion-based decoding to set new state-of-the-art benchmarks.
- It employs compositional semantic conditioning with language model embeddings to resolve visual ambiguities in bimanual action recognition.
- Empirical results show significant improvements on both dual-hand and single-stream datasets through adaptive loss-weighting and cross-hand fusion.
Diffusion-Based Dual-Hand Action Segmentation with Polyphony
Introduction and Motivation
Polyphony presents a unified three-stage pipeline for dual-hand action segmentation, addressing the need for fine-grained, temporally precise understanding of bimanual activity in complex assembly, kitchen, or surgical settings. Most temporal action segmentation (TAS) frameworks process human activity as a monolithic stream, ignoring the nuanced, context-dependent coordination patterns and asymmetries between left and right hand streams. Polyphony is explicitly designed to capture these phenomena, introducing new mechanisms for balanced representation learning, enhanced semantic alignment, and robust inter-hand coordination modeling. The framework further demonstrates strong effectiveness in both dual-hand and single-stream benchmarks, establishing new state-of-the-art (SOTA) performance.
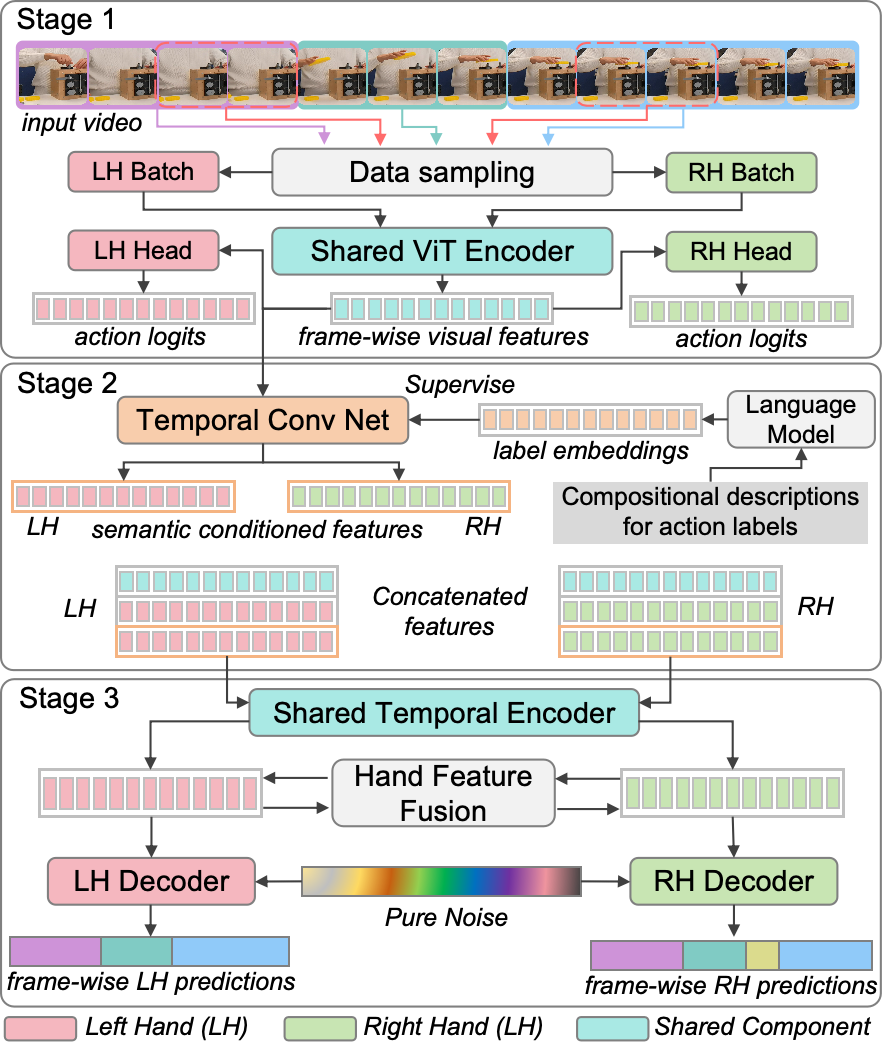
Figure 1: Polyphony's three-stage modular pipeline: dual-hand feature extraction via a shared ViT, semantic feature conditioning through compositional action language alignment, and diffusion-based dual-hand segmentation with cross-hand feature fusion.
