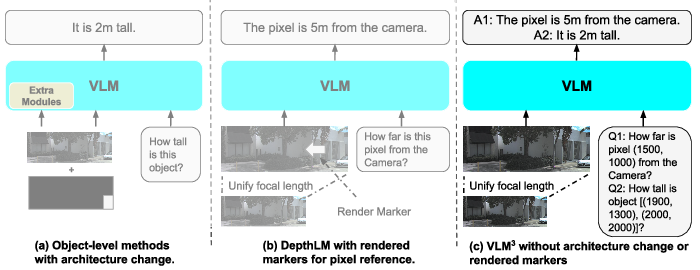
- The paper demonstrates that with minimal modifications, vision language models can be repurposed for high-fidelity 3D tasks.
- It introduces focal length unification and text-based pixel reference to overcome camera ambiguity and enhance geometric understanding.
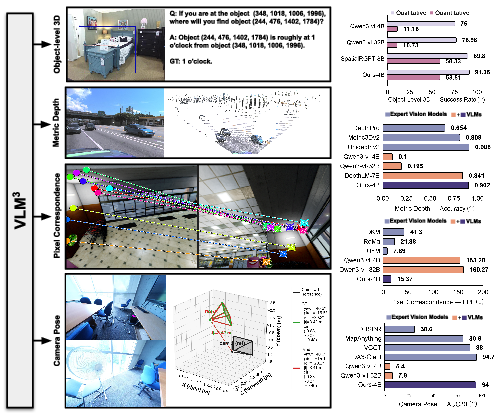
- Experimental results reveal that VLM3 outperforms or matches expert 3D models in depth, object-level, correspondence, and pose estimation tasks.
Vision LLMs Are Native 3D Learners: An Expert Analysis of VLM3 (2605.30561)
Motivation and Problem Setting
The paper "VLM3: Vision LLMs Are Native 3D Learners" addresses the longstanding dichotomy between expert 3D vision models—characterized by specialized architectures, complex losses, and heavy augmentations—and generalist vision LLMs (VLMs). Historically, VLMs have excelled in semantic tasks but have lagged dramatically in 3D geometric understanding, particularly at fine-grained levels such as depth metrics, correspondence, and pose. The central claim of the paper is that standard VLMs, equipped with proper task formulation and minimal design, are intrinsically capable of high-fidelity 3D understanding across a wide spectrum of tasks.
Methodology: Minimal Design, Maximal Generality
The VLM3 framework relies on three key simplifications:
The entire training pipeline retains vanilla VLM architectures and text-supervised finetuning (SFT) without regression losses, special decoders, or augmentation-heavy regimes.
Experimental Evaluation: Diverse 3D Tasks
VLM3 is evaluated across four mainstream 3D vision tasks:
Qualitative Results and Visualizations
Empirical results are reinforced by visualizations demonstrating reliable outputs across depth, spatial reasoning, correspondence, and pose, both in single and multi-view settings, for indoor and outdoor images. Notably, dense point clouds are generated via text prompting alone, and object/pose queries are resolved without architectural modifications or auxiliary markers.

Figure 3: Representative outputs for depth, object-level, correspondence, and pose estimation tasks; raw inputs suffice for robust predictions.
Analysis: Design Choices and Scaling Laws
- Text vs. Visual Pixel Reference: Text-based pixel reference performs equivalently to visual prompting when normalization is applied, offering greater efficiency and scalability for large batch QA.
- Data Mixture Weighting: Dataset size-based weights outperform uniform weighting, preventing saturation or regression performance when scaling to tens of millions of samples.
- Model Size: Increasing model size does not yield accuracy gains at current data scales; 4B models suffice for SOTA results, and overfitting emerges with larger models or higher data volume unless mixture is optimized.
Theoretical Implications
The results overturn several axioms in 3D vision:
- Regression Formulation Is Unnecessary: Treating 3D outputs as text QA achieves parity with regression-based expert models for depth, correspondence, and pose.
- Task-Specific Design Is Not Required: Standard VLM architectures, with focal length unification and normalized text queries, master diverse 3D tasks.
- Scalability Is Strongly Data-Limited: Proper data mixture, rather than architectural innovation, is the decisive factor for generalist model performance in 3D vision.
Practical Implications and Future Directions
VLM3 demonstrates that highly generalist VLMs are practical for 3D vision deployment, simplifying both training and inference pipelines. Foundation models with text-based supervision can now match expert accuracy in dense 3D tasks without custom architectures, losses, or augmentations. The findings invite new paradigms in vision-language training, suggesting that further scaling in data and cross-task QA packing could unlock even broader capabilities.
Research avenues include exploring larger models at escalated data scales, optimizing mixture ratios, and applying the VLM3 approach to new modalities (e.g., video, point cloud). Theoretical work may revisit the nature of geometric inductive biases and their necessity in multi-modal model learning.
Conclusion
VLM3 establishes that vision LLMs, when configured with minimal design and intelligent dataset weighting, are native 3D learners capable of mastering fine-grained geometric tasks across depth, objects, correspondence, and pose. The study significantly reduces the complexity of designing 3D vision models, shifting focus towards scalable, unified QA-based frameworks and reinforcing the primacy of data mixture over traditional architectural innovations. The work represents a fundamental step toward generalist 3D foundation models and provides a rigorous baseline for future AI research in multi-modal geometric learning.