- The paper introduces PARCEL, a dual-path tokenization architecture combining spatial anchors and conditioned elastic queries to boost vision-language efficiency.
- It decouples low-frequency geometric context from high-frequency semantic details, reducing computation while maintaining fine visual cues.
- Empirical results demonstrate 95–98% performance retention at 256 tokens, outperforming rigid pooling and query-only methods on tasks like RefCOCO segmentation and ChartQA.
PARCEL: Pool-Anchored Resampling with Conditioned Elastic Queries for Efficient Vision-Language Understanding
Motivation and Context
Large Vision-LLMs (LVLMs) suffer from prohibitive computational and memory complexities during inference due to the quadratic scaling of Transformer self-attention with input sequence length. In LVLMs, this bottleneck is exacerbated when visual information (images or video) must be tokenized into hundreds or thousands of dense visual tokens before fusion with language, resulting in significant compute and memory overhead. Prior research has targeted visual token compression via fixed-length pruning and merging, static downsampling, and query-based summarization. However, these methods enforce strict accuracy-efficiency trade-offs, limit post-training flexibility, and, as empirically demonstrated, induce severe performance bottlenecks when aggressively compressing input representations—either by destroying fine-grained detail (spatial pooling) or by undermining spatial layout and grounding (query resampling).
Elastic visual-token compression, inspired by the matryoshka paradigm, offers a “train once, deploy anywhere” approach that enables LVLMs to operate at multiple visual-token budgets post-training. Nonetheless, prevailing matryoshka-style architectures—rigid spatial downsampling (e.g., Matryoshka Multimodal Models, M3 [M3]) and non-local query resampling (e.g., Matryoshka Query Transformer, MQT [MQT])—induce complementary spectral bottlenecks. Pooling acts as a leaky low-pass filter leading to aliasing and degraded high-frequency content, while global query resampling erases explicit grid structure, undermining dense grounding.
PARCEL (Pool-Anchored Resampling with Conditioned Elastic Queries) introduces a novel hybrid visual tokenization strategy expressly designed to resolve these representational conflicts. The core principle is a division-of-labor whereby spatial anchors (obtained via learnable average pooling) provide explicit low-frequency geometric layout, and a supporting set of pool-conditioned elastic query tokens (trained via nested dropout) focus on capturing orthogonal or complementary information, particularly high-frequency and non-redundant detail.
After extracting visual encoder features, PARCEL pools them into deterministic 2D spatial anchors. Separately, learnable query tokens undergo Pool-Conditioned Query Resampling (PCQR). In PCQR, query tokens receive attention-based conditioning from the spatial anchors, encouraging them to ignore already-grounded information and instead specialize in details not represented in the anchor grid. This processed query set then cross-attends to the raw, uncompressed visual features (ViT outputs), forming a sequence of semantic explorer tokens that encode high-frequency and non-local cues. Ultimately, concatenating the anchor and explorer tokens forms a compact, budget-aware context for the language decoder.
