- The paper presents EvoRepair, which enables experience-based self-evolution to overcome repetitive, suboptimal repair cycles.
- It introduces a modular closed-loop process combining experience retrieval, repair execution, extraction, scoring, and bank updates for enhanced transferability.
- Experimental results demonstrate up to 93.47% accuracy on PATCHEVAL with reduced computational costs, emphasizing the framework's robustness and practicality.
EvoRepair: Experience-Based Self-Evolving Automated Vulnerability Repair
Introduction
The escalation of software complexity has intensified the exposure of security vulnerabilities, with an unprecedented surge in reported CVEs year over year, as visually tracked in recent quantitative analyses.
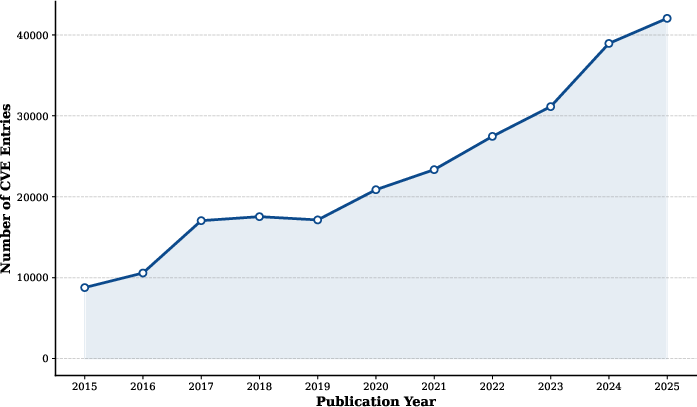
Figure 1: Yearly growth in reported CVEs, highlighting acceleration in vulnerability disclosure volume.
The state of Automated Vulnerability Repair (AVR) has seen methodical progression, with the landscape shifting from program analysis and search-based approaches toward neural methods leveraging pre-trained and, more recently, LLMs. Nevertheless, the predominant limitation in contemporary AVR—particularly LLM-based agents—lies in their lack of capability to (1) accumulate and make use of intra-vulnerability experience during iterative repair and (2) generalize historical repair knowledge across disparate vulnerabilities. In effect, agents repeatedly reiterate suboptimal repair paths and fail to systematically exploit transferable remediation knowledge.
The EvoRepair framework directly addresses these deficits by introducing an explicit, experience-based self-evolving AVR agent paradigm. EvoRepair structures AVR as a closed-loop process encompassing experience retrieval, repair trajectory execution, experience extraction, scoring, and bank updates. The design is modular and agnostic to backbone LLMs or agent frameworks, enabling broad applicability and transferability across programming languages, datasets, and even model architectures.
Motivation and Design Rationale
Empirical observation reveals that LLM-driven agents, if devoid of explicit experience chaining, often degenerate into nondeterministic, trial-and-error cycles—submitting numerous candidate repairs with limited learning from failures or intermediate diagnostic signals. This is corroborated through case studies, exemplified in CVE-related patching tasks, where naive agents either fail to break out of unproductive strategy cycles or produce brittle, test-oriented modifications in lieu of semantically robust fixes.
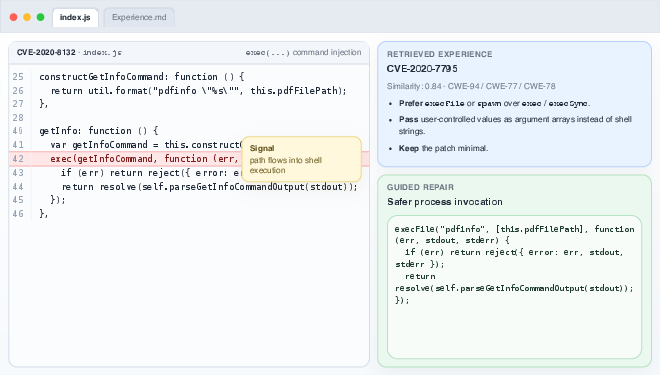
Figure 2: Motivational example demonstrating EvoRepair overcoming repeated mistakes in patching via experience guidance.
The EvoRepair framework is predicated on the formal distillation of domain-specific "experiences": compact, transferable tuples containing (a) vulnerability analysis, (b) explicit repair rationale, (c) trajectory highlights (actions, pitfalls), (d) prescriptive repair rules with examples, and (e) success/failure reflections. The repair process alternates between learning (experience extraction/synthesis) and repair (experience-augmented patching), systematically extending the agent’s domain-knowledge base.
