HandX: Scaling Bimanual Motion and Interaction Generation
Abstract: Synthesizing human motion has advanced rapidly, yet realistic hand motion and bimanual interaction remain underexplored. Whole-body models often miss the fine-grained cues that drive dexterous behavior, finger articulation, contact timing, and inter-hand coordination, and existing resources lack high-fidelity bimanual sequences that capture nuanced finger dynamics and collaboration. To fill this gap, we present HandX, a unified foundation spanning data, annotation, and evaluation. We consolidate and filter existing datasets for quality, and collect a new motion-capture dataset targeting underrepresented bimanual interactions with detailed finger dynamics. For scalable annotation, we introduce a decoupled strategy that extracts representative motion features, e.g., contact events and finger flexion, and then leverages reasoning from LLMs to produce fine-grained, semantically rich descriptions aligned with these features. Building on the resulting data and annotations, we benchmark diffusion and autoregressive models with versatile conditioning modes. Experiments demonstrate high-quality dexterous motion generation, supported by our newly proposed hand-focused metrics. We further observe clear scaling trends: larger models trained on larger, higher-quality datasets produce more semantically coherent bimanual motion. Our dataset is released to support future research.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
HandX: A Simple Guide
What’s this paper about?
This paper is about teaching computers to create realistic two-hand (bimanual) movements, especially detailed finger motions and when the hands touch things or each other. The authors build a big dataset called HandX, come up with a smart way to describe hand motions in words, and test two kinds of AI models that turn text into lifelike hand movements. They also show that using more and better data, plus bigger (but not too big) models, makes the results better.
What are the main questions the paper asks?
The paper focuses on five clear goals:
- Can we build a large, high-quality dataset of two-hand motions with accurate finger details?
- Can we automatically write good, detailed text descriptions of these motions?
- Can AI models generate realistic two-hand motions from text, including fine finger actions and hand-to-hand contact?
- How should we measure quality for hands (not just whole-body), especially timing of touch and coordination?
- Do models get better in a predictable way as we give them more data and more model capacity?
How did they do it? (Methods in everyday language)
Think of this like making a super-detailed cookbook for hand movements and testing two different “chefs” to follow the recipes.
- Building the data (the “ingredients”)
- They combined several existing datasets and converted everything into the same format so it all matches.
- They recorded new data with a 36-camera motion capture studio (like putting reflective stickers on hands and filming from many angles, as is done in animated movies). This captures tiny finger bends and when hands touch or slide.
- They cleaned the data by removing boring or unrealistic parts, keeping only meaningful interactions.
- Writing motion descriptions automatically (turning movements into words)
- First, they extract simple, reliable facts from the motion, such as:
- How much each finger bends
- Distances between fingers and palms
- Events like “touch,” “slide,” or “release”
- They turn these facts into a structured summary (like a tidy checklist).
- Then they ask a LLM (an AI that writes text) to turn those facts into natural-sounding descriptions at different detail levels: short, medium, and very detailed. The descriptions separately cover the left hand, the right hand, and how the two hands work together over time.
- Training two kinds of AI “chefs” to generate motion from text
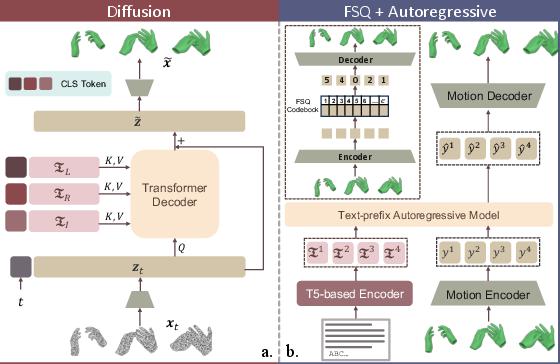
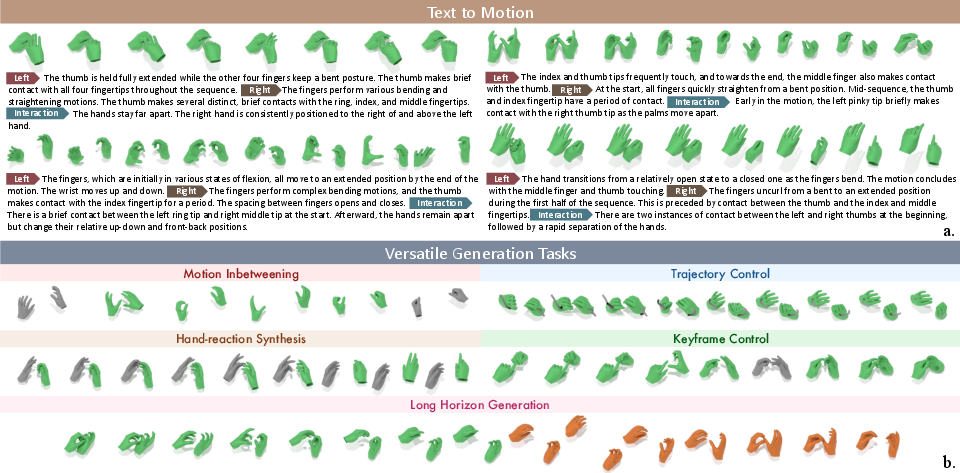
- Diffusion model: Imagine starting with a blurry/noisy drawing of hand motion and “cleaning” it step by step until it looks clear and realistic. This model reads three texts—left hand, right hand, and the interaction—and uses them to guide the cleaning process. It can also fill in blanks, like:
- Motion in-betweening: you give start and end poses, it fills the middle.