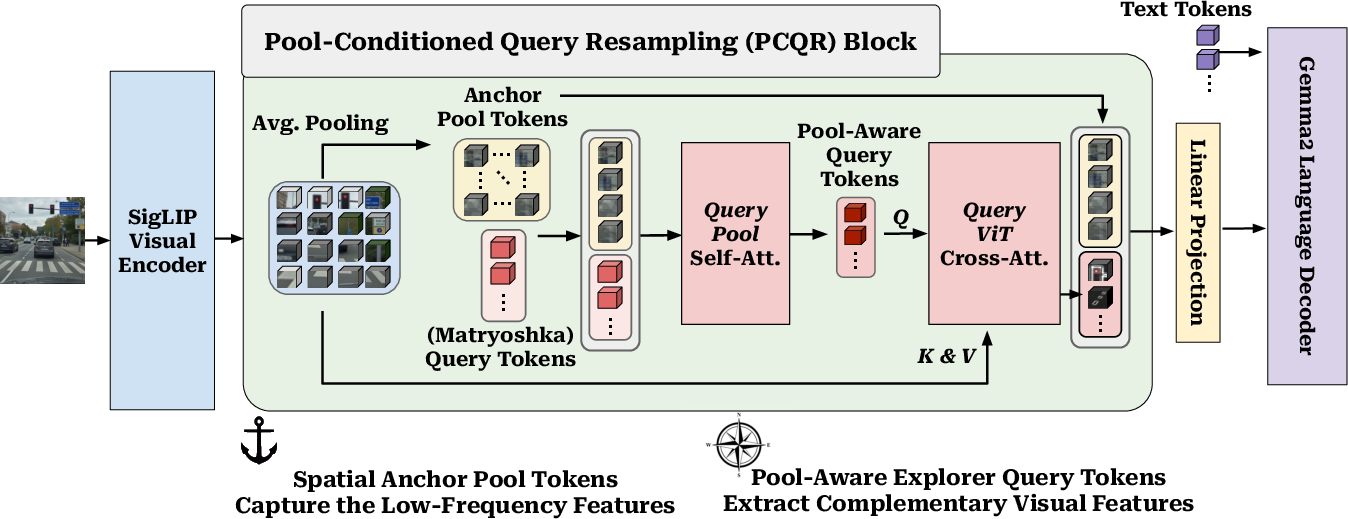
Figure 1: High-Level overview of the PARCEL architecture, depicting spatial anchoring, PCQR-based query conditioning, and semantic exploration for efficient vision-language coupling.
Spectral Analysis and Representational Bottlenecks
A systematic spectral analysis reveals the primary weaknesses of prior art. In rigid spatial pooling architectures (M3), average pooling manifests as a low-pass filter; however, with limited spatial grid resolution, aliasing severely distorts high-frequency content, rapidly degrading chart reasoning and text-centric VQA performance as compression increases. Conversely, in query-only approaches (MQT), learned queries, without explicit spatial anchoring, are forced to model both geometry and detail, leading to a breakdown in dense spatial grounding and localization.
PARCEL's dual-path architecture is validated via power spectral diagnostics: it achieves steep cumulative spectral power concentration at low frequencies in spatial anchors (indicating robust geometric preservation), while the conditioned queries maintain, via their attention footprints, substantial high-frequency support beyond the anchor Nyquist limit. This division directly underpins superior performance on tasks requiring simultaneous layout fidelity and semantic richness.
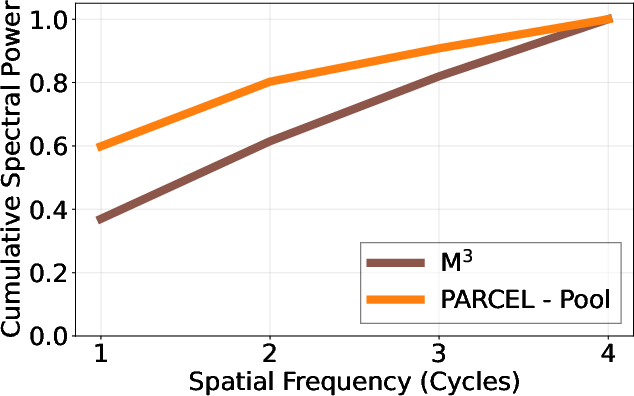
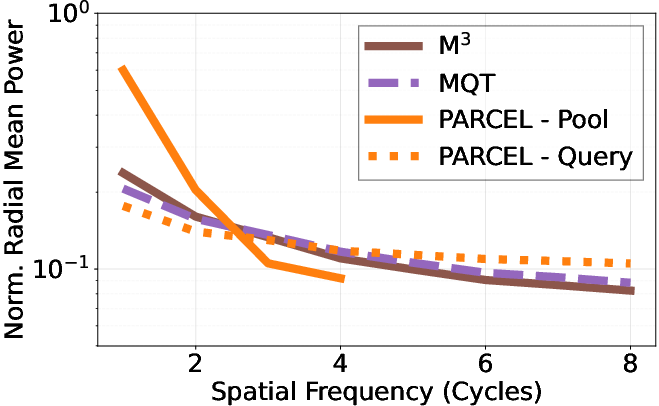
Figure 2: Baseband concentration profiles showing faster low-frequency accumulation for PARCEL’s spatial anchors compared to M3, confirming more effective separation and anchoring of geometric information.