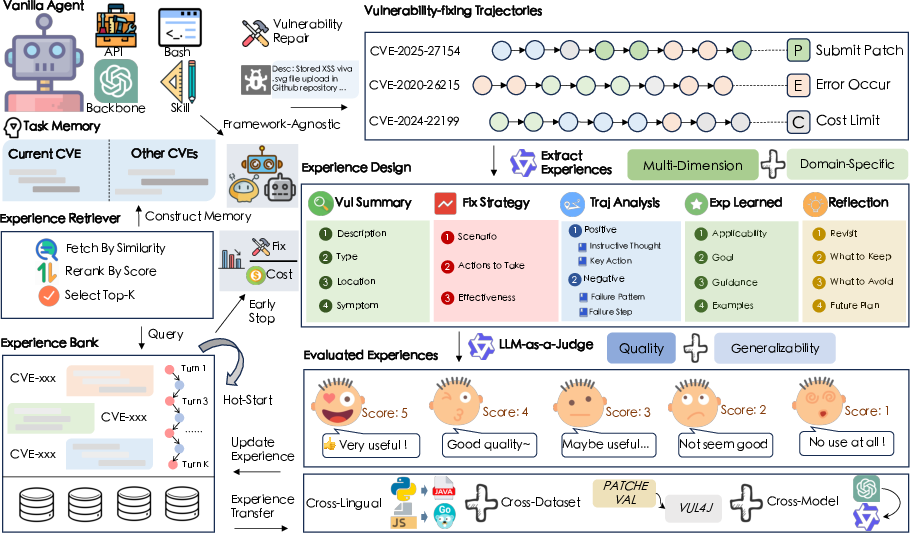
Figure 3: EvoRepair workflow illustrating the cyclic interaction between experience retrieval, agentic repair, experience synthesis, and bank updates.
This design leverages a hybrid scoring-rank retrieval mechanism: before each repair turn, the agent retrieves experiences based on both semantic vulnerability similarity and the composited quality/generalizability score of available entries, ensuring injection of only actionable, generalizable repair advice.
Experimental Results and Quantitative Analysis
Benchmarking and Metrication
EvoRepair was systematically benchmarked against 12 representative AVR baselines (learning-based, pure LLM, and agentic) on the multilingual PATCHEVAL (JavaScript, Python, Go) and C-centric SEC-bench datasets. The core metrics are absolute number of vulnerabilities fixed (#Fix) and percentage (\%Fix) validated via oracle PoC and function/unit-test execution.
EvoRepair achieves a new accuracy regime, measured at 93.47% on PATCHEVAL, 87.0% on SEC-bench, and 90.46% overall, notably eclipsing the strongest prior art (Live-SWE-Agent) by nearly 7 percentage points, as well as SOTA LLM-based (LoopRepair, IntentFix) by wide margins (33–71%).
Self-Evolution Dynamics
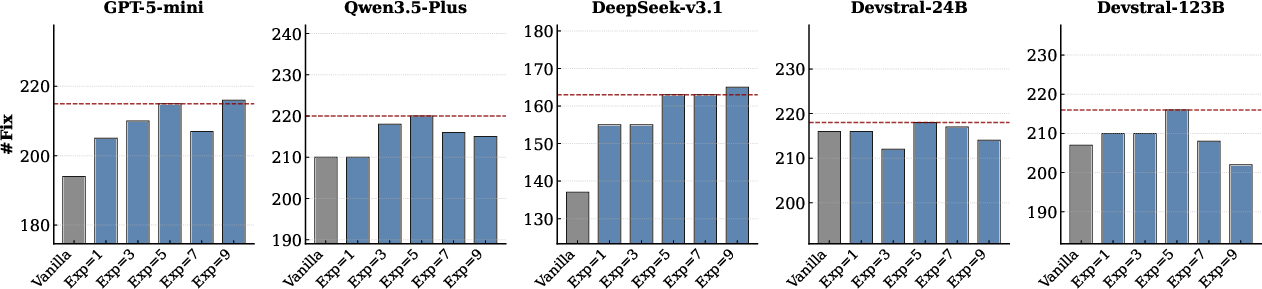
Turn-level analysis demonstrates that EvoRepair consistently surpasses vanilla agents across all base LLMs and converges to its repair ceiling in fewer iterative cycles.