- Keyframes: you give a few “snapshots,” it draws the motion between them.
- Wrist path or one-hand fixed: it follows given paths or reacts to a fixed hand.
- Long sequences: it generates motion in chunks that connect smoothly.
- Autoregressive (AR) model: Think of writing a sentence one word at a time. This model turns continuous motion into a sequence of discrete “motion tokens” (like letters), then predicts the next token over and over to build the full motion. It uses:
- FSQ (Finite Scalar Quantization): a method to turn smooth motion into a set of “tokens,” so the model can predict them like text.
- Measuring quality (fair scoring for hands) They use several metrics:
- Realism and variety: FID (a score that checks how close the generated motions are to real ones) and Diversity (do the results avoid repeating the same motion).
- Text alignment: R-Precision and Matching Distance (do the motions match the text description).
- Contact quality: precision/recall/F1 for contact (did the model touch at the right time and place?).
What did they find, and why does it matter?
- The dataset: HandX is large, clean, and focused on two-hand, contact-rich actions with finger-level detail. It includes multi-level text descriptions aligned with motion events.
- The models: Both the diffusion and AR models can create high-quality, expressive hand motions that follow text instructions and preserve realistic timing of touch and coordination.
- Flexible control: The diffusion model can fill in missing parts, follow key poses, respect wrist paths, or make one hand respond to the other—all with one unified approach.
- New hand-focused evaluation: Their metrics make it possible to judge finger and contact realism, which older whole-body metrics often miss.
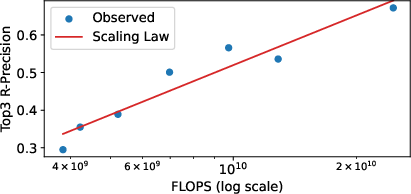
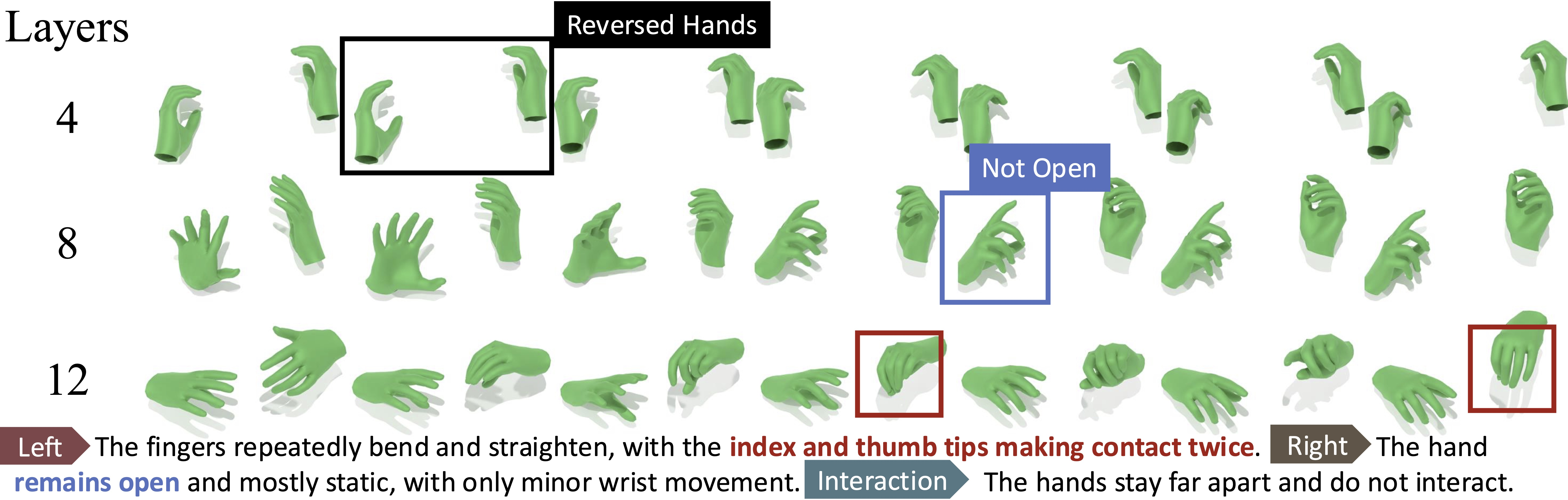
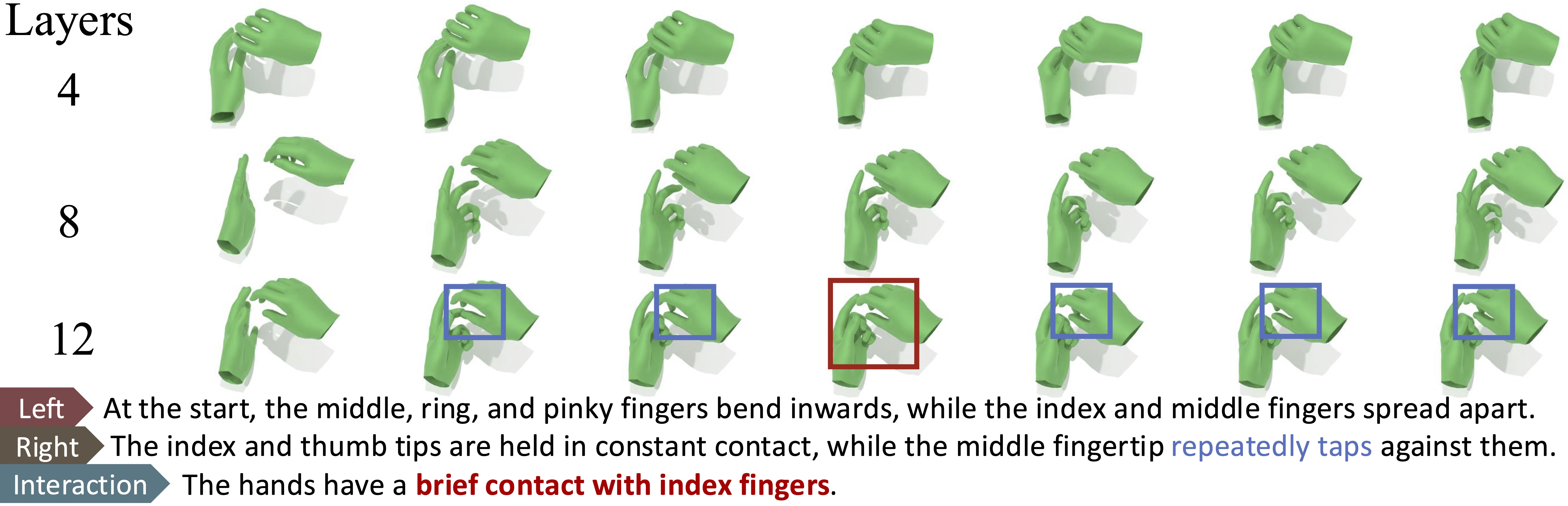
- Scaling trends: As they increase the dataset size and the model capacity together, text-matching and contact accuracy improve clearly. However, making the model too large without enough data can hurt performance. For AR models, bigger “token vocabularies” work best when the model itself is also bigger.
- Real-world test: They show the learned motions on a humanoid robot with dexterous hands, suggesting these methods can transfer beyond simulation.