Methodological Framework
Polyphony starts with an ADH-ViT backbone, in which a shared spatio-temporal ViT encoder is alternately trained on mini-batches corresponding to either left or right hand clips. This alternation ensures equal gradient contributions from each hand stream, directly mitigating representation conflict—a persistent problem where the dominant hand monopolizes optimization due to gradient magnitude and data distribution skews. Two hand-specific linear heads map encoder outputs to class logits per hand, but feature learning is fundamentally shared, maximizing cross-stream generalization. A sliding window mechanism enables dense per-frame feature extraction for downstream segmentation.
Stage 2: Semantic Feature Conditioning
To resolve visual ambiguity that often emerges between semantically similar bimanual actions ("screw nut onto bolt" vs. "screw nut onto shaft"), Polyphony introduces compositional semantic conditioning. For each action, structured descriptions (verb, manipulated object, target object, tool) are instantiated into LLM (LM) embeddings (the authors utilize MiniLM), and a TCN aligns dense visual features to these language-rich representations via an adaptive cosine-MSE loss. During inference, only visual pathways are used, so semantics are introduced solely as a training-alignment signal. The resulting features are concatenated into a composite Motion-Action-Semantic (MAS) embedding for each hand.
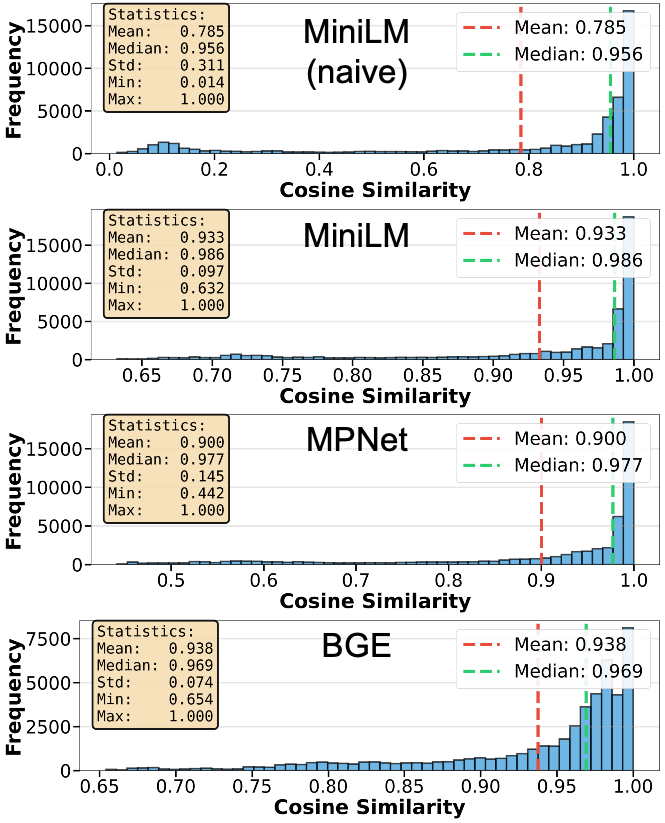
Figure 2: Distribution of cosine similarities between visual and semantic embeddings—structured descriptions yield tighter, higher-alignment distributions compared to naïve action names.