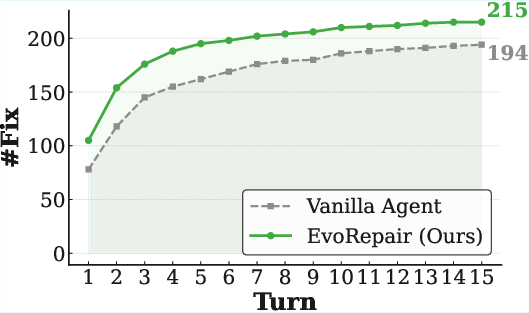
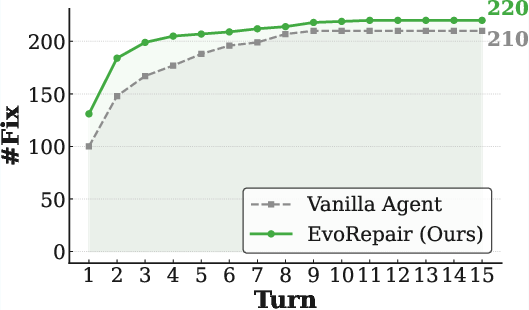
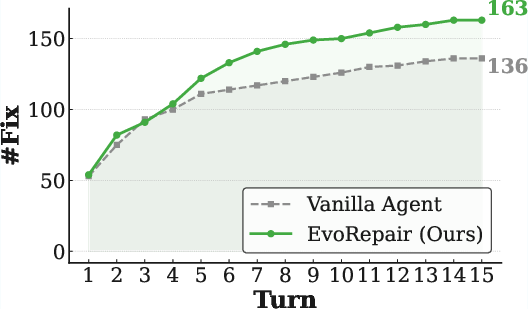
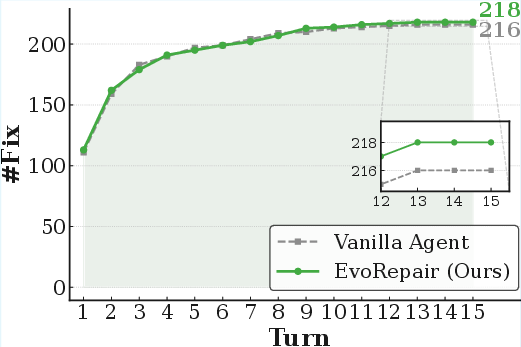
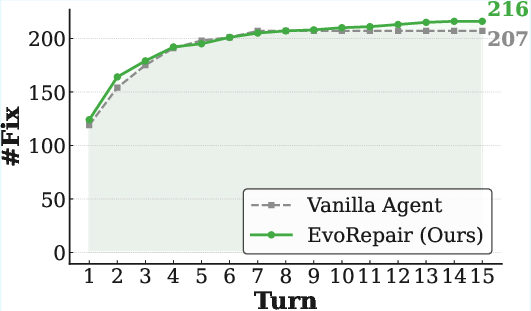
Figure 4: Turn-level repair success rates on PATCHEVAL, showing accelerated convergence and higher final performance of EvoRepair versus vanilla/competing agents.
On SEC-bench, the same trend holds, with EvoRepair not only exhibiting increased total fixes per model but also superior cost-effectiveness per repair trajectory.
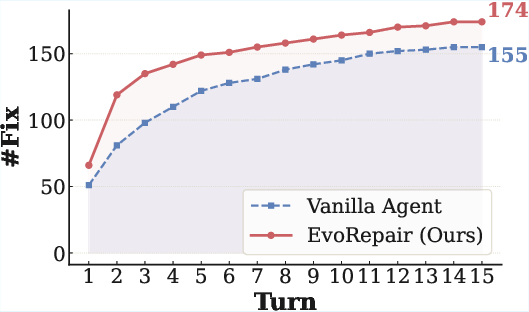
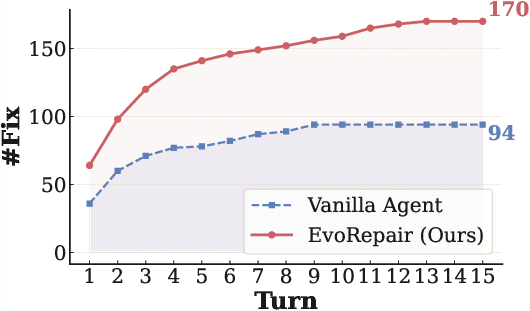
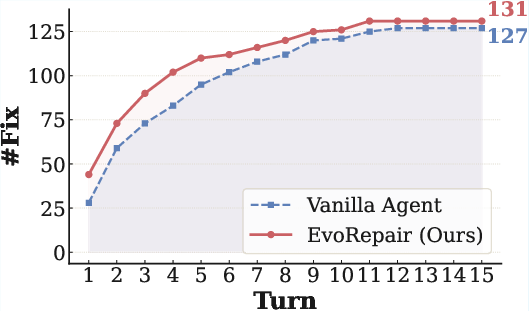
Figure 5: Per-turn progression in SEC-bench, evidencing EvoRepair's persistent advantage in both early and late repair turns.