This matters because believable hands are crucial in games, movies, VR/AR, telepresence, and robots. Before this, many systems treated hands too simply, which made motions look fake or unusable for tasks that require precise finger control.
What’s the bigger impact?
- Better virtual characters and avatars: More expressive, natural, and useful hand motions for storytelling, learning, and entertainment.
- Practical robotics: Robots could learn more human-like hand skills or better respond to text instructions for tasks involving grasping and manipulation.
- Research foundation: HandX (the data, descriptions, metrics, and benchmarks) gives other researchers a strong starting point to build even better hand-motion systems.
- Future directions: Add whole-body coordination, richer object interactions, and physics-based realism; improve safety and fairness; and make controls easier so anyone can guide complex hand actions with simple text.
In short, HandX shows how to scale up data, descriptions, models, and evaluation for two-hand motion—and proves that doing so leads to more realistic, controllable, and useful hand behaviors.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes strong contributions in data, annotation, and modeling for bimanual hand motion generation. However, several aspects remain underexplored or insufficiently validated. The following list summarizes concrete gaps that future work can address.
Dataset scope, coverage, and biases
- Unreported subject diversity and variability: the paper does not specify number of actors, handedness distribution, demographics, or hand morphology, leaving generalization across subjects and hand sizes unclear.
- Potential studio/egocentric domain bias: newly captured high-fidelity data is studio-based and consolidated sources are mostly egocentric/object-centric; generalization to in-the-wild, cluttered, or low-visibility settings is not examined.
- Limited whole-body context: HandX focuses on hands; the impact of missing body/arm/shoulder context on realism and coordination is unquantified.
- Unknown object coverage and taxonomy: the data composition with respect to object categories, materials, shapes, and bimanual object-hand-hand coordination is not detailed, limiting assessment of manipulation breadth.
- Canonicalization artifacts: the effects of cross-dataset skeleton unification (e.g., bone-length normalization, remapping) on kinematic fidelity and cross-domain transfer are not evaluated.