Stage 3: Diffusion-Based Dual-Hand Segmentation
The MAS features are passed to a temporal encoder with mixed convolution-attention layers, outputting initial per-frame logits and hierarchical features. Polyphony then applies a diffusion-based decoder architecture—following conditional denoising probabilistic modeling (DDPM)—to iteratively refine action distributions. Crucially, after initial encoding, each hand’s hierarchical features are fused via channel-wise concatenation and 1x1 conv layers, enabling asymmetric, hand-specific cross-stream interaction. This fusion is vital for modeling complex dependencies (independent, cooperative, or antagonistic) between hands.
The framework incorporates an adaptive, bidirectional loss-weighting scheme: during training, the loss for each hand is dynamically upweighted when recent validation accuracy lags the contra-lateral hand, preventing collapse or dominance of a single stream. The full training objective jointly optimizes encoder and decoder losses, including temporal smoothness and boundary penalties.
Empirical Results
Dual-Hand Segmentation Results
On HA-ViD and ATTACH, Polyphony sets new SOTA across all standard metrics (accuracy, edit distance, segmental F1), achieving gains up to 16.8 points over prior bests (FACT, DiffAct) using identical I3D visual backbones. With MAS features, the gains are even more pronounced. Unlike competing methods that require separate models per hand or explicit object bounding boxes, Polyphony produces dual-stream segmentation via a unified architecture with a single visual encoder.
Single-Stream Generalization
Polyphony’s modularity allows for natural extension to single-stream (monomanual) scenarios such as the Breakfast dataset. Here, even with a small ViT-Base backbone, Polyphony surpasses EAST (which uses 12× more parameters in ViT-Giant), demonstrating the advantage conferred by the MAS design and semantic conditioning. The model achieves 82.5% accuracy, setting a new benchmark for the dataset.
Component and Semantic Ablation
Ablations on HA-ViD show that hand-specific action logits and, particularly, compositional semantic features, each yield measurable accuracy and consistency improvements, especially for the non-dominant (left) hand. Removing cross-hand fusion or adaptive weighting exacerbates inter-hand imbalance, demonstrating the necessity of both modules for robust, unbiased learning. For semantic conditioning, the use of structured, compositional descriptions and smaller LMs yields superior alignment and segmentation performance versus naïve labels or higher-dimensional LMs.
Alternating Training Study
Alternating task-focused mini-batching (LH ↔ RH) outperforms naïve joint training: the non-dominant (LH) sees larger accuracy improvements and the performance gap is nearly eliminated, verifying that the method effectively averts representation collapse.
