- The paper presents AnchorSteer, which combines self-discovered concept injection and structural anchoring to achieve both semantic transformation and strict musical fidelity.
- It introduces unconditioned and conditioned injection modules that optimize h-space directions using contrastive prompt pairs to control attribute transfer.
- Results show that the conditioned injection variant significantly improves semantic editability while preserving rhythm and melody, outperforming pure steering or anchoring baselines.
AnchorSteer: Self-Discovered Concept Injection for Structure-Preserving Music Editing
Diffusion-based text-to-music (TTM) editing confronts a fundamental trade-off: how to achieve strong semantic transformation (i.e., high-level conceptual changes such as instrument or genre shift) while strictly maintaining the underlying rhythmic and melodic scaffold of a source audio track. Pure semantic steering mechanisms, when decoupled from structural constraints, induce significant structural drift, yielding attribute-aligned but unfaithfully reconstructed audio. Conversely, strict structural adaptors enforce temporal and melodic consistency but severely suppress responsiveness to edit prompts, resulting in over-constrained, minimally altered outputs.
AnchorSteer addresses this dilemma by proposing an explicit separation and synergistic integration of two editing forces:
- Semantic steering—achieved via self-discovered, interpretable concept vectors injected into the internal hidden-state (h-space) of the diffusion model.
- Structural anchoring—realized through the MuseControlLite adaptor, providing fine-grained, temporally aligned control over melody and rhythm.
This design enables controllable, attribute-driven editing, with robust preservation of musical structure.
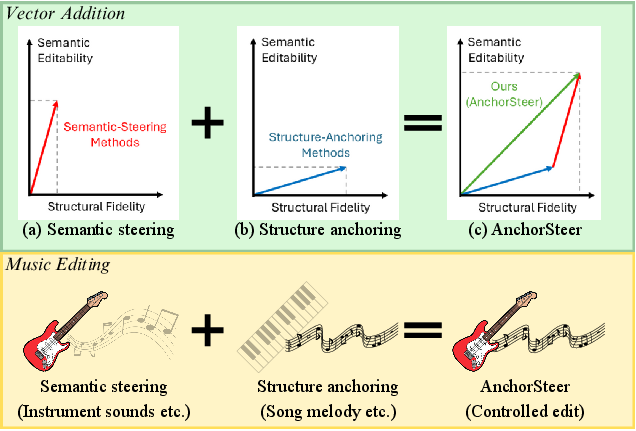
Figure 1: Schematic of the trade-off between editability (semantic steering) and fidelity (structural anchoring), highlighting the AnchorSteer approach which achieves both properties.
Self-Supervised Concept Vector Discovery
AnchorSteer's semantic steering module is grounded in self-supervised discovery of concept vectors without the need for curated attribute labels or specialized data. The key innovation involves comparing model generations from a base prompt versus a target prompt containing a specific semantic attribute (e.g., "A music piece" vs. "A solo piano music piece"). Reference generations conditioned on the target prompt are created. Then, injection modules are optimized—while freezing the diffusion backbone—to minimize reconstruction loss when denoising reference latents conditioned only on the base prompt plus additive injection vectors.
This pipeline operationalizes the semantic gap as a plug-and-play direction in h-space. Two injection parameterizations are explored:
- Unconditioned injection: layer-specific, fixed vectors applied additively in h-space.
- Conditioned injection: dynamic, adaptive modules that compute corrections as a function of the current hidden state.
The result is a set of reusable semantic controls encapsulating arbitrary concepts, applicable across varied audio contexts.
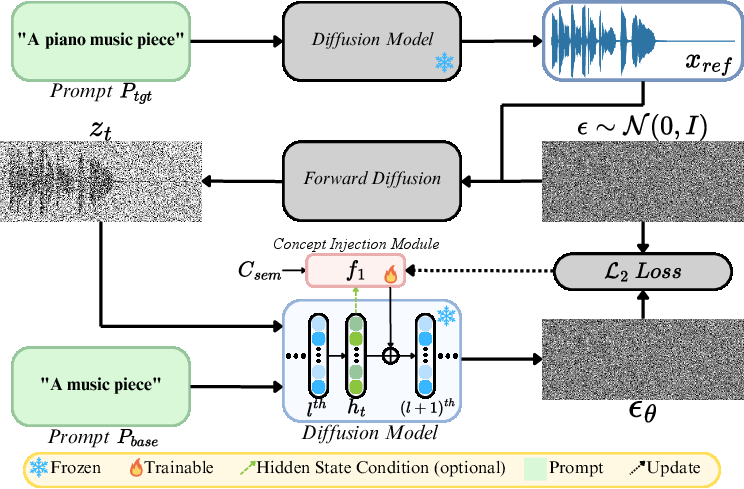
Figure 3: Workflow for self-supervised discovery, contrasting prompt pairs and optimizing injection modules via reference-based reconstruction.