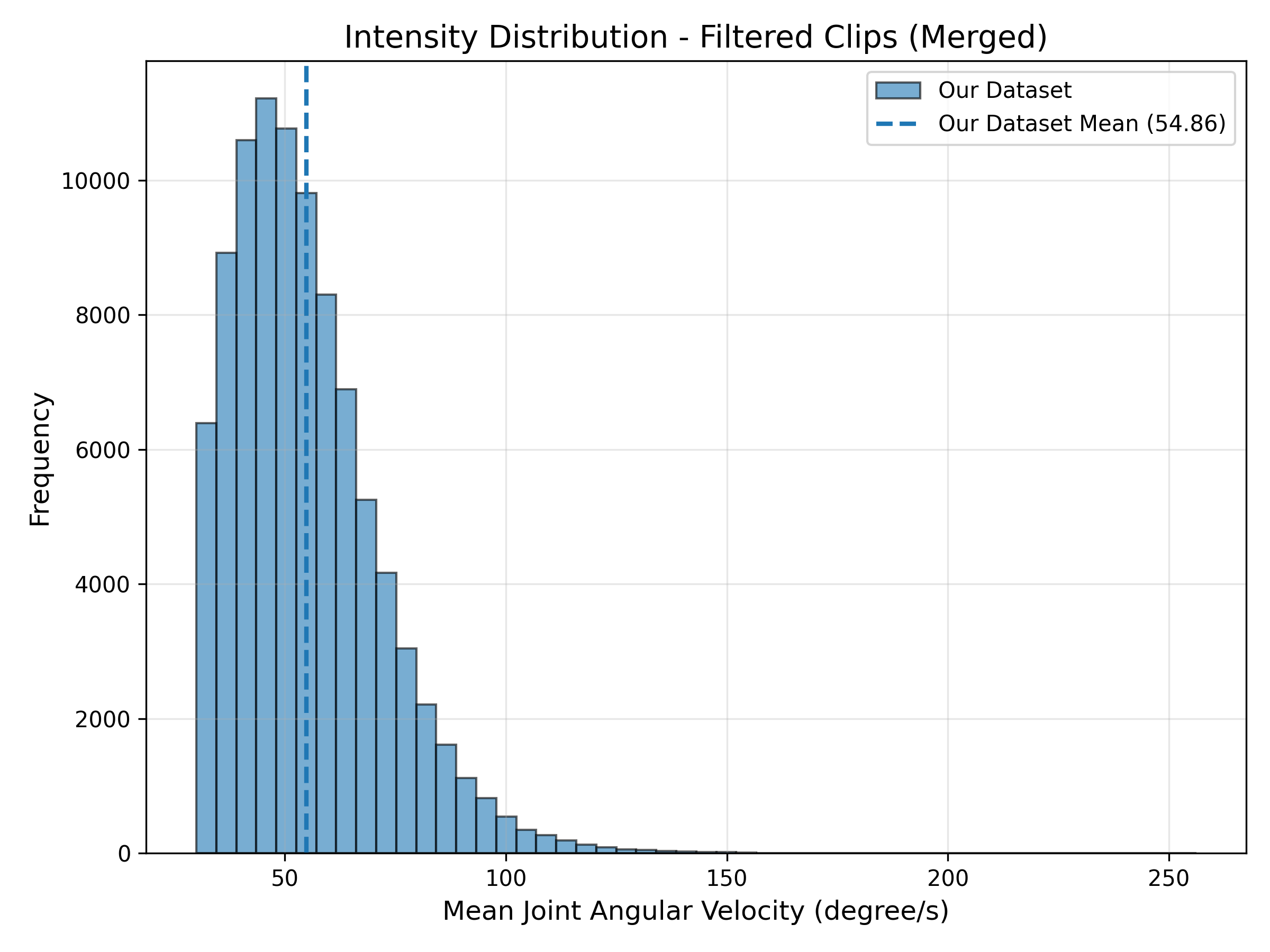
- Intensity-aware filtering bias: removing low-motion segments may discard meaningful pauses, preparatory phases, or slow expressive gestures; the impact on learning temporal pacing remains unstudied.
- Data split protocol and leakage: no analysis of near-duplicate clips across sources or subject overlap in train/val/test splits, risking overestimation of generalization.
Automatic captioning and language supervision
- Reliance on LLM-generated descriptions without human verification: the accuracy, consistency, and hallucination rate of LLM annotations from kinematic JSON are not quantified via human studies or inter-annotator agreement.
- Semantics limited to kinematics: the captioning pipeline does not integrate object identity, affordances, materials, or task goals; it is unclear how much semantic richness beyond motion patterns is captured.
- Temporal alignment and granularity: how well textual event sequencing matches ground-truth timing (e.g., onset/offset of contacts) is not validated.
- Multilinguality and ambiguity: only English is implied; robustness to ambiguous, underspecified, or culturally variable language is not explored.
- LLM reproducibility and drift: the specific LLM(s), prompts, and versioning are not detailed; annotation stability across LLM updates is an open concern.
- Descriptor sufficiency: the hand-crafted feature set (e.g., distances, flexion) may miss nuanced articulations (e.g., pronation/supination, subtle coupled joint movements); ablations on descriptor coverage are absent.
Motion representation and physical realism
- Simplified per-joint “1-DoF rotation scalar”: the assumption that a single scalar sufficiently captures joint rotation may be restrictive for complex MCP/IP coupling; comparative analysis versus full MANO or 3-DoF representations is missing.
- Post-hoc MANO recovery: the consequences of generating positions + scalars and then optimizing to MANO meshes (e.g., interpenetrations, bone-length consistency, anatomical plausibility) are not evaluated.
- No physical constraints: models are trained without physics-based or contact-consistency losses; absence of self-collision checks, joint-limit enforcement, or force/torque plausibility is not addressed.
- High-frequency motion preservation: AR tokenization uses temporal downsampling; the impact on capturing rapid fingertip motions, tremors, or fine manipulations is not quantified.