Ablation and Component Characterization
Ablation experiments elucidate critical properties of the design:
Robustness, Transferability, and Overlap
EvoRepair’s experiences support cross-model, cross-language, and cross-dataset transfer; models as divergent as Qwen3.5-Plus, Qwen3-Max, and Devstral-xxB can exploit the shared experience bank for true knowledge transfer, evidenced in transfer experiments to VUL4J (Java) where intra- and cross-model transfer yields 8–10% higher fix rates.
Model-to-model and agent-to-agent overlap analysis demonstrates that EvoRepair’s augmentation does not jeopardize baseline strengths; rather, it increases the set of commonly fixed vulnerabilities and harmonizes model repair behavior toward an expanded but robust solution set.
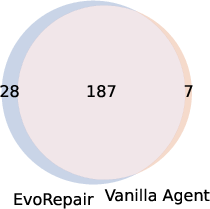
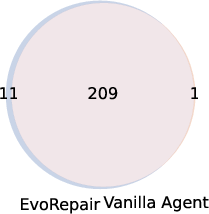
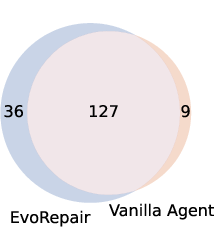
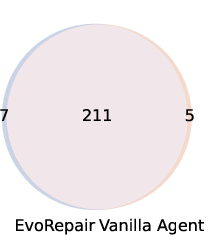
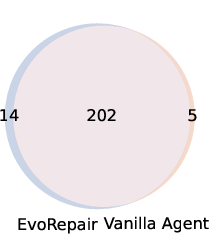
Figure 7: Overlap between fixed vulnerabilities across LLMs in both vanilla and EvoRepair configurations; EvoRepair consistently expands the intersection set.
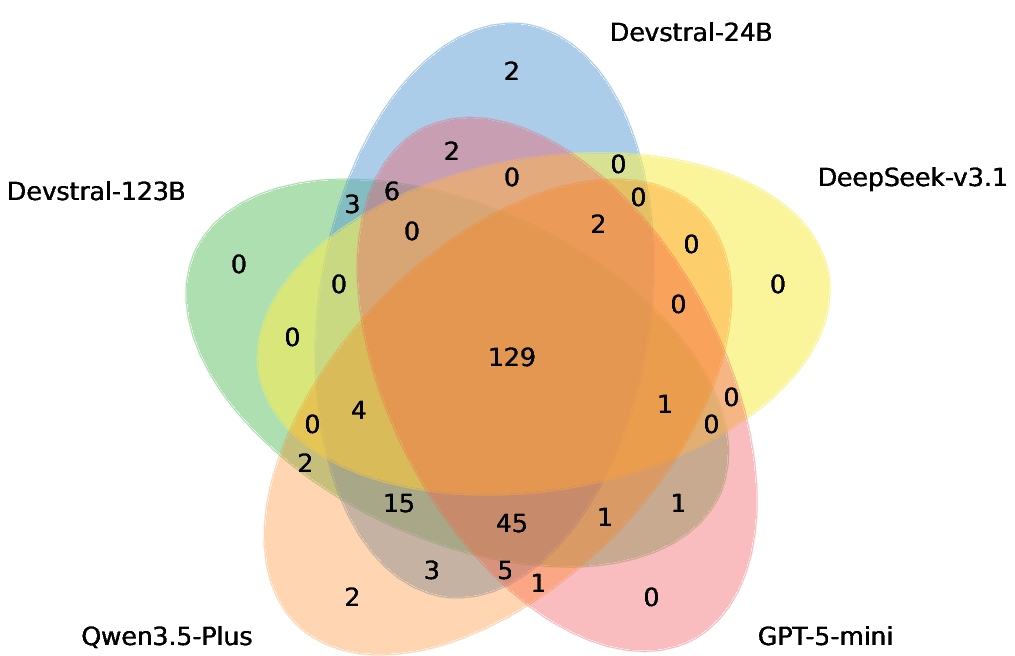
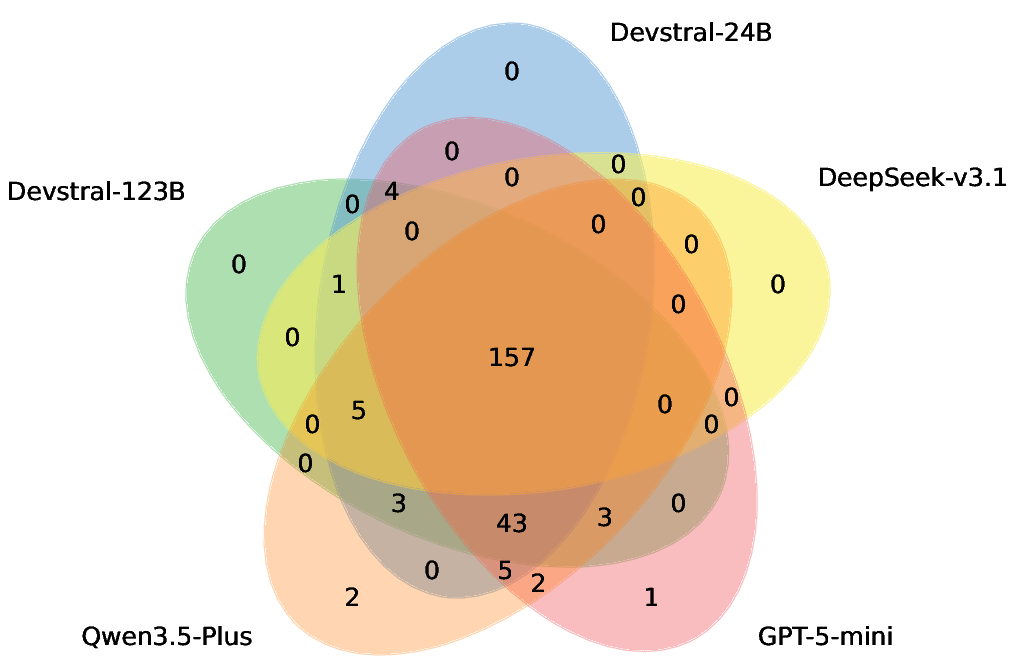
Figure 8: Visualization of vulnerabilities fixed by all base models before (left) and after (right) applying EvoRepair, evidencing the harmonizing effect of shared experience.
Trajectory Cost and Computational Efficiency
Per-CVE repair costs and overall computational budgets were thoroughly recorded. For high-capacity agents (e.g., Qwen3.5-Plus, GPT-5-mini), EvoRepair drives actual cost reductions (up to 41.6%) due to early convergence, while for less robust backbones overhead is largely due to unsolved cases. Early stopping guided by turn-level marginal gain/cost yield rate α, when set in [0.15, 0.25], reduces compute by 20–40% at negligible accuracy loss.