Structure-Anchored Steering: Editing Pipeline
During inference, AnchorSteer applies the discovered injection modules in tandem with explicit structural conditions extracted from a source reference via MuseControlLite. The cross-attention-based adaptor injects melody/rhythm/dynamics sequences (e.g., via CQT/beat-tracking) with rotary position embedding (RoPE) alignment, anchoring the generative process to the original musical scaffold.
The injection modules then bias the model’s trajectory in h-space toward the desired attribute. The synergy of the anchor and steering mechanisms is empirically validated to achieve both significant semantic transformation and stringent temporal/harmonic preservation.
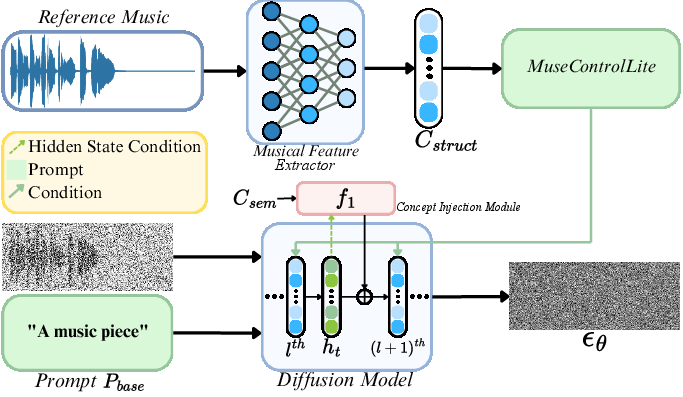
Figure 2: Block diagram of the synergistic editing pipeline, demonstrating integration of structural conditioning and semantic concept injection.
Experimental Results
Quantitative Results and Trade-off Analysis
On ZoME-Bench, AnchorSteer—especially the conditioned injection variant—outperforms both steering-only and anchoring-only paradigms. The semantic editability, as captured by GAP and ΔCLAP metrics, is maximized by AnchorSteer, whereas structural metrics (Chroma, LPAPS) confirm competitive, practical structure retention.
The plain steering baseline achieves maximal semantic shift (high GAP, high ΔCLAP_T), but fails at structural preservation (low Chroma, high LPAPS), signifying uncontrolled generative drift. The structure-anchoring baseline yields minimal semantic shift, confirming over-constrainment. AnchorSteer equilibrates both objectives, with marked improvement over the individual baselines.
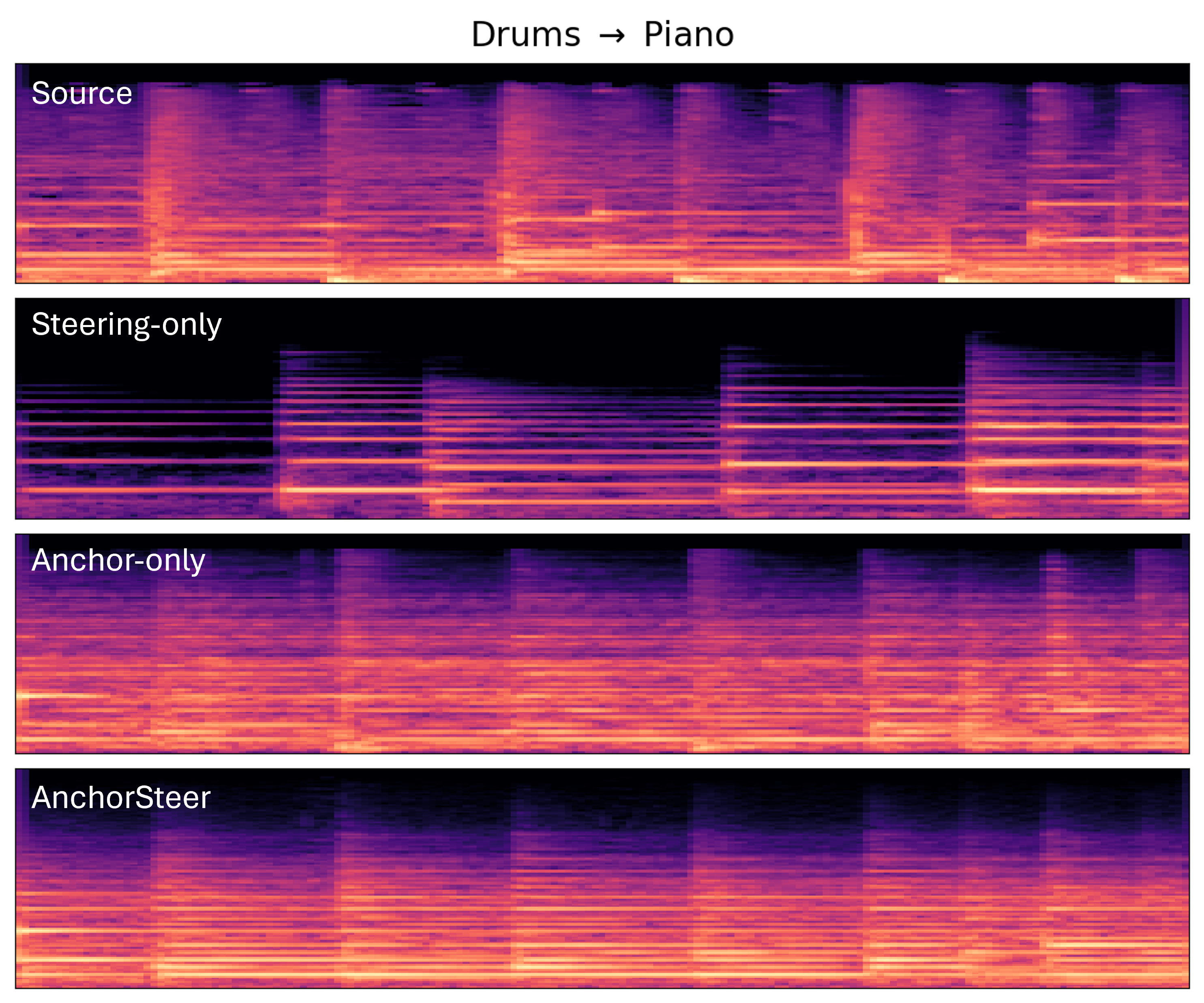
Figure 4: Spectrograms illustrating Drums→Piano editing: steering-only disrupts temporal alignment; anchor-only blocks semantic transfer; AnchorSteer achieves both harmonic and structural fidelity.
Ablation and Subjective Evaluation
Extensive ablations confirm that the conditioned injection module is robust to conflicting text prompts, consistently achieving high editability scores. Unconditioned injection is less robust to textual conflict, recommending neutral prompts for optimal effect. Subjective tests (mean-opinion scores from human listeners) corroborate these findings; AnchorSteer (conditioned) secures highest ratings in target attribute match and audio quality, with competitive content consistency.