Modeling choices and training dynamics
- Autoregressive decoding determinism: AR models use greedy decoding only; the trade-off between stochastic sampling, diversity, and text alignment is unstudied.
- Tokenizer alternatives: only FSQ is evaluated; comparisons to VQ-VAE/RVQ/semantic codebooks, continuous latent diffusion, or hybrid discrete-continuous schemes are absent.
- Over-scaling degradation: very large diffusion models degrade, but the root causes (optimization instability, overfitting, insufficient data quality, regularization) are not analyzed.
- Conditioning robustness: model behavior under noisy, conflicting, or underspecified text prompts (e.g., left/right ambiguity) is not stress-tested.
- Long-horizon stability: partial denoising autoregression is used for extension, but error accumulation, temporal drift, and stability over long sequences are not systematically measured.
Evaluation metrics and protocols
- Hand- and contact-specific metrics are narrow: contact metrics use a fixed 2 cm threshold and event matching; they do not assess contact duration accuracy, timing offsets, sliding/rolling, or contact stability.
- Lack of object-aware evaluation: there are no metrics for hand–object or hand–hand–object contacts (e.g., grasp stability, object state changes, functional success).
- No physical plausibility audits: metrics for self-penetration, joint-limit violations, mesh–mesh collisions (inter- and intra-hand), or kinematic smoothness are not reported.
- Text–motion alignment depends on generic embeddings: R-Precision/MM Dist rely on unspecified text/motion encoders; sensitivity to encoder choice and their suitability for hand-level semantics is not studied.
- Missing human perceptual studies: no user evaluation on realism, dexterity, or text faithfulness, particularly for subtle finger articulation and bimanual coordination.
- Task-specific evaluation gaps: while versatile controls (in-betweening, keyframes, wrist paths, hand-reaction) are demonstrated, standardized benchmarks and metrics for each control mode are not provided.
Generalization, robustness, and OOD behavior
- Cross-dataset generalization: performance when training on some sources and testing on different capture modalities or skeletons is not reported.
- OOD prompts and skills: robustness to unseen verbs, compound instructions, or rare bimanual patterns is untested.
- Sensitivity to kinematic noise: the effect of annotation noise and reconstruction errors (especially in consolidated datasets) on generation and evaluation is not analyzed.
Robotics transfer and embodiment
- Limited details on robot instantiation: the pipeline for retargeting to robot hands (kinematics, contact control, compliance, force targets) and quantitative success rates are not provided.
- Contact and force realization: alignment between generated kinematic contacts and executable force-closure grasps on hardware is not evaluated.
- Perception–action loop: the system is not integrated with perception or closed-loop control; robustness under real-world sensing and actuation uncertainty remains open.
Scaling laws and data quality
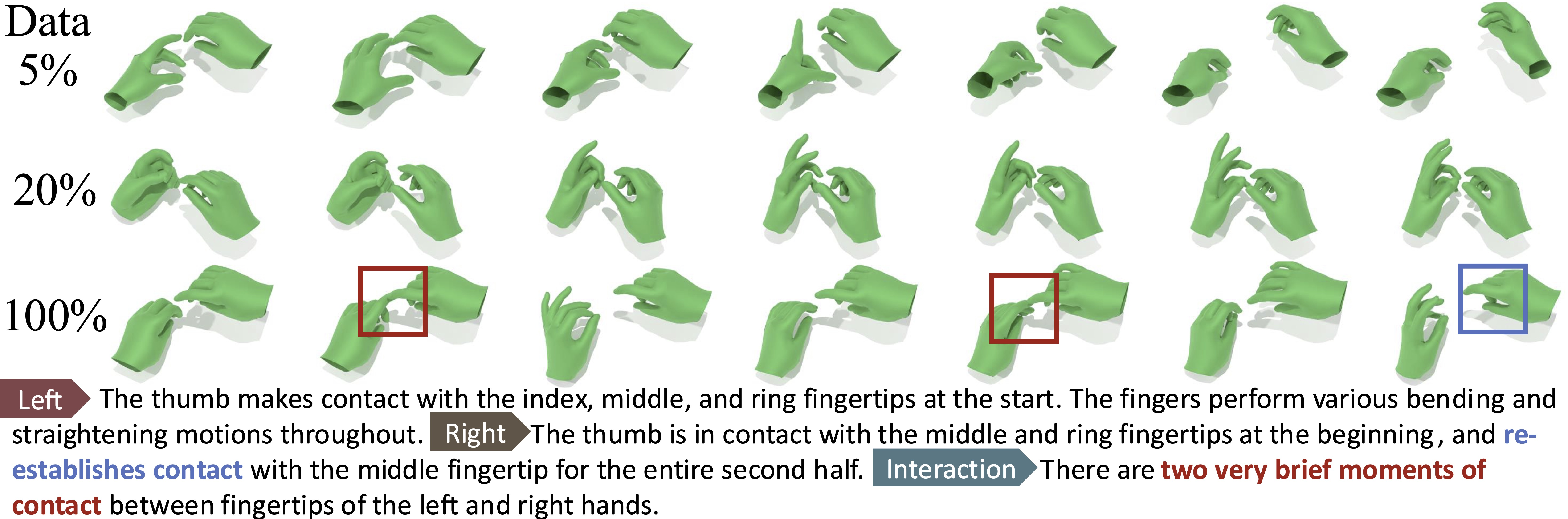
- Partial scaling analysis: the reported log-linear law (R-Precision vs FLOPs) is derived at 5% data; it is unclear if the relationship holds across full data scales or for other metrics (e.g., contact F1, FID).