Theoretical Implications and Directions
EvoRepair formally demonstrates the value of explicit, context-aware experience chaining for complex sequential reasoning and code synthesis tasks in LLM-based agents. By abstracting experiences into structured, actionable, and rankable knowledge units, the framework sets a precedent for scaling agentic repair systems to ever-growing vulnerability landscapes—addressing both intra- and inter-task memory bottlenecks.
Practically, EvoRepair serves as a knowledge amplifier: it enables not only single-agent improvement but, by virtue of its experience bank architecture, facilitates distributed, asynchronous experience sharing and transfer. Theory-wise, this suggests new self-improvement routes for agentic LLM architectures, echoing but operationalizing "operational/episodic" memory in neurosymbolic systems.
Conclusion
EvoRepair is established as a highly effective, transferable, and robust architecture for LLM-based AVR, demonstrably outperforming state-of-the-art baselines across diverse languages, datasets, and LLM platforms. The formalization of experience-based self-evolution introduces a modular protocol that balances repair effectiveness, computational cost, and generalizability. The approach’s success indicates that future advances in agent-based code reasoning and security automation should prioritize systematic and explicit inter-episodic knowledge accumulation, experience refinement, and transfer.
Reference: "EvoRepair: Enhancing Vulnerability Repair Agents Through Experience-Based Self-Evolution" (2605.30105)