PARCEL advances the Pareto frontier in the performance–efficiency landscape for elastic visual-token compression. Across 27 standardized benchmarks—encompassing video understanding, dense segmentation, and resolution/grounding-sensitive reasoning—PARCEL consistently yields the highest mean retention of baseline (uncompressed) LVLM performance at any fixed token budget. Notably, PARCEL achieves:
- 95–98% retention at 256 tokens (image/video), with up to +3% improvement over prior matryoshka baselines.
- Robust performance at 16–64 tokens, with mean retention consistently best-in-class, particularly on spatially- and detail-demanding tasks (e.g., up to +4.2 points improvement on RefCOCO segmentation at 256 tokens, and +4.7 points on ChartQA at 64 tokens).
Importantly, ablation studies confirm these improvements result from the architectural division-of-labor, not from increased parameter count or trivial capacity scaling. Both PCQR and budget-aware routing are essential; fixed or naive allocation of anchor/query sizes severely inhibits compression robustness.
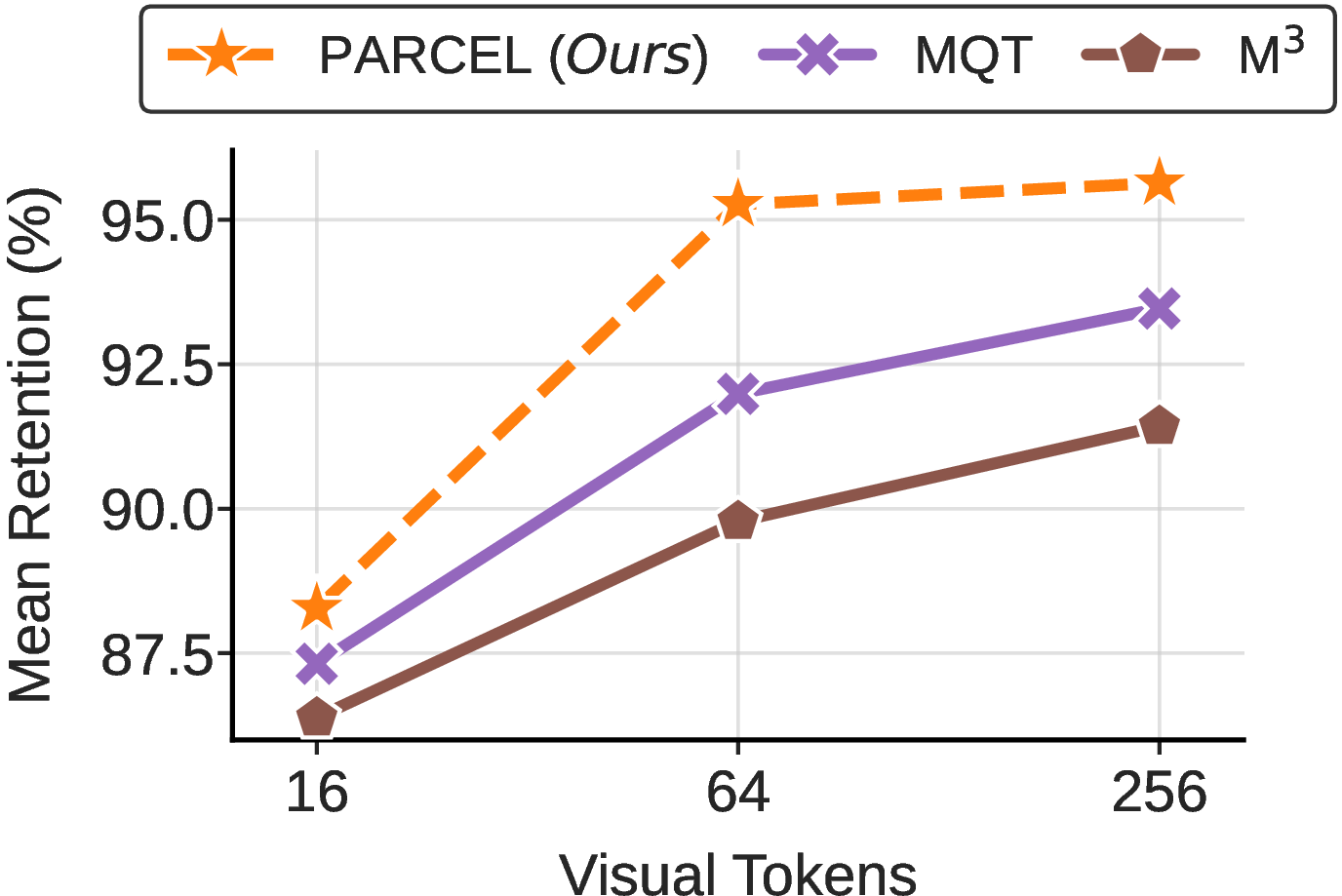
Figure 3: Aggregate efficiency–retention trade-off: PARCEL yields higher performance retention at given FLOP/KV-cache budgets compared to MQT and M3.
Comparative Analysis: M3, MQT, and PARCEL
The architectural contrast between M3 (rigid, grid-based pooling), MQT (query resampling with no explicit geometry), and PARCEL (hybrid anchoring) is critical. M3 collapses at high compression because aliasing destroys fine detail, MQT collapses under spatial ambiguity, while PARCEL's pool–query split is robust to both. Visual overviews (see below) illustrate this contrast.
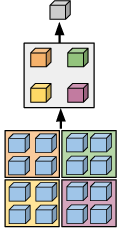
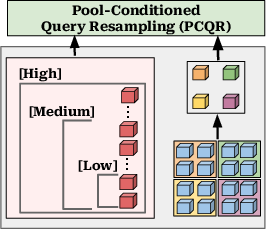
Figure 4: Conceptual structure of M3: rigid spatial pooling compresses visual features but is susceptible to aliasing.
Practical and Theoretical Implications