- Data quality vs. quantity: the relative contributions of filtration, caption detail, and new mocap data to scaling gains are not disentangled.
- Negative scaling regimes: conditions under which more capacity or more (noisier) data hurt performance are not systematically mapped.
Reproducibility and release details
- Annotation and metric reproducibility: concrete prompt templates, LLM versioning, and evaluation encoders are not fully specified for exact replication.
- Licensing and ethical use: implications of consolidating datasets with heterogeneous licenses and privacy constraints are not discussed.
These gaps suggest concrete next steps: broaden and disclose dataset statistics and splits; validate LLM captions with human audits; incorporate object/task semantics; strengthen physical plausibility; expand metrics to contact timing and object interaction; benchmark control tasks with standardized protocols; analyze over-scaling; and quantify real-robot performance with closed-loop control.
Practical Applications
Immediate Applications
- Procedural bimanual hand animation for games, VR/AR, and VFX (Entertainment/Software)
- Uses: Text-to-motion for expressive finger articulation; keyframe in-betweening; wrist-trajectory–constrained synthesis; hand-reaction synthesis; long-horizon generation for cutscenes and live experiences.
- Tools/workflows: Unity/Unreal/Blender/Maya plugins that take left/right/inter-hand text prompts or sparse keyframes and output FBX/BVH; animation retargeters for MANO → custom rigs; partial-denoising “constraint-aware” motion editors.
- Assumptions/dependencies: Rig compatibility and retargeting quality; real-time or near-real-time inference speed; license/access to HandX and model checkpoints; GPU availability for diffusion.
- Telepresence and social XR avatars with realistic, contact-aware hand gestures (HCI/Telecom)
- Uses: More believable hand coordination in video calls, VRChat, enterprise collaboration; gesture-enhanced communication for demos and training.
- Tools/workflows: Integration with avatar SDKs (e.g., Meta Avatars, Ready Player Me); runtime blending of captured wrist/arm trajectories with generated finger motions; latency-aware diffusion/AR decoders.
- Assumptions/dependencies: Robust real-time tracking; low-latency inference; safety filters to prevent implausible contact poses; per-user calibration.
- Rapid motion prototyping and retargeting for dexterous robot hands (Robotics)
- Uses: Generate candidate bimanual trajectories from natural language or sparse constraints for Allegro/Shadow/LEAP hands and humanoids; accelerate programming-by-description and task rehearsal.
- Tools/workflows: ROS 2 node that consumes text + constraints and outputs joint trajectories; human→robot kinematic retargeting and IK; contact-aware trajectory post-processing.
- Assumptions/dependencies: Accurate retargeting between human MANO and robot kinematics; collision/force constraints added downstream; perception and control stacks for closed-loop execution (not provided by HandX alone).
- Synthetic data generation for training perception and HOI models (Computer Vision/AI)
- Uses: Augment datasets for hand/keypoint detection, hand-object/hand-hand contact recognition, and HOI parsing with varied, contact-rich bimanual poses.
- Tools/workflows: Dataset sampler that renders HandX motions on digital hands/avatars; domain randomization for backgrounds, textures; labels exported for contact events and kinematic descriptors.
- Assumptions/dependencies: Domain gap mitigation for vision tasks; consistent skeletal standards across datasets; rendering realism sufficient for downstream generalization.
- Benchmarking and evaluation of hand-centric motion models (Academia/R&D)
- Uses: Adopt HandX’s contact precision/recall/F1 and text-alignment metrics to evaluate new generative models, motion planners, and controllers.
- Tools/workflows: Metric library and standardized splits; cross-benchmark comparison dashboards.
- Assumptions/dependencies: Consistent contact labeling across methods; community adoption for comparability.
- Scalable motion captioning for existing mocap archives (Content Ops/Annotation)
- Uses: Apply the two-stage kinematic-feature→LLM pipeline to produce fine-grained annotations (left/right/inter-hand, events, timing) for legacy datasets.
- Tools/workflows: Feature extractor that emits JSON descriptors; prompt templates for LLMs (e.g., T5/LLM APIs); quality-check sampling and human-in-the-loop correction.
- Assumptions/dependencies: Reliable feature extraction from diverse skeletons; LLM access and cost control; prompt robustness across motion domains.
- Instructional content and interactive tutorials (Education/Training)
- Uses: Generate stepwise, semantically aligned hand demonstrations for crafts, assembly, or lab techniques; overlay in AR.
- Tools/workflows: Web widget that maps natural-language steps to hand-motion clips; timeline editor aligning events to narration.
- Assumptions/dependencies: Domain validation of motions (task correctness); alignment with tools/objects when present; accessibility considerations.
- Reproducible lab demos for dexterous humanoids (Academia/Robotics Labs)
- Uses: Replicate the paper’s “instantiation on a real-world humanoid with dexterous hands” for coursework, demos, or baselines.
- Tools/workflows: Provided HandX models + retargeting scripts; lab-specific safety wrappers and execution monitors.