Qualitative Analysis
Qualitative results highlight Polyphony’s ability to maintain temporal coherence, resolve asymmetric streams, and synchronize action transitions where appropriate, outperforming prior approaches prone to over-segmentation and poor coordination. Notable failure cases include syncretic bias—where the system predicts excess hand coordination due to supervision asymmetries—and errors on long-tail or tool-mediated actions (Figure 3).
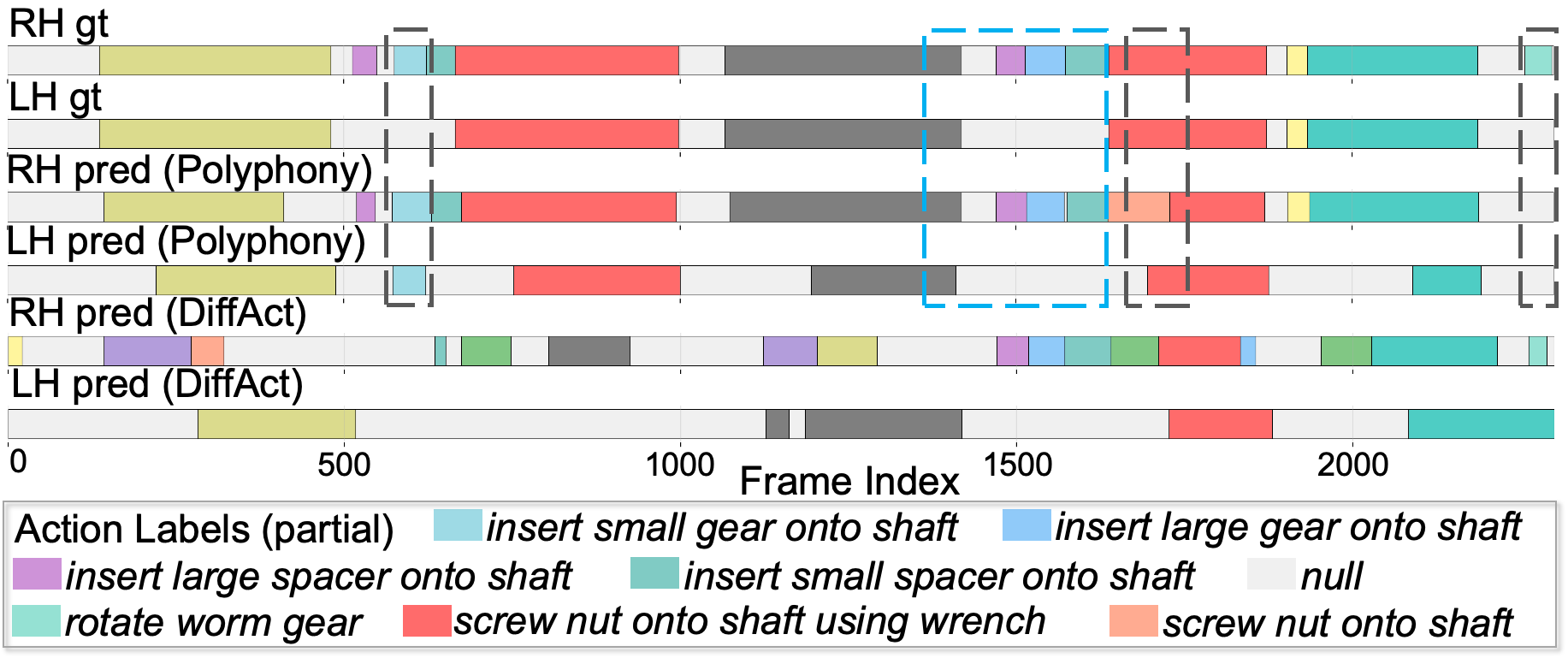
Figure 3: Dual-hand segmentation examples: Polyphony demonstrates correct asymmetric, coordinated, and independent action transitions relative to ground truth and the DiffAct baseline; failure modes and challenging cases are boxed for discussion.
Implications and Future Directions
The Polyphony pipeline establishes several important precedents: (1) fine-grained bimanual action segmentation can be addressed by a single, alternately-trained vision backbone, countering prior architectural orthodoxy; (2) diffusion models, with appropriate cross-stream conditioning, provide strong advantages for complex, coordinated temporal prediction; (3) semantic feature conditioning via compositional language promotes disambiguation of visually similar actions.
Practically, this positions Polyphony as a candidate for real-time bimanual task understanding in domains such as collaborative robotics, medical skill assessment, and surveillance. The architecture’s modularity allows upgrades in any stage (e.g., stronger backbone, better semantic LM, advanced cross-stream attention) without end-to-end re-design.
Despite these strengths, current limitations are identified: Polyphony’s dependence on manually constructed compositional semantic descriptors limits scalability. Learned coordination priors sometimes induce errors on hand-decomposed or minority action classes. The system could further benefit from end-to-end LLM-based semantic parsing and self/weakly supervised expansion, as well as extension to multi-agent (beyond dual-hand) contexts.
Conclusion
Polyphony introduces a compelling, well-architected solution to dual-hand action segmentation by tightly integrating vision transformers, compositional semantic signals, and diffusion-based iterative decoding with cross-hand fusion. It delivers substantial improvements over strong established baselines across bimanual and monomanual datasets, with empirical and analytic evidence supporting the efficacy of its critical design choices. Its modularity and balanced learning mechanisms make it an important foundation for future studies of coordinated and compositional activity understanding in complex video scenarios (2605.31115).