Comparison to State-of-the-Art
AnchorSteer outperforms DDPM-Friendly, SDEdit, and MusicMagus in semantic transfer (GAP score) while maintaining high content coherence due to structural anchoring. The conditioned module, in particular, delivers superior trade-off resolution, achieving strong target attribute alignment without catastrophic loss of musical structure.
Implications and Future Directions
AnchorSteer establishes a transferable paradigm for controllable generative editing in music, extending vision-domain findings on semantic h-space manipulation to the audio domain. The plug-and-play nature of the learned concept vectors enables broad practical applicability for music editing tasks, including multi-concept and layered editing scenarios.
From a theoretical perspective, the success of self-supervised h-space injection reinforces the interpretation of pretrained diffusion models as possessing composable, navigable latent semantic manifolds—suggesting avenues for more general conditional generation. The explicit anchor-steer separation invites similar decompositions in other structured, temporally extended generative modalities (e.g., video, speech).
Open challenges remain, notably: (i) scaling to multi-attribute and long-form editing, (ii) generalizing concept discovery to unseen or abstract attributes zero-shot, and (iii) mitigating structure-editability trade-offs when strong attribute changes inherently conflict with source structure.
Conclusion
AnchorSteer presents a structure-aware music editing framework that integrates explicit structural anchoring with self-discovered semantic concept injection. This composition achieves a superior balance in the inherent trade-off between semantic editability and structural preservation. The methodological separation of attribute transfer (“steer”) and structure preservation (“anchor”) offers a generalizable, effective approach to controlled generative editing in music diffusion models, as substantiated by strong numerical and perceptual results (2605.31053).