- Assumptions/dependencies: Availability of dexterous hands; hardware interfaces; compliant control and safety interlocks.
Long-Term Applications
- Language-guided household service robots performing dexterous bimanual tasks (Robotics/Smart Home)
- Uses: Execute text-described tasks (e.g., “open the jar while steadying the lid”) with contact-aware coordination.
- Tools/workflows: Integrate HandX-style generators with perception, grasp planners, tactile sensing, and feedback controllers.
- Assumptions/dependencies: Robust sim2real transfer; object/scene perception; force/impedance control; safety certification for HRI.
- Surgical and medical skills simulation with precise bimanual manipulation (Healthcare/MedEd)
- Uses: Train and assess procedures requiring fine finger coordination and timed contact (suturing, instrument handling).
- Tools/workflows: Physics-based simulators with anatomical constraints; haptic devices rendering contact events from generated motions; performance metrics aligned with HandX’s event descriptors.
- Assumptions/dependencies: Domain-specific data, anatomy constraints, and validation; high-fidelity haptics; regulatory considerations for training certification.
- Sign-language synthesis and translation with fine-finger articulation (Accessibility/Communication)
- Uses: Naturalistic, expressive hand articulation for sign-language avatars and translators beyond template gestures.
- Tools/workflows: Combine HandX-like generators with linguistic models and sign-specific datasets; timing and prosody control.
- Assumptions/dependencies: Large-scale, linguistically annotated sign corpora; cultural and linguistic validation; metrics for sign intelligibility.
- Assistive exoskeletons and prosthetics with coordinated bimanual intent decoding (Healthcare/Assistive Tech)
- Uses: Map user intent (EMG/EEG/IMU) to natural bimanual motions with correct contact timing and inter-hand coordination.
- Tools/workflows: Intent decoders feeding a constrained HandX-style generator; personalization via on-device fine-tuning.
- Assumptions/dependencies: Reliable intent sensing; safety and comfort; adaptation to individual biomechanics; regulatory approval.
- Predictive human–robot collaboration in manufacturing (Industrial Robotics)
- Uses: Forecast human hand trajectories and contact events to synchronize robots, reduce collisions, and improve ergonomics.
- Tools/workflows: Real-time predictors trained with HandX-style contact metrics; shared autonomy planners using predicted contact windows.
- Assumptions/dependencies: High-quality sensing (multi-view, depth, wearables); latency bounds; workplace safety standards.
- Contact-aware haptic feedback generation for XR (Haptics/Entertainment)
- Uses: Drive vibrotactile/force-feedback cues using predicted contact events and intensities to enhance immersion.
- Tools/workflows: Event-to-haptic mapping engines; device SDK integration (gloves, controllers).
- Assumptions/dependencies: Device capabilities and bandwidth; user comfort; perceptual tuning of contact thresholds.
- Standards and policy for evaluating dexterous interaction (Standards/Policy)
- Uses: Adopt contact precision/recall/F1 and text alignment as components of benchmarks for dexterous manipulation systems.
- Tools/workflows: Test suites and compliance benchmarks using HandX metrics; reporting guidelines for contact-rich tasks.
- Assumptions/dependencies: Community consensus; cross-industry buy-in; alignment with safety regulations.
- Creative AI copilots for hand choreography and performance capture (Media/Software)
- Uses: High-level natural language to author stylistic, expressive hand performances, with editable events and timing.
- Tools/workflows: Timeline-based editors with partial-denoising constraint handles; style conditioning and reference-based synthesis.
- Assumptions/dependencies: Expanded datasets for style/genre; controllability and interpretability features.
- Digital ergonomics and product/affordance design (Manufacturing/Design)
- Uses: Simulate human hand interactions with prototypes to evaluate reachability, grip comfort, and two-hand workflows.
- Tools/workflows: CAD/PLM plugins that import hand motions; contact heatmaps and ergonomic KPIs.
- Assumptions/dependencies: Accurate object models and material properties; physics-based contact modeling; validation with user studies.
- Hand-accurate video generation and editing (Media/Foundational AI)
- Uses: Control hand fidelity and contact events in video diffusion pipelines for advertising, film, and training content.
- Tools/workflows: Motion-to-video conditioning interfaces; compositing with tracked footage; fine-grained hand-edit handles.
- Assumptions/dependencies: Integration with video diffusion models; temporal coherence; licensing and rights management.
Notes on overarching assumptions and risks:
- Generalization: HandX emphasizes contact-rich bimanual motions; coverage of objects, cultural gestures, and edge cases may be limited. Additional curated data may be required for domain transfer.
- Skeleton mismatch: Converting between MANO, custom rigs, and robot kinematics requires robust retargeting and may degrade fidelity.
- Real-time constraints: Diffusion and AR models may require distillation or pruning for interactive or embedded deployment.
- Safety and ethics: Executing generated motions on robots demands collision/force limits and HRI safety checks; using LLM annotations requires transparency and human oversight for sensitive domains.
Glossary
- autoregressive (AR) model: A generative model that predicts the next element conditioned on previous ones in a sequence. "We benchmark two generative paradigms: diffusion-based and autoregressive (AR) models."
