- The paper presents a unified evaluation framework that standardizes speech translation assessment across offline and streaming modes using metrics like BLEU, UTMOS, and latency measures.
- It introduces a modular design that integrates evaluation of translation fidelity, speech naturalness, speaker and emotion preservation, and temporal consistency.
- Experimental results reveal performance trade-offs, highlighting that strong translation quality does not guarantee robust speaker or paralinguistic preservation.
OpenSTBench: A Unified Multidimensional Evaluation Framework for Speech Translation
Motivation and Context
The speech translation (ST) landscape now encompasses both speech-to-text (S2TT) and speech-to-speech (S2ST) translation, deployed in offline and low-latency, streaming scenarios. Outputs thus vary not only in linguistic content but also in speech naturalness, paralinguistic features, speaker and emotion preservation, and temporal behavior. Historically, evaluation in ST has remained fragmented, focusing primarily on translation quality metrics (BLEU, COMET) and adopting ad hoc, task-specific protocols for assessing speech and timing characteristics. This heterogeneity has hindered cross-system benchmarking and constrained comprehensive advances in holistic speech translation.
OpenSTBench Framework: Unified Multidimensional Evaluation
OpenSTBench addresses this fragmentation through a unified framework for multidimensional evaluation, standardizing the assessment of S2TT and S2ST systems across offline and streaming operation modes. The benchmark consolidates translation quality, speech quality (including naturalness, transcription fidelity, speaker and emotion preservation, paralinguistic fidelity), and temporal quality (consistency and latency), all organized under a single shared evaluation protocol and data schema. This enables consistent, reproducible, and extensible benchmarking of heterogeneous system outputs.
Figure 1: Conceptual positioning of OpenSTBench.
System developers provide outputs in a common format; OpenSTBench automatically invokes the relevant evaluation modules according to available modalities. Modularity allows easy extension to new datasets, metrics, and languages without disrupting the evaluation protocol.
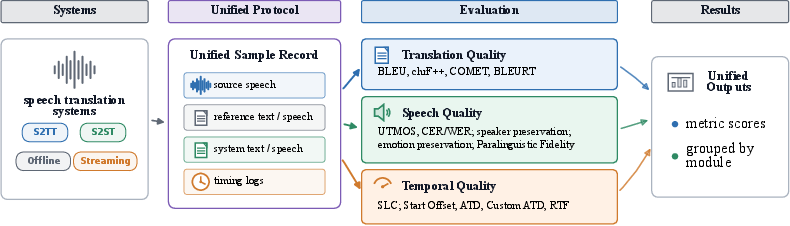
Figure 2: OpenSTBench overview: unified evaluation workflow across S2TT and S2ST systems in both offline and streaming settings. Metrics span translation, speech, and temporal aspects.
Evaluation Design and Component Metrics
OpenSTBench introduces explicit coverage of the following evaluation axes:
1. Translation Quality:
Assessed using sacreBLEU, chrF++, COMET, and BLEURT—thus quantifying lexical, character-level, and semantic fidelity between generated and reference translations.
2. Speech Quality:
- Naturalness: UTMOS, an automatic MOS predictor for speech.
- Text–Speech Consistency: ASR-based CER (for CJK) or WER (for other languages), comparing the ASR transcript of synthesized speech against target text.
- Speaker Preservation: Resemblyzer and WavLM, both based on embedding similarity, using a target-language speaker anchor to avoid cross-lingual degradation.
- Emotion: Emotion2Vec cosine similarity and audio-based emotion classification accuracy.
- Paralinguistic Fidelity: Event Content F1 and Event Timing F1, leveraging CLAP-detected acoustic events to assess preservation and alignment of nonverbal paralinguistic content.
3. Temporal Quality:
- Temporal Consistency: Speech Length Compliant (SLC) score at τ=0.2 and τ=0.4, evaluating if target speech durations match source durations within tolerance.
- Latency and Efficiency: For streaming systems, Start Offset, Average Token Delay (ATD), Custom ATD (adjusted for audio playback), and for offline models, Real-Time Factor (RTF).
This multidimensionality allows for rigorous characterization of system strengths and operational trade-offs.