By achieving strong retention while drastically reducing FLOPs and KV-cache requirements, PARCEL directly enables deployment of LVLMs on memory- and compute-constrained edge devices, mobile, or real-time applications—particularly for multi-frame inputs and high-resolution scenarios where static token allocation is infeasible. The explicit geometric–semantic division also facilitates further research into adaptive compression (input-dependent token allocation), learned budget scheduling, and more granular, feature-level transfer.
Theoretically, the results reinforce a principled approach to multimodal representation: preserving global structure and local detail must be disentangled and separately parameterized to avoid spectral entanglement bottlenecks. This insight can propagate to related problems in self-supervised representation learning, hierarchical latent modeling, and token-efficient generative architectures.
Future Directions
Further progress is expected in (1) input-adaptive budget prediction for dynamic token assignment, (2) exploring richer anchor-query coordination mechanisms, possibly leveraging spatial-frequency domain priors, (3) application of similar dynamic decomposition to other dense-to-sequential architectures, and (4) integration with emerging efficient backbone architectures beyond ViT and standard Transformers. Addressing backbone and data biases, as well as more comprehensive scaling studies, remains crucial for responsible and transferable deployment.
Conclusion
PARCEL demonstrates that principled architectural decomposition—anchoring geometric context via spatial pooling while dynamically resampling information-rich queries conditioned on anchor cues—enables LVLMs to achieve a superior trade-off between efficiency and semantic fidelity. Across a broad suite of vision-language tasks, PARCEL robustly preserves task-critical details even under aggressive token-compression, outperforming state-of-the-art matryoshka baselines and advancing the deployability of multimodal models in practical, resource-constrained settings (2605.30126).