- bimanual: Involving the coordinated use of both hands. "a large-scale dataset of bimanual and dexterous motions paired with fine-grained textual descriptions."
- causal attention: Attention mechanism that only attends to past tokens to preserve autoregressive ordering. "attention among text prefix tokens is bidirectional, while attention in the motion branch is causal."
- codebook size: The number of discrete symbols available in a quantized latent representation. "varying the number of Transformer layers (8, 12, and 16) and the codebook size (512, 1,024, 2,048, and 4,096)."
- codebook utilization: How effectively a quantization codebook’s entries are used by the tokenizer. "we adopt Finite Scalar Quantization (FSQ) as it offers better codebook utilization, reconstruction quality, and scaling behavior"
- contact precision: The proportion of predicted contact events that are correct, used to evaluate interaction fidelity. "We therefore adopt contact precision (), recall (), and F1 score () to evaluate hand contact accuracy."
- cross-attention: An attention mechanism that conditions one sequence on another (e.g., motion on text). "Text embeddings for the left hand, right hand, and bimanual interaction are separately cross-attended with noisy motion embeddings"
- degrees of freedom (DoF): Independent parameters that define a joint’s possible movements. "Given that hand joints have limited rotational degrees of freedom, a single scalar is sufficient."
- deterministic decoding: A decoding strategy that selects the highest-probability token at each step (greedy decoding). "During inference, we use deterministic decoding, selecting the token with the highest predicted probability at each step."
- diffusion model: A generative model that learns to denoise data through a reverse diffusion process. "we benchmark diffusion and autoregressive models with versatile conditioning modes."
- egocentric: Captured from the perspective of the actor, typically with wearable sensors or cameras. "We consolidate large egocentric and human-object interaction datasets into a standardized corpus"
- Finite Scalar Quantization (FSQ): A discretization method that maps continuous latents to fixed scalar levels for token-based modeling. "we adopt Finite Scalar Quantization (FSQ) as it offers better codebook utilization, reconstruction quality, and scaling behavior"
- forward diffusion process: The process of progressively adding noise to data in diffusion models to define the generative objective. "The noisy input is obtained from the clean motion through the forward diffusion process~\cite{ho2020denoising}:"
- Fréchet Inception Distance (FID): A metric that compares distributions of features between generated and real samples to assess realism. "we employ the Fréchet Inception Distance (FID), which quantifies the similarity between the feature distributions of generated and ground truth sequences"
- hyperextension: Extension of a joint beyond its normal range, treated as a notable motion event. "requiring the model to report critical motion events such as contact, separation, and hyperextension"
- kinematic descriptors: Structured measurements that characterize motion (e.g., joint angles, distances) over time. "We first compute a set of kinematic descriptors, \eg, finger flexion and finger-palm distances"
- loco-manipulation: Coordinated locomotion and manipulation actions in human motion datasets. "emphasize locomotion and loco-manipulation but provide limited hand detail"
- MANO: A parametric 3D hand model used to reconstruct hand meshes from parameters. "we optionally recover the MANO parameters~\cite{MANO:SIGGRAPHASIA:2017} through post-optimization to obtain the hand meshes."
- masked conditioning: A technique that enforces known constraints during generation by masking parts of the input. "we leverage masked conditioning so a single model supports diverse control modes"
- Motion In-betweening: Generating intermediate frames between specified start and end poses. "such as fixing start and end poses for Motion In-betweening"
- Multimodal Distance (MM Dist): A metric measuring alignment between generated motion features and associated text features. "and the Multimodal Distance (MM Dist), which quantify feature-level correspondence between generated hand motion and their associated text embeddings."
- OptiTrack: A commercial optical motion-capture system using multiple cameras and reflective markers. "We collect new data using a 36-camera OptiTrack optical motion-capture system in a dedicated studio"
- partial denoising: A diffusion inference strategy that blends known conditions with current samples during denoising. "This versatility stems from an inference-time {partial denoising} strategy, which enforces known constraints by blending the input condition with the current sample at each denoising step."
- quantization levels: The discrete scalar values used to represent continuous latents in quantization. "the latent is discretized into uniformly spaced integer levels as:"
- R-Precision: An information-retrieval metric measuring how many relevant items appear in the top-R results, used for text-motion alignment. "we adopt R-Precision and the Multimodal Distance (MM Dist), which quantify feature-level correspondence"
- SMPL: A parametric 3D human body model commonly used in motion synthesis. "treat them as rigid end-effectors in SMPL~\cite{SMPL:2015}"
- T5: A Transformer-based sequence-to-sequence model used here as a text encoder. "We adopt T5~\cite{raffel2020exploring} as the sequence-to-sequence text encoder for the prompts."
- text-prefix autoregressive model: An AR model conditioned on a sequence of text tokens prepended as a prefix. "We adopt a text-prefix autoregressive model."
- timestep token: An explicit embedding of the diffusion timestep appended to the motion sequence representation. "we further encode the timestep using an MLP-based timestep encoder to obtain a timestep token"
- tokenizer (motion tokenizer): The module that encodes motion into discrete tokens (and decodes them) for AR modeling. "Our motion tokenizer consists of a motion encoder , a motion decoder , and a finite scalar quantizer "
Collections
Sign up for free to add this paper to one or more collections.