Experimental Methodology
The authors evaluate leading commercial and open speech translation systems:
- Streaming S2ST: Qwen3-LiveTranslate, Doubao AST 2.0, GPT Realtime Translate.
- Streaming S2TT: Baidu Realtime ST.
- Offline S2ST: SeamlessM4T-v2-Large, UniSS.
Datasets cover both English–Chinese translation directions and span general ST (MSLT), speaker preservation (LibriTTS-based paired speaker set), emotion preservation (RAVDESS, MCAE-SPPS), and paralinguistic fidelity (NonverbalTTS, SynParaSpeech).
The evaluation protocol is carefully controlled, using native system interfaces for latency and real-time measurements, and aligning output representations for fair metric calculation.
Empirical Results
Translation Quality:
Qwen3-LiveTranslate outperforms all other systems in BLEU, chrF++, COMET, and BLEURT in both EN→ZH and ZH→EN, with Doubao AST 2.0 and UniSS as main alternatives in their respective (streaming, offline) domains.
Speech Quality:
- UniSS and Doubao AST 2.0 are consistently strong in speaker preservation.
- Emotion preservation and paralinguistic fidelity remain difficult for all systems—absolute F1 scores are low, with substantial room for improvement.
- Notably, UTMOS and CER/WER metrics are not always concordant, highlighting the complexity of naturalness vs. realization fidelity.
Temporal Quality:
- Streaming systems show a marked trade-off: lower latency (Start Offset, ATD, Custom ATD) does not guarantee high temporal consistency (SLC).
- UniSS outperforms other offline models in both RTF and SLC, but S2TT systems (like Baidu Realtime ST) have structural limitations (such as lack of target speech, and thus no event or emotion scores).
The radar plots provide a concise visualization of bilingual average performance profiles across all evaluated systems, enabling direct cross-dimensional trade-off analysis.
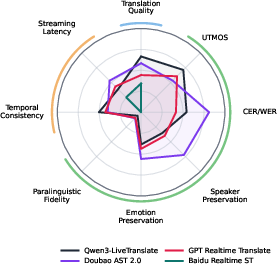
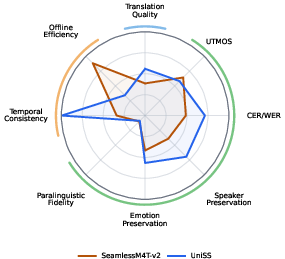
Figure 3: Bilingual-average radar plots of normalized scores across translation, speech, and temporal dimensions for all evaluated streaming and offline systems.
A salient finding is the absence of system dominance: Strong translation does not entail strong speaker or emotion preservation, nor does low-latency guarantee temporal consistency. This substantiates the claim that ST benchmarking must move beyond one-dimensional leaderboards in favor of application-aligned comparative analysis.
Implications and Future Research Directions
OpenSTBench advances the methodology for holistic and reproducible speech translation evaluation, standardizing cross-modal, cross-operational assessment for increasingly heterogeneous and multimodal systems. The main implications and prospects include:
- Application-aware Benchmarking: The multidimensional protocol enables system selection tailored to end-user priorities (e.g., real-time dialog vs. high-fidelity dubbing).
- Future Expansion: While this release focuses on English–Chinese, the architecture and protocol are readily extensible to more languages and evaluation scenarios (including more complex conversational, multi-party, or highly expressive tasks).
- Human Alignment: As many speech and paralinguistic evaluators remain automatic, future work should further calibrate automatic metrics against human judgments, particularly in speaker and emotion preservation.
- Unified Speech Interface Research: OpenSTBench lays groundwork for new research at the interface of speech, language, and paralinguistics, promoting joint modeling and evaluation of non-semantic content in end-to-end systems.
The framework will be released as an open, modular Python package, supporting comprehensive and customizable evaluation pipelines for both academic and industrial speech translation research.
Conclusion
OpenSTBench represents a significant methodological advance in speech translation evaluation by introducing the first extensible, open-source protocol for unified, multidimensional benchmarking across S2TT, S2ST, offline, and streaming scenarios. Experimental results confirm that strong variation persists across translation, speech, and temporal attributes—mandating multidimensional, application-oriented benchmarking for both research and deployment. The release of OpenSTBench is expected to facilitate further innovation and nuanced system comparison in the evolving speech translation landscape.

